/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

Wantedly, Inc.'s job postings
- バックエンド / リーダー候補
- PdM
- Webエンジニア(シニア)
- Other occupations (17)
- Development
- Business
こんにちは。ウォンテッドリーでデータサイエンティストとして働いている市村(@chimuichimu1)です。この記事は Wantedly Advent Calendar 2024 の22日目の記事です。
私は普段業務で推薦システムの開発に携わっており、プロダクトを継続的かつ効率的に改善していくため、コードの内部品質が重要だと感じています。内部品質が保たれていないコードベースでは、機能追加や改善のスピードが落ちるだけでなく、バグの温床にもなります。
こうした内部品質を担保する1つの手段として、静的解析ツールの利用が考えられます。この記事では近年注目されている Python の静的解析ツールの Ruff について紹介したうえで、特にその高速性に焦点を当て、それがどう実現されているかについて深堀りしたいと思います。
Ruff とは
Ruff が高速に動作する理由
並列性
冗長性の排除
整数値の解析における工夫
トークン位置のインデックスにおける工夫
おわりに
Ruff は Python 用の静的解析ツールであり、ソースコードにおける構文エラーやスタイルの問題を検出することができます。Ruff の特徴として、以下があげられます。
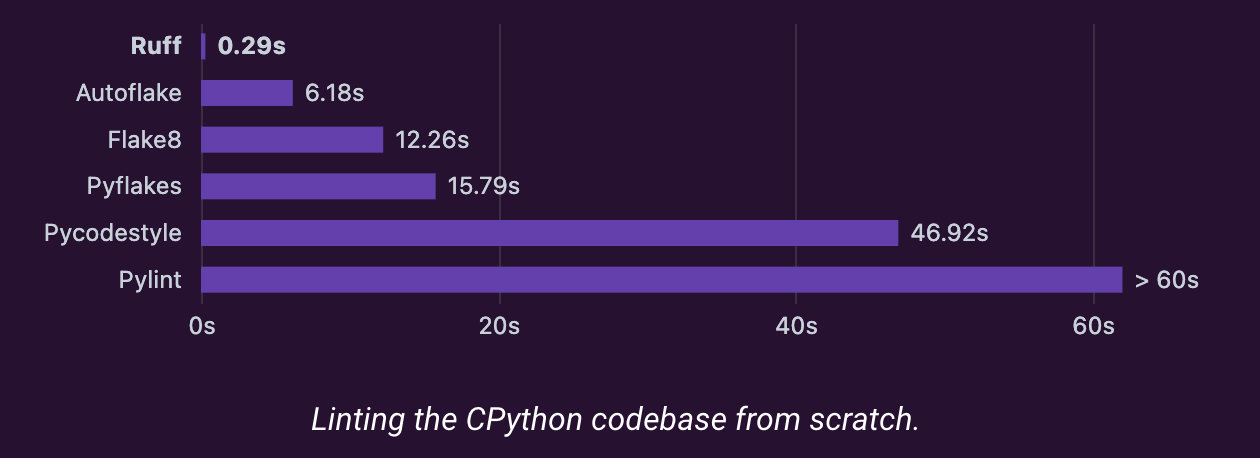
Ruff を使用するメリットとして良くあげられるのが、前述の「高速性」です。以下の図は CPython のコードベースのリントにかかる時間を、各静的解析ツールで比較したものです。他のツールと比較し、Ruff の処理速度が群を抜いていることが分かります。
CPython のコードベースに対する各ツールのリントにかかる時間(公式ドキュメントより抜粋)
Ruff のこの高速性について気になり調べていたところ、PyCon US 2024 で Ruff: An Extremely Fast Python Linter and Code Formatter, Written in Rust という発表があったことを知りました。この発表では Ruff の開発者である Charlie Marsh 氏が、 Ruff のパフォーマンス改善に関する設計や最適化の取り組みを紹介しています。以下ではこの内容をもとに、Ruff の高速性を支える工夫をいくつか抜粋して紹介します。なおこの発表は PyCon US 公式が動画を YouTube に公開しています。
前提として Ruff は Rust 言語で書かれたツールであり、Rust の言語としての性能が高速化に大きく寄与していると発表で述べられています。しかしそれだけではなく、Ruff は他にも多くの工夫を取り入れており、これらの工夫が高速性の実現に寄与しています。
Ruff はコード解析の各ステップをファイル単位で並列に実行しています。具体的には、ソースコードのトークン化や構文の解析などを各ファイルで並行して行うことにより、処理速度を向上させています。
また、SIMD(Single Instruction, Multiple Data)を利用することでデータ処理も効率化しています。例えばトークン化のステップにおいて、巨大な文字列から特定のデータを検索する処理を SIMD を用いて最適化しています。
このように Ruff はファイル単位でのマクロなレベルでの並列処理と、個別のデータ処理のようなミクロなレベルでの最適化により、高速な解析を実現しています。
Python のソースコードを静的解析するとき、複数のツールを組み合わせることがあると思います。例えば、pycodestyle で PEP8 に準拠しているかをチェックし、pyflakes で論理的なエラーをチェックする、などです。この場合、各ツールの中でトークン化や構文の解析が行われますが、例えばトークン化は各ツールで同様の処理がそれぞれ独立に実行されることになります。
