
はじめに
SWC はRust製の高速なJavaScriptトランスパイラです。 (minifierやbundlerなど他の機能の実装も進められていますが、現時点ではトランスパイラとしての役割が主です)
この分野ではもともとJavaScript製のBabelというツールが広く使われています。そのBabelには強力なプラグインシステムがあり、これによりBabelは単なるダウンレベルコンパイラ (新しい構文を古い構文に置き換える) としての役割だけではなく、メタプログラミングのツールとして広く普及しています。
いっぽう、SWCのプラグインシステムは2022年2月ごろに実装が進み、現在ではNext.jsを含め広く利用可能な状態になっています。SWCはRustで書かれていること、速度を非常に重視していることから、Babelとの差異も多く存在しています。
本稿ではSWCとBabel自体の仕組みの違いに注目しながら、SWCプラグインとBabelプラグインの書き味の違いを紹介していきます。
この記事は、2022年3月にインターンに来てくれた田村くんの成果:
- BabelプラグインをRust (SWC) に移植して、JavaScriptのコンパイルを爆速にする 〜基本編〜
- BabelプラグインをRust (SWC) に移植して、JavaScriptのコンパイルを爆速にする 〜プラグイン作成編〜
および、筆者が自作のBabelプラグインをSWCに移植した経験に基づいています。
プラグインアーキテクチャの違い
Node.jsでは未知のコードをrequire/importで動的に読み込むことができます。そのため、Babelはプラグインを同一Node.jsプロセス内に読み込んで実行します。プラグインはBabel本体や他のプラグインとオブジェクト状態を共有します。
この一見当たり前のような前提がSWCでは成り立ちません。RustコードはネイティブコードやWASMにコンパイルして使用されるため、実行時に未知のコードをevalするという方法はとれません。
かわりの方法としてC言語などでよく使われるのが dlopen(3) などの動的ライブラリインターフェースです。しかしこの方法にも好ましくない点があります。
- プラグイン側も複数のターゲットアーキテクチャに向けてコンパイルする必要がある。
- インターフェース部分をunsafe Rustで書く必要がある。
SWCではこの方法を使わずに、プラグインをRustで書きつつ、SWC本体や他のプラグインから独立したWASMインスタンスとして立ち上げます。 (現時点ではVMとしてwasmerを採用しているようです)
プラグインとのやりとりは大きく2つに分けられます。
- バッチ入出力 (入力AST、プラグイン設定、コンテキスト、出力AST)
- rkyvというシリアライゼーションフォーマット (protobufやmsgpackなどの仲間) を使い、ホスト側からWASMのメモリを直接読み書きしてやりとりする。
- 対話的入出力 (コメント情報、衛生性、診断メッセージ)
- WASM側からホスト関数を呼び出す。
JavaScriptプラグインについて
SWCは当初、JavaScriptによるプラグインシステムを提供していました。このパフォーマンスの問題を解決するために現在のWASMベースのプラグインシステムが作られ、JavaScriptによるプラグインシステムはドキュメントから削除されました。
このプラグインシステムはおそらくまだ残されていますが、使わないのが無難でしょう。
組み込みプラグイン
SWCのプラグインシステムはネイティブコードでない点やRPCが必要な点から、おそらく多少のパフォーマンスオーバーヘッドがあります。 (といっても、Babelが全体として遅いのに比べたらおそらく些細なものでしょう) これによりプラグインのラインナップにも違いが出ています。
BabelはBabelの一部として提供されている変換もサードパーティー製のものと同様にプラグインとして提供されています。設定ファイルのpluginsに名前を書くことで変換が有効化されます。
いっぽう、SWCでは同様の変換がプラグインではなくコンパイラに組み込みのオプションとして提供されています。プラグインシステムは最近できたばかりなので当たり前の話ですが、SWCがパフォーマンスを非常に重要視していることを鑑みると、これらがプラグインとして分離される可能性は低いでしょう。
ただし、SWC内のRust API上は変換パスは Fold または VisitMut として実装されていて、これはコンパイラに組み込みの場合もプラグインの場合も同様です。
プラグインパスの違い
プラグインアーキテクチャの違いは、プラグインの実行順の違いにも影響しています。
Babelプラグインはデフォルト (passPerPreset が無効の場合) では、プラグインをその定義順優先ではなくASTの訪問順優先で実行します。あるノードについて全てのプラグインを実行し、次のノードについて全てのプラグインを実行し、…… という流れです。また、変換処理の実行前フックと実行後フックもまとめて実行されます。
