
YAMLは「便利なJSON」として使われることが多い一方、その複雑性から落とし穴も多く、しばしば批判の対象になります。
なぜYAMLはそこまで複雑なのでしょうか? その背景のひとつは、本来のYAMLがJSONとは大きく異なる目的意識で作られているからです。
本稿ではYAML specに従う形でYAMLのコンセプトを解説することを目指します。残念ながら、ここに書かれているYAMLの思想は実際には実用されているとは言い難いですし、これらの背景を理解しても「YAMLは複雑だ」という事実がひっくり返ることはないでしょう。それでも、YAMLの複雑さの源泉を体系的に理解し、YAMLとほどほどの距離感で付き合う助けにはなるのではないかと思います。
この記事ではこういう話をします
- YAMLはJSONとは独立に、異なる目的で生まれた野心的な仕様である
- アンカーやタグなどの強力な構文は、これらの目的を満たすために必然的に生まれてきたもので、単なる便利機能というわけではない
- YAMLの仕様、面白いよ
YAMLの目的
YAMLの目的はYAML specの最初のセクションに明記されています。その中でも重要なのが以下の項目です。
3. YAML should match the native data structures of dynamic languages.
抄訳: YAMLは動的プログラミング言語の固有のデータ構造に適合する(よう設計される)べきである。
つまり、YAMLはRubyのMarshalに代表されるようなデータマーシャリングフォーマットであると位置づけられています。これはJSONがシンプルな直列化フォーマットであることと対照的です。
その上で、Marshalとの差別化ポイントは以下のように述べられています。
1. YAML should be easily readable by humans.
2. YAML data should be portable between programming languages.
