
ウォンテッドリーにおける推薦システム開発の流れ | Wantedly, Inc.
はじめにこんにちは、ウォンテッドリーの合田(@hakubishin3)です。私は推薦チームに所属していて、機械学習領域のテックリード兼プロダクトマネージャーとして会社訪問アプリ「Wantedly...
https://www.wantedly.com/companies/wantedly/post_articles/864502
こんにちは、ウォンテッドリーでデータサイエンティストをしている林 (@python_walker) です。
ウォンテッドリーでは、テクノロジーの力で人と仕事の適材適所を実現するために推薦システムの開発を行っています。これまでのウォンテッドリーでの推薦システムの開発に興味のある方はぜひ下の記事も読んでみてください。
この記事では、Wantedly Visit での募集推薦の際に「相互推薦」と呼ばれる技術を活用することによってユーザーが魅力的に感じ、かつ企業側からみても魅力的なユーザーに対して自社の募集が推薦される状態を実現した施策について書きたいと思います。
会社訪問アプリ Wantedly Visit (以下 Visit) では、ユーザーが話を聞きに行きたい募集を見つけることを補助するために様々な場所で推薦システムが活用されています。今回スコープとしているのは、この中の1つで「募集一覧ページ」と呼ばれる部分での推薦の話です。募集一覧ページは下のような見た目になっており、画像とともにユーザーに対しておすすめの募集が並んでいます。
ユーザーはこの一覧ページから自分の興味がある募集をクリックして詳細を読み、もっと詳細を聞きたいと思ったら「話を聞きに行きたい」ボタンを押すことで応募をすることができます。そして応募された企業がユーザーを魅力的に感じたら返信を行い、両者のマッチングが成立します。
この募集一覧ページは仕事を探しているユーザーや気になる募集が無いか少し見に来たユーザーなど、様々な理由でVisitを利用するユーザーが閲覧するページになっていて、ユーザー属性によって異なる推薦システムを使うことでそれぞれのユーザーに最適な募集を推薦できるようになっています。ユーザー属性に沿った推薦システムに興味のある方は、2024年のDEIMで新規ユーザーに対する推薦について発表した資料がありますのでぜひ見てみてください。
