こんにちは、Wantedly の Infrastructure Team で Engineer をしている南( @south37 )です。
今日は、WANTEDLY TECH BOOK 5 から「巨大企業による分散データベース技術の発展」という章を抜粋して Blog にします。
「WANTEDLY TECH BOOK 1-7を一挙大公開」でも書いた通り、Wantedly では WANTEDLY TECH BOOK のうち最新版を除いた電子版を無料で配布する事にしました。Wantedly Engineer Blogでも過去記事の内容を順次公開予定であり、この Blog もその一環となっています。
以下、「WANTEDLY TECH BOOK 5 - 巨大企業による分散データベース技術の発展」の内容です。
はじめに 皆さんは「分散データベース技術」というものにどのくらい関心があるでしょうか?もしかするとそれほど興味は無いかもしれません。ただし、サービスが成長して扱うデータ量が増え続ければ、その技術は無視できない存在となるはずです。
少し歴史を振り返ってみましょう。1990年に World Wide Web が登場して以来、インターネット上でやりとりされるデータ量は爆発的に増大してきました。Google や Amazon といった地球規模のインターネットサービスを提供する企業が現れ、その巨大なデータ量を扱う為に Bigtable や Dynamo といった分散データベースが生まれました。その技術は論文として公開され、世界に大きなインパクトを与えました。また、その技術を参考にして Cassandra や HBase のような優れた分散データベース実装が登場しました。さらに近年では、分散データベースは GCP の Cloud Bigtable や Cloud Spanner、あるいは AWS の DynamoDB のようにクラウド上のマネージドサービスとして提供され、より簡単に利用できるものになりました。
分散データベース技術を利用するハードルが下がる一方で、その重要性は増しています。なぜなら、世界中でデータは増え続けており、インターネット上で提供されるサービスはより一層巨大になっているからです。サービスが成長してデータが増える、あるいは世界中のユーザーにサービスを提供するようになると、1台のマシンで動かすデータベースには限界が来ます。そんなとき、分散データベース技術が必要になるはずです。
幸い、現代に生きる私たちは優れたオープンソース実装やクラウドサービスを利用できます。Google や Amazon のように自分たちでゼロから実装する必要はありません。一方で、既存の分散データベースの内部実装や特性を把握していなければ、最適な技術選定は出来ないはずです。あるいは、既存の分散データベース実装やクラウドサービスでは自分たちのニーズを満たすことが出来ず、新しく分散データベースを作ることがあるかもしれません。そんなときにも、既存の分散データベース技術の知識が役に立つはずです。
本稿では、分散データベース技術について、特に「地球規模のインターネットサービスを提供する巨大企業による技術発展」という観点から、ご紹介したいと思います。トピックは以下になります。順に見ていきましょう。
Bigtable と Dynamo の登場 オープンソースの分散データベース クラウドサービスの分散データベース ユースケースに合わせた独自実装の分散データベース まとめ 1. Bigtable と Dynamo の登場 地球規模のインターネットサービスの第一人者といえば、Google でしょう。Google は、汎用コンピュータのクラスターを利用して大量の構造化データを低 latency で扱う為に、 Bigtable という分散データベースを生み出し、2006年に発表しました[1] 。
一方、Amazon は極めて高い availability を実現する為に、 Dynamo という分散 Key-value store を生み出し、2007年に発表しました[2] 。Consistency を多少犠牲にしてでも availability を高めるというアプローチは衝撃的で、大きなインパクトを与えました。
Bigtable と Dynamo のアイディアは、現在のさまざまな分散データベース実装に取り入れられてます。ベース技術といってもよいでしょう。この2つの分散データベース実装について概観することで、分散データベースに対する理解を深めたいと思います。
1-1. Google による Bigtable(2006)の登場 Bigtable は、Google が 2004 年から開発し、 2006年の論文 で公開された分散データベースです。
Bigtable は、次のような特徴を持ちます。
Google File System や Chubby など「Google の社内システム」を利用 Master をもつアーキテクチャ 行キー、列キー、列ファミリを利用して構造化データを保持できる Wide column store というデータモデル memtable や Sorted String Table(SSTable)という書き込みとシーケンシャルな読み込みに強いデータ構造 順に説明します。
1-1-1. Google File System や Chubby など「Google の社内システム」を利用
Bigtable は、Google の社内システムである Google File System や Chubby に依存した設計になっています。
Google File System は、Scalable な Google 製の分散ファイルシステムです。巨大なデータを chunk に分割して cluster に保存し、replication によって高い availability や durability を実現します。BigTable は Google File System の上に作られているため、replication は Google File System に任せて、データの分割やデータの読み書きだけに集中するアーキテクチャになっています。
Chubby は分散ロックサービスで、分散システムにおけるサーバー間の協調動作のために Google のシステムから利用されています。ファイルシステムに似た API を提供しており、「最初に特定のディレクトリ直下のファイル作成に成功したものを採用」することでリーダー選出に利用したり、リソースのロックに利用したり、メタデータの保存に利用したりできます。Chubby は5台のマシンから構成されており、データを replication することで availability を高めています。Chubby 内では、Paxos と呼ばれる分散合意アルゴリズムが利用されています。Chubby について気になった方は、 論文も参照してみてください[1] 。Bigtable からは、Chubby はメタデータの保存やロックの獲得などに利用されています。
1-1-2. Master をもつアーキテクチャ
Bigtable は複数 node からなる cluster 上で動作します。node には、1つの Master server と複数の Tablet server が存在します。この2種類の server は違う役割を持っています。
Bigtable 上のテーブルのデータは Tablet と呼ばれる単位で分割され、Tablet server へ割り振られます。この割り振りを管理するのが Master server の役目です。また、Tablet server の死活情報などその他の cluster のメタ情報も Master が管理しています。
