Wantedly Kubernetes クラスタアドオン大全 2023

この記事は Wantedly Advent Calendar 2023 の17日目の記事です。昨日は林さん ( @python_walker ) による「負例サンプリングの工夫による推薦システムの性能向上」でした。
17日目の記事にしようと思ったけど早く書きすぎた Kubernetes Pod の resources.limits.memory がいつのまにか 200PiB に設定されていた話 もあるのでよかったら読んでみてください。
Wantedly, Inc. では Kubernetes を本番環境のプロダクト基盤で使い始めて8年目になりました。この記事では Wantedly の基盤を支える Kubernetes クラスタアドオンについて、社内の人のために概要を索引的に把握できるように書いてみたものを公開してみます。
謝辞
Wantedly では 2022年に kOps による Kubernetes on EC2 の構成から AWS のマネージドサービスである Amazon EKS に移行しました。その時、Chatwork さんの ChatworkのKubernetesを支えるツールたち(2020年版) という記事や他社さんの EKS 事例ブログにすごく助けられたのを覚えています。あのときはありがとうございました。この記事も誰かの参考になれば幸いです。
Kubernetes クラスタアドオンとはなにか
Kubernetes クラスタアドオンは、Kubernetes クラスタの機能を拡張するための追加コンポーネントやプラグインです。これらはクラスタの管理や操作を容易にし、さまざまな基盤としての要求に応える機能やサービスを提供するために使用されます。例えば、Kubernetes Node のオートスケールを実現する Cluster Autoscaler や Kubernetes Ingress を AWS Application Load Balancer で実現する aws-load-balancer-controller などがあります。
マネージドな Kubernetes サービスだと最初からインストールされてクラウドの機能と統合されているものも多いです。たとえば Google の GKE は Node のオートスケールのための Cluster Auttoscaler やコンテナログ収集コンポーネントの fluentbit は最初からインストールされています。
これらのアドオンを使いこなすことで、インフラストラクチャの運用を効率化し、開発の生産性を高めていくことができます。
Wanteldy Kubernetes クラスタアドオン全部書く
wantedly/k8s (internal only) で管理されている(≒ Infrastructure チームが管理している) Wantedly のクラスタアドオン manifest ディレクトリの一覧です。OSS・内製・設定ファイルのみのディレクトリ含めて全部で34個ありました。また、EKS アドオン(AWS リソース)として管理されているものが4個あります。
- ambassador
- argo-cd
- argo
- aws-efs-csi-driver
- aws-for-fluent-bit
- aws-loadbalancer-controller
- cert-manager
- cluster-autoscaler
- coredns
- custom-metrics (prometheus + prometheus-adapter)
- dd-agent
- dex
- external-dns