いっぽう、SWCのプラグインはASTを入力してASTを出力する関数として抽象化されているため、プラグインごとに一気に実行されます。
ASTの違い
estree vs. SWC
BabelはJavaScriptにおけるJavaScript ASTのコミュニティー標準であるestreeをベースにいくつかの改変を加えたものを使っています。
一方RustにおけるJavaScript ASTにそのようなものはなく、SWCは独自にASTを定義して使用しています。とはいえ、大まかな構造はestreeと同じようなところに落ち着いているので、そこまで混乱はないはずです。
循環参照の問題
しかし、問題は別のところにあります。それはRust自身がもつデータ構造上の制約……特に、循環参照を持てない、という点です。
Rustは論理的な正しさを保証しやすい形でプログラムを書き、それによって高度な最適化を行う言語です。なかでもプログラムの挙動を難しくしている諸悪の根源がエイリアシングであり、Rustはエイリアシングを制御下に置くために大変な工夫をしています。
たとえば、ASTを組み立てるにあたって、同じノードを使い回すのはエイリアシングの代表例です。
// x = x + y のAST
const x = t.identifier("x");
const y = t.identifier("y");
// xをあらわすノードが使い回されている
const expr = t.assignmentExpression("=", x, t.binaryExpression("+", x, y));このような処理を書くと、後続の処理でさらにASTを書き換えたときに不可解な挙動に悩まされることになります。そのためBabelでもノードの使い回しはしてはいけないことになっていて、次のようにcloneNodeを行う必要があります。
// x = x + y のAST
const x = t.identifier("x");
const y = t.identifier("y");
const expr = t.assignmentExpression("=", x.cloneNode(), t.binaryExpression("+", x, y));SWCで同じことをしようとすると所有権の問題でコンパイルエラーになり、cloneが必要になることがすぐわかります。
実は同じような問題が循環参照にも存在しています。それは循環参照もまたエイリアシングの一形態だからです。
「いやいや、循環参照のあるASTなんて作らないよ」と思うかもしれませんが、ユーザーが明示的に作らなくても親方向のリンクと子方向のリンクがあれば自動的に循環参照が発生します。Babelの場合はやや特殊で、NodePathとNodeが分けられているから正確には循環参照にはなっていないのですが、エイリアシングが生じてしまっていることには違いありません。
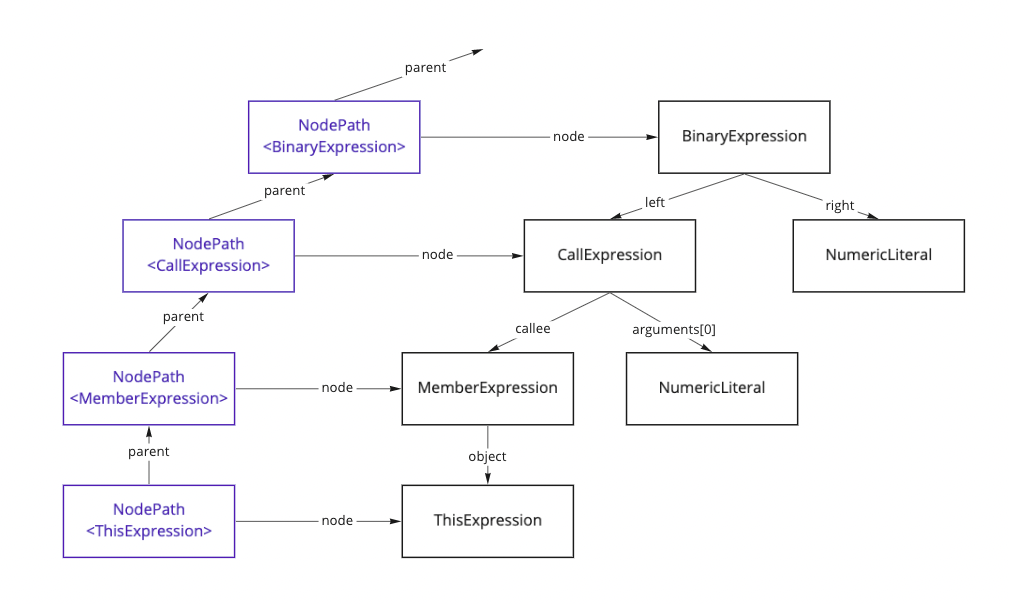
このような理由から、Rustでは木構造に親リンクがない設計が普通です。TypedArenaやWeakなどを使えばできないことはないのですが、SWCはパフォーマンス重視なこともあってかそのような手法は取られておらず、親リンクは存在しません。
実際の書き味の違い
ASTを親方向に辿ることができないので、基本的にはトラバースの段階で下に潜りすぎないことが求められます。
たとえば、ES ModulesをCommonJSに変換する処理を例にとってみます。この変換では、インポート変数への参照をオブジェクトプロパティに置き換える必要があります。
import { x, f } from "mod";
console.log(x);
console.log(f());
// ↓
"use strict";
var _mod = require("mod");
console.log(_mod.x);
console.log((0, _mod.f)());この式の置き換え処理を、Babelは次のように実装しています。
const rewriteReferencesVisitor: Visitor<RewriteReferencesVisitorState> = {
// 変数参照する識別子が来たら呼ばれる
ReferencedIdentifier(path) {
const importData = imported.get(localName);
// 変数名が置換対象のものだった場合
if (importData) {
// 置換するための式を作り、
const ref = buildImportReference(importData, path.node);
// 置き換える。
if (