Tablet server は Tablet へのデータの読み書きを担当します。Bigtable に対して接続するクライアントは、実際にデータを読み書きする際は Tablet server とやりとりを行います。Tablet server はデータの増大に応じて増やせる仕組みになっているので、Bigtable は全体としてスケーラブルな分散データベースとなっています。
1-1-3. 行キー、列キー、列ファミリを利用して構造化データを保持できる Wide column store というデータモデル
Bigtable は、発表された論文が「 Bigtable: A Distributed Structured Storage System 」というタイトルであることからも分かるように、構造化データを保持できるデータモデルとなっています。
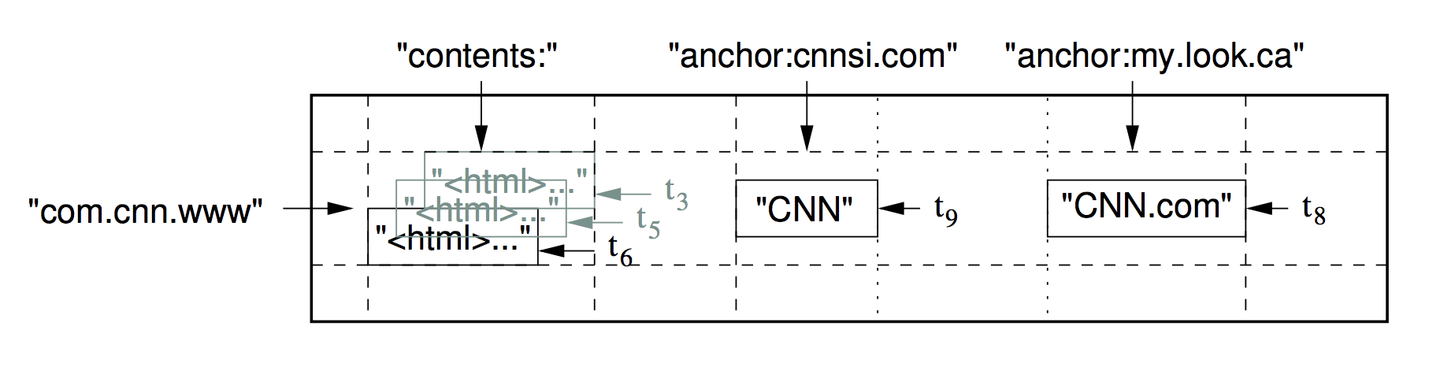
ただし、リレーショナルモデルやドキュメントモデルとは違い、行キーおよび列キーによってデータの場所を示し、timestamp によってデータの version を指定できる Wide column store となっています。
[Bigtable のデータモデル。行キーである "com.cnn.www" と、列キーである "contents:" や "anchor:cnnsi.com" の組み合わせでデータを指定。データは timestamp 付きの複数 version が存在する。 "A Distributed Storage System for Structured Data" p2より引用]
Bigtable においては、複数の列のうち、同時に利用したいデータは「列ファミリ」としてまとめておくことが推奨されています。ストレージへは列ファミリごとにまとまった構造で保存されるため、同時に利用するデータの locality を高めてアクセスを効率化できるからです。
また、Bigtable では行単位の書き込みに対する atomicity を保証している為、atomic な transaction は関連データを1行にまとめることで実現します。RDB における transaction とは違う考え方になるので、気をつける必要があります。
Bigtable のデータモデルは RDB とは大きく違う一方で、Cassandra や HBase など同じデータモデルを採用する実装は数多くあります。覚えておいて損は無いでしょう。
1-1-4. memtable や Sorted String Table(SSTable)という 書き込みとシーケンシャルな読み込みに強いデータ構造
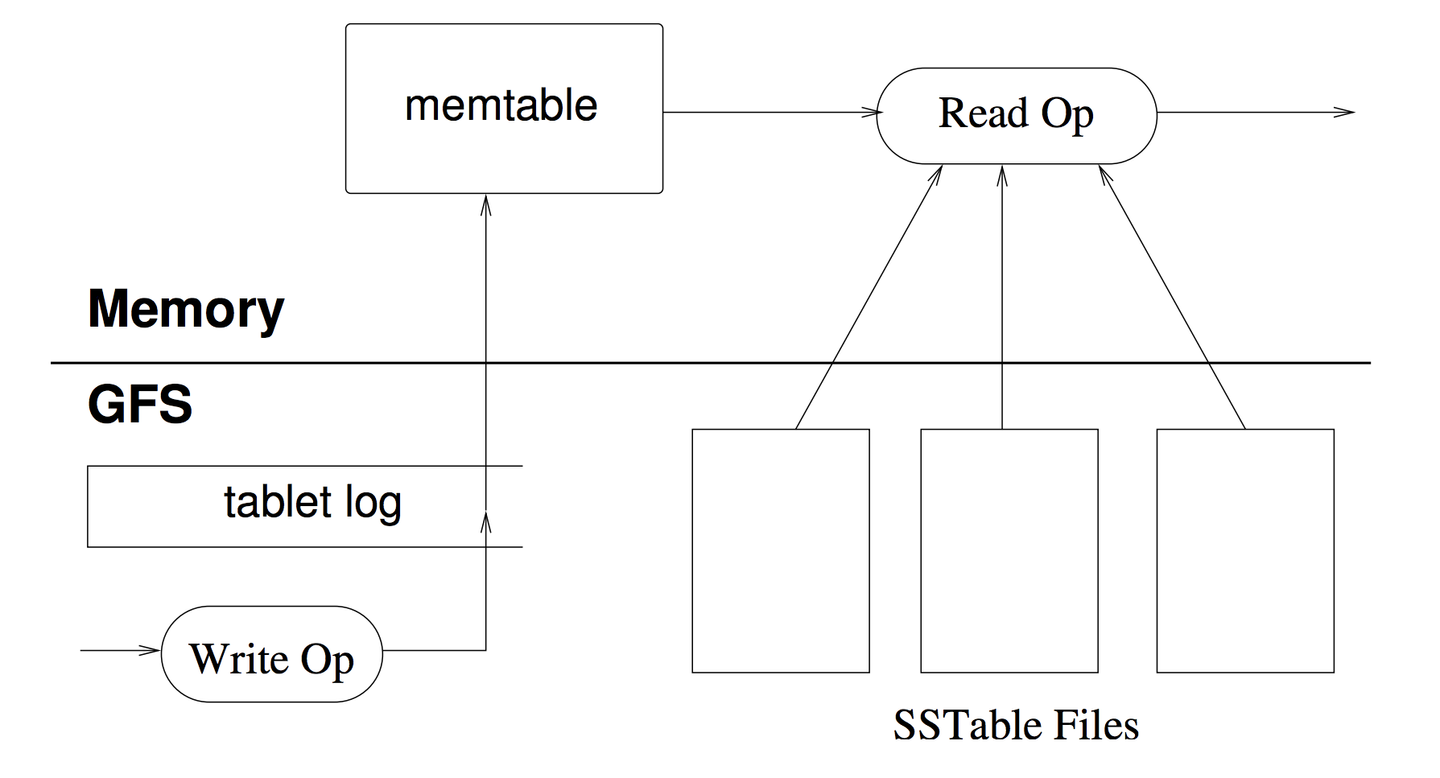
Bigtable の内部実装に目を向けると、Tablet への読み書きの際は memtable と SSTable と呼ばれるデータ構造が利用されます。memtable はメモリ上の書き換え可能な小さなテーブルで、行キーで sort した状態でデータを保持します。SSTable は Google File System へ永続化された読み込み専用のデータ構造で、こちらも行キーで sort した状態でデータを保持します。また、durability を実現するための commit log (RDB の WAL のようなもの)も存在します。commit log も Google File System で永続化されています。これらを組み合わせて、どうやって書き込みと読み込みが実現されているかを見てみましょう。
[memtable と SSTable の模式図。 "A Distributed Storage System for Structured Data" p6より引用]
データが書き込まれる際は memtable に insert が行われます。そのとき、commit log へもデータを追記しておくことで server が down した場合でもデータが失われない様にします(durability の実現)。データが書き込まれ続けると memtable のサイズが大きくなり、ある閾値を超えるとマイナーコンパクションと呼ばる処理が行われます。マイナーコンパクションでは、memtable の内容を SSTable へ書き出し、新しい memtable を作成します。また、commit log の内容も clear します。これによって、memtable や commit log を一定サイズ以下に抑えることができます。マイナーコンパクションがしばらく続くと SSTable が増えてきます。そこで、バックグラウンドでマージングコンパクションを行うことによって、 SSTable の数を一定数以下に抑えます。マージングコンパクションでは、いくつかの SSTable と memtable の内容を読み取り、結果を merge して新しい SSTable を作成します。古い SSTable と memtable は捨て去られることで、全体として SSTable の数を減らすことができます。さらに、全ての SSTable を1つの SSTable へ merge するメジャーコンパクションと呼ばれる処理も存在します。メジャーコンパクションは定期的に実行されて、削除済みのデータなどを完全に消し去ります。
このように、書き込みは memtable, SSTable それぞれに対して行キーで sort 済みの状態を作りながら実行されます。次は読み込みの際の挙動を見てみましょう。
読み込みの際は、memtable と SSTable の中から指定された行キーのデータを探索します。どちらも行キーで sort 済みである為、探索は効率的に行うことができます。また、「読み込んだ SSTable の cache」や「Google File System から読み込んだ Block 単位の cache」、さらに「Bloom filter を利用して読み込み対象の SSTable 絞り込み」を行うことで、読み込みを高速化しています。
以上が Bigtable における Tablet への読み書きの内部実装です。この実装は、「書き込みやシーケンシャルな読み込みが高速」という特徴を持ちます。書き込みの際は、ボトルネックである Google File System へのアクセスは基本的に commit log への書き込みだけです。読み込みの際も、シーケンシャルな読み込みであればソート済みデータ構造や block cache が効いてきます。逆に、ランダム読み込みは遅いというのが注意すべきポイントです。
コラム: memtable と SSTable という優れたアイディア
memtable と SSTable というアイディアはさまざまなデータベース実装にも広まっています。特に興味深いのは LevelDB で、これは Bigtable 作者である Jeff Dean 本人が chrome の IndexedDB の為に「高速な組み込みデータベース」として実装したものといわれています [3] [4] 。LevelDB は memtable と SSTable を利用することで、SQLite よりも高速な書き込み性能とシーケンシャル読み込み性能を獲得しています。LevelDB はその後、 Facebook による RocksDB 実装 へと繋がり、 Facebook の MySQL の storarge engine を置き換えるにまで至ります[5] 。優れたアイディアや実装が広く利用される様になり、世界を進歩させていると考えるとワクワクしますね。
