hi18nとは hi18n は現在Wantedlyで開発中の、 TypeScript/JavaScript向け翻訳テキスト管理ライブラリ ( i18nライブラリの一種 ) です。
本記事は以下のシリーズの続きです。
本記事ではCLIツール側の中核機能である 翻訳の同期 がどのように実現されているのか説明します。
翻訳の同期で実現すること アプリケーションが変更されれば、必要な翻訳も増減します。翻訳ファイルをアプリケーション側の要求に追従させるにあたって、全てを手動で行うのではなく、ある程度の作業を機械的に行うことができると便利です。hi18nではこれを翻訳の同期と呼んでいます。
翻訳ファイルのライフサイクル 翻訳対象がアプリケーションから抽出され、翻訳がアプリケーションに呼ばれるまでの流れは、i18nライブラリごとに少しずつ異なります。
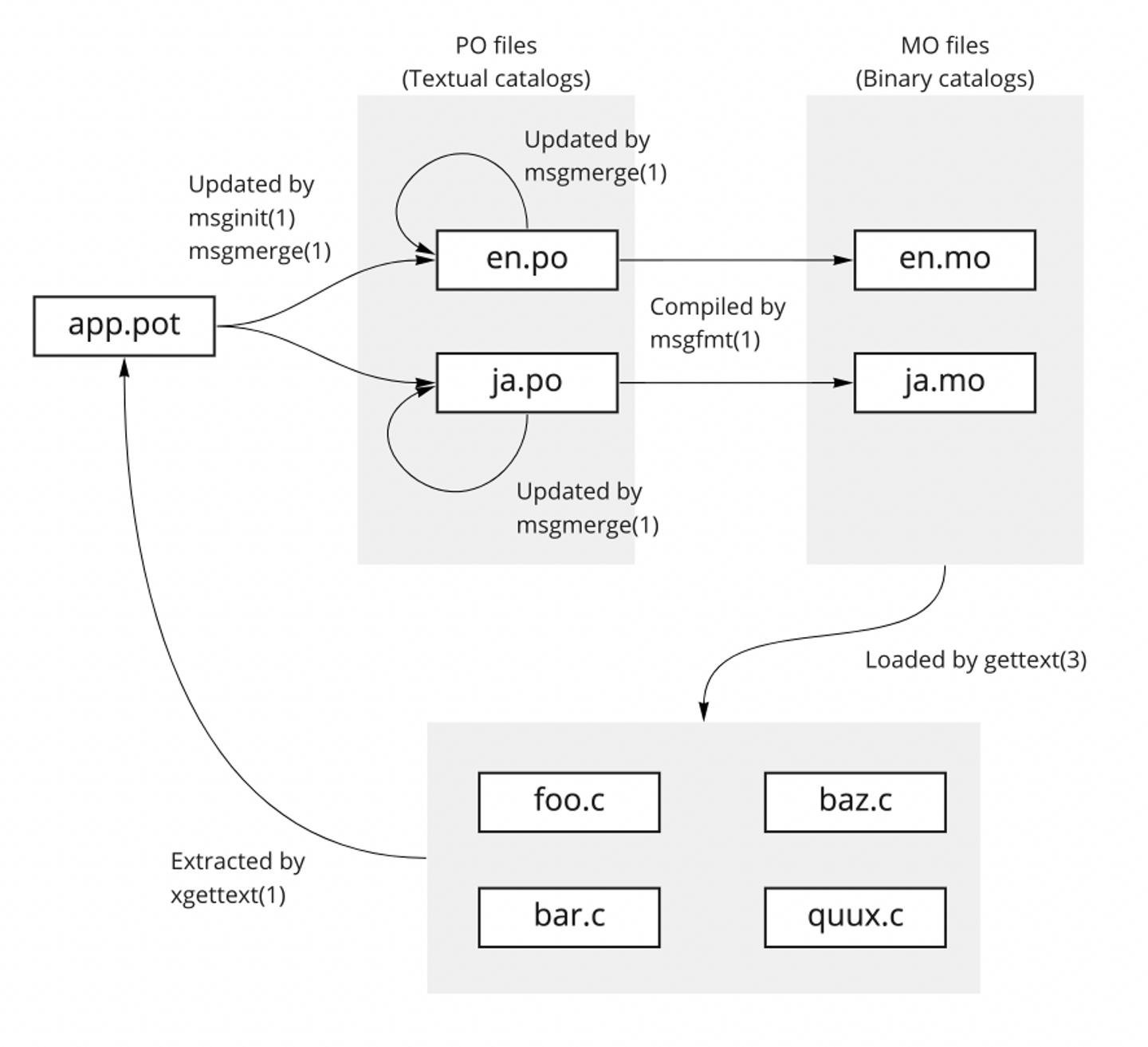
GNU gettext たとえば、 GNU gettext の翻訳ファイルはおおよそ以下のようなライフサイクルを持ちます。
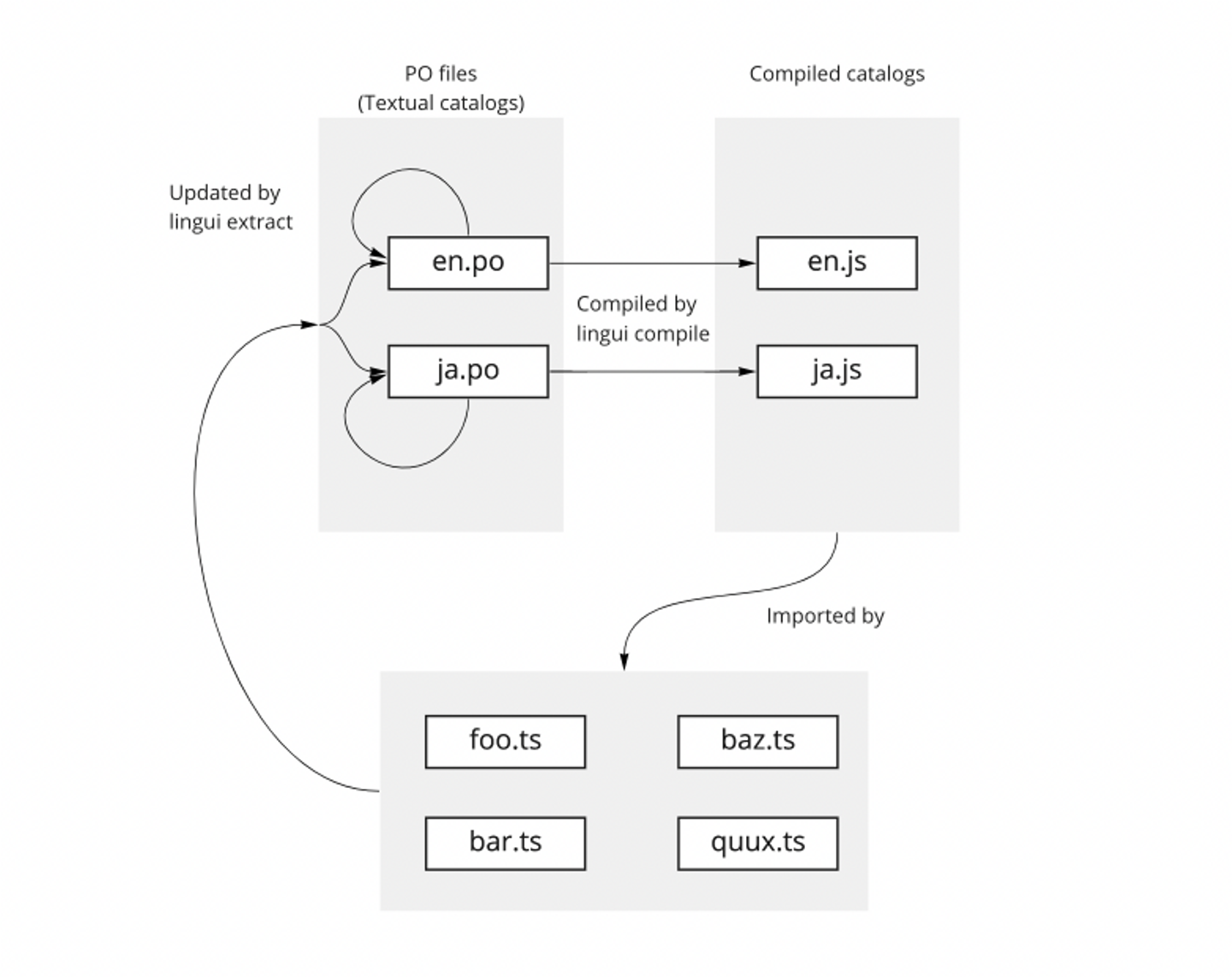
xgettext(1): アプリケーションコードから翻訳テキストの呼び出しを検索し、翻訳テンプレートを生成します。 msginit(1) / msgupdate(1): 翻訳テンプレートをもとに各言語の翻訳ファイルを更新します。 msgfmt(1): 翻訳ファイルをバイナリにコンパイルします。 gettext(3): バイナリの翻訳ファイルをアプリケーション内に読み込みます。 LinguiJS LinguiJS はgettextと似ていますが、potファイルを持たずに直接poに対して同期を行います。また、翻訳データはjsファイルにコンパイルされアプリケーションに直接リンクされます。 (一般的な方法でバンドラーを構成している場合)
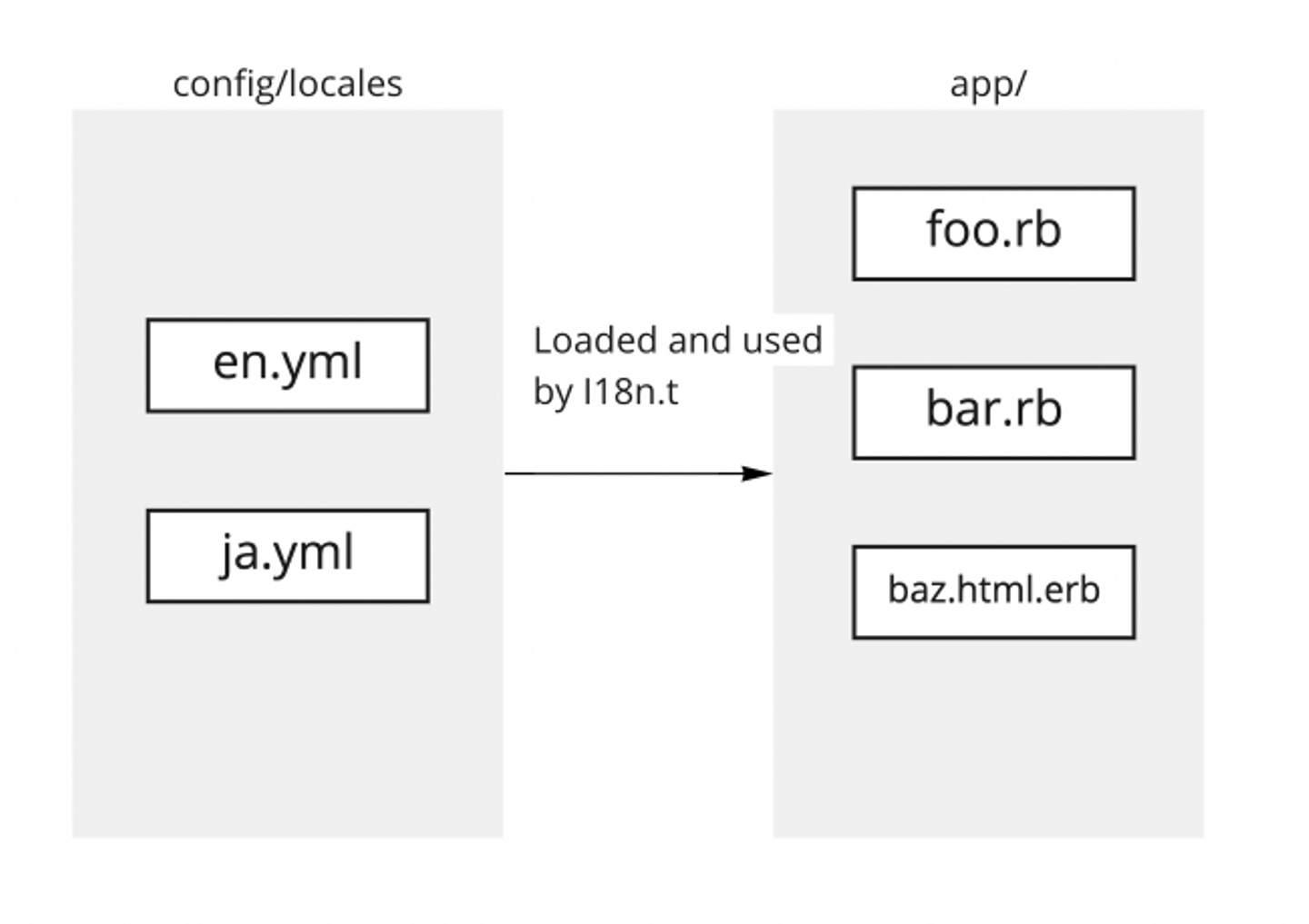
Rails Rails はデフォルトでは特別なツールを持たず、ライフサイクルは非常にシンプルです:
ただし、これは翻訳ファイルの管理がほぼ自動化されていないことを意味します。
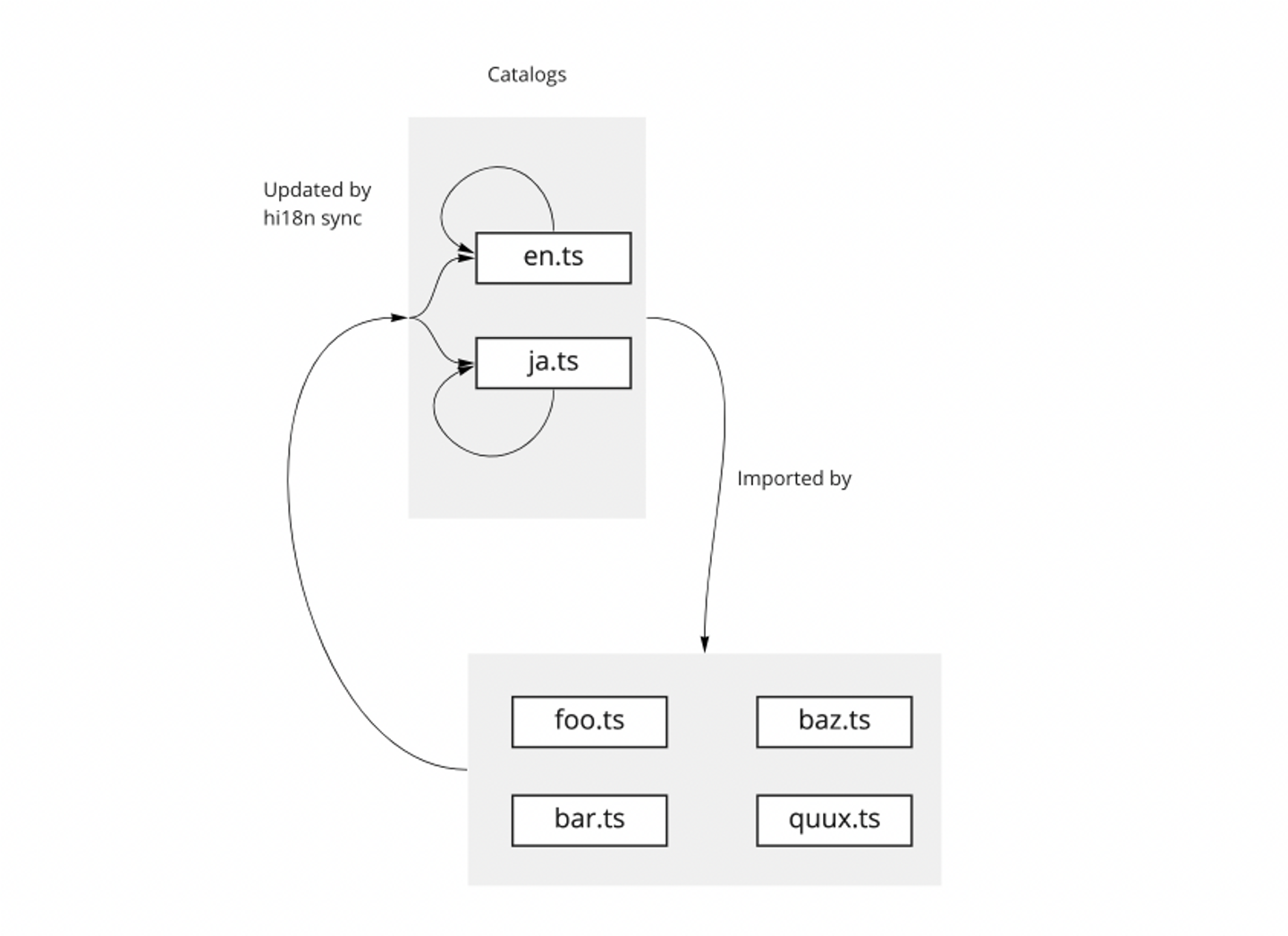
hi18n hi18nではJavaScriptの内部DSLを使って翻訳を定義するため、ライフサイクルはシンプルです:
翻訳同期処理の全体像 hi18nでは1つのプロジェクト内に複数のbook (翻訳カタログを集めた基本単位) を持てるようにしていました。そのため、単に翻訳利用箇所を発見するだけではなく、 翻訳データをどのbookから取得しているか も算出する必要があります。
これを踏まえて、翻訳同期処理は以下の3ステップ構成になっています。
プロジェクト内のソースコードをスキャンし、翻訳利用箇所を発見する。また、bookの定義箇所もこの時点で発見する。 それぞれの翻訳利用箇所で、翻訳データをどのbookから取得しているかを算出する。 必要な翻訳のリストにもとづき、カタログファイルを更新する。 JavaScriptコードを操作する 現代のフロントエンドエコシステムではJavaScriptコードを操作するための基盤が充実しています。
今回翻訳同期を実装するにあたって、以下の4種類のツールを検討しました。
Babel (トランスパイラ) パーサーは @babel/parser ジェネレーターは @babel/generator ESLint (リンター) パーサーは選択式 (espree, @babel/eslint-parser, @typescript-eslint/parser) jscodeshift (codemodライブラリ) パーサーはesprima ジェネレーターはrecast ts-morph 結論としてはESLintを使うことになりました。理由は以下の通りです。
まず、Babelは通常ビルド過程の一部で使われることを想定しているため、人間可読なJavaScriptを出力することにはあまり関心が強くありません。筆者の理解では @babel/generator はround-trip性を持たないはずです。少なくとも、Babelを単体として使うのは今回の目的では不向きです。
別の選択肢として、 @babel/generator の出力をさらにprettierなどのフォーマッターに入力するという手もあります。こうすれば少なくとも人間に扱いづらいソースコードが出力されることは避けられるでしょう。しかし、もし利用者側で異なる設定のフォーマッターが構成済みだった場合は厄介です。翻訳同期処理とプロジェクト固有のフォーマッターが干渉する可能性があります。利用者に余計な負担をかけないためにも、できるなら他の方法をとりたいところです。