path.parentPath.isCallExpression({ callee: path.node }) &&
isMemberExpression(ref)
) {
// 関数呼び出しの一部だったらthisを消すために (0, _) を作る
path.replaceWith(sequenceExpression([numericLiteral(0), ref]));
} else {
// 通常ケース
path.replaceWith(ref);
}
}
}
};このように、識別子を見つけてから、それがどのような文脈で使われているのかに応じて処理をしています。
いっぽう、SWCでは次のように実装しています:
impl VisitMut for ModuleRefRewriter {
// 式を見つけた場合
fn visit_mut_expr(&mut self, n: &mut Expr) {
match n {
// その式が変数参照だった場合
Expr::Ident(ref_ident) => {
// さらに、その変数名が置換対象の変数名だった場合
if let Some(expr) = self.map_module_ref_ident(ref_ident) {
// 置き換える
*n = expr;
}
}
_ => n.visit_mut_children_with(self),
};
}
// 関数呼び出しの対象を見つけた場合
fn visit_mut_callee(&mut self, n: &mut Callee) {
match n {
// その式が変数参照だった場合
// (この処理は visit_mut_expr(e) より先に発生する)
Callee::Expr(e) if e.is_ident() => {
// 前処理
let is_indirect_callee = e
.as_ident()
.and_then(|ident| self.import_map.get(&ident.to_id()))
.map(|(_, prop)| prop.is_some())
.unwrap_or_default();
// トラバースを続ける
// (この中で visit_mut_expr(e) が呼ばれる)
e.visit_mut_with(self);
// 後処理
if is_indirect_callee {
// (0, _) が必要なので挿入する
*n = n.take().into_indirect()
}
}
_ => n.visit_mut_children_with(self),
}
}
}置換対象の式自体のノードを見ても (0, _) を挿入するべきか判断がつかないので、それより上のレベルから処理を行っていることがわかります。
Plugin cheatsheet - SWC > Ownership model (of rust) にも例があります。
Visitorの違い
Babel, SWCともに、変換パスがそれぞれに再帰を書かなくていいようにVisitor patternを実装しています。しかしその使い方にはちょっとした差異があります。
Babel (@babel/traverse) のvisitorは再帰処理に対するフックとして実装されています。「ノードに入る瞬間」をあらわすenterイベントと「ノードから出る瞬間」をあらわすexitイベントの2種類のイベントにフックできるようになっています。
{
Identifier: {
enter(path) {
// Identifierに入るときの処理
console.log("Identifier: in");
},
exit(path) {
// Identifierから出るときの処理
console.log("Identifier: out");
},
},
MemberExpression(path) {
// enterイベントの省略形
console.log("MemberExpression");
},
}特定のノードの再帰処理を止めたい場合は、enterイベント内で path.skip() を呼びます。
一方、SWC (swc_ecma_visit) のvisitorは再帰処理中の分岐自体を実装します。デフォルトでは以下のような内容が実装されています。
trait VisitMut {
fn visit_mut_ident(&mut self, n: &mut Ident) {
n.visit_mut_children_with(self);
}
fn visit_mut_callee(&mut self, n: &mut Callee) {
n.visit_mut_children_with(self);
}
fn visit_mut_expr(&mut self, n: &mut Expr) {
n.visit_mut_children_with(self);
}
// ...