- fluentd-servicex
- hnc
- ingress-nginx
- istio
- k8nskel (内製)
- k8s-cd (内製)
- kube-apiserver
- kubecost
- kubernetes
- loki
- metrics-server
- nodelocaldns
- nvidia-device-plugin
- oauth2-proxy-manager (内製)
- prometheus-operator
- rbac (内製)
- storage-class
- telepresence
- vault
- velero
- vertical-pod-autoscaler
EKS Addons
- kube-proxy
- CoreDNS
- VPC CNI plugin
- EBS CSI Driver
その他
- https://github.com/wantedly/forkx-controller (internal)
- https://github.com/wantedly/virtual-service-controller (internal)
- https://github.com/wantedly/deployment-duplicator
ここでは EKS Addons 以外の、wantedly/k8s repo で manifest を管理しているクラスタアドオンについて「概要」「Wantedly でのユースケース」「運用エピソード(あれば)」の3つに着目して簡単に書いていきたいと思います。
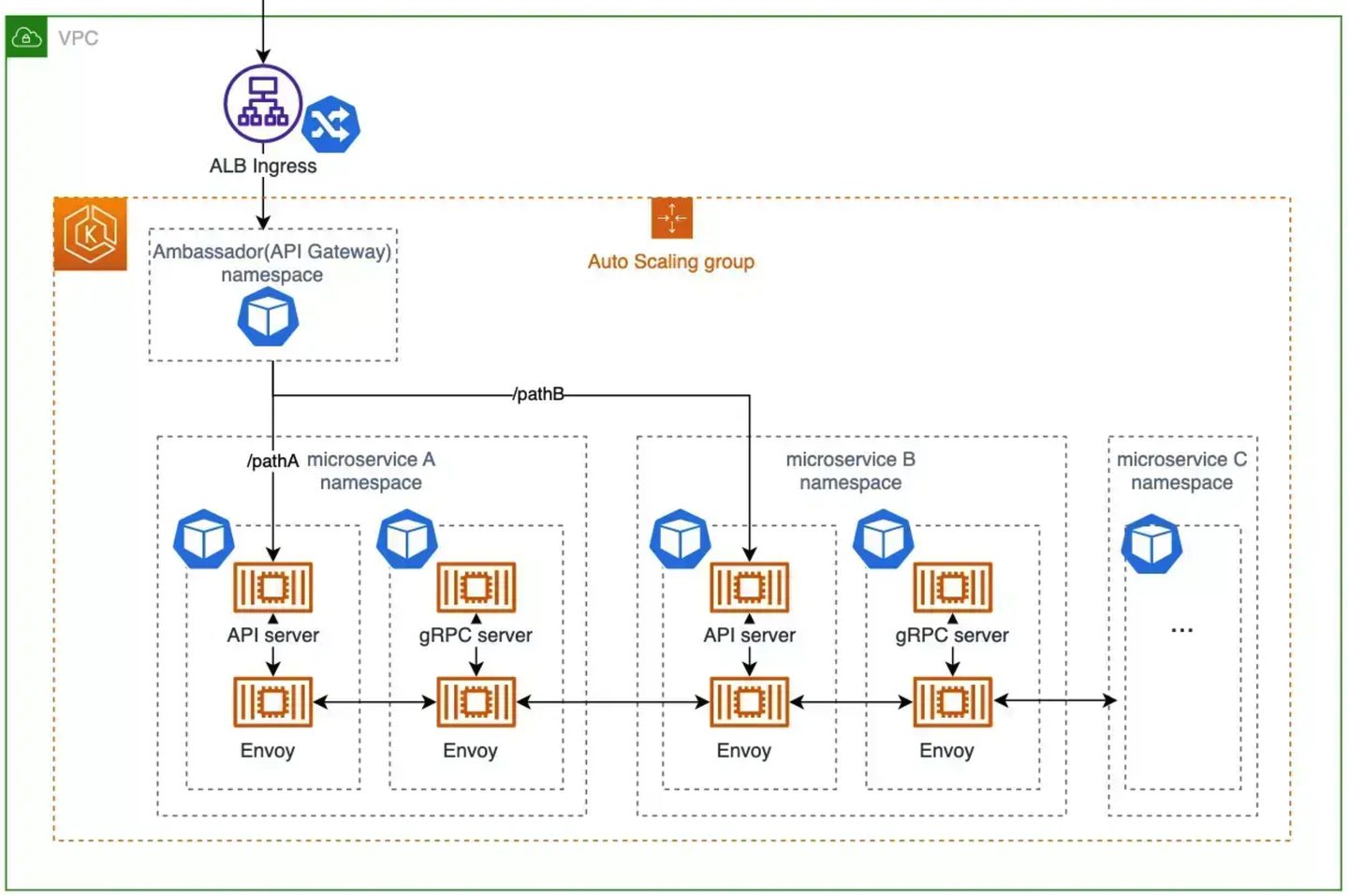
ambassador (Emissary Ingress)
サービスへのリクエストを捌く API Gateway として、Emissary Ingress (旧 ambassador API Gateway) を導入しています。このディレクトリでは、API Gateway のコンポーネント自体の Deployment や HPA 設定の他、クラスタ内の各マイクロサービスへの k8s service へのルーティングやきめ細やかなリクエストの制御を設定を可能にする Custom Controller Definition (CRD) が管理されています。
もともと Web アプリの多様化(Web, Android, iOS)とマイクロサービス化によって増殖と複雑化する API エンドポイントのために導入した Gateway ですが、現在はその役目の一部を内製した GraphQL Gateway に譲っており、現在は LP へのリダイレクトや一部のサービスにおける段階リリースのための柔軟なルーティング設定など、役割が変化しています。
Argo CD
GitHub Repositoryの Kubernetes manifest YAML をクラスタに apply / sync させる Continuous delivery のためのツールです。Argo CD は各マイクロサービスの GitHub repo の master ブランチをクラスタに同期し、API サーバーや gRPC サーバーといったシステムのインフラ設定をデプロイします。また、このクラスタアドオンも Argo CD でデプロイされます。
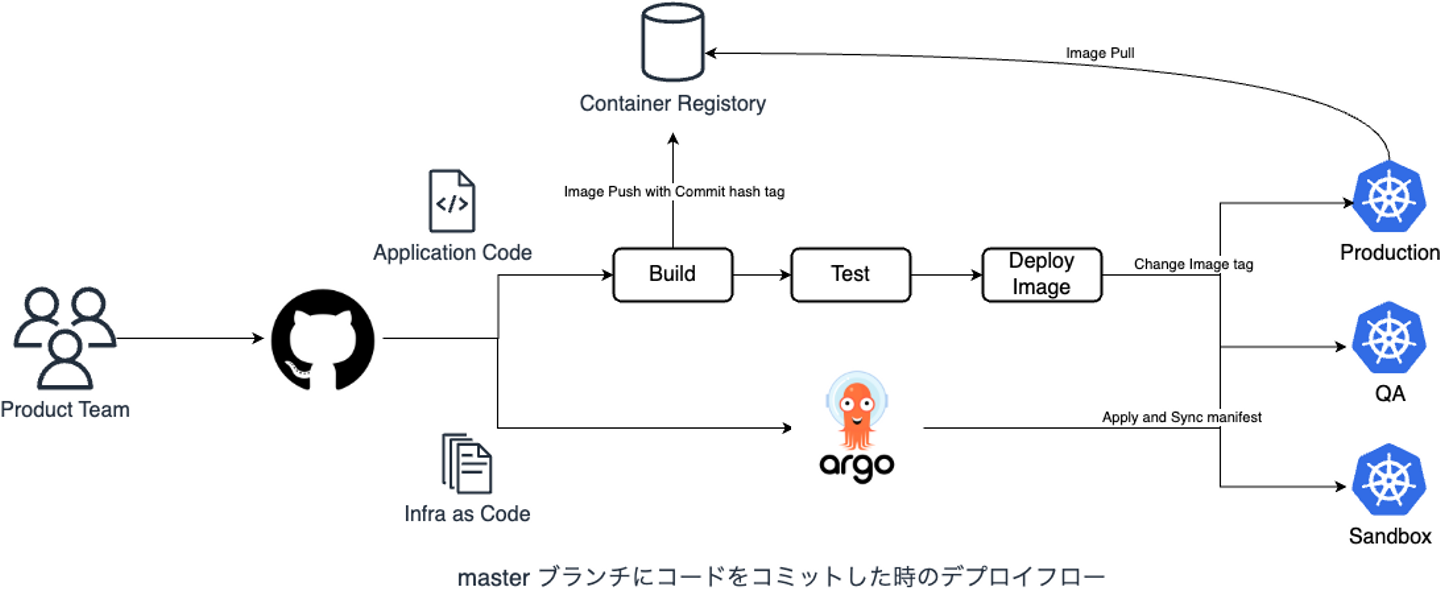
- https://argoproj.github.io/cd/
- Wantedly における漸進的な Argo CD 導入の取り組み
- リリース・デプロイ戦略 - Wantedly Engineering Handbook