抄訳: YAMLは人間によって容易に読むことができるフォーマットであるべきである。YAMLデータは異なるプログラミング言語間を移動可能であるべきである。
つまり、プログラミング言語の違いを吸収し、人間可読であることを要請した汎用のデータマーシャリングフォーマットというのがYAMLの設計の根底にあると理解できます。
また、以下のように拡張性も意図されており、XMLとの対比をうかがわせる内容になっています。
6. YAML should be expressive and extensible.
YAMLパイプライン
データマーシャリングでは、単純な直列化とは異なり、プログラムがメモリ上に持っている構造を正確に表現するために複雑な手続きが必要です。YAMLではこれを3段のパイプラインで表現しています。
- メモリ上のオブジェクトからノードグラフを構築する。
- ノードグラフを展開してイベントツリーに変換する。
- イベントツリーを文字列として表現する。
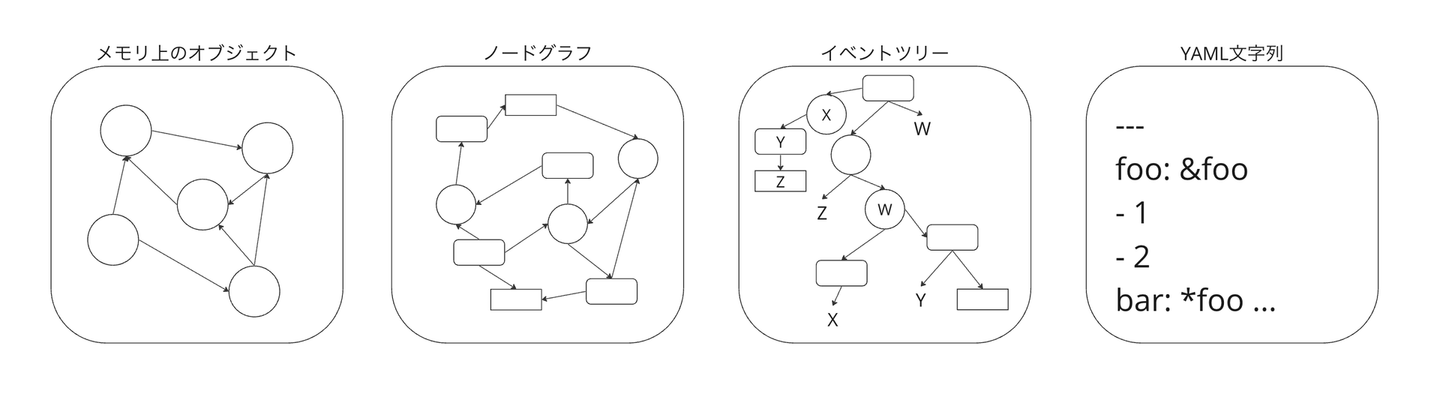
そこで、本稿ではこれらのステージごとにYAMLの特徴を見ていきます。
ノードグラフの構築
オブジェクトをマーシャルするには、まずプログラミング言語ごとに固有のオブジェクトから状態を読み取り、プログラミング言語に依存しない中間形式で表現します。これがノードグラフです。
YAMLのノードグラフにおいて、ノードは3種類しかありません。
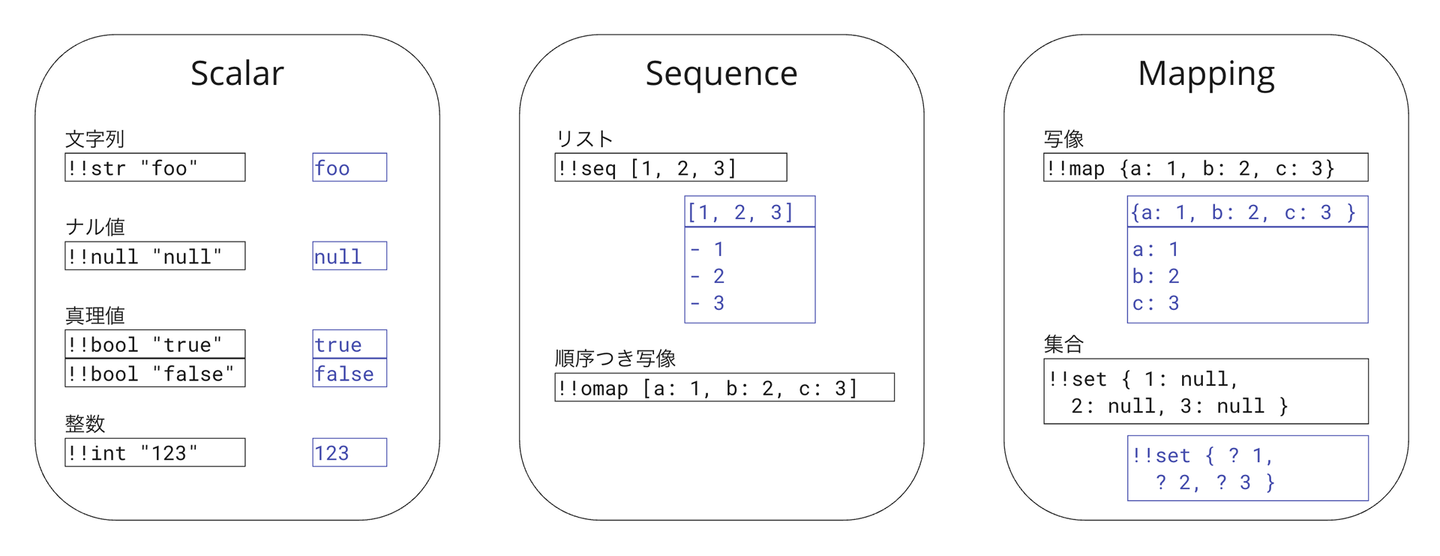
その3種類とは、
- スカラーノード (scalar) -- データを文字列で表現する。
- 列ノード (sequence) -- データを0個以上のノードの並び(順序あり)で表現する。
- 写像ノード (mapping) -- データを0個以上のノードの対の並び(順序なし)で表現する。
です。YAMLを普段使いしている人には直感に反する説明ですが、そのカラクリは以下の通りです。
