
WantedlyでAndroidアプリの開発を主にしている住友です。最近グロースハック始めました。
単にプロダクトを作ってリリースしても自然とユーザーが付いて使い続けてくれることは稀です。どうすればプロダクトの良いところを知ってもらえるか、プロダクトを使い続けてくれるかを試行錯誤し、改善サイクルを繰り返すことで初めてユーザーさんが定着し、使い続けてくれるようになります。
Wantedlyは最近でこそデータに基づいたアプローチを行うようになりましたが、それまでには沢山の苦労と試行錯誤がありました。今回はそこまで辿り着くまでに何を行ってきたかのお話です。
ログを探して
プロダクトを改善したと思っても、改善の成否の指標が無ければ判断できません。そしてログが無ければ指標も作れません。
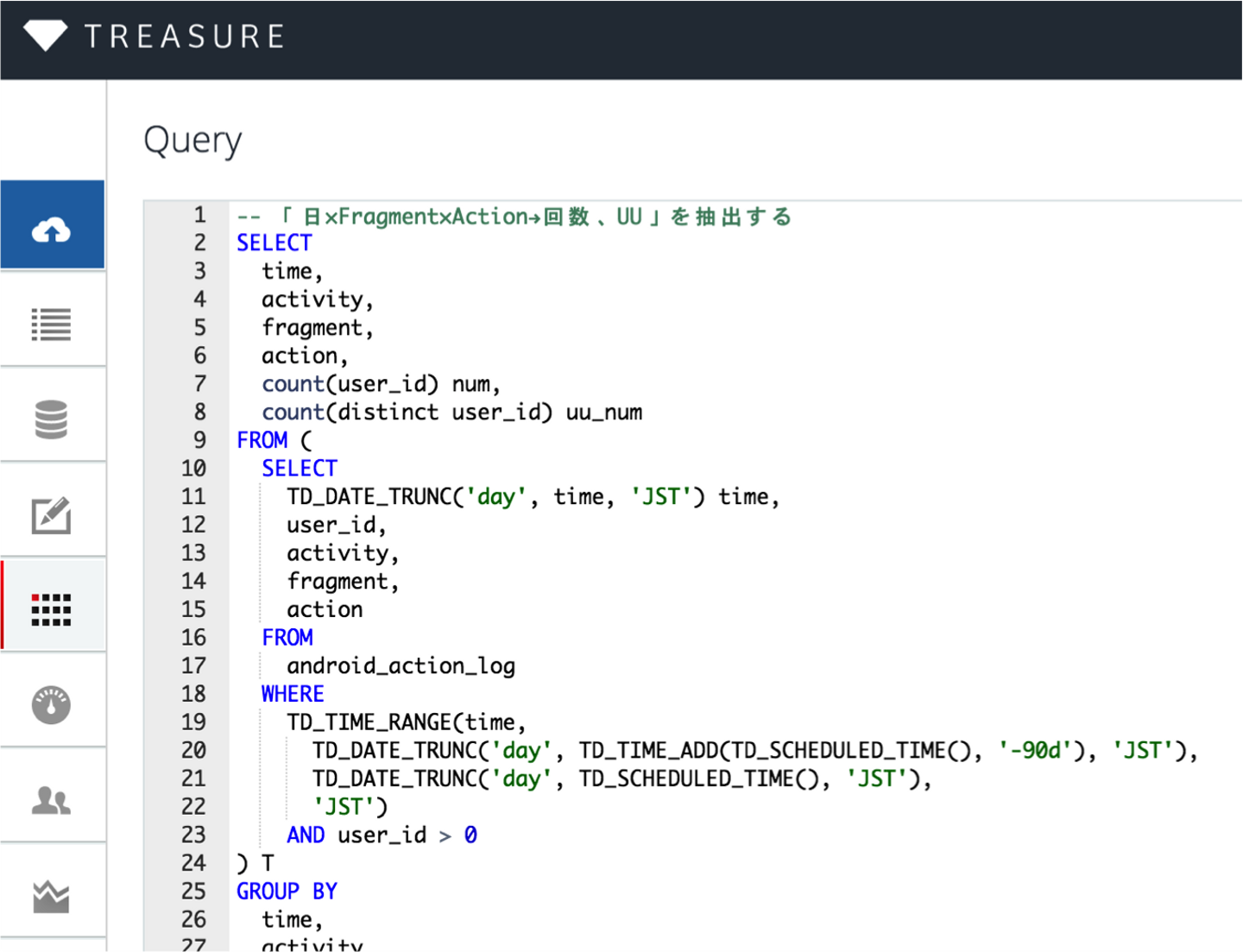
WantedlyではWeb側のログは全てTreasure Dataというクラウド型データマネージメントサービスに集めています。そこではHiveQLというSQLライクなクエリーを発行することでログから情報を抽出することができます。
最初はTreasure Dataを使えば指標に必要な情報が全て得られると考えていましたが、そう甘くはありませんでした。Web側のログからはアプリからのリクエスト程度の情報しか得ることができず、アプリ上での操作を知ることはできないからです。