1-1-5. Bigtable まとめ
以上、Bigtable の概観でした。さらに詳細が気になった方は、 技術評論社の「Google を支える技術」[6] や Google の発表した Bigtable 論文[1] を参照してみてください。きっと理解に役立つと思います。なお、第4章では Bigtable をクラウドサービス化した Cloud Bigtable について触れますが、こちらも公式ドキュメントがかなり充実していますので、ぜひ参照してみてください。
1-2. Dynamo(2007)by Amazon 次に、Amazon が開発した Dynamo という分散データベースの特徴を見てみましょう。Dynamo は、availability を重視した decentralized な分散 Key-value store で、 2007 年に「Dynamo: Amazon’s Highly Available Key-value Store」という論文で公表されました[2] 。Dynamo は次のような特徴を持っています。
Master がいない decentralized なアーキテクチャ 全ての node が共通の機能をもつ(Server symmetry)。単一障害点が無く、高い availability を実現。 Consistent hashing を利用した partitioning Successor node への replication Gossip protocol による membership 管理 設定可能な consistency Hinted handoff Vector clock Anti-entropy Read-repair Simple な Key-value store Persistent engine は選択可能。Barkley DB などが利用される。 順に見てみましょう。
1-2-1. Master がいない decentralized なアーキテクチャ
Dynamo は、Master がおらず decentralized なアーキテクチャとなっています。cluster を構成する node は全て共通の機能を持っており、Master 無しで協調的に動作します。Master を持たないことで SPOF を無くし、availability を上げています。また、node を追加することで簡単に scale out できる様にしています。
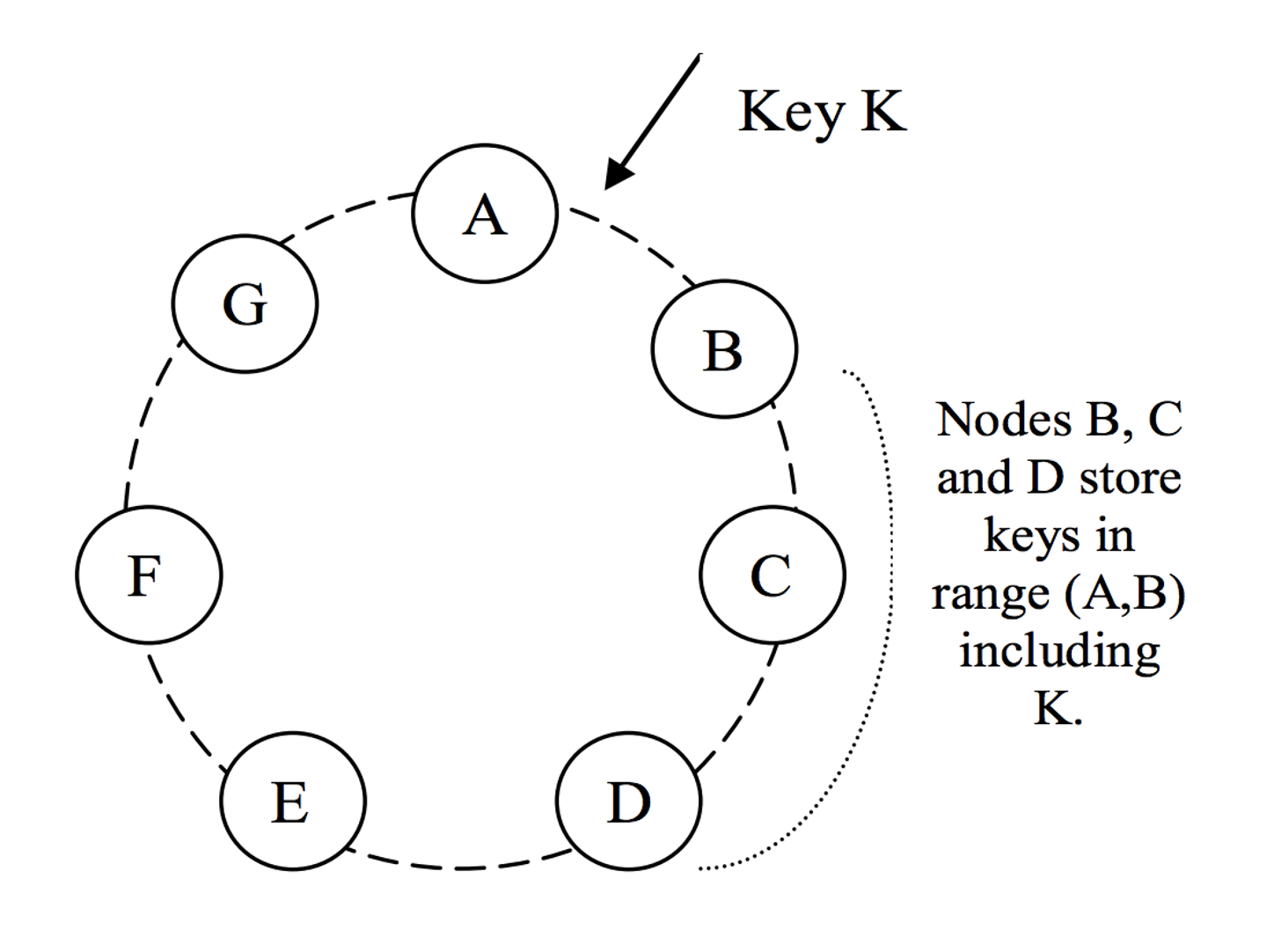
paritioning には Consistent hashing を利用しており、key の値から「どの node が対象 key のデータを保持するか」が分かる様になっています。Consistent hashing というのは「hash 値を ring 状に並べて、区間ごとに特定の node に割り当てる」アルゴリズムです。node を追加した時に、再割り当てされる key の数を小さく抑えられることが特徴です。
replication は、ring 状の並びの node に対して行われます。replication 数 N は設定可能ですが、多くの場合には N=3 が使われます。key ごとに replication 対象の node は決まっており、それは preference list と呼ばれる list で管理されます。node の故障に備えて、preference list には N より多くの node が登録されます。
[Dynamo の partitioning と replication の模式図。"Dynamo: Amazon’s Highly Available Key-value Store" p5より引用]
node の membership 情報は、Gossip protocol と呼ばれるアルゴリズムで eventually に伝達されます。毎秒ランダムに選ばれた2つの node 同士が情報を交換することで、membership 情報が更新されます。
node の障害検知は、各 node が別の node へ request を送った際に、応答を返すかどうかで行われます。応答を返さない場合は障害が起きたと判定しますが、availability を損ねない為にさらに別の node へ request を送って処理を継続します。
1-2-2. 設定可能な consistency
Dynamo では、replication 数 N に対して、R と W という設定値を持っています。replication される N 個の node のうち、R は read 時に応答を待つ node 数、W は write 時に応答を待つ node 数です。この N, R, W が設定できることで、availability や latency, consistency のバランスを調整できるようになっています。
R や W を小さく抑えると、応答を返さない node がいても処理を継続できるため availability が上がります。その代わりに、replication は background で行われるため eventually consistency となります。
1-2-3. Hinted handoff
また、node に障害があった場合にはその node A を skip して別の node B に「A に障害があった」という情報を持たせます。これは Hinted handoff と呼ばれています。node A が復旧すると node B が預かっていた情報は node A に渡されます。
1-2-4. Vector clock
Dynamo は書き込みの際に conflict が起きることを許容しており、その際の解決策として Vector clock という機構を用意しています。これは、version の分岐の情報を保持するデータ構造で、client がその情報を読み取って conflict を解決できる様にしています。
1-2-5. Anti-entropy
また、replication が非同期で行われることを許容している為、node が障害などによって古い version のデータを持っている場合もあります。これを修正する機構として、Anti-entropy と呼ばれるデータ同期機構も用意しています。
1-2-6. Read-repair
さらに、client が read を行なった際、R 個の node の response を待って client への返答を行なった後、少し他の node の response を待ち、古い response が返ってきたらその node のデータを新しいものに更新するという動作もします。これは Read-repair と呼ばれており、Anti-entropy と共にデータ同期機構を提供しています。
1-2-7. simple な Key-value store
Dynamo は、論文中では Key-value store だと紹介されています。また、persistent engine として、Berkeley DB などの既存のデータベース実装を利用している様でした。
1-2-8. Dynamo まとめ
以上、Dynamo の概観でした。高い availability を実現する為に、Dynamo はさまざまなアイディアを利用しています。特に、Masterless なアーキテクチャ、更新の衝突を許容して read 時に解決するというアイディアは特徴的です。興味を持った方は、ぜひ Amazon による論文[2] を参照してみてください。
