/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

Wantedly, Inc.'s job postings
- バックエンド / リーダー候補
- PdM
- Webエンジニア(シニア)
- Other occupations (17)
- Development
- Business
これは Wantedly Advent Calendar 2024 の19日目の記事です。
こんにちは、ウォンテッドリーで Infra Squad に所属している donkomura です。普段は趣味としてボルダリングを楽しんでいますが、インフラエンジニアとしては Amazon S3 のコスト改善をした話をしたり、 Datadog APM の小話をしたりしています。
ウォンテッドリーのインフラを支える Infra Squad では、サービスの信頼性を維持・向上させるために SLO の導入や社内ツールの最適化などの施策を実施し、ユーザーに継続的に価値を届けるための基盤を整備してきました。アラート設定もその一つです。アラートはサービスに異常が発生した場合やサービスが不安定になった時に関係者に状況を知らせるための仕組みです。本来であれば異常を知らせるものですが、異常がほとんどないにもかかわらず通知される場合があります。それによって関係者が頻繁に対応を迫られることから、しばしば「アラート疲れ」を引き起こします。
本記事ではウォンテッドリーにおけるアラート疲れを低減させてきた歴史と、New Relic から Datadog へ移行する際の失敗談を踏まえて、快適で役立つアラートを Datadog でどのように設定したのかをご紹介します。
ウォンテッドリーのアラート運用の歴史
ウォンテッドリーのアラート運用
アラート疲れを減らす取り組み
New Relic から Datadog への移行
うるさいアラート、静かすぎるアラート
Datadog 移行における快適なアラート設定
アラートを整理する
閾値と集計
as_count() を modifier とするとき集計関数に avg は利用できない
最小値を評価値とする
SLOアラートを利用する
まとめ
アラートについて考える前に、ウォンテッドリーにおけるアラートの運用方法について説明します。
ウォンテッドリーでは以下のようにアラートを運用しています。
上記のように、緊急度と重要度で通知先を分けて運用しています。
詳細な運用方法・問題の調査方法については本記事では触れませんが、気になった方は Wantedly Tech Book をご覧ください。
前節で紹介したようにウォンテッドリーでは 2015 年頃から各モニタリングやアプリケーションのエラーを通知する目的で Slack と PagerDuty を使ったアラートを導入しています。
Wantedlyを支えるモニタリング [2015]
しかし次のような課題があったため、2021年にアラートの設計と運用を見直すことにしました。
同年に行われた改善の取り組みによって、false positive なアラートは排除され確認するべきアラートが明確になりました。また、runbook を整備したことでアラート対応時に行うべき作業や調査方法を調べる手間を少なくすることができました。具体的には以下のような改善施策を実施しました。
モニタリングに利用するツールも変化していきました。現在では次のようなツールを利用しています。
その他の利用 SaaS については Wantedly Engineering Handbook [SaaS] [Dashboard] を参照してください。
アプリケーションに関するメトリクスは New Relic と Datadog の両方で監視していました。分散トレーシングのためのライブラリとして OpenCensus を導入した2019年頃から本格的に Datadog を利用しており、マイクロサービスのためのオブザーバビリティを支えていました。そうした歴史的な経緯と機能集約による開発体験の向上やコスト改善を目的としてアラートを含めてすべてのモニタリング機能を New Relic から Datadog へ移行することにしました。これは今年2024年10月から12月にかけて実施されました。
