
この記事は Wantedly Advent Calendar 2024 の 20 日目の記事です。昨日の記事は @donkomura による「快適で役立つアラート - 歴史と実践」でした。Datadog の話が 2 連続です。明日も @bgpat による Datadog Live Tokyo 2024 Reprise への登壇記事が公開される予定になっています。ご興味があればそちらもぜひご覧ください。
ウォンテッドリーの Infra Squad に所属している @fohte です。本記事では、苦戦しながらもなんとか構築できた Datadog SLO を活用した SLO 監視基盤やその基盤の運用について紹介します。
なお、本記事は Japan Datadog User Group Meetup#4 で発表した次の資料がベースとなっています。こちらも併せてご覧ください。
目次
ウォンテッドリーにおける SLO 運用と課題
SLO ダッシュボードで顕在化した課題
Datadog SLO の導入
なぜ Datadog SLO なのか
Datadog SLO の基盤を作るために
Datadog SLO の計測方法は 3 つある
ログから Custom Metrics を作る
URL のグルーピングをどう実現するか
Pipelines の制約をどう回避するか
迅速に気付ける仕組み
Datadog SLO の利点
Datadog SLO の課題
最後に
ウォンテッドリーにおける SLO 運用と課題
ウォンテッドリーでは 2018 年から SLO の運用を始め、ウォンテッドリーが提供しているサービスの異変を早く検知できるようにするために導入されました。サービスを運営する上で重要なエンドポイントにおいて成功したリクエストの比率を SLI として定義し、SLO はそれぞれのエンドポイントにおいて過去 90 日間でリクエストの 99.9 % が成功することを目標として定義しています。現在も継続的に SLO を運用しており、導入時の目的であった「異変を早く検知する」ための指標として活用できています。この運用ルールの整備や課題は、去年の Wantedly Advent Calendar 2023 で @bgpat が執筆した「Wantedly での SLO 運用の現状とこれから」にもまとめられています。
以前は SLO ダッシュボードを内製し運用していましたが、2023 年 6 月から BI ツールである Looker でのダッシュボードでの運用も始めました。Looker は Google が提供していることもあり、BigQuery との連携に長けています。ウォンテッドリーでは BigQuery にさまざまなデータを蓄積しているため、それを元にクエリし、次のように SLO/SLI の状況を俯瞰できるようなダッシュボードを作成しました。
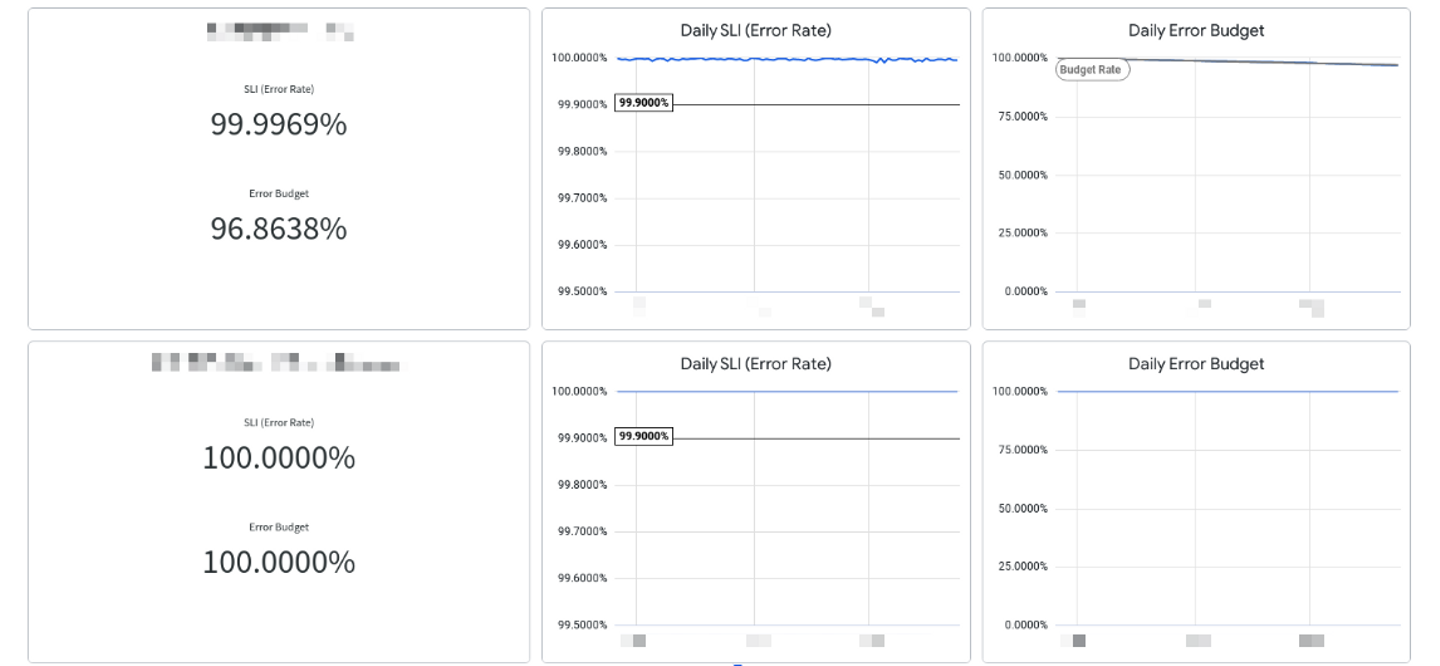
SLO ダッシュボードで顕在化した課題
一見十分機能するように見える Looker のダッシュボードですが、これにはいくつかの課題がありました。