一方で Ruff はトークン化や構文の解析を一度だけ実行し、その結果を利用して複数のルールを適用します。このアプローチにより冗長性を排除し、解析時間を短縮しています。
幅広い機能やルールを提供するという Ruff の特徴は、1つのツールで多くを実現できるというユーザー視点の利便性だけでなく、パフォーマンスにも寄与しているのです。
Ruff は、Python の整数値を Rust で扱う際の最適化も行っています。Python は任意の長さの整数を扱えますが、Rust では固定長の整数型を使用します。前述の通り Ruff は Rust で書かれているため、Python のソースコードの整数値を解析で扱う場合、その値を Rust で表現する必要があります。Rust の固定長の整数型の範囲を上回る大きな整数値を扱うために、従来はベクタ型で整数値を表現していました。
Rust ではベクタ型のような可変長のデータはヒープに割り当てられるという仕様があり、固定長のデータが割り当てられるスタックに比べてメモリ管理が煩雑となり、パフォーマンスが劣る場合があります。
そこで、扱う整数値が小さい場合は i64 型で保存し、非常に大きな整数の場合のみベクタ型を使用するようにする変更が行われました(Pull Request)。この変更により、可能な限りヒープへの割り当てを抑え、トークン化の処理速度を最大で8%程度向上することに成功したとのことです。
Ruff はソースコード内のトークンの位置を「行と列」で表現するのでなく、バイトオフセットの形式で保持する方法を採用しています。例えば以下の例だと、`import os` の `s` の位置情報を「2行目、9列目」と持つのではなく、先頭から数えて「23」という形式で情報を保持します。
import logging
import os # `s` の位置は、行と列の形式だと「2行目、9列目」、バイトオフセットだと「23」
# ...Ruff はソースコードの解析時に、位置情報からトークンにアクセスしてルールを適用するという処理を大量に行います。「行と列」の表現は解析結果をユーザーにレポートする場面では分かりやすいですが、内部的なデータアクセスにおいては非効率です。例えば「13行目」の位置のコードを参照する場合は、プログラムの改行を先頭から数えながら走査する必要があり、コストが発生します。
過去の Ruff はトークンの位置を「行と列」で保持する形式を採用していましたが、これをバイトオフセットで保持する変更が行われました(Pull Request)。ユーザーに診断結果をレポートするときは、ユーザビリティの観点からバイトオフセットを「行と列」に変換する処理が必要になるのですが、診断結果を伝える必要があるソースコード、すなわち構文エラーなどの問題があるソースコードは、コードベース全体に対して少数であることが多いため、データアクセスの効率化によるメリットが上回るケースが多いです。実際にこの設計変更により、Ruff の全体の処理時間が10%程度短縮されたとのことです。
Python コード用の静的解析ツールである Ruff について紹介し、その高速な処理速度を支えるテクニックについてお話しました。Ruff の優れたパフォーマンスは「Rust で開発されているから」という理由だけではなく、多くの地道な設計や最適化の工夫により、実現されていることが分かりました。
本記事のもとになっている PyCon US 2024 の発表では、この記事では紹介しきれなかったテクニックについても触れられています。また、Ruff の開発における文化として、小さな改善の積み重ねや、データに基づく意思決定の重要性にも触れられています。とても興味深く、参考になる内容なので、本記事を読んで興味を持たれた方は、ぜひ発表を視聴してみてください。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()



/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)