この観点からはcodemod系のライブラリ (jscodeshift) が優れていると言えますが、jscodeshiftは以前使ってみたところライブラリ自体のTypeScript対応が微妙だったりと全体的に整備が万全ではない印象があったため今回は避けることにしました。
一方のESLintには以下の利点があります。
ESLintはcodemodライブラリではないが、autofixという機能があり、これで実質的にcodemodとしての役割を担うことができる。 もともとライブラリの正しい使い方を強制するためにESLintのルールを実装する予定だったため、同じ仕組みをCLIツールでも再利用できたほうが開発・メンテナンスしやすくなることが見込まれる。 逆に欠点としては、ESLintのautofixはテキストベースであってASTベースではないという点が挙げられます。ESLintではスタイル面での修正も行いたいため、テキストベースの修正が存在していること自体は自然ですが、今回の目的にはそこまで便利ではない面もあります。これについては気合で何とかします。
ts-morphは便利そうですが、今回はESLintとの統合による利点を引き出すことを優先したのと、TypeScriptに強く依存するのは避けようという判断から使わないことにしました。ESLintも @typescript-eslint/parser を使うことでTypeScriptとの統合を実現できるようになっているので、必要に応じて部分的にTypeScriptの力を借りる余地は残されています。
@typescript-eslint/utils を使う やや脇道にそれますが、ESLintの説明をするにあたって是非伝えておきたい内容なので無理矢理ここに書いておきます。
TypeScriptを使ってESLintを扱う (プラグインを書いたりESLintを呼び出すコードを書いたりする) 場合、 eslint パッケージを直接使うのはおすすめしません。型に微妙なところが多いからです。
TypeScript向けのESLintプラグインを提供している @typescript-eslint が、eslintや周辺ライブラリの型をつけ直した @typescript-eslint/utils というパッケージも提供しています。型がまともなおかげで生産性が段違いなので、TypeScript使いであれば間違いなくこちらを使ったほうがよいです。
(個人的にはestreeのtypeにstring enumを使っているところだけ相容れませんが……)