Looker 以前の内製ダッシュボードや Looker でのダッシュボードは、インフラチームがダッシュボードを週次で確認する運用でした。ただ、アラートもなかったため、この運用ではいくつかの課題が顕在化しました。たとえば、仮に error budget が枯渇しても気付くのは週に一度になります。もちろん頻繁に気にかける人がいれば気付くタイミングも増えますが、これでは属人化が進んでしまいます。また、問題があるかどうかを判断する基準が人によって異なるといった課題もあります。明確な基準は error budget が枯渇したかどうかしかなく、error budget が枯渇しそうという場合であっても、このまま様子見でよいのかどうかの判断は見る人に委ねられていました。
Looker ダッシュボードには基盤として運用する上での課題もありました。Looker ダッシュボードでは、エンドポイントごとに BigQuery にクエリして計測していたため、計測対象のエンドポイントが変わるごとにクエリを書き換える必要があります。Looker は Infrastructure as Code のようなコード管理が難しいこともあり、人が手動で書き換える必要があり、レビューも簡単ではありません。計画メンテナンスのように SLO の計測対象からは省きたい場合にもクエリを書き換える必要があったりと、変更がしにくいという課題がありました。
Datadog SLO の導入
これらの課題を解決するために、ウォンテッドリーでは 5 月に Datadog SLO を導入しました。Datadog SLO を用いたダッシュボードは次のようなイメージです。一覧で俯瞰でき、error budget が減っている原因がどのエンドポイントであるかも詳細に見られるようにもなっています。
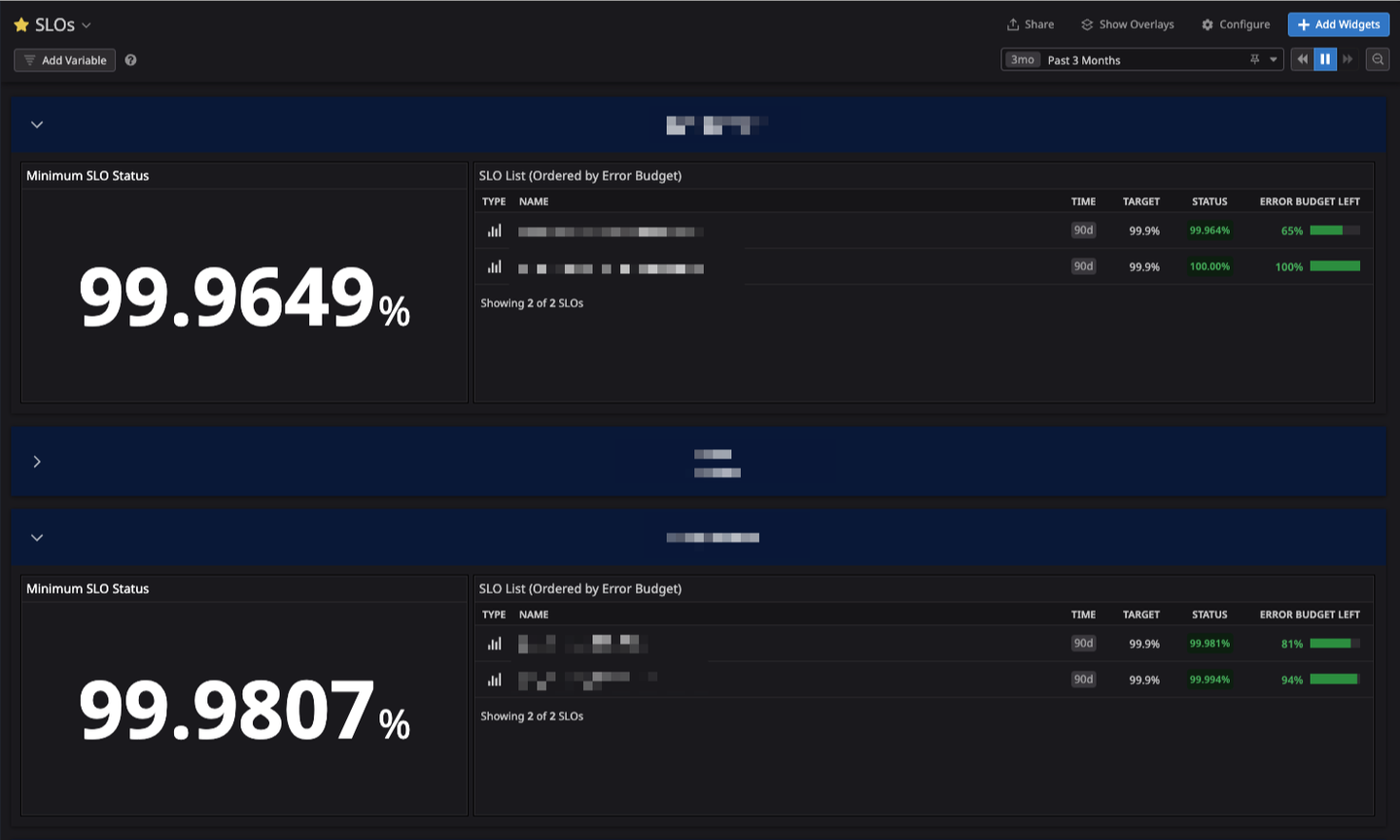
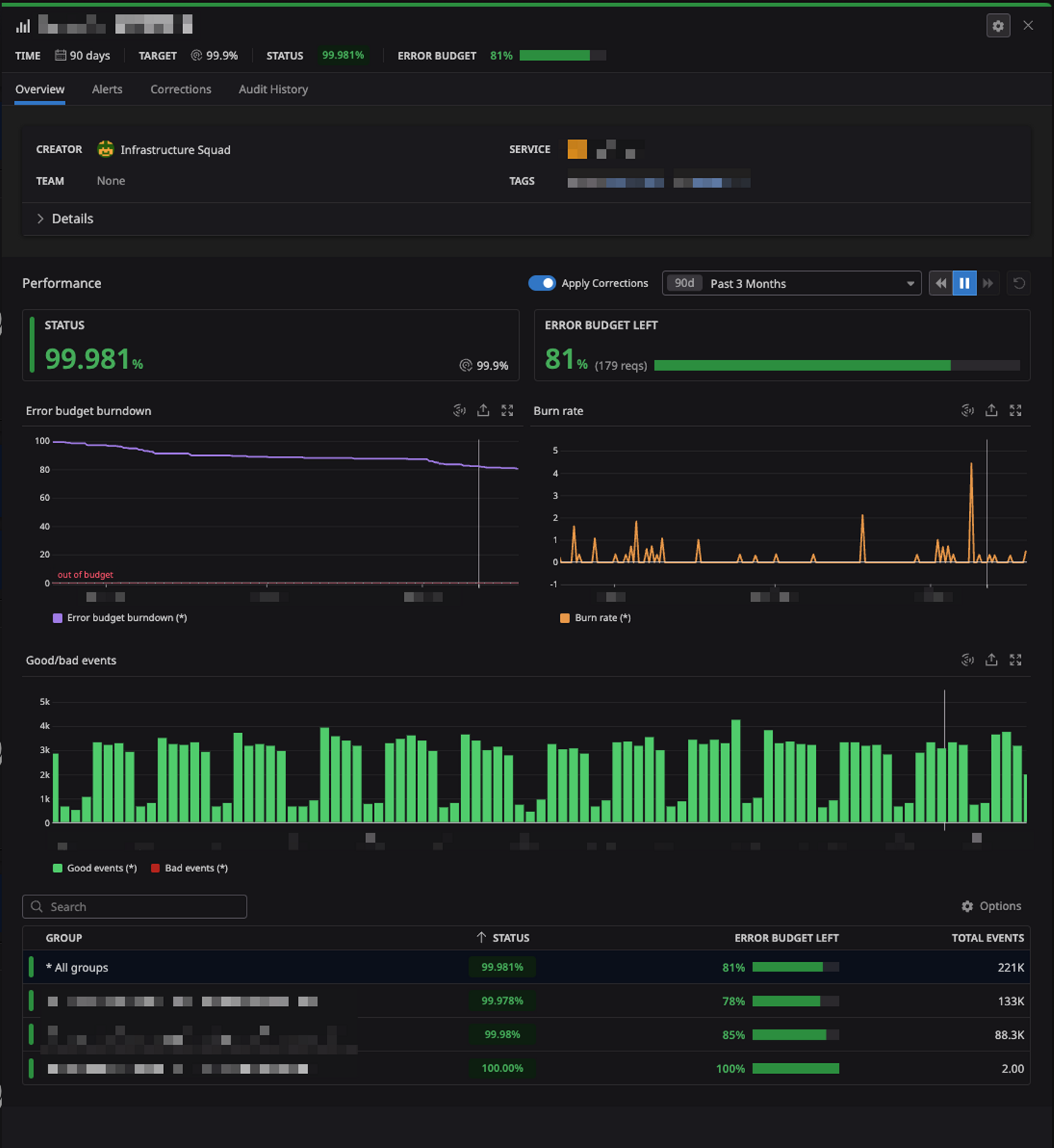
なぜ Datadog SLO なのか
ウォンテッドリーでは Datadog を主にインフラ監視や APM で活用しています。Datadog SLO であれば大きなハードルもなく導入でき、Datadog 上にあるオブザーバビリティ基盤と組み合わせ、よりオブザーバビリティを強化できるのではないかという期待がありました。実際に導入した後の感想としても、SLO の計測対象に問題が起きた際に、どこで問題が起きているのかをエンドポイント単位で俯瞰できたり、Terraform による Infrastructure as Code が実現できたりと、期待どおりの恩恵を受けられました。
Datadog SLO の基盤を作るために
前述のとおり、ウォンテッドリーでは Datadog をすでに活用しています。しかし、実際に Datadog SLO を私たちのニーズに合致させるためには、いくつかの障壁がありました。ここからは、その障壁をどう乗り越えたのかを紹介します。
Datadog SLO の計測方法は 3 つある