プログラミング言語の持つ高度なデータ型は、まずこの3種類のノードの組み合わせとして表現されます。そのとき、元のデータ型が何であったかを表現するためにタグという情報が付与されます。タグは全てのノードに1つずつ存在します。
タグは誰でも新しく定義できるように、URIとして表現されます。
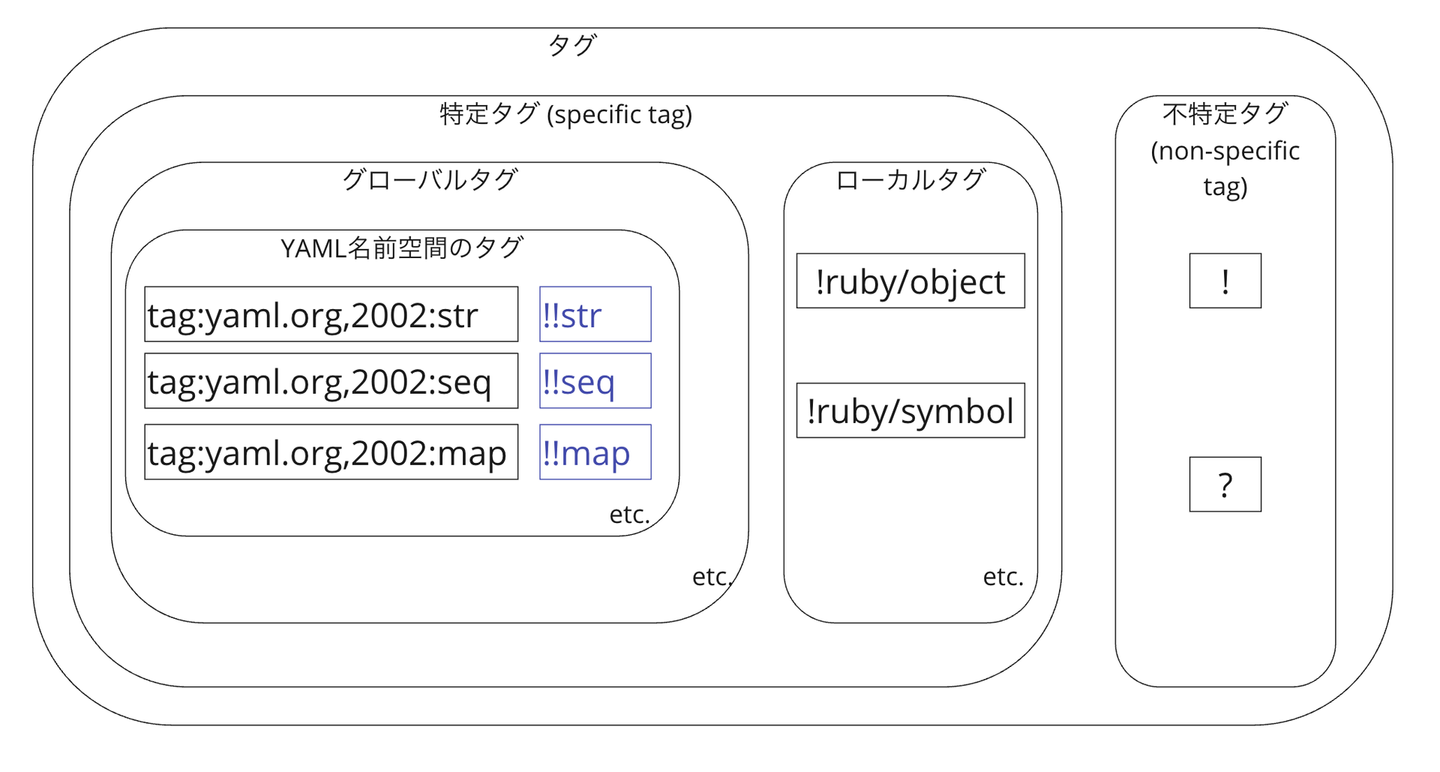
たとえば、よく使われるデータ型には以下のようなタグが割り当てられています。
- スカラーノードで表現されるデータ型
- tag:yaml.org,2002:str ... 文字列 (デフォルトタグ)
- tag:yaml.org,2002:null ... ナル値
- tag:yaml.org,2002:bool ... 真理値
- tag:yaml.org,2002:int ... 整数
- tag:yaml.org,2002:float ... 浮動小数点数
- tag:yaml.org,2002:binary ... バイト列
- 列ノードで表現されるデータ型
- 写像ノードで表現されるデータ型
- tag:yaml.org,2002:map ... 写像 (デフォルトタグ)
- tag:yaml.org,2002:set ... 集合 (順序なし)
各プログラミング言語のYAMLライブラリは、このタグが当該プログラミング言語ではどのように表現されるかをあらかじめ定義したり、あるいは呼び出し側でマーシャルの方法を拡張できるようにするなどした上で、適切なタグを選んでマーシャリングを行います。
なお、後述する通り、これらは !!str や !!seq のように略記されることが多いです。
例
たとえば、以下のようなRubyのオブジェクトを考えます。
class Company
attr_accessor :name, :employees
def initialize(name)
@name = name