New Relic ではアプリケーションのメトリクスを用いて閾値ベースのアラートを設定していました。これらは先述したように、緊急対応が必要となるアラートや緊急ではないが重要なアラートです。したがって、New Relic から Datadog に移行した後も同様のアラート通知を受け取れるようにすることが求められていました。
New Relic APM と Datadog APM で取得できるデータは完全に一致しているわけではありませんでした。Datadog にトレースが送信されていなかったアプリケーションで重要なものについては計装し、New Relic と同等のアプリケーションのメトリクスを閲覧できる状態にしました。数が多かったためすべてを計装せずに一部のアプリケーションについてはサービスメッシュのメトリクスで代用しました。New Relic と同等のモニタリングが可能なアプリケーションについてはトレースメトリクスを用いることでアプリケーションの状態を観測できる状態にしました。
このようにして分散トレーシングが導入されて以降、併用していたアプリケーションのモニタリング機能を Datadog に統一しました。
Datadog でモニタリングの基盤を整えた後、アラートの移行に取り掛かりました。アラートを移行すると次のようなアラートがあることが分かりました。
アラート疲れの要因ともいえるうるさいアラートは New Relic では整理されて無くなっていましたが、Datadog に移行した際に出現しました。後に Datadog で誤った設定をしていたため、うるさいアラートとなっていることが分かりました。また、同様に静かすぎるアラートもありました。これらのアラートがあるとユーザー体験に異常のある問題が発生した際に気づくことができなかったり、サービス復旧や原因の特定などのアクションをすぐに取ったりすることが難しくなります。
次節では Datadog でアラートを設定した際の誤りと適切なアラートを設定する方法について説明します。
ここからは Datadog でどのようにアラートを設定したのかを説明します。アラートは Datadog Monitor で実現されています。ここでは特に言及がない限り、閾値ベースのアラートに基づいて説明しています。
New Relic から Datadog へ移行する際にアラートの整理を行いました。
既に Datadog で設定されているアラートを廃止したり、New Relic で重複のあったアラートは単一のアラートに集約したりすることで、必要なアラートのみを移行することにしました。
Synthetic Monitor については New Relic で意味のあるものとして長らく利用されていたため、そのまま Datadog Synthetic Testing and Monitoring に移行しました。
Datadog ではアラートは Datadog Monitor という機能を用いて実現されています。
Datadog Monitor では評価ウィンドウ(evaluation window)という評価時間幅内でメトリクスの集計を行い、評価値を計算します。算出された評価値が閾値を超えた場合に通知されます。
New Relic で設定されていたアラートには主にエラーレートとレイテンシの2種類のアラートがありました。
エラーレートのアラートを移行する際に、当初 avg を用いて評価ウィンドウ内のメトリクスを集計していましたが、OK/NGが繰り返し発生するアラートが多かったり New Relic の時よりもエラーレートが高く計算されていることが分かりました。
調査したところ、これらは以下のような集計の問題が原因であったことが分かりました。