Datadog SLO では、Datadog Monitors のようになにかの値をクエリし、その結果を SLO として評価するという仕組みになっています。つまり、そのクエリをするなにかが必要となります。この手段として、Datadog SLO では次の 3 つが用意されています。
- Metric-based SLO
- メトリクスの特定の値や閾値に基づいて評価する
- Monitor-based SLO
- ある Monitor が OK である期間と Alert である期間の割合を評価する
- Time Slice SLO
- 定義された時間枠内において、正常に動作しているとみなした時間の割合に基づいて評価する
- 例: 95 %ile のレイテンシーが 1 秒未満を正常とし、その正常な割合を評価
今回は、ウォンテッドリーでは SLO/SLI をリクエストの成功率で計測しており、この計測方法が実現できる Metric-based SLO を選択しました。
ログから Custom Metrics を作る
Metric-based SLO ということは、クエリするための metric が必要です。しかし、SLO の計測対象であるエンドポイントのエラーレートをクエリできるような、やりたいことに完全に合致した metric はなく、custom metrics を作成することにしました。Datadog では custom metrics を作る手段がいくつかありますが、今回は Datadog Logs に蓄積されていたリクエストのログをもとに custom metrics を生成しました。
ここには大きな障壁があります。たとえばユーザーのプロフィールページのエラーレートを計測したいとき、slo_requests{url:"https://wantedly.com/id/*"} のようなクエリが考えられますが、これは実現が困難でした。custom metrics の料金体系はタグの key/value ごとに別の custom metrics としてカウントされ、その custom metrics ごとに課金が発生します。たとえば、リクエストがあった URL をそのままタグに含めた場合、URL の種類は無尽蔵に存在するためかなりの額の課金が発生することとなります。筆者の Wantedly Visit のプロフィールページであれば https://wantedly.com/id/fohte という URL ですが、この fohte の部分はユーザーによって異なります。動的なパスがあると、タグのバリエーションが無尽蔵に増えることとなり、その数に応じて課金も発生します。クエリパラメーターも含めようとなると、非常に多大な課金が発生すると想定できます。
ではこの障壁をどのように乗り越えればよいでしょうか。今回は、URL をグルーピングするという手法を取りました。先の例であれば https://wantedly.com/id/:id のように、動的な部分を :id のような placeholder に変換します。こうすることで URL が静的となり、タグの数とそれに応じた料金も予測でき十分許容できるものに収まります。