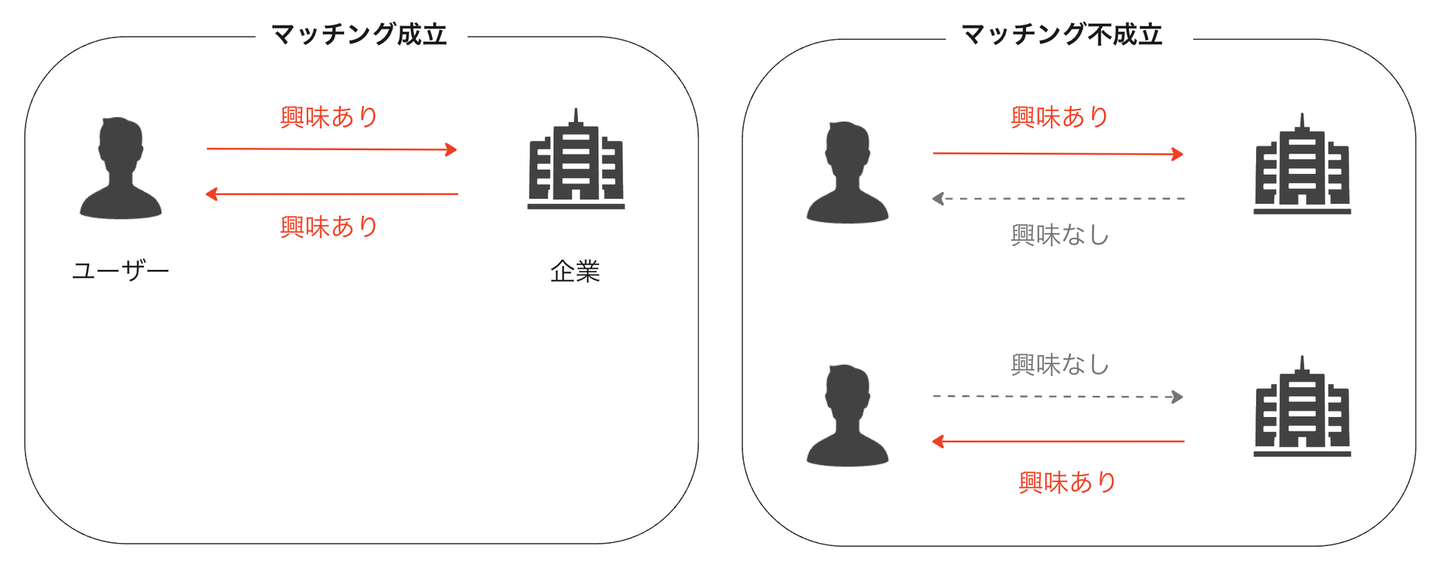
最初に書いたように、ウォンテッドリーではテクノロジーの力で人と仕事の適材適所を目指してプロダクト開発を行っています。Visit のようなジョブマッチングサービスでは、我々が開発している推薦システムにとっての「成功」は「ユーザーと企業のマッチングが成立した状態」を指します。この点はユーザーに推薦したアイテムが購入されれば成功とみなされることが多いECサイトなどの推薦システムとは大きく異なっています。Visit での推薦ではユーザーが興味を持つかどうかだけを精度良く予測できても必ずしもマッチングはしません。ユーザーが興味をもって応募してくれたとしても、応募された側の企業に返信する意思がなければマッチングにはならないからです。
また、推薦でユーザーが興味を持つかどうかだけを考慮したときのユーザーと企業がする体験を想像してみると
といったものになり双方にとって悪い体験になっています。では企業の嗜好が精度良く予測できればいいのかということかというとそうではないのは自明で、
のように依然として双方にとって悪い体験となります。そのため、我々が目指すユーザーと企業のマッチングを実現するためにユーザーと企業の双方の嗜好をバランスよく考慮した推薦システムを開発することが必要でした。
Visit で使われている推薦システムでは機械学習が使われており、モデルの学習の際にはユーザーが応募したという結果とマッチングが成立したという結果に対して異なるターゲット値を設定して、特徴量に対してこのターゲットを予測するタスクを解かせていました。例えばユーザーがある募集に対して反応しなかった場合にはターゲット値は0、応募はしたがマッチングは成立しなかった場合には1、マッチングが成立した場合には2といった具合です。こうすることで、モデル予測時の出力の降順に募集を並べることでマッチングが成立しそうな募集→応募しそうな募集→それ以外の募集、といった順番で募集が並んだランキングを作ることができると期待できます。