@employees = []
end
def employ(user)
@employees << user
user.employers << self
end
end
class User
attr_accessor :name, :employers
def initialize(name)
@name = name
@employers = []
end
end
c1 = Company.new("Good Object, Inc.")
c2 = Company.new("Neko K.K.")
u1 = User.new("Taro")
u2 = User.new("Hanako")
c1.employ(u1)
c2.employ(u1)
c2.employ(u2)
root = { companies: [c1, c2], users: [u1, u2] }図にするとこんな感じです。
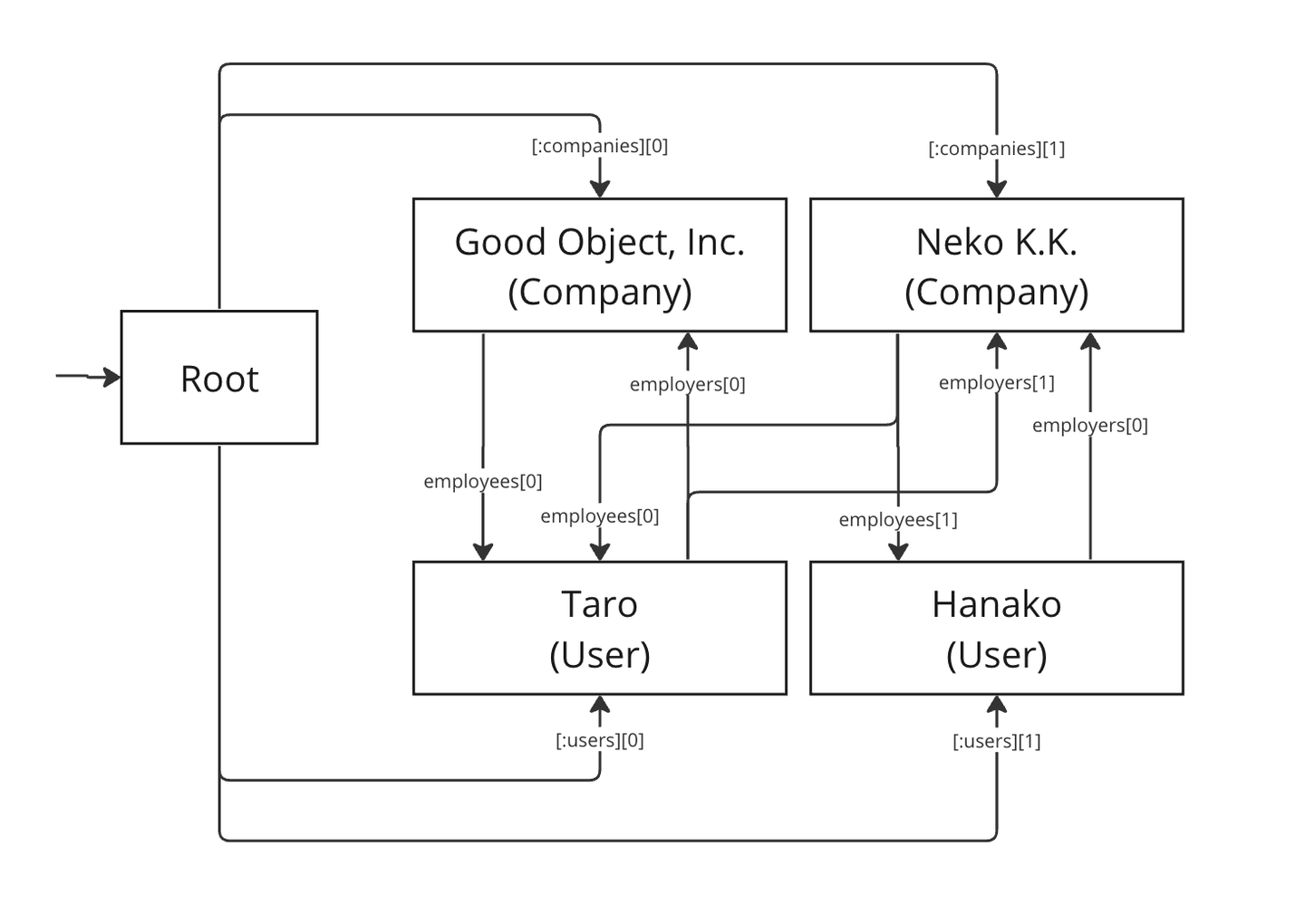
これは次のようなノードグラフに翻訳されます:
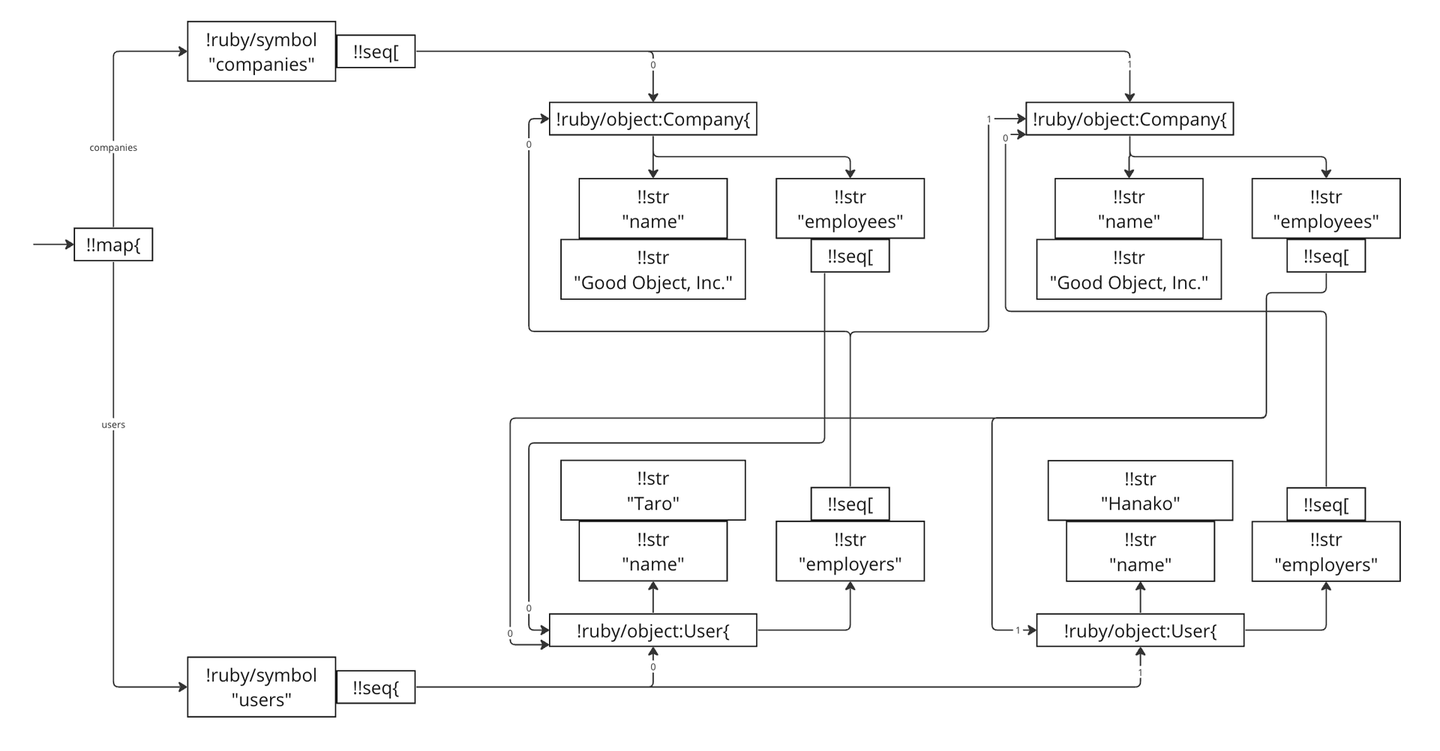
ローカルタグと不特定タグ
相互運用性が重要ではない場合は、URLのかわりに ! で始まる文字列をタグとして使うことができます。これはローカルタグと呼ばれます。
たとえばRubyのプレーンなオブジェクトには !ruby/object:<class_name> というタグがつけられます。
また、ノードグラフの段階では出てきませんが、後続するステップでは不特定タグ (non-specific tag) という特別なタグが出てきます。これは、その内容からタグを推論せよという意味のタグで、 ! と ? の2種類のみからなります。
イベントツリーへの変換
プログラミング言語のもつデータ構造は必ずしも木構造とは限りません。具体的には
- ノードの共有
- 循環参照