コラム: Dynamo と DynamoDB は違うもの
Amazon が 2007 年に論文で発表した分散データベース Dynamo と、AWS が 2012 年からクラウドサービスとして提供するようになった DynamoDB は、名前は似ていますが違うものです。Dynamo が単純な key-value store だったのに対して、DynamoDB のデータモデルはドキュメント指向となっています。また、ストリームやトリガーなどの便利な機能も用意されています。ただし、 DynamoDB を紹介した Amazon CTO のブログでは、DynamoDB は Dynamo の主要な原則にのっとって作られていると紹介されています[7] 。DynamoDB は、 Dynamo の正当な後継といえるでしょう。
2. オープンソースの分散データベース実装 Bigtable や Dynamo の登場は、さまざまなオープンソースの分散データベース実装に繋がりました。 Facebook の Cassandra 、 Twitter の FlockDB 、 Linkedin の Voldemort 、 Powerset の HBase など、巨大なデータを扱う企業が自分たちのニーズを満たす為に分散データベースを作成し、オープンソースとして公開しました。また、これらのオープンソース実装は、巨大企業がシステムを作る際の選択肢にもなりました。巨大企業が利用することでオープンソースの分散データベース実装は進化し、今日では、HBase は Facebook や LINE、Airbnb などに、Cassandra は Netflix や Uber などに利用されています。
オープンソースの分散データベースデータベース実装のうち、特にメジャーなのは HBase と Cassandra だと思います。ここでは HBase と Cassandra に絞ってその特徴を見てみます。
2-1. HBase(2007)by Powerset HBase は Bigtable のクローン実装です。 2007年に Powerset で作成され、Apache へ寄贈されました 。Bigtable が Google File System と Chubby に依存した設計になっているように、HBase は同じ Apache プロジェクトの Hadoop Distributed File System(HDFS) と ZooKeeper に依存した設計になっています。HDFS は Google File System のクローン実装で、分散ファイルシステムです。Zookeeper は Chubby のクローン実装で、分散ロックサービスです。Google の一連のプロダクトが、オープンソースのクローン実装として用意されています。
HBase は Bigtable のクローン実装であるため、Bigtable の特徴をほぼそのまま受け継いでいます。データモデルは Wide column store ですし、内部では Bigtable の「memtable と SSTable」に対応する「MemStore と HFile」というデータ構造を利用しています。
HBase は次のように、多くの企業に利用されています。
ユースケースを見てみると、Messaging Platform の構築に利用されたり、Hadoop や Spark と組み合わせて解析的な用途で利用されることが多いようです。「書き込み」と「シーケンシャルな読み込み」に強いアーキテクチャであるという特徴や、強い一貫性を持つという特徴が、存分に活かされていることが分かります。
2-2. Cassandra(2008)by Facebook Cassandra は、 Facebook が inbox search を構築するために作成し、2008年にオープンソースとして公開されました[13] 。Cassandra は 「Cassandra: Daughter of Dynamo and Bigtable」というブログポストがある[14] ことからも分かるように、多くの性質を Dynamo と Bigtable から受け継いでいます。
Cassandra は、Dynamo から「Master がいない decentralized なアーキテクチャ」、「設定可能な consistency」などの特徴を受け継いでおり、Dynamo と同様に高い availability を持ちます。Consistent hashing での Paritioning, Gossip protocol による Membership 管理, Anti-entropy, Read-repair, 設定可能な consistency など、Dynamo 由来の多くのアイディアを活用しています。一方、データモデルについては Bigtable に影響を受けており、行キー、列キー、列ファミリをもつ Wide column store となっています。また、データの読み書きの際には memtable や SSTable が利用されており、これらも Bigtable 由来のアイディアです。
Cassandra は次のように、多くの企業で利用されています。
Cassandra はその scalability や availability、また書き込みに強い特性から、さまざまなユースケースで活用されています。
2-3. 「オープンソースの分散データベース実装」まとめ 以上、オープンソースの分散データベース実装、特にその中でも広く使われている Cassandra と HBase について紹介しました。Bigtable や Dynamo のアイディアが色濃く反映されていることが分かったかと思います。
今後、分散データベースを利用する機会があれば、技術選定にこれらの知識が活かされるでしょう。また、今後新しく分散データベースが登場したり、あるいは自分たちで作る必要が出てきた場合でも、きっとこれらのオープンソース実装に対する知識が役立つと思います。
3. クラウドサービスの分散データベース 現在、我々はクラウドの時代に生きています。巨大企業が発達させてきた分散データベース技術を、GCP や AWS のようなクラウドプロバイダーはさまざまな分散データベースサービスとして提供しており、我々は便利なサービスとして簡単に利用することができます。その一方で、我々には適切な技術選定を行う責任が生まれています。
この章では、クラウドで提供されるデータベースサービスに注目して、その特性を紹介したいと思います。特に、Bigtable や Dynamo の影響が強く出ている Cloud Bigtable や Cloud Spaner、DynamoDB の3つのサービスについて説明いたします。
3-1. Cloud Bigtable by GCP Cloud Bigtable は、Google 社内の Bigtable をベースにしたクラウドデータベースです。Wide column store、行キーでのインデックス、行レベルでの atomicity など第2章で書いた Bigtable の性質をほぼそのまま持っています。
Hadoop、Cloud Dataflow、Cloud Dataproc など他のツールやクラウドサービスと連携ができて、さらに HBase API をサポートした使いやすいものになっています。低レイテンシーで大量データの分析や操作をしたい時に選択肢になるでしょう。