Argo Workflow
Wantedly ではデータのオフライン協調 / 非同期処理の戦略として、バッチジョブを採用しています。これらバッチジョブのスケジュール実行を、アプリケーションコンテナと Kubernetes CronJob で実現しています。しかし、ジョブ同士の依存関係や実行順序が存在する場合、時間制御だけでは不十分です。バッチジョブ同士の依存関係を解決しつつスケジュールジョブ実行を実現するツールとして、コンテナベースのジョブ実行基盤である Argo Workflow を採用しています。もう実行スケジュールと処理時間をにらめっこしてジョブ依存を書くのはやめたいユースケース、特に機械学習や複雑なデータ集計のジョブ実行です。
AWS EFS CSI Driver
Amazon EFS を Kubernetes リソースとして扱えるようにする拡張です。 Pod 上で機械学習バッチを回したり、長時間実行する ML 開発では、途中で中間生成物を消失した場合にジョブが初めからやりなおしとなり、時間がかかってしまいます。都度中間生成物を S3 などのオブジェクトストレージに保存しておけばよいですが、こまめに保管するために気をつけるのも限界がありますし、k8s Node にスポットインスタンスを使っているため、突然開発中の Pod が消えることもあります。また、複数の Pod で成果物を共有しながら実験を回したい。こんな状況でも機械学習の開発をスムーズに行うために、Amazon EFS を Pod に接続し、ファイル書き込みを可能にしています。この辺は推薦基盤チームのニーズに対していろいろ試行錯誤しています。
aws-for-fluent-bit
Kubernetes 上で動作するコンテナログを S3 に保管するために fluentbit を利用しています。S3 のコンテナログは永続的に保管して Athena で検索可能にしています。そのままインストールしてしまうと S3 の PutObject の API コールが大量に発生してお財布に厳しいので、バッファリングやフラッシュ間隔などを調整しています。
aws-loadbalancer-controller (AWS Load Balancer Controller)
Kubernetes Ingress の実装として AWS Elastic Load Balancer を使えるようにする拡張です。Web サービスのインフラとして AWS で Kubernetes を利用する場合、Ingress においては第一候補と言って良いのではないでしょうか。Wantedly のメインのサービスはほとんど ALB を使っています。
v1 のときは AWS への API コールが多くて RateLimit かかかってしまい、Terraform の方の AWS API も失敗してしまう事象に悩まされていましたが、いろいろいじったのか v2 になって安定したのか、その頻度は少なくなったように感じます。
cert-manager
クラスタ内で SSL 証明書を作成・管理するための拡張です。弊社ではこのツールで本番サービスの SSL 証明書を管理することはしていませんが、内部の開発ツールや cert-manager に依存するアドオンがあるためにインストールしています。
cluster-autoscaler
k8s Node を Pod のリソースリクエストに応じてオートスケールするための拡張です。各クラウドプロバイダーに対する実装があります。AWS の場合は Auto Scaling Group (ASG) による実装です。GKE なんかはデフォルトでインストールされていますが、EKS ではユーザーが自分でインストールしないといけません。