URL のグルーピングをどう実現するか
URL のグルーピングというアイデアの実現にも大きな障壁がありました。まず、ここまでのフローを整理すると、次のようになっています。
- Datadog Logs にあるログから custom metrics を生成
- この custom metrics をクエリして SLO を設定
ログにはリクエストされた URL が入っているものの、動的部分が :id のような placeholder にはなっていません。今回は custom metrics を生成する段階で URL をタグとして設定したいため、ログを Datadog Logs に送信する前か、Datadog Logs 自体で変換する処理が必要となります。そこで、今回は後者の Datadog Logs 自体で変換ができる Pipelines を使うこととしました。
Pipelines の制約をどう回避するか
Pipelines にはさまざまな processor が用意されています。Pipelines では、純粋なテキストデータであるログを parse し、これらの processor を通して処理した結果をログのタグや属性として設定できます。この設定されたタグや属性をもとに custom metrics を作成し、タグを作成できるようになっています。
これを活用し URL のグルーピングを実現するための方法として、たとえばログのテキストに含まれる URL を抽出し、/id/\d+ という正規表現にマッチしたときに /id/:id に置換するという処理が考えられます。しかし、現在の Pipelines には正規表現にマッチして特定の属性を設定する processor (Grok parser) はあるのですが、置換処理がありません。ここが今回 Datadog SLO での基盤を作る上でのもっとも大きな障壁でした。
ではどうしたかというと、次のような processor を設定しました。
- Grok parser でパスを / ごとに区切って属性を設定
- 分割されたパスを Category processor でグルーピング
Grok parser では次のように設定をしており、かなりの力技であることがわかります。なお、anypath は %{regex("[^/]"*)} という helper です。たとえば /id/fohte というパスであれば、path_0: id, path_1: fohte という属性が設定されます。
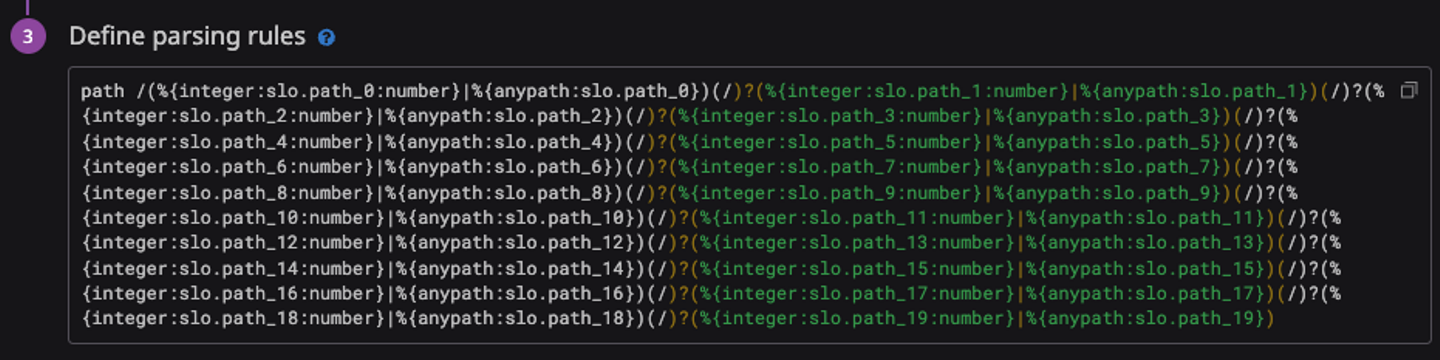
この属性をもとに、Category processor でパターンマッチングをします。Category processor では、特定のクエリにマッチしたものに特定の属性を設定するという処理が可能です。たとえば @slo.path_0:id @slo.path_1:* にマッチした場合に /users/:id に設定する、といった条件が設定できます。これをグルーピングしたいエンドポイントの数だけ設定しています。