}もし上のBabelの例と同じように書きたければ、自分で visit_mut_*_with を書く必要があります。
impl VisitMut for MyVisitor {
fn visit_mut_ident(&mut self, n: &mut Ident) {
// Identに入るときの処理
eprintln!("Identifier: in");
n.visit_mut_children_with(self);
// Identから出るときの処理
eprintln!("Identifier: out");
}
fn visit_mut_member_expr(&mut self, n: &mut MemberExpr) {
eprintln!("MemberExpression");
n.visit_mut_children_with(self);
}
}逆に言えば、 visit_mut_children_with の呼び出しを削除することで、特定ノードの内部の探索を止めることができます。
そのほか @babel/traverse はキューによる訪問優先度管理やNodePathの管理など色々と複雑なことをしていますが、 swc_ecma_visit はシンプルにASTの構造に対する再帰だけを行います。
SWCのVisit/VisitMutはRustコンパイラのvisitorパターンの影響を受けていると推測されます。
変数管理の違い
変数の導入
ASTを加工するときにはしばしば、元のコードにはない新しい変数を導入したくなる場合があります。たとえば以下のコード
console.log(foo?.bar.baz);からoptional chainingを取り除くと、以下のようなコードになります (Babelの出力例):
var _foo;
console.log((_foo = foo) === null || _foo === void 0 ? void 0 : _foo.bar.baz);もし、元のソースでも _foo が使われていたらどうなるでしょうか。
console.log(foo?.bar.baz, _foo);この場合、Babelは衝突を避けて _foo2 を導入します。
var _foo2;
console.log((_foo2 = foo) === null || _foo2 === void 0 ? void 0 : _foo2.bar.baz, _foo);シャドウイング対策
1つのソースコード中に、同名の変数束縛が複数出てくる可能性もあります。たとえば以下の例を考えます。
import { x } from "mod";
console.log(x);
function f(x) {
console.log(x);
}この例でES ModulesをCommonJSに変換する場合、最初の console.log(x) は変換する必要がある一方、2つ目の console.log(x) を変換するとおかしなことになってしまいます。BabelやSWCはこのようなケースも考慮しています。 (Babelでの出力例)
"use strict";
var _mod = require("mod");
console.log(_mod.x);
function f(x) {
console.log(x);
}Babelの変数管理
Babelの変数管理は @babel/traverse によって実装されています。 @babel/traverse は単にASTを走査するだけではなく、スコープの解析も行います。
変数管理の基本単位はスコープ (Scope) です。ひとつのスコープ内では同じ変数名は同名の束縛に解決されます。スコープに存在しない変数名は親スコープにフォールバックします。
スコープはプログラム全体にひとつと、ブロック1つにつきひとつずつ生成されます。他にもcatch節やfunction式などに対しても生成されます。
構文上同一のものとみなせる変数は束縛 (Binding) という単位でまとめられます。多くの場合、束縛にはただひとつの宣言が対応しますが、varやfunctionなどは宣言のマージが可能であるため、ひとつの束縛に複数の宣言が対応する可能性があります。
NodePathオブジェクトに大して path.scope を呼ぶことでスコープを取得し、スコープに対して scope.getBinding(name) を呼ぶことでその位置で解決される束縛を取得することができます。Bindingオブジェクト同士を比較することで、同名変数を間違って書き換える事故を回避することができます。 (例)
また、スコープに対して scope.generateUidIdentifier() を呼ぶことで、そのスコープ内で新規に宣言しても問題ない変数名を生成することができます。第一引数に文字列を渡すと、変数名はその文字列をベースに決定されます。
SWCの変数管理 (1): Rustのマクロ衛生性
SWCでは変数管理のために、Rustコンパイラのマクロ衛生性の仕組みを流用しています。これは変数に対して変数名とは別に番号を振ることで、「変数名 + 番号」で束縛を一意に識別できるようにする仕組みです。