なお AWS で k8s Node のオートスケールを実現するツールと言えば Karpenter があります。これは ASG ではなくより AWS ネイティブな実装になっているため、Node (EC2 インスタンス) 起動が高速であったり、リソース状況によって最適なインスタンスタイプを自動で選択してくれるので管理が楽になっていたりしますが、まだ試せていません。
CoreDNS + cluster-proportional-autoscaler
Kubernetes クラスタ内の名前解決として CoreDNS がインストールされていますが、このディレクトリでは CoreDNS のオートスケーリングを実現する cluster-proportional-autoscaler の設定ファイルが管理されています。CoreDNS は EKS アドオンで AWS リソースとして管理されています。ディレクトリ名が coredns なのは、かつて EKS ではなく自前で Kubernetes on EC2 で構築していた時、自分たちで CoreDNS をインストールしていた名残です。
custom-metrics (prometheus + prometheus-adapter)
Pod の水平オートスケールである Horizontal Pod Autoscaler (HPA) を、リクエスト数に応じてスケーリングを可能にするためのカスタムメトリクスの提供を実現します。実態としては Prometheus と prometheus-adapter により、Nginx のリクエスト数である `nginx_connections_current` や Envoy の各種メトリクスを HPA で扱えるようにしています。社内では custom-metrics namespace として管理しています。
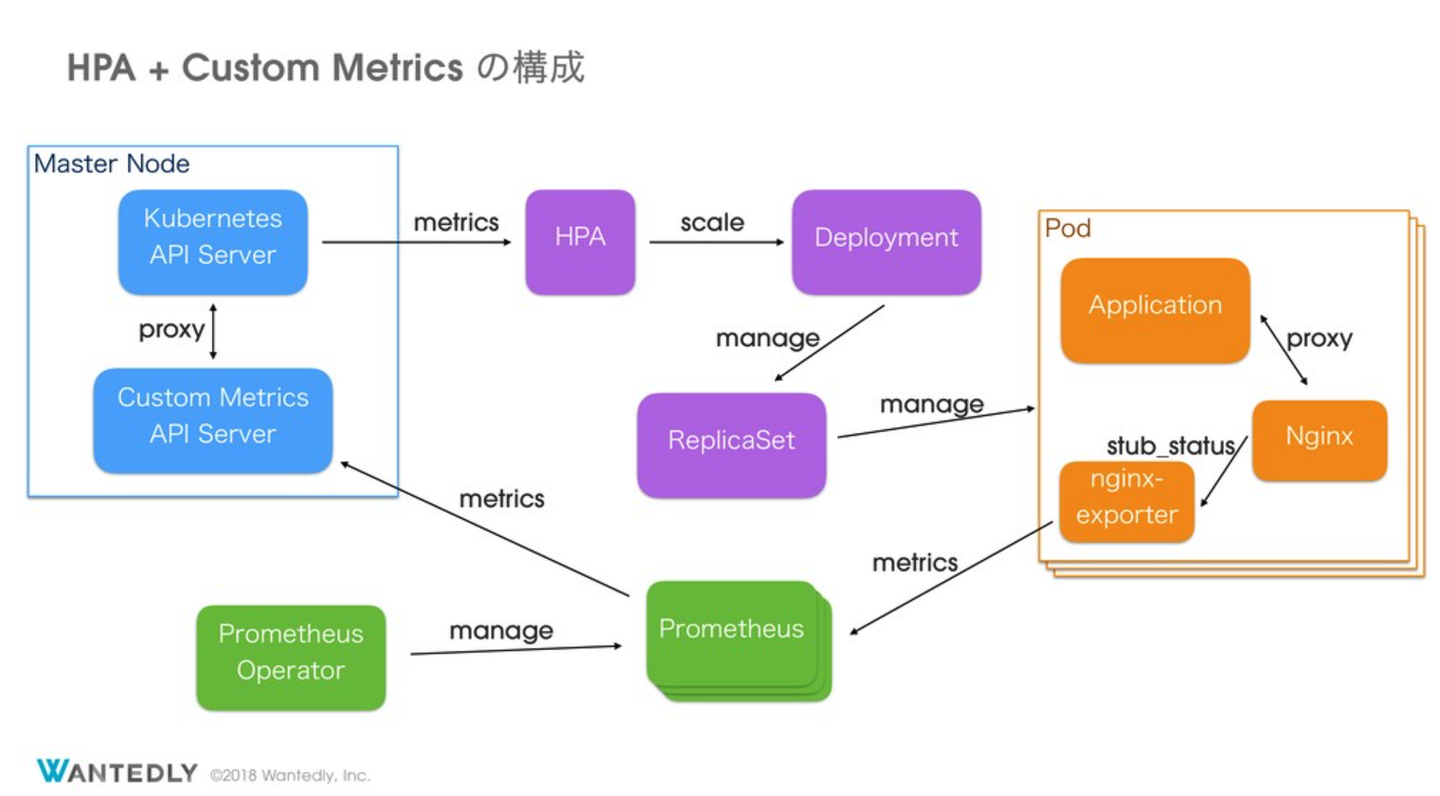
dd-agent (Datadog Agent)
Datadog Agent です。Kubernetes や Prometheus のメトリクスの他、アプリケーションの Trace や Log を Datadog に提供します。また、PostgreSQL や Redis、Elasticsearch などのミドルウェアのメトリクス収集も担当します。
Datadog Agent の manifest 管理は結構難しく、メトリクスやフラグの変更、それに伴う manifest の変更によって簡単に壊れます。しかもサービスに直接影響が出るわけではないので、監視が壊れてないか監視することはとてもむずかしいと感じています。少なくとも helm chart での manifest 管理を行い、メトリクスやフラグの変更に伴う manifest の変更は自動で書き換えられるようにしておくと吉です。
dex
Wantedly の Kubernetes クラスタ認証は GitHub と連携されており、その実装に使っています。Dexは OpenID Connect (OIDC)とOAuth 2.0をベースにしたアイデンティティと認証プロバイダーとして振る舞います。EKS は OIDC で認証認可を設定できるため、dex の OIDC としてのバックエンドを GitHub OAtuh に接続し、EKS --(OIDC)--> dex --> GitHub OAuth App というフローで認証認可を GitHub で行っています。
また、kubectl における OIDC 認証は kubelogin という OSS にお世話になっています。