このようなモデル構成は一見するとうまくいきそうに見えます。しかしモデルの出力を分析するうちに、このような構成ではモデルを改善してユーザー体験を向上させていくといったプロセスがやりづらくなっていることがわかってきました。ここまで書いてきたように、マッチングするかどうかというのは次の2つのステップに分解することができます。
我々が設計したモデルではこの2つに対してターゲット値を振り分けて区別させていますが、ユーザーが応募するかどうかの予測精度と企業返信の予測精度の間にトレードオフがあるということがわかってきました。1つのモデルで実質的に2つのタスクを解かせているためです。その結果、例えばモデルに改善を加えて応募予測性能が向上したときに逆に企業返信予測性能が悪化してしまうという関係が発生しやすいといった状態が存在していました。これら2つの予測性能にトレードオフがある状態では、マッチング性能を向上させることが難しくなります。
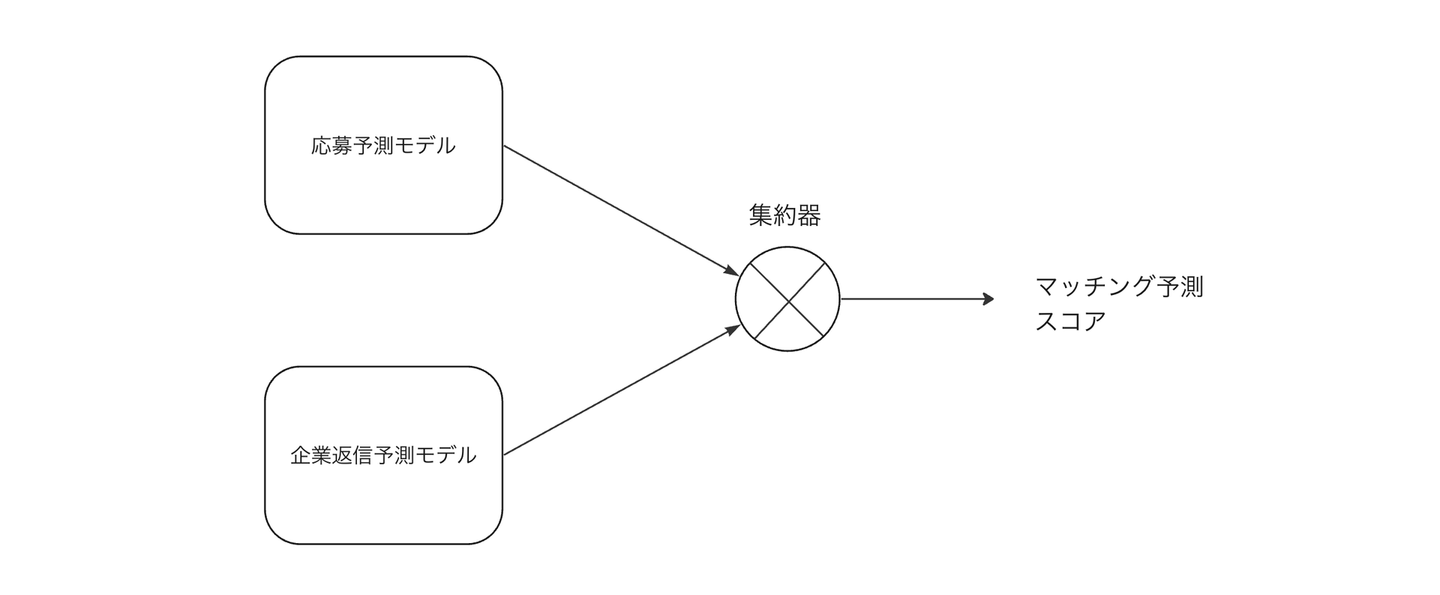
上に述べた課題を解決するために、モデルの構成を大きく変更して相互推薦システムと呼ばれるものを実装しオンラインでテストするということを行いました。相互推薦モデルはVisitのようなジョブマッチングサービスやオンラインデーティングサービスのような人に対して人を推薦する文脈で活用できるフレームワークで、学術的にも多くの研究がされています。
相互推薦(reciprocal recommendation)という名前は2010年のRecSysで発表された論文 "RECON: A Reciprocal Recommender for Online Dating"[1] において初めて使われ、それ以来多くの相互推薦システムでは双方の嗜好を別々に予測して最後に予測値を集約して1つの予測値にするという手法が取られてきました。Visitの推薦システムでも以下のような形で相互推薦システムの開発を行いました。