ライブラリ利用箇所を発見する パーサーを手に入れたので、まずはライブラリの利用箇所を発見します。
型に依存しない静的解析でできることは限られますが、それでもできるだけ寛容に発見できるように実装することにします。
たとえば、hi18nではbookのインスタンスを複数持つことが可能で、1ファイル内で複数のbookのインスタンスを参照することも考えられます。
import { book as book1 } from "../../common/translations";
import { book as book2 } from "../translations";
const { t: t1 } = useI18n(book1);
const { t: t2 } = useI18n(book2);
t1("example/greeting");
t2("example2/submit"); このような場合にはリネームは不可欠です。このように実用的にもある程度寛容に検出できたほうが望ましいです。
また、以下のようなバリエーションもあります。
// namespace importを使っている
import * as hi18n from "@hi18n/react";
// destructuring assignmentを使わずに毎回メンバーアクセスを行う
const i18n = hi18n.useI18n(book);
i18n.t("example/greeting"); こういった違いを吸収するためにユーティリティーを用意することにしました。importを起点にして関心のあるノードを再帰的に辿り、その結果を報告するという処理を共通化しています。
作った後で存在に気付いたのですが、このコンセプトはeslint-utilsの ReferenceTracker として実装されているユーティリティーに近いです。ただし、上記の自作trackerはいくつかの追加機能を備えています。
関数呼び出し、コンストラクタ呼び出し、JSX呼び出しの結果を再帰的に追跡する。 その際、特定の引数をキャプチャして記憶しながら追跡する。 これにより、ライブラリの利用状況の静的解析をほぼ宣言的に行えるようになっています。
これを使って、以下の3つの利用箇所を探します。