- https://dexidp.io/docs/kubernetes/
- https://github.com/int128/kubelogin
- https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/enable-iam-roles-for-service-accounts.html
external-dns
Ingress リソースの annotations にサブドメインを記述することで、自動的に Ingress にサブドメインの名前解決のための設定を行ってくれる拡張です。本番サービスのドメインは DNSimple と Terraform で静的に監理していますが、開発環境や開発ツールのサブドメイン設定は external-dns で動的に行っています。
fluentd-servicex
アプリケーションのアクセスログとイベントログを BigQuery に転送するための Fluentd です。アプリケーションの共通ライブラリである servicex が、クラスタ内の Fluentd k8s service にログを送信し、この fluentd-servicex Daemonset が BigQuery に転送します。fluentbit はコンテナログ専門なので、少し役割が違います。別れていることで障害分離やそれぞれのチューニングができるのですが、ややこしいですね。
hnc (Hierarchical Namespace Controller)
namespace で親子関係の構築とリソースの伝搬を行うことができる CRD です。活用シーンとしては権限管理コストの低減です。RBAC など全 namespace で共通で作成されてほしいリソースがあります。これらを開発者がそれぞれのリポジトリで管理してしまうと、追加・変更漏れなどアクセス制御設定の統制が取れなくなってしまうため、親 namespace の RBAC リソースを子の namespace に伝搬させることで、重要な RBAC の変更箇所を1つにしつつ確実に全 namespace に設定することができます。
ingress-nginx (Ingress-NGINX)
Ingress 実装の一つです。サービスで利用している Ingress は ALB がメインですが、Ingress-NGINX は Wantedly における 社内ツールやダッシュボードなど開発向けのエンドポイントに利用されています。
導入当時、エンドポイントに対して oauth2-proxy による GitHub 認証が一番簡単に実現できたため採用されています。いまでは dex と OIDC で任意の認証認可が ALB でできるように基盤が整理されたため、そのうち使うのをやめるかもしれません。
Istio
マイクロサービスアーキテクチャにおいてサービスメッシュを構成するコンポーネントです。Wantedly では gRPC のロードバランシングを目的として導入されました。2023年12月時点では ネットワークのメトリクスや可視化、FeatureFlag 機構で必要なコンテキスト伝搬の実装として使われています。
k8nskel (内製)
特定 namespace の k8s secrets を複数の namespace に伝搬させる CRD です。前述した HNC がなかったころに自作したものです。そのうち HNC に置き換えられると思います。
k8s-cd (内製)