指標としてよく使う情報には、閲覧回数や滞在時間といった画面に関するログと、ユーザーの操作に関するアクション(イベント)のログの2つを考えました。アプリにこれらのログを取得する処理を埋め込むようにしました。
Androidの場合、一見は単純にActivityやFragmentのonResume/onPauseを追えば画面のログは得られるように考えられます。しかし、単一のActivityの画面、単一のActivityに単一のFragmentの画面、単一のActivityに複数のFragmentの画面などの複数の実装パターンがあり、一筋縄では行きませんでした。結局、複雑な構成になっている箇所は一括して取得することは難しいと判断したため、個別に泥臭く実装することに行き着きました。
これら試行錯誤によりやっと改善の成否の指標となるログが得られるようになりました。
ログの可視化
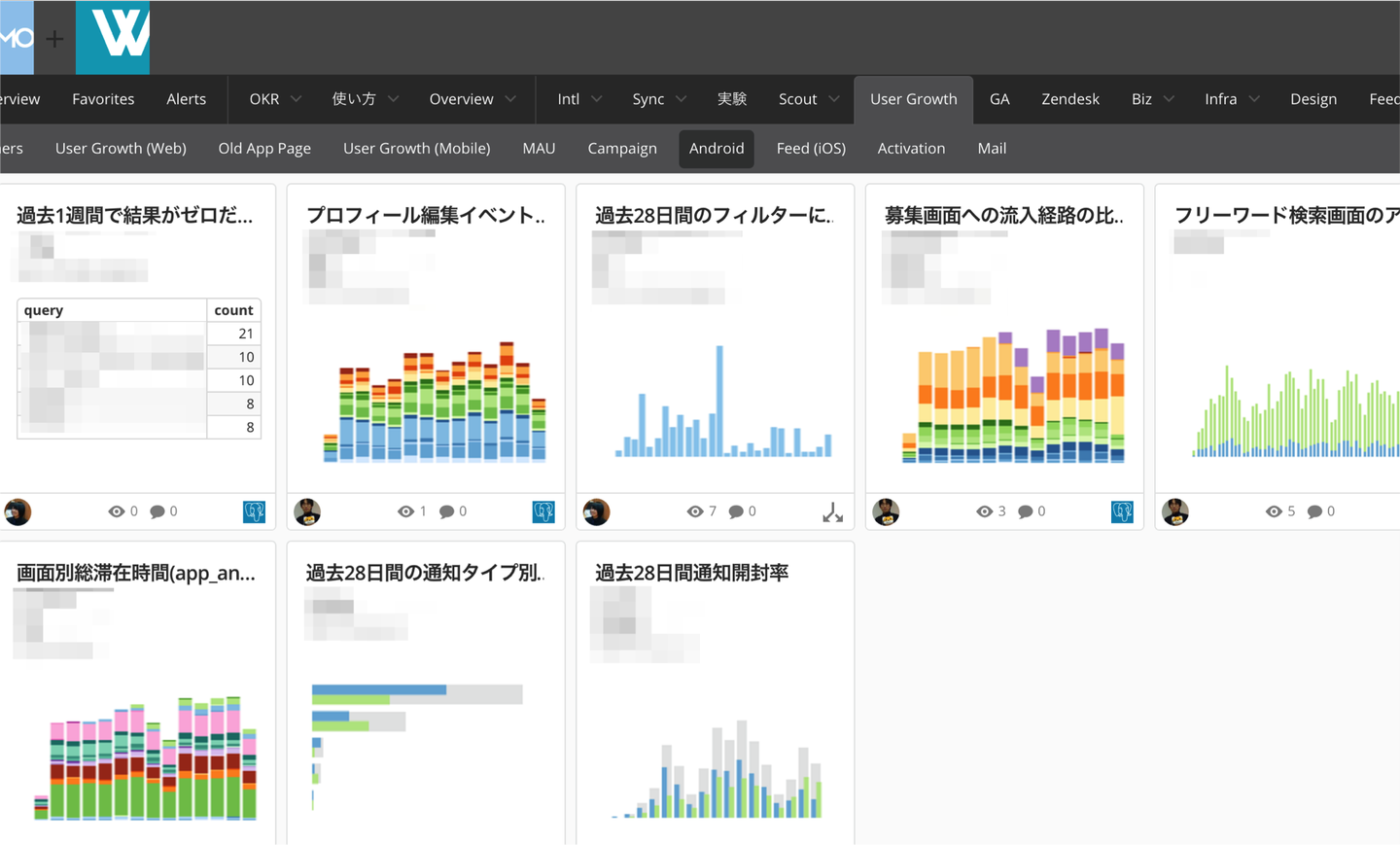
ログが取れるようになったらそれを可視化します。暗算が得意な方はCSVファイルから数値を読み取って判断できると思うのですが、私にはそれはできないのでグラフという形で可視化します。
Treasure DataにHiveQLを発行し、結果をCSVファイルとしてダウンロードし、それをMicrosoft Excelを用いてグラフやピボットテーブルで読めるようにします。ちなみにExcelの性能は凄いもので数十万レコードあっても捌いてくれます。