が発生することがあります。こういった情報を適切に書き出すには、同じノードが参照されているという状態を木構造にうまく落としこむ必要があります。そのためにYAMLでは、ノードの初回出現時にノードに名前をつけて、以降ではノードを名前で呼び出すことによってノードの同一性を表現します。
この変換が適用された状態のデータ構造をイベントツリーと呼びます。イベントツリーでは、イベントの種類が4種類に増えます:
- スカラーノードの作成
- 列ノードの作成
- 写像ノードの作成
- エイリアス (アンカーの参照)
また、ノードの作成イベントではノードにアンカーという名前を付与できるようになります。アンカーは &, エイリアスは * という記号で表現されます。
先ほどの例の場合、ノードグラフは以下のようなイベントツリーに変換されます。
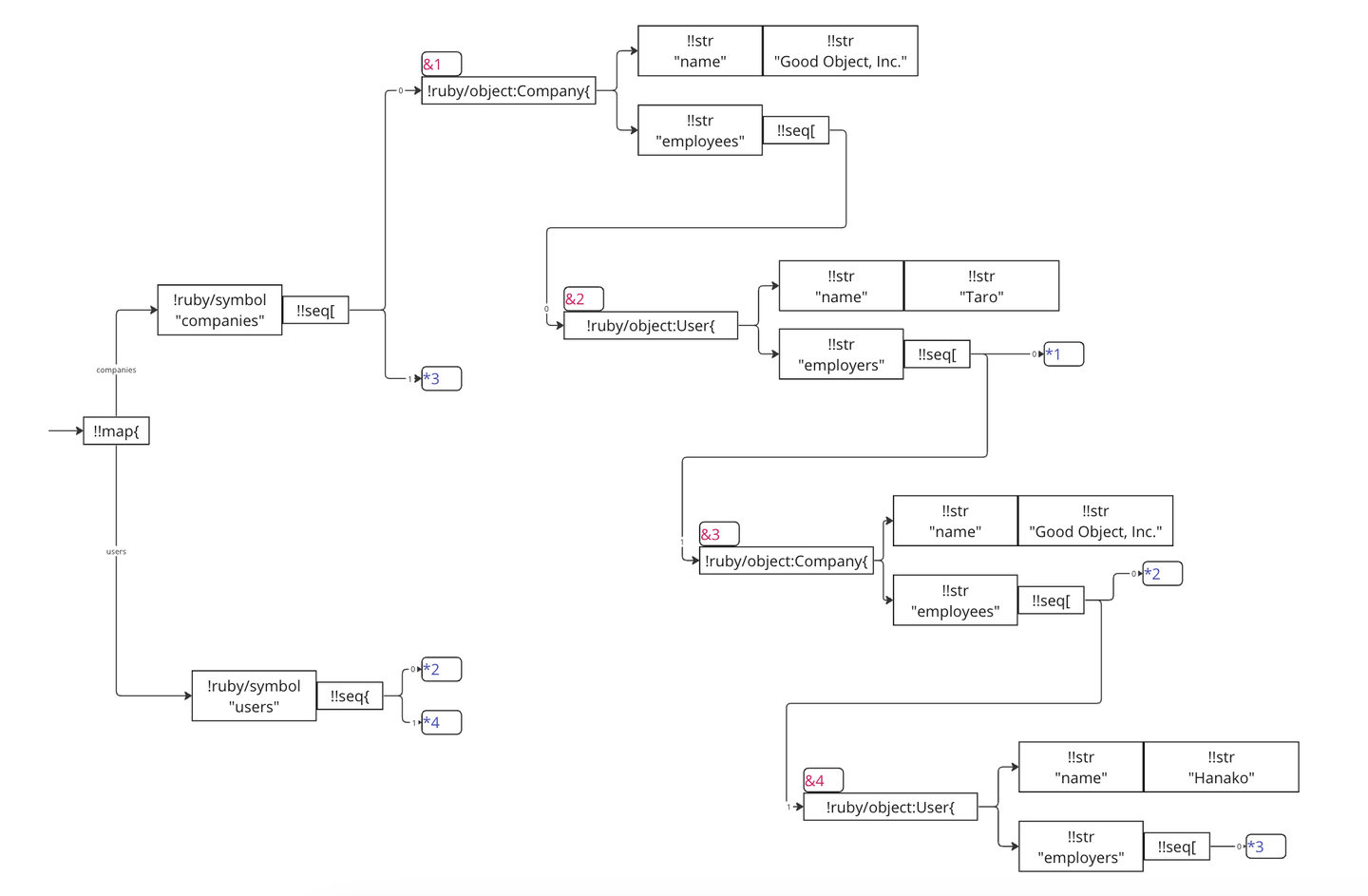
文字列表現の構築 (1) スキーマの適用
多くの場合、タグは省略可能です。よく使うタグは不特定タグである ! または ? から推論可能だからです。この推論ルールを定めるのがスキーマです。
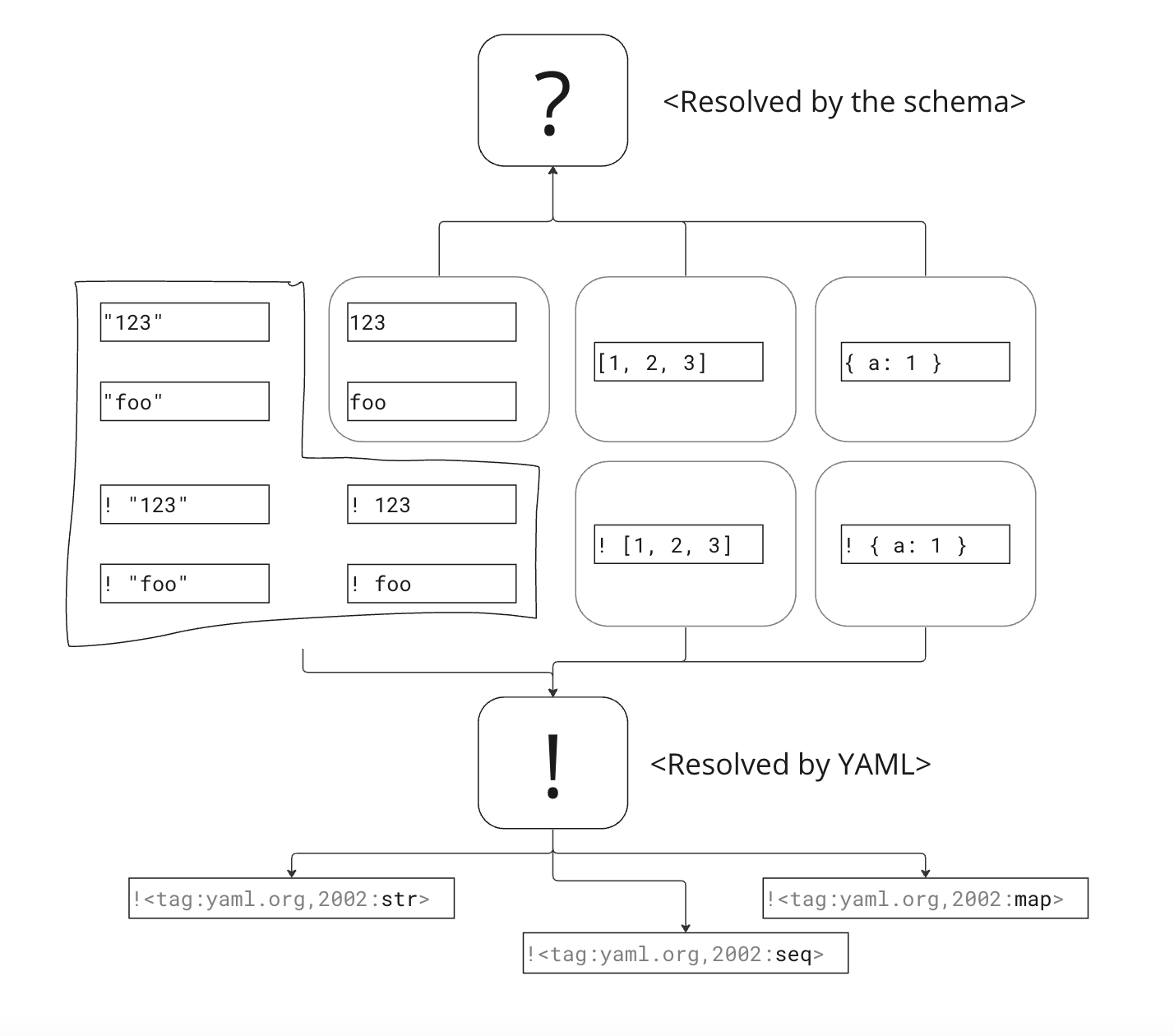
まず、 "!" の推論ルールは仕様で定められています。
- スカラーノードの "!" は tag:yaml.org,2002:str に解決される。
- 列ノードの "!" は tag:yaml.org,2002:seq に解決される。
- 写像ノードの "!" は tag:yaml.org,2002:map に解決される。
一方、 "?" のついたノードの解決方法はYAML仕様では固定されておらず、スキーマを指定することで決まるようになっています。ただし、実装上はYAML仕様で例示されている "Core Schema" を拡張したものが使われていると思って問題ないでしょう。
その "Core Schema" のルールは以下のようになっています。
- 列ノード・写像ノードの解決ルールは "!" と同じ。