GitHub の Pull Request 上のコメントで kubectl apply をするためのリソースです。実行環境とコードは CircleCI の job と k8s RBAC 設定なのですが、apply のための k8s service account や ClusterRole / ClusterRoleBinding など強い権限が必要なので個別のディレクトリで管理されています。
kube-apiserver
EKS では Kubernetes API のエンドポイントでカスタムドメインや SSL 証明書を利用できません。いままで自前 Kubernetes クラスタで運用していた時は Kubernetes API エンドポイントを独自ドメインで設定しており、そのエンドポイントに依存する社内開発ツールが多いため、EKS でも カスタムドメインで Kubernetes API エンドポイントを設定しておきたいという要求が EKS 移行において発生しました。
実態としては デフォルトのクラスタ内部の Kubernetes API ( default/kubernetes service ) をプロキシする Ingress-NGINX を使ったカスタムドメイン、社内認証の設定入りの Ingress リソースです。
kubecost
Kubernetes リソースに対する料金を可視化、モニタリングしてくれる OSS です。導入する前までは Pod の数や CPU / Memory の利用状況と EC2 インスタンスの料金から Namespace や Pod あたりの料金を算出したりして頑張っていましたが、kubecost ではダッシュボードを見るだけでいいのでだいぶ楽になりました。
kubernetes (default k8s resources)
Kubernetes の default resource を宣言的に管理するディレクトリ。クラスタにデフォルトで入っているリソースに対して変更を加えたい場合に使います。いまは default/kubernetes service の設定だけが管理されています。メトリクス収集で annotation を追加したかったためです。というかディレクトリ名 kubernetes ってめちゃくちゃわかりにくいですね。あとで変えます。
loki (Loki + Promtail + Grafana)
コンテナログをリアルタイムに収集・可視化するコンポーネントです。loki + promtail + grafana 一式の manifest が管理されています。
もともとコンテナログは S3 と Athena で保管・検索していましたが、Athena の検索が遅くて使いにくかったため、直近のログを高速に検索できるように導入しました。しかし Loki では長期間のログの検索ではクエリがエラーになってしまったりと、コンテナログ周りの課題はまだかなりあります。
metrics-server
クラスタ内のリソース状況を収集し、ダッシュボードや HPA を動作させるためのコンポーネントです。クラスタ運用においてはかなり基本的なコンポーネントですが、EKS においてはデフォルトでインストールされていないので自分たちで管理する必要があります。
nodelocaldns (NodeLocal DNSCache)
NodeLocal DNSCache (https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/) は Kubernetes 公式が提供している kube-dns (CoreDNS) に対する DNS の問い合わせの結果をキャッシュするための拡張機能です。この拡張機能をデプロイすると各 Node に DaemonSet として NodeLocal DNSCache (CoreDNS) が立ち上がり、また Node 内の各 Pod の DNS query は kube-dns ではなく Node 内に存在する NodeLocal DNSCache の Pod に対して DNS の問い合わせを行うようになります。