ここで一つ課題があります。この作業は地味に時間掛かり面倒くさいです。クエリーを設定しておけば日次で実行され、結果をグラフとしていつでも見れるところまで自動化しておきたいものです。この課題に対しWantedlyではDomoというビジネス管理プラットフォームを導入しました。DomoにはTreasure Dataや各種RDBMS、Googleスプレッドシートなどの情報を集約して可視化できる機能があります。この機能を用いて様々な指標をいつでもWebブラウザ上で閲覧できるようにしてこの課題を解決しました。
品質を確保するには
ログが取れ、可視化できるようになり、やっと改善サイクルを回せるようになりました。グロースハックの一つ一つの施策が成功する確率は低く、20%とも10%とも言われます。アプリを早く改善するためには改善サイクルを早く回すことが重要になってきます。
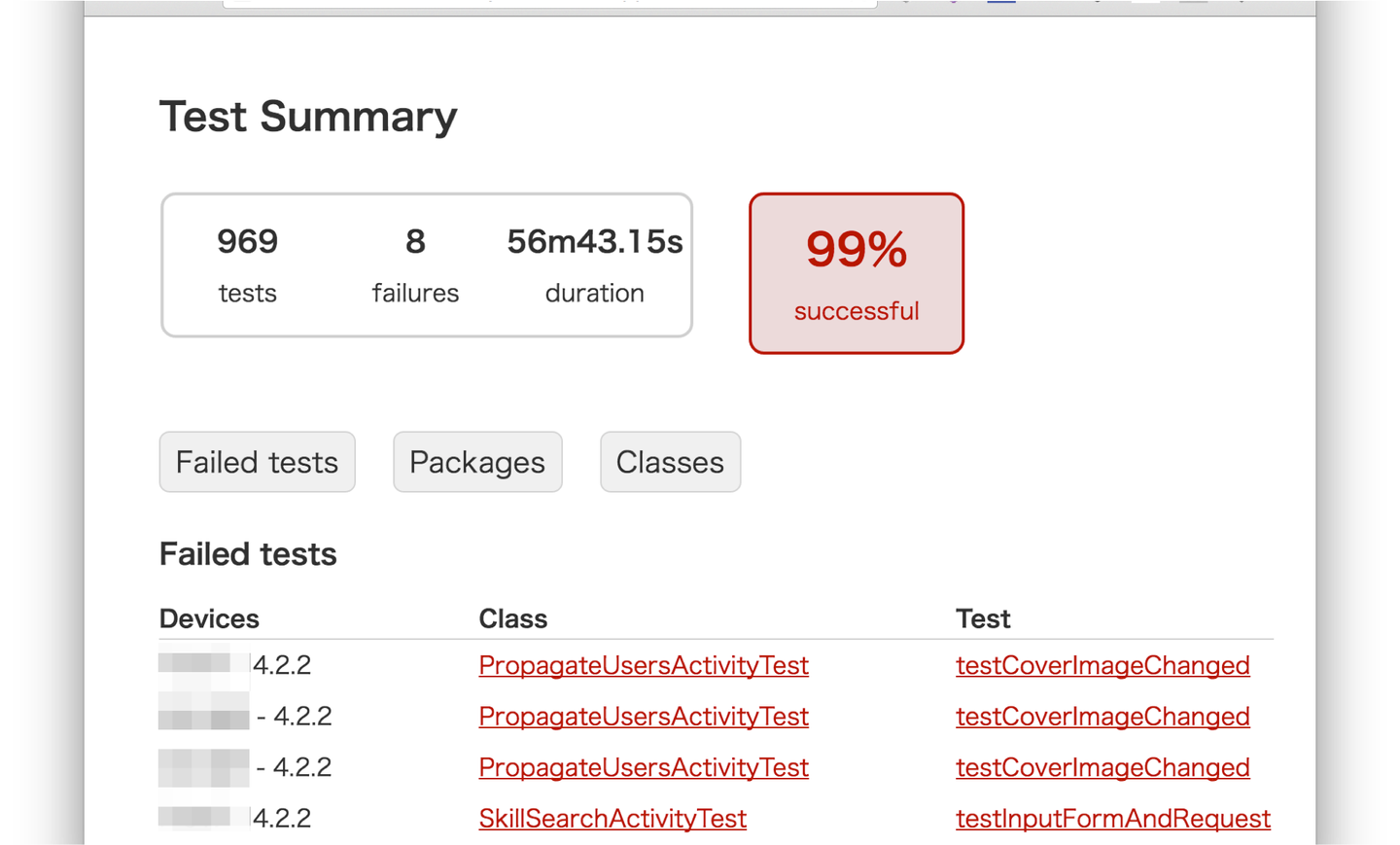
ここでまた課題です。改善サイクルを早くすることは1回のアプリのリリースに掛かる時間が短くなることを意味しており、品質の確保に影響がでるようになります。単純に品質の確保をするにはテストシートを作成し、十分な時間を掛けてテストすれば良いですがそれでは時間が掛かり過ぎます。この課題にはテストコードを書き、自動化することで対応しました。AndroidではJUnitによるロジック周りのテストだけでなく、EspressoによるUI周りのテストを行うようにしました。現在は社内にJenkinsを立て、そこに実機を複数台ぶら下げてテストを走らせるようにしています。
テストコードも一言で書いたといえば簡単なのですが、実際のところはアプリ側もテスタブルな設計になるようにかなり改修しました。Activity、Fragment、Adapter、通信処理、データクラスなどが密結合している場合、テストコードが書きにくくなったり可読性が悪くなったりします。さらにちょっとした修正がテストコードの本質と関係ないところでfailするようになります。このようなことが起こらないようにDependency InjectionとしてDagger2や独自DIを適用できるように改修しました。
全てを自動化できればそれに越したことは無いのですが、やはり限界はあります。特にコンバージョンに関わるところについては人の手で動作確認を行い、たとえテストコード漏れがあってもユーザー様の手元で致命的な問題が起こらないようにしています。
まとめ
今回の話ではいろいろな試行錯誤や苦労をご紹介しました。しかし、ここまではまだ準備段階に過ぎません。改善サイクルはこれから回して行きます。その中では新たな課題がでてくると思います。その苦労と試行錯誤はまたこのブログでご報告できればと思います。
全ての人がココロオドル仕事と巡り会えるために。

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