as_count() を modifier とするとき集計関数に avg は利用できないas_count() では次のように評価値が計算されます。
avg(last_5m):error
-----------------
avg(last_5m):totalこれは想定していたエラーレートを計算することができません。つまり、 as_count() は avg と併用できません。区間内のリクエスト数の分散によって評価値が大きく変わっていたため、false positive / false negative なアラートとなっていました。
エラーレートを avg で集計する際には as_rate() を利用すると想定通りの評価値を計算することができます。
avg(last_5m):error/totalDatadog への移行時に平均 avg() で評価値を計算していましたが、最小値を計算することで「直近N分以内で継続的にX%のエラーレートであれば通知する」アラートを作成することができます。これにより、問題があった場合にすぐに気づけるだけでなく、アラートのバタつき (flapping) を抑えることができます。
[100, 105, 110, 120, 5000] というメトリクスがあるときmin() で計算すると 100 となる。avg() で計算すると 1087 となる。ユーザーに影響はないが、たびたびスパイクするようなメトリクスではアラートがバタついてしまう(false positive となってしまう)。上記のような問題を修正して SLO や他のアラート・メトリクスと組み合わせて観察したところ、アプリケーションに異常のある場合にのみ通知されることが確認できました。
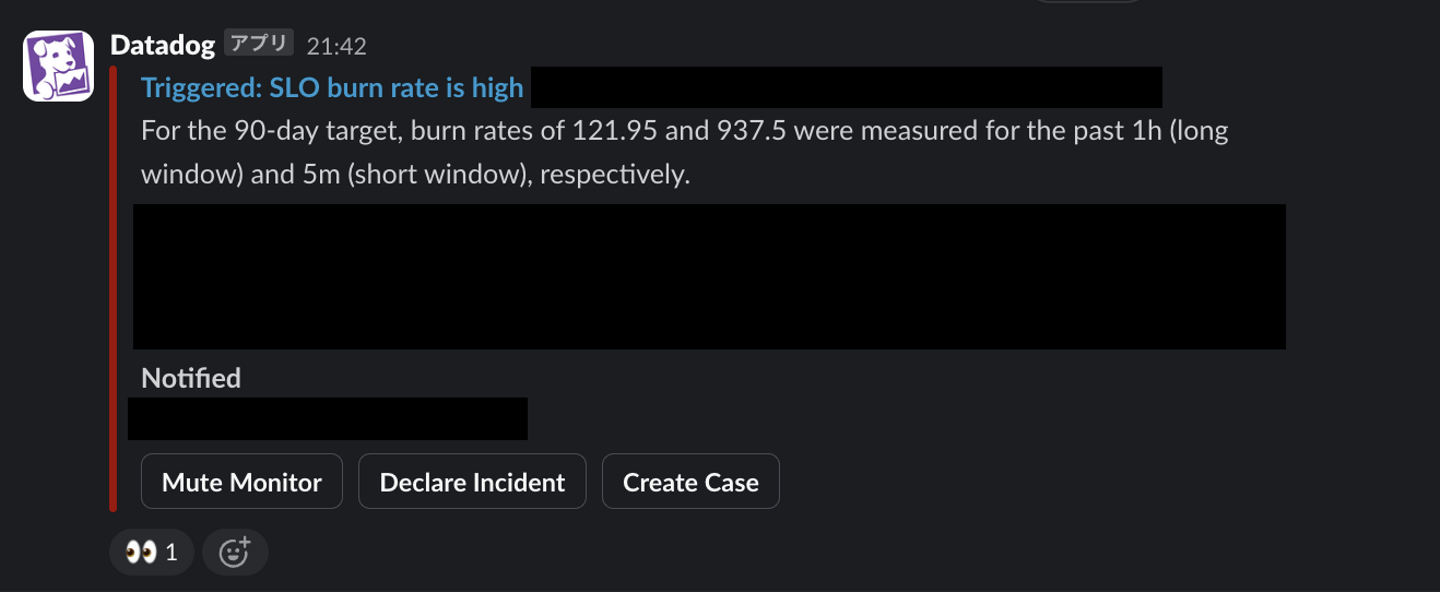
ウォンテッドリーでは SLO (Service Level Objective) を運用しており、ユーザーに影響のある問題に対してアクションが取れる体制を整えています。SLO 対象の機能をリアルタイムに近い間隔で監視し自動で通知するような仕組みとして Burn rate alert を導入しています。
Burn rate alert は対象となる SLO に対して Long/Short window で指定した期間における burn rate (Error budgetの消費量を示す度合, Error budget は SLO に対して許容できる異常系・エラーの割合のこと) を計算して、両方の window で閾値を超えた場合に通知します。
これまではひとつの Burn rate alert を運用してきましたが、Long window が24時間と設定していたため問題の検知に時間がかかっていることから、閾値設定の難しさを感じていました。これを解消するために The Site Reliability Workbook の “6: Multiwindow, Multi-Burn-Rate Alerts” で紹介されているように、multi-window の burn rate alert の導入を進めています。SLO と burn rate alert については明日の Advent Calendar の記事で詳しくご紹介しますので、ぜひお楽しみにお待ちください。
この記事では、ウォンテッドリーでの「アラート疲れ」を低減してきた歴史を紹介しました。後半は New Relic から Datadog に移行した際に誤ったアラートの設定を紹介し、どのように疲れないアラートを構成したのかを紹介しました。
適切なアラートを設定することで、サービスの信頼性を維持し、対応する従業員の負担を減らすことができます。今後もアラートの運用を改善しながら信頼性の高いサービスを提供できる基盤づくりに専念していきたいと思います。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)