3-2. Cloud Spanner by GCP Cloud Spanner は、2012年に 「Spanner: Google’s Globally-Distributed Database」という論文[19] で発表された Spanner という Google 製分散データベースをクラウドサービス化したものです。水平スケーリング可能で Externally consistent な分散 transaction を兼ね備えた、初のリレーショナルデータベースサービスといわれています。
Cloud Spanner の特性を理解するために、Spanner がどんな分散データベースなのか、少し詳細を見てみましょう。
Spanner は Bigtable (やその後作られた Megastore)が抱えていたいくつかの課題を解決する為に作られました。データセンターをまたがる強い整合性を持った Replication、複数行や複数テーブルに対する分散 Transaction、複雑かつ変化する Schema をもつアプリケーションへの対応、それらを満たしつつ高い書き込み Throughput を保つことなどは、Bigtable や Megastore では実現できていないことでした。Spanner は、この課題を解決しています。「SQL like なクエリ言語」、「Externally consistent な読み書き分散 Transaction や読み込み分散 Transaction」などを提供しています。
それでは、Spanner がどうやってこれらの性質を実現しているのかも見てみましょう。
Spanner は、timestamp 付きの multi-version データを格納しており、timestamp を指定することで任意の時点のデータを読み取ることができる様になっています。この際、分散システムである以上 server 間の時計のズレが問題になるはずですが、Spanner では TrueTime API を利用して時計のズレを10ms以下の小さな範囲に抑え、さらに Commit wait と呼ばれる手法で External consistency(transaction の順序と timestamp の大小が一致する整合性)が保たれる様にしています。これによって、timestamp を信頼して読み取りが行える様になっています。
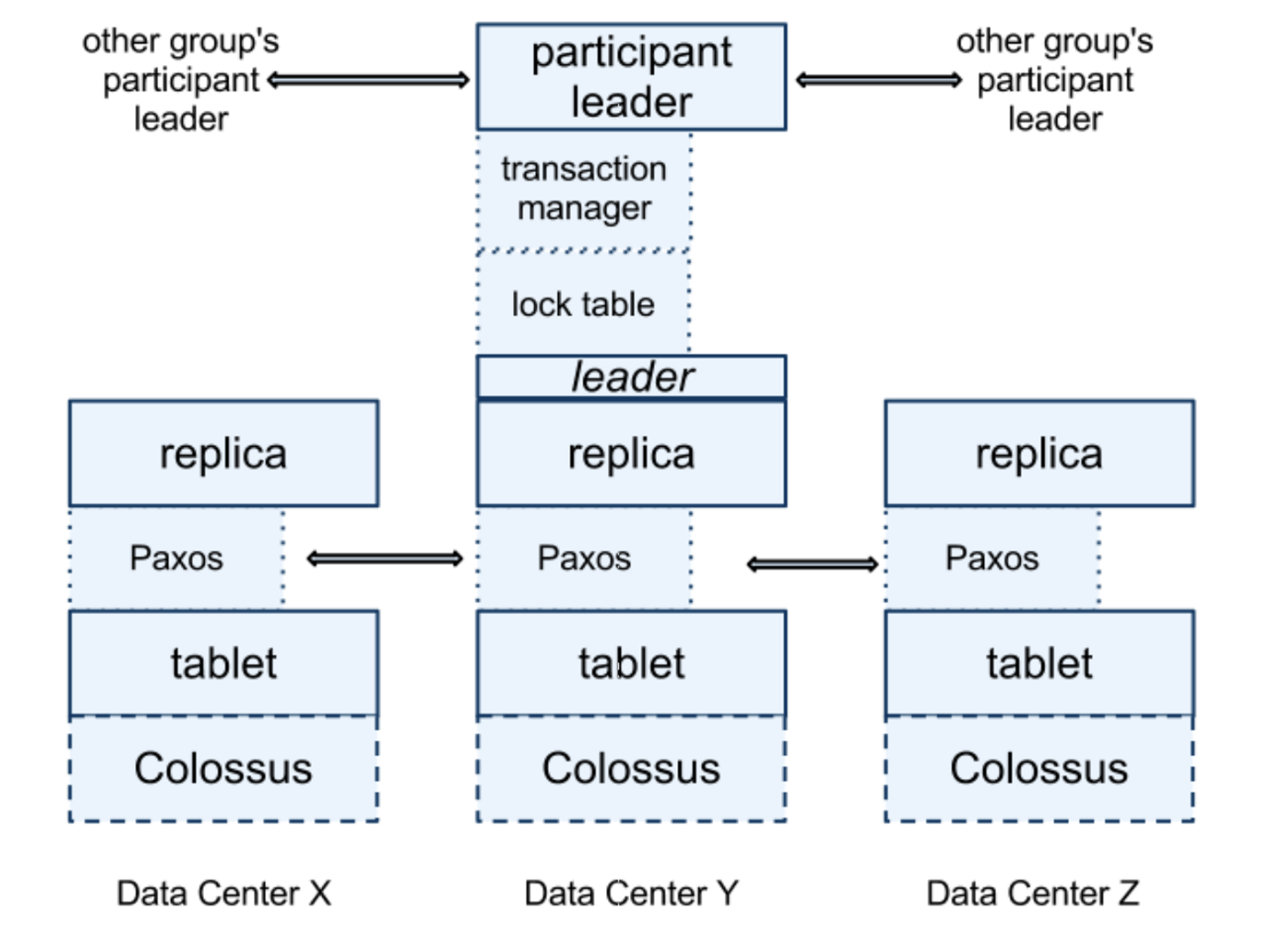
さらに、Spanner は「Paxos leader が参加者となった Two-Phase Commit 」によって分散 Transaction を実現しています。Paxos leader は Paxos という分散合意アルゴリズム で合意する Paxos group の leader です。Paxos group として見ると高い availability が保たれています。Two-Phase Commit は参加者の故障に弱いアルゴリズムとして有名ですが、Paxos leader が参加者となることで故障を気にせずに Two-Pahse Commit が利用できています。
Spanner は、Google File System の後継である Colossus の上に構築されてます。また、Bigtable と同様に Tablet と呼ばれる単位にデータを分割して各 server(spanserver)に割り当てています。Tablet の割り当ては、zonemaster と呼ばれる server が行います。また、Tablet ごとに、data center をまたいで Paxos group を形成して replication を行っています。
[spanserver のアーキテクチャ。 "Spanner: Google’s Globally-Distributed Database" p3より引用]
以上が Spanner の実装の簡単な説明になります。さらに詳細が気になった方は、 Spanner 論文[19] や kumagi さんによる Spanner の解説記事[20] を参照してみてください。
Spanner は、global scale の分散データベースでありながら Externally consistent な transaction を実現する画期的なシステムとなっています。Google 社内でも、Ads など重要なサービスに利用されている様です。大量のデータを global scale で扱いたい、しかし同時にある程度複雑な schema のテーブルで transaction を行いたいといった場合に、最適な選択肢となるでしょう。
3-3. DynamoDB by AWS DynamoDB は、AWS が 2012 年から提供し始めたマネージドなクラウドデータベースサービスです。Dynamo と名前が似ており、多くの性質を受け継いでいますが別物です。スケーラブルで高い Availability をもつだけでなく、構造化したデータを JSON 形式で保存できるドキュメント指向のデータモデルとなっています。また、各行をクエリする際にはプライマリキーだけでなく、セカンダリインデックスもサポートしています。ストリームやトリガーなど、変更を検知して処理を行う機構もあります。
DynamoDB が特徴的なのはその課金体系です。読み込み throughput や書き込み throughput の上限を read capacity unit や write capacity unit という単位で設定し、その設定値に応じて課金が行われます。注意しなければならないのは「paritioning が行われると、各 node の throughput は全体の capacity を node 数で割ったもので制限される」ということです。 一部 hot な key が存在すると、その key の為に全体としてかなり大きめに capacity を設定することになり、割高になってしまうことがある様です[21] 。利用する際は、自身のユースケースに求められるワークロードを理解した上で、それを満たすものかどうか検証する必要がありそうです。
3-4. 「クラウドサービスの分散データベース」まとめ 以上、クラウドサービスとして提供される分散データベースである Cloud Bigtable、Cloud Spanner、DynamoDB について、その特徴を紹介しました。巨大企業によって発展してきた分散データベース技術が、簡単に利用できる時代になったことが分かります。
4. ユースケースに合わせた独自実装の分散データベース 巨大企業は、オープンソースの分散データベースだけではなく、自身のユースケースに合わせた独自の分散データベース実装も行ってきました。たとえば、 Facebook はソーシャルグラフ情報を管理するために TAO という分散データベースを生み出しましたし[22] 、 Twitter は低レイテンシーの分散データべースを求めて Manhattan を[23] 、 Uber は Trigger 機能付きの Schemaless を生み出しました[24] 。
企業にとっては、オープンソース実装を利用するだけでなく、「ユースケースに合う実装が無ければゼロから作る」というのも、選択肢のひとつであることが分かります。
これらの企業がどういった問題意識から独自のデータベースを構築したのか、少し実例を見てみましょう。特に、Facebook の TAO は、これほど巨大なソーシャルグラフデータを扱う企業がほとんどないという点で、極めて特徴的です。TAO について、詳しく見てみたいと思います。
4-1. TAO(2013)by Facebook TAO は、Facebook がソーシャルグラフ情報を保存および取得するために利用している分散データベースです。 2013年に論文が公開されました[22] 。