Node 内の Pod の DNS の問い合わせを kube-dns ではなく Node 内に存在するキャッシュ用の DNS に行うようにすることによって、DNS の信頼性の向上が見込めます。
nvidia-device-plugin (k8s-device-plugin)
NVIDIA 製の GPU を搭載した Kubernetes Node を、GPU を Kubernetes の resources として認識できるようにして Pod から使えるようにするための Kubernetes device plugin の一種です。
Kubernetes で GPU を利用する別のアプローチとして NVIDIA GPU Operator (https://github.com/NVIDIA/gpu-operator) があります。 しかし当時の GPU Operator は EKS が公式で提供する AMI (Amazon Linux 2, Ubuntu 20.04) に対応しておらず、GPU Operator を使うことができなかったため、AWS が公式で紹介していた NVIDIA device plugin を利用する方法を採用しています。
oauth2-proxy-manager (内製)
Ingress NGINX に対して oauth2-proxy を使って GitHub 認証を実現しています。1つの Ingress NGINX に対して oauth2-proxy は1つ必要なのですが、新しい Ingress が増えるたびに oauth2-proxy リソースをつくるのが面倒だったので、 oauth2-proxy-manager というものを自作しています。Ingress の annotation に設定をしておくだけで oauth2-proxy リソースを自動的に作ってくれる CRD です。
Prometheus Operator
Prometheus Operator は Kubernetes における監視ツールである Prometheus を管理運用するオペレーターです。Prometheus Server や周辺コンポーネントと Kubernetes リソースとして管理できます。
Wantedly では大きな Prometheus Server は運用しておらず、必要に応じて Namespaced な Prometheus Server を運用することが多いです。パッと Prometheus Server を構築するときにはとても便利に使っています。
rbac
k8s cluster 内での任意の GitHub User / Team の権限を管理する為のディレクトリです。具体的には、ClusterRole や ClusterRoleBinding の manifest file を配置しています。
Wantedly での「環境ごとの権限管理の方針」に基づき、Namespace や Admin / Developer / Biz などのロール・チームごと権限や、ロール・チームの親子関係定義(HNC を利用)が設計されています。1つの YAML にそのチームの ClusterRole や ClusterRoleBinding、システム権限の場合は ServiceAccount も定義されます。以下は YAML ファイルの配置例です。ディレクトリが namespace になっており、ディレクトリ階層構造が親子関係になっています。
.