翻訳を呼び出している箇所 `useI18n(book)` → `t(...)` `getTranslator(book, locales)` → `t(...)` `<Translate book={book} id=... />` `translationId(book, ...)` カタログ定義 `new Catalog<Vocabulary>({ ... })` bookの定義 `new Book<Vocabulary>({ ... })` 翻訳利用箇所と翻訳定義箇所の関連づけ ライブラリ利用箇所を収集したら、それらのリンクを行います。以下の2種類のリンクを認識する必要があります。
これらは通常別々のファイルに存在しているため、ファイルをまたいだ解決が必要です。話を単純にするため、以下のどちらかの構成になっていることを要求することにします。
exportしたものを直接importして使っている 定義箇所と利用箇所が同じファイル内にあり、定義したものをファイルスコープ変数に入れて同じファイル内で使っている 同ファイル内での参照を許しているのは、小さく始めるのを簡単にするためです。たとえばhi18nでのREADMEではbookとカタログを同じファイルに同居させた以下の例を掲示しています:
import { Book, Catalog, Message, msg } from "@hi18n/core";
type Vocabulary = {
"example/greeting": Message<{ name: string }>;
};
const catalogEn = new Catalog<Vocabulary>({
"example/greeting": msg("Hello, {name}!"),
});
export const book = new Book<Vocabulary>({ en: catalogEn }); いきなりファイルをたくさん作らせるよりも、1ファイルでできる例を示したほうが入りやすいだろうという考えからこのような機能を実装しています。
ファイルパスの解決 もしexportを経由してbookやカタログを参照している場合は、ファイルパスを解決する必要があります。
残念ながら、importのパスの解釈方法は場合によってまちまちです。Node.js周辺に限っても細かいカスタマイズが行われているものが多く、「これだけ対応しておけばOK」という決定版はありません。今回は以下のようにしました。