- スカラーノードの "?" はその文字列内容に基づいて決定される。
- null およびそのタイトルケース (Null), 大文字 (NULL) は tag:yaml.org,2002:null に解決される。
- ~ も tag:yaml.org,2002:null に解決される。
- 空文字列も tag:yaml.org,2002:null に解決される。これはいくつかの場面でノードを省略した場合に使われる。
- true, false およびそのタイトルケース (True, False), 大文字 (TRUE, FALSE) は tag:yaml.org,2002:bool に解決される。
- 整数 tag:yaml.org,2002:int の判別ルール (詳細略)
- 浮動小数点数 tag:yaml.org,2002:float の判別ルール (詳細略)
- ".inf", "+.inf", "-.inf", ".nan" およびそのタイトルケースや大文字は tag:yaml.org,2002:float に解決される。
- 上記に該当しなければ tag:yaml.org,2002:str に解決される。
という風になっています。ここから逆算すると、 tag:yaml.org,2002:bool というタグを持つ "true" という内容を持つノードを文字列化するにあたっては tag:yaml.org,2002:bool を書かずに ? という不特定タグを置いておけばよいことがわかります。 (なお、後述のように、 "?" は文字列化するときには省略されます)
文字列表現の構築 (2) ノードの文字列化
タグの表現を決定したら、あとは文字列化するだけです。ここでもYAMLは利便性のために様々な表現を用意しています。
タグの文字列表現
タグは !<...> という括弧に入れて表記されます。しかしこの表記は冗長であるため実際にはほとんど使われません。かわりに以下の省略記法が使われます。
- !<!> → !