このような構成にすることによって、技術的な課題としてあった応募予測性能と企業返信予測性能の間のトレードオフを軽減することを目指しました。1つのモデルで作成したランキングの性能をベースラインとして、相互推薦の枠組みで実装したモデルが作成するランキングの性能をユーザーの過去のログデータを使って比較してみると、応募予測の性能と応募マッチの性能の両方がベースラインと比べて大きく向上することがわかりました。
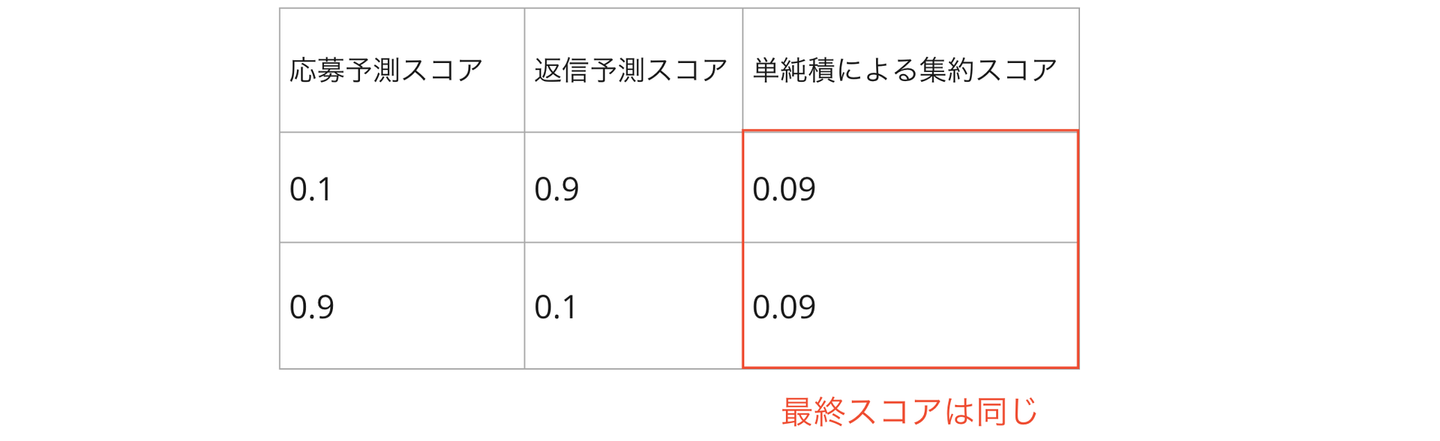
しかしながら1つ問題があり、実験した相互推薦システムでは集約関数として単純積を使っているために「ユーザーが応募する確率が高いが企業から返信が来る確率が低いユーザー・募集ペア」と「ユーザーが応募する確率が低いが応募したとしたら企業から返信する確率が高いペア」が同列に扱われてしまっていました。単純積で集約すると (応募予測値, 返信予測値) = (0.1, 0.9), (0.9, 0.1) の場合の最終スコアが同じになってしまうためです。
ユーザーが募集一覧を見たときの体験を考えたとき、理想的なのは自分が応募したいと思える募集が一覧の上部に多く現れることです。つまり表示の優先順位としては「応募したいと思えるが返信が来ないかもしれない募集」> 「応募したいとは思わないが応募したら返信が来そうな募集」が体験的には良いはずだと考えました。これを実現するために、応募の予測値が低い募集についてはランキング上での順位を落とすという後処理を行うことにしました。
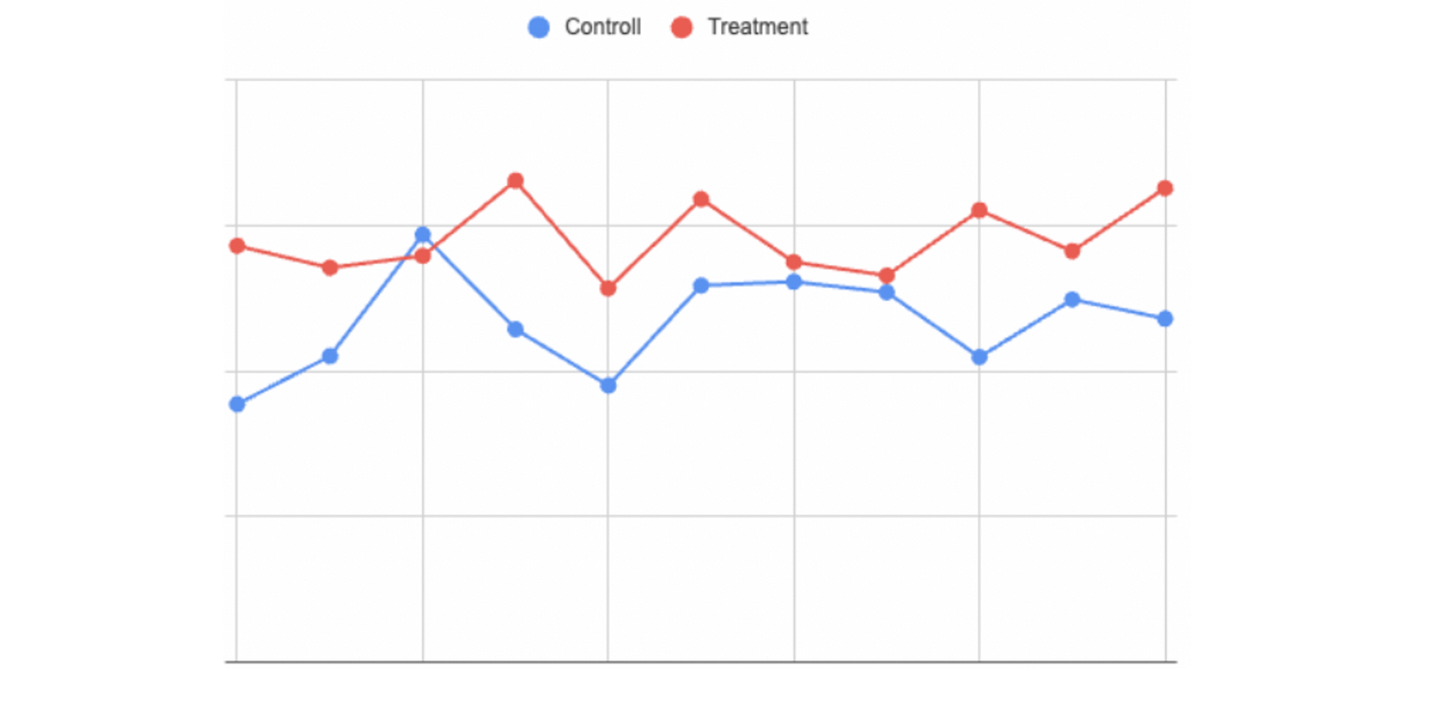
オフラインでのテストでモデルのマッチング性能が向上しそうなことがわかったので、オンラインテストに出して実際にユーザーの体験を向上させられるかテストを行いました。テストの結果、主要KPIは+20 %を超える大きな改善を示し相互推薦モデルの有効性が確かめられました。下図はオンラインテスト中の主要KPIの1つの時間による変化です。Treatmentで示されているのが相互推薦モデルの性能で、これまでのモデル(Control)と比較して明らかに性能が向上していることがわかります。