まず、パスの解決の基本ルーチンとして resolve packageを使います。これはNode.js本体が提供する require.resolve を一般化したもので、以下のような処理を行ってくれます。
symlinkの解決 index.jsの解決 package.jsonのmain fieldの解決 node_modulesの解決 yarn PnP利用時のPnPに沿った解決 拡張子の補完 しかし、resolveのデフォルトの使い方だけではプロジェクト構成次第では対応できない場合があります。
拡張子の補完 まず1つ目が拡張子の補完に関する問題です。resolveはデフォルトでは .js, .json, .node を省略しても補完してくれますが、これだけでは不十分です。たとえばTypeScriptのプロジェクトでは ./foo をインポートしたときに foo.ts に解決されるように構成していることがほとんどです。
hi18nでは解決ルールが寛容すぎる分には困らないので、よく使われる拡張子をデフォルトで補完するようにオプションを足しています。さらに念のため、設定ファイルで拡張子の設定をカスタマイズできるようにしています。
Native ESM拡張子対応 Node.jsのNative ESMモードでは拡張子の補完が行われないため、Native ESMを前提にしたプロジェクトでは異なる設定が使われていることがあります。
この場合も問題になるのはTypeScriptなどのケースです。Native ESM対応のTypeScriptのプロジェクトでは通常、トランスパイル後の名前として正しく解釈できるように拡張子を記載します。つまり、 ./foo.js をインポートしたときに foo.ts に解決されるように構成します。
resolve自身はこのような状況には対応していないため、hi18nではインポートパスをresolveに渡す前に拡張子を削除しています。削除する拡張子もカスタマイズできるようにしています。
path mapping対応 もう1つよく使われるのが、特定のインポートパスに別の意味を割り当てるという設定です。Node.js自身のパスの解釈はおよそ以下のように決まっています。