├── README.md
└── sandbox # クラスタ名
├── deploy-members.yaml # deploy-members Group のクラスタ全体権限セット
├── developers.yaml
├── kubernetes-deploy-experimental.yaml
├── wantedly-inc # wantedly-inc Namespace を継承する Namespace の権限セット
│ ├── hierarchyconfiguration.yaml # wantedly-inc Namespace に対する親子関係の定義
│ ├── managed-by-bizeng-and-developers # managed-by-bizeng-and-developers Namespace を継承する Namespace の権限セット
│ │ ├── bizeng.yaml
│ │ ├── deploy-members.yaml
│ │ ├── developers.yaml
│ │ ├── hierarchyconfiguration.yaml
│ │ ├── kube-ci-deploy.yaml
│ │ └── namespace.yaml
│ ├── managed-by-developers # managed-by-developers Namespace を継承する Namespace の権限セット
│ │ ├── deploy-members.yaml # managed-by-developers Namespace を継承する Namespace の deploy-members Group 権限セット
│ │ ├── developers.yaml
│ │ ├── hierarchyconfiguration.yaml
│ │ ├── kube-ci-canary.yaml
│ │ ├── kube-ci-deploy.yaml
│ │ ├── kube-ci-sh.yaml
│ │ └── namespace.yaml
│ └── namespace.yaml # wantedly-inc Namespace の定義
└── wantedlybot.yamlStorageClass
Kubernetes クラスタで永続ボリューム (Persistent Volume) をプロビジョニングするための StorageClass の設計および manifest です。Wantedly ではステートフルなアプリケーションも Kubernetes クラスタで動かすニーズがあります。現状 Amazon EBS / EFS の2種類の provisioner を使っています。
- Elasticsearch の StatefulSet / Data volume
- 開発環境における PostgreSQL / Redis Pod の StatefulSet / Data volume
- 開発環境における機械学習 Pod の データの永続化 Data Volume
Telepresence
Telepresence はクラスタに流れる通信を自分のローカルに流すことのできる便利なツールです。マイクロサービス化が進んだ基盤ではローカルの開発環境でアプリケーションを開発、デバッグするには他のマイクロサービスも起動する必要があり面倒です。Telepresence を使うと開発したいマイクロサービスだけ起動して、あとはクラスタで動いているマイクロサービスを使うことができます。そのためのコンポーネントの manifest が管理されています。
- https://www.getambassador.io/docs/telepresence/latest/reference/architecture
- マイクロサービスでもポチポチ確認するための Kubefork
Vault
HashiCorp Vault は秘匿情報を管理するコンポーネントです。元々、秘匿情報は KMS で暗号化して DynamoDB に格納し、専用の CLI を開発してその利用者が追加・参照・更新・削除を行っていました。しかしそのニーズを満たすかつより高機能な Vault が出てきたため、置換え中です。
まだ secret の管理と一部 CI/CD での連携くらいしかできてませんが、Terraform で作成したクラウドリソースの secret を そのまま Vault に入れたり、クラウドリソースの secret を動的にローテーションしたり、Kubernetes secret と同期したりと使いたい機能がいっぱいあります。
Velero
Kubernetes リソースのバックアップを実現するツールです。Wantedly では 30分に一回、Kubernetes リソースを S3 に書き出してバックアップを行っています。これにより、誤って削除してしまったリソースの復元や、問題が発生した当時の Kubernetes クラスタを再現するなど、クラスタ運用において重要な役割を果たしています。Persistent Volume の snapshot 機能などもありますが、執筆時点ではリソースのバックアップのみを利用しています。そのため、S3 の容量などは問題にはなっていません。
Vertical Pod Autoscaler (VPA)
Pod のリソースを垂直オートスケーリングするためのコンポーネントです。ウォンテッドリーにおいてはスケールアップというよりは、スケールダウンによるコスト削減を狙って導入しています。特に開発環境やQA環境は余剰なリソース(resources.requests)になっていることも多いのですが、VPA によってあまり手間がかからずに削減できています。実際に VPA が壊れて検知が遅れたときはお財布に大ダメージを与えました。
また、意図はしてなかったのですが、メモリリークしている Pod がスケールアップされて救われている場面もあったりしました。
まとめ
Wantedly の Kubernetes クラスタにインストールされているクラスタアドオンを書き出してみました。
どれもシステムの信頼性や開発生産性の向上を目指して導入したもので、失敗して削除したアドオンも実は多いですが、着実に基盤は良くなっているなと感じます。ただしそれ自体の運用で逼迫しないように、不要になったものは捨て、入れ替え、定期的にメンテナンスする、またその仕組みを整えることが大事だなと改めて思います。
仕組みの方もまた今度まとめたいな。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