- !<!ruby/object> → !ruby/object
- %TAG directive で対応関係を置き換え可能
- !<tag:yaml.org,2002:str> → !!str
- %TAG directive で対応関係を置き換え可能
- !<https://example.com/suffix> → !e!suffix
- %TAG directive で対応関係を登録済みのときに利用可能
加えて、以下のルールでタグを省略できます。
- 非プレーンスカラー (引用符で囲まれているフロー形式のスカラー or ブロック形式のスカラー) の !<!> は省略可能。
- プレーンスカラー (引用符で囲まれていないフロー形式のスカラー)・列ノード・写像ノードの !<?> は省略可能。
これにより、よく知られているユースケースではタグを明記する必要がなくなります。
スカラーの文字列表現
フロー形式とブロック形式があります。フロー形式では引用符ありの形式となしの形式があり、引用符のない形式はプレーンスカラーと呼ばれ特別な効果を持ちます。多くのスキーマではプレーンスカラーの内容に応じて異なるタグに解決するように設定されているため、プレーンスカラーは数値や真理値など非文字列の記述によく用いられます。
ブロック形式にも様々な亜種がありますが、ここでは省略します。
列の文字列表現
フロー形式では [ ... ] で囲み、カンマ区切りで要素を記述します。
ブロック形式ではバレット - を各行に並べて要素を記述します。
写像の文字列表現
フロー形式では { ... } で囲み、カンマ区切りで要素を記述します。ブロック形式では要素を各行に並べて記述します。
各要素の完全な記法では ? と : という2つの記号が使われます (この ? は不特定タグをあらわす ? とは関係ありません)。
{ ? a : 1, ? b : 2, ? c : 3 }不完全な形式でも ? と : のいずれか片方は必須です。ほとんどのユースケースでは ? が省略されます。この場合、key-valueのkey側の表現能力は制限されます。 (フロー形式のスカラーしか記述できません)
複雑なkeyを書く場合は ? を記述することになります。
逆に、 : を省略した場合は空のプレーンスカラーが指定されたものとして扱われます。空のプレーンスカラーは通常、nullに解決されます。
インデントについて
各ノードのブロック形式では、インデントによって構造が表現されます。ブロック形式の子ノードは親ノードよりも深いインデントにする必要があります。
このルールには例外が1つあります。それは列ノードが写像ノードの子ノードとして出現する場合です。この場合のみ、子ノードは親ノードと同じでもよいことになっています。
foo:
- 1
- 2
- 3YAMLに関するスタイル規約・フォーマッターには、この例外をなるべく利用するようなものとこの例外を避けるようなものの両方があり、不統一のもとになっています。
例
ここまでで扱ってきた例は、最終的に以下のようなYAMLとして出力されます。
:companies:
- &1 !ruby/object:Company
name: Good Object, Inc.
employees:
- &2 !ruby/object:User
name: Taro
employers:
- *1
- &3 !ruby/object:Company
name: Neko K.K.
employees:
- *2
- &4 !ruby/object:User
name: Hanako
employers:
- *3
- *3
:users:
- *2
- *4ディレクティブとストリーム
YAMLのドキュメント全体を制御可能にするために、ディレクティブが記述できるようになっています。
%YAML 1.2
%TAG !e! https://example.com/
---ディレクティブでできることは以下の2つです:
- YAMLのバージョン指定
- タグの省略記法の設定
また、RubyのMarshal.loadと同様、YAMLも1つのバイトストリームから複数のYAML文書を取り出すことができるようになっています。この場合、2つの文書を区切るためには少なくとも以下のいずれかが必要です。
- 文書の開始をあらわす行 "---"
- 文書の終了をあらわす行 "..."