絶対パス (/ から始まる) 相対パス (最初のセグメントが . または .. である) 組込みモジュール (特定の名前を持つ または node: で始まる) パッケージ内インポート (# から始まる) node_modules相対インポート (上記のいずれにも当てはまらない) Node.jsの周辺ツールも同様のルールを実装しています。しかしTypeScriptやWebpackなどいくつかののツールにはそれに加えて、これらのルールを上書きする設定項目があります。特に、同じパッケージ内のモジュールを参照するために相対パスを使うと .. の連続が鬱陶しいことから baseUrl などの設定項目が重宝されています。
こうしたカスタマイズをしているプロジェクトへの対応として、hi18nでもTypeScriptのbaseUrl/pathsに相当する設定を書けるようにしています (自動では動作しません) 。
エクスポート名の照合 hi18nの推奨構成では1ファイル内で複数のbookやカタログがエクスポートされることはありませんが、一貫性のためにそういったケースも対応しておくことにします。処理を簡単にするためのちょっとした工夫として、「ファイル名 + エクスポート名」の組み合わせを以下のようなURLにシリアライズしています。
ファイル内参照の場合: /path/to/foo.ts?local=book ファイル間参照の場合: /path/to/foo.ts?exported=book なお、このような工夫をするのはJavaScript特有の事情によるものです。JavaScriptではMapやSetなどの基本的なコレクションでユーザー定義の等価演算子が使えないため、今回のようなケースでは組み込みの === で意図通りに比較できるような値を使うのが望ましいのですが、複数の値をまとめるためにオブジェクトを使おうとすると同一性で判定されてしまうためにうまくいきません。今回のユースケースにぴったりな提案であるRecords and Tuplesが使えるようになるのは当分先の話なので、今回は文字列へのシリアライズという方法を使っています。
翻訳ファイルの更新 ここまでの処理を行うことで、各翻訳ファイルごとに「実際に使われている翻訳IDの一覧」が収集できます。あとは、これらの情報にもとづいて翻訳ファイルを更新していきます。主に以下の3つのケースを考えます。
翻訳が定義されているが、使われていなかった場合 翻訳が使われているが、実際には定義されていない場合 過去に使われていたデータが残っている場合 新規作成する必要がある場合 未使用翻訳の削除 翻訳が使われていない場合は、その翻訳データを削除します。