迅速に気付ける仕組み
ここまでは Datadog SLO の具体的な設定方法について紹介しましたが、設定するだけで終わりではありません。「週次で確認していて問題発覚が遅れる」という課題の解決も必要です。
そこで今回は、Datadog Monitors の機能である Burn Rate Alerts を利用しました。Burn Rate Alerts は、error budget が枯渇したタイミングだけではなく、burn rate が特定の期間においてある閾値を超えたときにアラートを出す機能です。特定の期間での burn rate を監視することで、error budget が枯渇する可能性が高い場合に気付けるようになります。以前は error budget が枯渇するかどうかをダッシュボードを見る人が error budget の推移を見て判断していましたが、決められた監視方法があることで属人化を防ぎつつ、問題があったときにアラートが来ることで迅速に気付けるようにもなりました。
Datadog SLO の利点
Datadog SLO を導入したことにより、以前の SLO ダッシュボードで特に課題に感じていた問題に迅速に気付けないことが改善され、属人化も防げました。また、custom metrics の生成など SLO として監視するための基盤や、SLO 定義はすべて Terraform で管理しており、SLO 計測対象の変更がしやすい仕組みを実現できています。
また、ウォンテッドリーではインフラ基盤の更新作業などで計画メンテナンスを実施することがあります。この期間のエラーは SLO の計測対象から除外するという運用をしています。以前の Looker ダッシュボードでは、除外するクエリを書くことで計測対象から除外していました。Datadog SLO には機能としてダウンタイムが設定できるようになっており、対象の期間は error budget の計測対象から除外されます。さらにこのダウンタイム設定も Terraform で管理できるため、以前はクエリを書いていたダウンタイム設定は、簡単に設定できレビューができるようにもなりました。
予想していなかった副次的な利点として、どのエンドポイントで問題が起きているかもわかるようになりました。Datadog SLO の Metric-based SLO では、クエリした metric のタグごとにも error budget や burn rate が閲覧できます。今回はたとえば slo_requests{path:/id/:id OR /id/:id/skill-assessment} のようにクエリして SLO を設定しています。このとき、Datadog のクエリとして path で group by によるグルーピングをすると、path ごとに error budget や burn rate が閲覧できます。この例では path で group by していますが、metric のタグがあれば自由にグルーピングできるため、詳細に見たい粒度を自由に決められます。複数のエンドポイントをまとめて SLO として定義している場合に、問題を引き起こしているエンドポイントがどれであるか特定しやすいのは思いがけない利点でした。