さらにテスト結果を分析してみると、相互推薦モデルの導入によって実現したかった「よりユーザーが応募したいと思う募集を一覧の上位に表示できるようにする」、「ユーザーがマッチングできる募集をより一覧の上位に表示できるようにする」という要求をともに実現できていることもわかりました。
この記事で紹介した施策では、Visitの推薦システムを大きく性能向上させることができました。しかし、この施策でもまだ改善の余地が様々あります。その一例を挙げると、
これらの課題に関しては、また別の施策で解決を行っていきたいと思っています。
この記事では、Wantedly Visit の推薦システムではユーザーと企業の両方の嗜好を考慮して推薦を行うことが求められていること、そしてそれを相互推薦システムを使って解決することができた事例について紹介しました。モデルを大きくアップデートすることによって募集一覧におけるユーザー体験を大きく向上することができた一方で、また新たに様々な課題が出てきました。これからも継続的に推薦システムの改善を行い、もっと多くのユーザーが自分にあった仕事を見つけられるようにしていきたいと思っています!
また、私たちと一緒に、推薦システムという技術活用を促進して人と会社の理想的なマッチングを追求するデータサイエンティスト・機械学習エンジニアの仲間を探しています。少しでも私たちの取り組みに興味を持っていただけたら、以下の募集から「話を聞きに行きたい」ボタンをクリックしてください!
[1] Luiz Pizzato, Tomek Rej, Thomas Chung, Irena Koprinska, and Judy Kay. 2010. RECON: a reciprocal recommender for online dating. In Proceedings of the fourth ACM conference on Recommender systems. ACM, 207–214.
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