これらの行を見かけることは少ないですが、YAML frontmatterなどの形で出ているのを見たことはあるかもしれません。
その他の拡張
その他のスカラー値
Language-independent types for YAML という古いdraft specには、様々なデータ型が定義されています。その中には以下のようにCore Schemaに含まれていない有用な型も存在します。
- !!binary SGVsbG8sIHdvcmxkIQ== # 任意のバイト列
- !!timestamp 2023-09-14T00:00:00Z # 日付時刻仕様中の例示を見る限り、timestampはタグの解決ルールに含める(タグを省略可能にする)利用方法が想定されているようです。
マージ
マージもまたそうした規格のひとつです。 tag:yaml.org,2002:merge 型の値はマップのキーに出現するときに特別な意味を持ち、その値に指定されたノードを本体にマージすることを意味します。
? !!merge "<<"
: { a: 1, b: 2 }
c: 3
# => { a: 1, b: 2, c: 3 } と同じ意味このタグもまた、省略して解決されることが意図されています。その前提のもとでは以下のように書くことができます。
<<: { a: 1, b: 2 }
c: 3この仕組みが真価を発揮するのは、アンカー・エイリアスと組み合わせた場合です。この形での出現を見たことがある人は多いのではないでしょうか。
default: &default
foo: 1
bar: 2
advanced:
<<: *default
baz: 3既知のスカラー値の拡張ルール
YAML 1.1からリンクされているブール値の古いdraft specでは、本体規格より広い範囲の構文が指定されています。
- yes/no およびその亜種 (Yes/No, YES/NO)
- y/n およびその亜種 (Y/N)
- on/off およびその亜種 (On/Off, ON/OFF)
整数値の古いdraft specでも、コロンで区切られた60進数などのエキゾチックな派生が指定されています。
YAML実装によってはこれらの解決ルールが実装されていることがあり、しばしば混乱のもとになります。
Rubyシンボル
RubyのYAMLサポートには固有のタグ解決ルールがあり、 ":" で始まるプレーン文字列はシンボルとして解釈されます。
- :foo
- !ruby/symbol foo # 上と同じ":" で始まるプレーン文字列のタグは !ruby/symbol に解決される、と説明できれば簡単なのですが、実態はそうではありません。もしそうであれば :foo は !ruby/symbol :foo と等価なはずですが、実際には !ruby/symbol foo と等価だからです。
JSONとの関係
仕様中で説明されている歴史によると、YAMLとJSONの類似は「まったくの偶然」であると説明されています。
その後、JSONの存在に気付いたYAML開発者らによって仕様がわずかに改訂され、YAML 1.2ではJSONを完全に部分集合として含むようになりました。この改訂で対応されたのは一部の特殊な文字やエスケープシーケンス、マイナーな文字エンコーディングなどに関する些細な非互換性であり、YAML 1.1の時点でも大部分のJSONはそのまま解釈可能でした。
YAMLがJSONのスーパーセットになっているのは偶然の産物ではありますが、この偶然はJSONの強い厳密性を前提に成立しています。特に重要なのは、JSONにおいて全ての文字列がダブルクオートで囲まれている必要があるという制約です。この制約を取り払ったJSONの拡張はたいていYAMLとは非互換な結果になります。たとえばJSON5とYAMLでは以下の文書の解釈が異なります。
{NULL: 1}また、JSONの拡張の多くはコメントを // 形式で表現しますが、これもYAMLとは互換性がありません。
YAMLが失敗だったとしたら
過程や背景がなんであれ、YAMLが現在も広く使われている事実がある以上、YAMLというプロダクトそのものは間違いなく「成功」だったとみなしてよいでしょう。その一方で、YAMLの意図した設計の全てが成功したとは言いがたい面があります。
この点について筆者の見解を残しておきます。
マーシャリングの需要はそこまで高くない
「プログラミング言語のデータ構造をそのまま出力する」という意味でのマーシャリングの利点は、直列化のための準備が必要ないという点が大きいのではないかと思います。この前提のもとでは、言語非依存のマーシャリングフォーマットの需要はあまり高くはなく、RubyのMarshalのように同言語内での情報交換ができれば十分だったのではないかという気がします。
XMLを代替するには至らなかった
YAMLのタグは拡張可能性が考慮されており、ユーザー定義のデータ型を作るための仕組みとしては申し分ないものだと思います。また筆者としては、YAMLがマークアップ言語ではないという一点をもって、構造化データの記述言語としてXMLよりYAMLのほうが優れていると言ってしまいたいところです。
とはいえ、技術的に優位であれば普及するというような簡単な話ではありませんから、そういった普及戦略まで考えるとYAMLにはXMLに対する勝ち目はあまりなかっただろうと思います。そして、YAMLの持つタグという仕組みがあまり広く使われていないのは、XMLを代替できなかったことの帰結だと言えるのではないでしょうか。
不十分な互換性保証
スカラー値が文字列であるか数値であるかは、ユーザーにとってとても重要な違いです。YAMLはその重要性を低く見積もっていたのではないかと思います。
その重要性にもかかわらず、YAMLではプレーンスカラーの解釈をスキーマに委ねることで、多様な実装を許してしまっています。これは、YAMLを「設定ファイル」以上の重要な情報交換に使うのをためらわせるには十分だったのではないかと思います。
具象構文の複雑性
YAMLに強力な構文があること自体は、YAMLの設計思想によりある程度は正当化されるでしょう。しかし、やはり具象構文のレベルでは、データモデルの設計とは無関係に複雑すぎるように感じられます。
まとめ
- YAMLはJSONとは異なる出自を持つもので、その本来想定された利用目的もJSONとは異なる。むしろ、XMLやRubyのMarshalなどと近いものだと考えたほうがよい。
- 実際にはFancy JSON以上の使い方が必要になることは稀だが、こういった背景を押さえておくことで、YAMLが持つ強力な構文も理解しやすくなるはず。
- 本稿ではこれらの前提を踏まえて、YAMLがデータ構造をどのように整理しているのかを紹介した。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