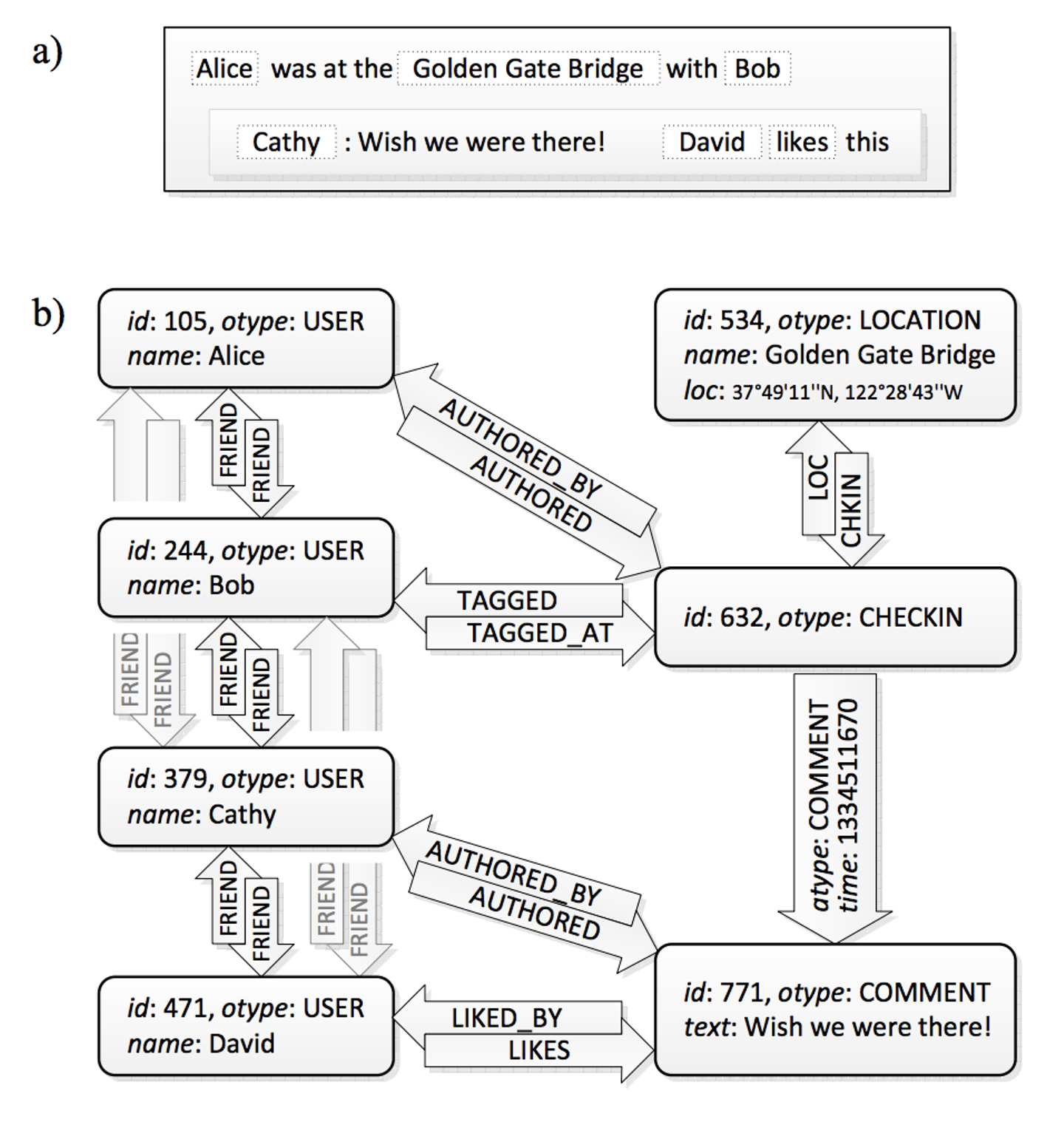
Facebook は世界中で利用される地球規模のインターネットサービスです。TAO は、Facebook の過酷なワークロードに耐えられる様に、グローバルに分散した数千台のマシンから構築され、毎秒数十億の読み取りと数百万の書き込みを処理する分散データベースとなっています。また、Facebook では、「友達」というユーザー同士のつながりだけではなく、「チェックイン」や「タグ付け」、「Like」や「コメント」などさまざまな情報がソーシャルグラフ情報として扱われます。その為、TAO はさまざまな object の間に何種類もの association が存在する前提で、それを表現する API をもっています。
[Facebook のソーシャルグラフ。チェックインや Like、コメントはソーシャルグラフとして表現される。 "TAO: Facebook’s Distributed Data Store for the Social Graph" p1より引用]
TAO の データモデルと API TAO は、object と association という2種類のデータを保持します。object は unique な id を持ち、object type(otype)や key-value データを保持しています。Association は 2つの id の組と association type(atype)で表現され、こちらも key-value データを保持することができます。また、association の作成時刻は time として残します。time は association を取得する際に極めて重要な役割を果たします。
ソーシャルグラフの特性として、association へのクエリは newest なものに集中します。つまり、association には creation-time locality が存在します。その為、association を取得する際には最新順で結果を返しますし、time の範囲を parameter で絞って取得することもできるようにしています。また、内部実装としても、time で絞った取得に最適化しています。
Object と association は次の式で表現できます。
Object: (id) -> (otype, (key -> value)*) Association: (id1, atype, id2) -> (time, (key -> value)*) object に対しては、取得、作成、更新、削除の API が提供されています。これに関しては、特筆すべき点は無いでしょう。Association に対しては、更新の為に次の3つの API が提供されています。
assoc_add(id1, atype, id2, time, (k→v)*) id1 と id2 の間に atype の association を追加。作成時刻は time として渡す。key-value のデータも持たせることが可能。 assoc_delete(id1, atype, id2) id1 と id2 の間の atype の association を削除 assoc_change_type(id1, atype, id2, newtype) id1 と id2 の間に atype の association が存在したら、その association type を newtype に変更 また、association 取得には、次の4つの API が提供されています。assoc_count を除いた全てで、time の降順(最新順)で association のリストを返すようになっています。
assoc_get(id1, atype, id2set, high?, low?) id1 と id2set 中の id2 の間の atype の association を全て返します。high と low がパラメータとして渡された場合には、high >= time >= low を満たす association だけが返されます。 assoc_count(id1, atype) id1 がもつ atype の association 数を返します。 assoc_range(id1, atype, pos, limit) id1 がもつ atype の association のうち、pos から始めて limit 数の association を返します。 assoc_time_range(id1, atype, high, low, limit) id1 がもつ atype の association のうち、high >= time >= low を満たす association を limit 数だけ返します。 TAO が提供するのはシンプルな API ですが、これで Facebook の多くのユースケースを満たすことができます。
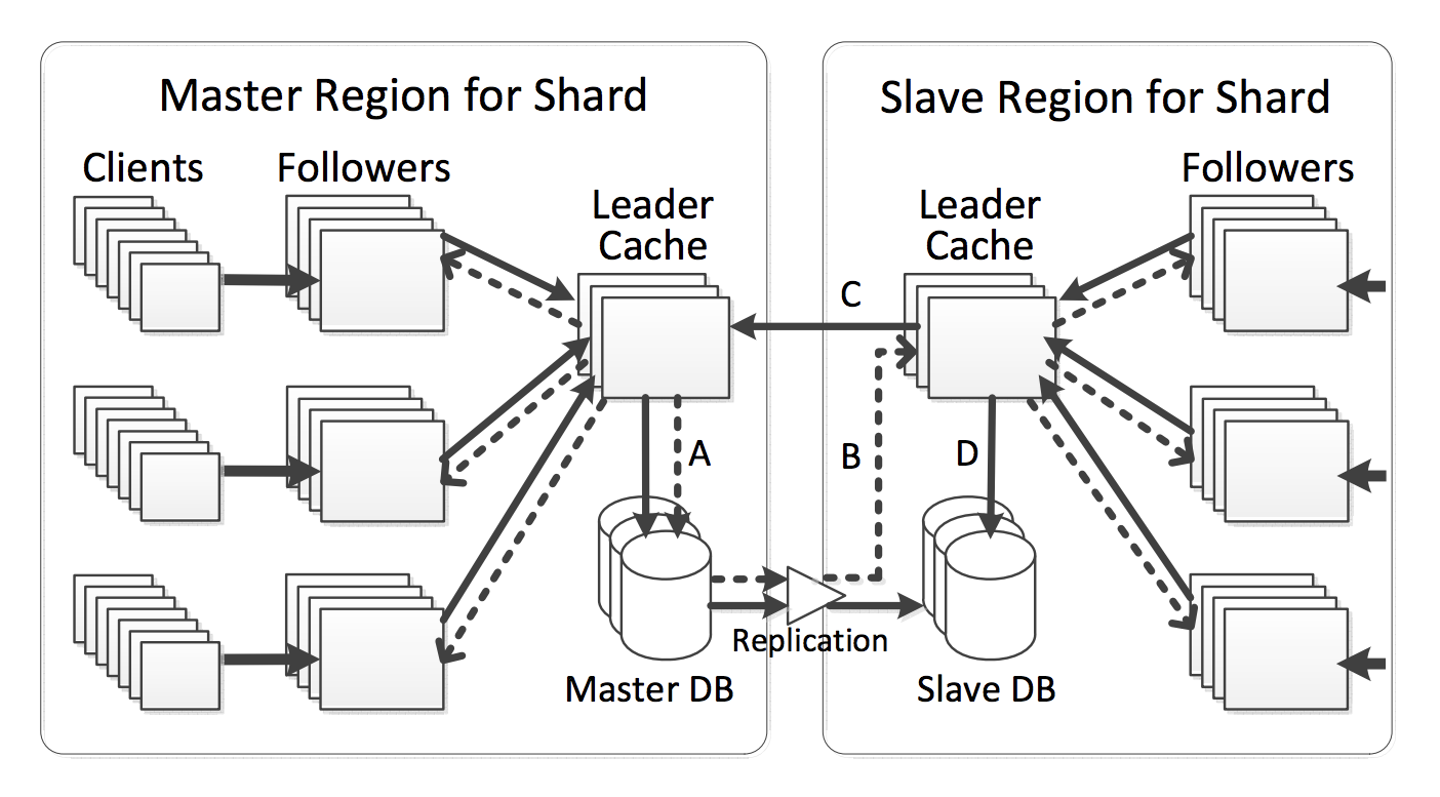
TAO のアーキテクチャ TAO は、2層の cache layer と storage layer をもつ multi-region 構成のシステムとなっています。Storage layer には MySQL の cluster を利用しています。TAO 以前の Facebook のシステムにおいてもソーシャルグラフ情報は MySQL へ保存されていたらしく、MySQL は自然な選択肢だったようです。
[TAO のアーキテクチャ。 "TAO: Facebook’s Distributed Data Store for the Social Graph" p5より引用]
MySQL server には object 用のテーブルと association 用のテーブルがそれぞれ存在し、object や association はレコードとして表現されます。Object も association も、基本的には1つのテーブルに全ての type のデータが保存されます。key-value データは data というカラムに保存されます。Association テーブルには、効率的にレスポンスを返す為に (id1, atype, time) の index が存在します。また、COUNT クエリを避ける為に、association 数は別のテーブルに保存しています。
TAO の扱うデータ量は膨大である為、object や association のデータは shard として分割され、MySQL cluster のそれぞれの server に割り当てられます。通常、shard 数は server 数よりもかなり大きな数となっており、server の負荷に応じて割り当ての調整が可能です。Object の id には shard_id が埋め込まれていて、id を見ればどの shard なのかが分かるようになっています。「(id1, atype, id2)」の3つ組として表現される association は、id1 の object と同じ shard に保存されるため、大抵の association query は 1 つの server から response を返すようになっています。