Rustの場合、マクロの呼び出し元と呼び出し側で変数名の衝突を回避するためにこの仕組みが使われています。たとえば、assert_eq! というマクロは以下のように実装されています。 (わかりやすさのために一部改変)
macro_rules! assert_eq {
($left:expr, $right:expr, $($arg:tt)+) => {
// 左辺、右辺を評価
let left_val = &$left;
let right_val = &$right;
if *left_val != *right_val {
// 一致しなかったのでエラーを出す
panic!(
"assertion failed: {:?} != {:?}: {}",
left_val,
right_val,
format_args!($($arg)+),
);
}
}
}このマクロでは不一致時にユーザー定義のメッセージを埋め込むことが可能です。たとえば以下のように書くとどうなるでしょうか。
let left_val = "left";
assert_eq!(42, 100, "left_val = {}", left_val);このマクロを素直に展開すると以下のようになります。
// マクロの外で定義された left_val
let left_val = "left";
// マクロの中で定義された left_val
let left_val = &42;
let right_val = &100;
if *left_val != *right_val {
panic!(
"assertion failed: {:?} != {:?}: {}",
left_val,
right_val,
// この left_val がどちらを指すのかが問題になる
format_args!("left_val = {}", left_val),
);
}展開するとマクロの呼び出し元とマクロ定義内の left_val が衝突してしまいます。しかし、 left_val という名前はマクロの実装詳細にすぎないので、この通りに実行されてしまうのは望ましくありません。
そこで、コンパイラは内部で変数名に番号を足して区別するようになっています。この番号はユーザーには見えませんが、仮想的には以下のようなコードになります
// マクロの外で定義された left_val
let left_val = "left";
// マクロの中で定義された left_val
let left_val#1 = &42;
let right_val#1 = &100;
if *left_val#1 != *right_val#1 {
panic!(
"assertion failed: {:?} != {:?}: {}",
left_val#1,
right_val#1,
// この left_val がどちらを指すのかが問題になる
format_args!("left_val = {}", left_val),
);
}上の擬似コードで #1 と表記したものはコンパイラが内部的に生成するMarkと呼ばれるIDです。Markはマクロが1回呼ばれるたびに1つ生成されます。
マクロが展開される前に、マクロ定義側のトークンにMarkが付加されます。もしマクロが二重になっている場合は、Markは複数個足され foo#1#2#3 のようになっていきます。
実際に Vec<Mark> のまま識別子を管理するのはコストがかかるため、 Vec<Mark> を一意に識別するためのIDをさらに生成します。これがSyntaxContextです。Rustの場合は変数名とSyntaxContextの対によって変数を区別することになります。
SWCの変数管理 (2) 変換パスによる変数名の導入
このRustのマクロ衛生性のための仕組みがSWCにも流用されており、名前もそのままMark / SyntaxContextです。SWCではこれを2つの目的で使っています。
- 変換パスによる変数名の導入
- シャドウイング対策
まずは変数名の導入についてです。JavaScriptにはマクロはありませんが、BabelやSWCのようなトランスパイラの変換パスはソースファイル全体を引数にとる手続きマクロのようなものだとみなせます。
expand_optional_chain! {
console.log(foo?.bar.baz);
}つまり、マクロ側で生成する識別子に適切なMarkを付与することで、変数名の衝突を避けることができます。具体的には以下のように書くことができます。
let ident = private_ident!("tmp");
// または: Ident::new("tmp".into(), DUMMY_SP.apply_mark(Mark::new())
let ident = private_ident!(span, "tmp");
// または: Ident::new("tmp".into(), span.apply_mark(Mark::new())Markを作るときは、親となるMarkを指定することもできます。これはマクロがネストしたときの親スコープを管理する必要があるRustコンパイラには必要ですが、SWCでは特に気にする必要はなさそうです。