Datadog SLO の課題
Datadog SLO の導入により利点が多くありましたが、新たな課題も見つかりました。
大きな課題としては、Logs から生成された custom metric をベースにしているため、custom metrics を生成し始める前の SLO が計測できない点が挙げられます。Logs で生成できる custom metrics は、設定した時点から新しく収集したログに対し custom metrics を生成します。つまり、設定した時点より前のログに対しては custom metrics を生成できません。これは、たとえば SLO の計測対象を増やしたいときに、ウォンテッドリーでは SLO の計測期間を 90 日間としているため、custom metrics のデータが 90 日間分充足するまでの間は短い期間で計測されることとなります。仮に custom metrics を生成し始めてから 1 日後に SLO を設定した場合、その時点では 1 日間での計測になり、本来 90 日間の期間では問題にはならないエラーレートであっても error budget が枯渇してしまうといった課題があります。この課題の有効な対策は模索しており、解決できた際には Wantedly Engineer Blog にて紹介できればと考えております。
最後に
本記事では、Datadog SLO 導入前の課題感から導入時に苦戦した設計や、導入後の利点や課題について紹介しました。完成した基盤は運用を始めてから 6 ヶ月経ちますが、紹介した課題以外では大きな課題はなく、とても便利に活用できています。
1 年前に書かれた「Wantedly での SLO 運用の現状とこれから」では次の課題が挙げられていました。
現在の SLO 運用は毎週エンジニアがダッシュボードを確認することで回しています。また集計には1日かかるシステムになっており、その日のうちに発生した問題については検知できないという課題があります。
これに対処するため、 SLO 対象の機能をリアルタイムに近い間隔で監視し自動で通知するような仕組みを導入しようとしています。いくつかの機能に対して自動アラート設定を有効化したところユーザー体験を損なう問題に早いタイミングで気付けるケースが複数確認できており、全体への適用を進めています。
この課題は今回の Datadog SLO 導入により解決できました。あらためて振り返ってみると継続的な改善がなされていることがわかります。まだ Datadog SLO にも課題は残っていますが、今後も改善を続け、よりよい SLO 基盤を模索していく所存です。
/assets/images/5673658/original/767e046d-422d-44e3-ac17-74af4a96146e?1709547072)

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