TAO の cache layer は2層構造となっており、leader と follower に大きく分かれます。leader は storage layer と直接やりとりを行う cache server で、region 内で tier を形成します。tier 内の server はそれぞれ担当する shard が決まっており、tier 全体として任意の object や association に対する request に応えられるようになっています。
Follower は client から直接繋ぐ cache server であり、複数の tier を形成します。Follower はそれぞれ自身の leader に紐づいており、cache miss や write request は leader へ forward します。
2層の cach layer によって、tier 内の server 数を抑えつつ tier の数と cache server の数を増やし、過酷なワークロードに耐えられるようにしています。巨大な tier は hot spot を生みやすいなどの問題がある為、tier 内の server 数を抑えることが重要な意味を持ちます。
TAO は eventually consinstency な分散データベースです。leader に対する書き込みが行われると、対応する follower へ非同期で変更が通知され、cache が更新されます。ただし、書き込み request を行った元々の follower に対しては、leader からの response が来たタイミングで同期的に cache が更新されます。これによって、read-after-write consistency が実現されます。cache の非同期更新通知には version 番号が割り振られている為、古い更新通知が届いても単に無視されます。
特定の id に対する書き込みは必ず同じ leader に届くため、leader が書き込みを serialize できるアーキテクチャになっています。その為、MySQL を thundering herd から守ったり、特定の shard に対して最大クエリ数の制限をかけたりできるようになっています。
TAO は global な multi-region 構成となっています。各 region には、これまでに説明した leader tier と複数の follower tier、さらに MySQL cluster が存在します。複数 region のうち、1つの region が master region、残りの region は slave region となります。書き込み request は slave leader から master leader、そして master DB cluster へ forward されます。書き込みに成功すると、response は同期的に伝搬して slave leader や slave follower の cache を更新し、さらに非同期で slave DB cluster への replication やその他の cache server への cache 変更通知が行われます。slave region から見ると、書き込みは region をまたがる必要がある為に latency が増大する一方で、読み込みは region 内で完結する為に latency が下がります。Facebook のワークロードでは、読み込み request が書き込み request の500倍、キャッシュヒットしない読み込みに絞っても25倍の差があるため、この multi-region 構成を選択しているようです。
Facebook は、「全ての region が同じソーシャルグラフのコピーをもつ、つまりソーシャルグラフを region で分割しない」という選択肢を取っています。ソーシャルグラフは内部で強固に結合しており、上手く分割することが難しいからだと説明されています。
TAO の障害時の動作 TAO の cluster 中の server に障害が起きた際の挙動を見てみましょう。TAO は、正常時には consistency を保ちますが、障害時には多少 consistency を犠牲にしてでも availability を高める設計になっています。
master DB に障害が起きた場合は、MySQL の failover 機能を利用して slave が master へ昇格します。slave DB に障害が起きた場合は、slave leader からの forward 先は master leader へ変更されます。どちらのケースでも、TAO は動作を続けることができます。
leader cache server に障害が起きた場合は、follower が read や write の forward 先を変えます。read は直接 DB に対して行います。また、write は leader tier の中からランダムに選出した server に対して行います。選ばれた leader server は期待された動作を行い、さらに障害が起きた leader の復旧に備えて非同期の invalidation job を enqueue します。ただし、leader の復旧直後は、溜まった invaildation job を消化するまでの間は consistency が失われた状態となります。
Follower cache server に障害が起きた場合は、他の tier の follower がその shard の request を処理します。TAO の client には、follower server として primary と backup が設定されており、primary が落ちている場合には backup に request が送られます。backup によって、TAO は動作を続けることができます。ただし、書き込み直後に primary に障害が起きた場合は、backup にまだ変更が反映されてないかもしれず、read-after-write consistency が失われる可能性があります。
TAO まとめ 以上のように、Facebook は MySQL と cache server の cluster によって TAO というソーシャルグラフに特化した分散データベースを構築しています。ソーシャルグラフの特性を活かした sharding や replication、cache system を考案しており、とても興味深い実装となっています。
5. まとめ 本稿では、分散データベース技術について、特に「地球規模のインターネットサービスを提供する巨大企業による技術発展」という観点からご紹介しました。Bigtable や Dynamo の登場以来、技術発展は進み、Cassandra や HBase のような優れたオープンソース実装が生まれました。また、GCP の Cloud Bigtable や Cloud Spanner、AWS の DynamoDB のようなクラウドサービスが登場し、分散データベースが簡単に利用できるようになりました。さらには、Facebook がソーシャルグラフを保存するために生み出した TAO など、ユースケースに合わせた新たな分散データベースも次々と作られてきました。それらの技術発展の歴史を、本稿では振り返りました。
サービスが成長し続ければ、いつかは巨大なデータ量や地理的な分散環境について考える時がやってきます。そんな時、本稿で紹介した分散データベース技術の知識が役に立てば幸いです。