SWCの変数管理 (3) シャドウイング対策
次にシャドウイング対策についてです。SWCではシャドウイング対策でもMark/SyntaxContextを使います。 (Rustコンパイラではこのような使い方はせず、HIR loweringで各束縛にグローバル一意なIDを振ることでスコープの問題を解決します)
SWCのパーサー実装である swc_ecma_parser はMark/SyntaxContextを付与しませんが、生成されたASTは変換パスに通される前に swc_ecma_transforms_base 内のresolverによる前処理を受けます。ここでスコープごとにMarkが生成され、宣言されたスコープに合わせて各変数にMarkが付与されます。
そのため、SWCの変換パスは同名変数が区別されている前提のもとで処理を行うことができます。とはいっても変数名 (文字列) をそのまま使っては意味がありません。 Ident構造体の to_id メソッドの戻り値を使うことで、変数を区別することができます。
SWCの変数管理 (4) 出力
この段階で同名変数は内部的には区別されていますが、そのまま出力するとその区別は失われてしまいます。そこで変換後のASTは出力前にswc_ecma_transforms_base 内のhygieneパスによる後処理を受けます。このhygieneパスはMark/SyntaxContextの情報に基づいて変数名を適切にリネームします。
SWCの変数管理についてはPlugin cheatsheet - SWC > Alternatives for babel APIs > generateUidIdentifier にも説明があります。
コメント処理の違い
Babel/SWCは基本的に機械可読なJavaScriptを出力できれば十分であるため、一見するとコメントを維持する必要はないように思えるかもしれません。しかし実際には、以下のように出力中のコメントが重要になる事例も存在します。
- ライセンス表記
- tree-shakingのためのヒントとしての `/*#__PURE__*/` コメント
- Webpackのimportメタデータ (`await import(/* ... */ "module")`)
そこでBabel/SWCともにコメントを扱うための機構が存在しますが、ここにも違いが存在します。
BabelはコメントをASTのノードメタデータとして扱います。ノードオブジェクトそのものに leadingComments / trailingComments の情報が含まれています。
// コメントを出力
console.log(node.leadingComments);
// コメントを追加
t.addComment(node, "leading", "Hello!");いっぽう、SWCではコメントをソースコード中の位置に紐付けます。位置とコメントの対応関係はASTとは独立したCommentsストアに含まれます。
プラグインの場合、ASTはプラグインの実行時にまとめて渡されますが、コメントの情報は対話的に取得します。
// コメントを出力 (comments: C は C: Comments を満たす)
// プラグインの場合はホストとの通信が発生する
comments.get_leading(node.span.lo());
// コメントを追加
// プラグインの場合はホストとの通信が発生する
comments.add_leading(node.span.lo(), Comment {
kind: CommentKind::Block,
span: DUMMY_SP,
text: "Hello!".into(),
});leading commentsではなくtrailing commentsを取得する場合は、ノードの末尾位置 (node.span.hi()) に対して取得を行います。
まとめ
SWCは機能的にはBabelの代替を目指す一方で、パフォーマンスにものすごく気を遣って実装されています。プラグインシステムにも様々な点で工夫がほどこされています。
- プラグインはWASMで実装され、通信ボトルネックの解消のためにrkyvによるzero-cost deserializationとメモリコピーによるデータの受け渡しが採用されている。
- 一方でアクセス頻度の低いコメントなどの情報は対話的に取得する形になっている。
- ASTはRustのデフォルトのデータ構造 (循環参照や共有部分を持てない) として実装されている。
- 変数名の衝突回避のために、Rustのマクロ衛生性のための仕組みを流用している。これにより個々の変換プラグインは変数名の衝突回避のためのスコープ走査を行わなくて済むようになっている。
SWCのプラグインを書く場合は、こういった事情からBabelのプラグインとは書き味が違うことを理解しておくと正確なプラグインを書きやすくなるでしょう。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