参考文献 [1] Fay Chang et al. "Bigtable: A Distributed Storage System for Structured Data". In Proceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation, p.15-15, November 06-08, 2006, Seattle, WA
[2] Giuseppe de Candia et al. "Dynamo: amazonOs highly available key-value store". In Proceedings of twenty-first ACM SIGOPS symposium on Operating systems principles (SOSP '07), October 14-17, Stevenson, Washington, 2007.
[3]「LevelDB: A Fast Persistent Key-Value Store」 https://opensource.googleblog.com/2011/07/leveldb-fast-persistent-key-value-store.html
[4]「LevelDB mailing list: "Current Status of LevelDB"」 https://groups.google.com/forum/#!msg/leveldb/Dby98QYzJqw/s5elVIkpIAUJ
[5]「MyRocks: A space- and write-optimized MySQL database」 https://code.fb.com/core-data/myrocks-a-space-and-write-optimized-mysql-database/
[6] 西田圭介「Google を支える技術」技術評論社, 2008年
[7]「Amazon DynamoDB – a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications」 https://www.allthingsdistributed.com/2012/01/amazon-dynamodb.html
[8]「HydraBase – The evolution of HBase@Facebook」 https://code.fb.com/core-data/hydrabase-the-evolution-of-hbase-facebook/
[9]「Storage infrastructure using HBase behind LINE messages」 https://www.slideshare.net/naverjapan/storage-infrastructure-using-hbase-behind-line-messages
[10]「NoSQL at Netflix」 https://medium.com/netflix-techblog/nosql-at-netflix-e937b660b4c
[11] 「Apache HBase at Airbnb」 https://www.slideshare.net/HBaseCon/apache-hbase-at-airbnb
[12]「Apache HBasea」 https://en.wikipedia.org/wiki/Apache_HBase
[13]「Cassandra – A structured storage system on a P2P Network」 https://www.facebook.com/notes/facebook-engineering/cassandra-a-structured-storage-system-on-a-p2p-network/24413138919/
[14]「Cassandra: Daughter of Dynamo and Bigtable」 https://blog.insightdatascience.com/cassandra-daughter-of-dynamo-and-bigtable-1b57b16229b9
[15]「Apple Inc.: Cassandra at Apple for Massive Scale」 https://www.youtube.com/watch?v=Bc4ql9TDzyg
[16]「Meet Michelangelo: Uber’s Machine Learning Platform」 https://eng.uber.com/michelangelo/
[17]「The Infrastructure Behind Twitter: Scale」 https://blog.twitter.com/engineering/en_us/topics/infrastructure/2017/the-infrastructure-behind-twitter-scale.html
[18]「Apache Cassandra」 https://en.wikipedia.org/wiki/Apache_Cassandra
[19] James C. Corbett et al., "Spanner: Google's globally-distributed database". In Proceedings of the 10th USENIX conference on Operating Systems Design and Implementation, October 08-10, 2012, Hollywood, CA, USA
[20] 「Spanner」 https://qiita.com/kumagi/items/7dbb0e2a76484f6c522b
[21] 「Why Amazon DynamoDB isn’t for everyone」 https://read.acloud.guru/why-amazon-dynamodb-isnt-for-everyone-and-how-to-decide-when-it-s-for-you-aefc52ea9476
[22] Nathan Bronson et al. "TAO: Facebook's distributed data store for the social graph". In Proceedings of the 2013 USENIX conference on Annual Technical Conference, June 26-28, 2013, San Jose, CA
[23] 「Manhattan, our real-time, multi-tenant distributed database for Twitter scale」 https://blog.twitter.com/engineering/en_us/a/2014/manhattan-our-real-time-multi-tenant-distributed-database-for-twitter-scale.html
[24] 「Designing Schemaless, Uber Engineering’s Scalable Datastore Using MySQL」 https://eng.uber.com/schemaless-part-one/
[25] Photo Credit: NASA https://unsplash.com/photos/Q1p7bh3SHj8

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)