特にJavaScriptではbundle sizeが増大することの悪影響が大きいため、使っていないデータを検出して削除することは重要です。
とはいえ、せっかく翻訳したリソースを無言で削除するのは (もしかしたらVCSにコミットする前かもしれないことを考えると) リスキーです。手違いで利用側のコードがうまく検出されていなかったとか、一時的にコメントアウトしていただけという可能性もありますし、できれば復元可能な形にしておきたいです。
hi18nでは翻訳データはJavaScriptの内部DSLで書かれているため、 使われていない翻訳はコメントアウト という形で除外することにします。コメントアウトされた行を本当に削除するかどうか (そしてその作業) はユーザーに任せます。
たとえば、
{
"example/greeting": msg("Hello, {name}!"),
"example/link": msg("You have <link>unread messages</link>."),
} というコードで、 example/link が未使用であれば
{
"example/greeting": msg("Hello, {name}!"),
// "example/link": msg("You have <link>unread messages</link>."),
} と書き換えられます。
この処理はプロパティの手前に "// " を挿入するだけなので比較的簡単ですが、1つのプロパティが複数行にまたがる場合は注意が必要です。
{
"example/greeting": msg("Hello, {name}!"),
// "example/link": msg(
// "You have <link>unread messages</link>."
// ),
} また行コメントを使っていることで発生する別のエッジケースとして、プロパティの終わりが行末になっていないケースにも注意が必要です。
// "example/link" のコメントアウトが難しい例
{
"example/greeting": msg("Hello, {name}!"),
"example/link": msg("You have <link>unread messages</link>.")
,} (このケースは現時点では対応していません)
削除した翻訳の復元 逆に、呼び出されているはずの翻訳IDが実際には存在しない場合は、翻訳データを足すことで差分を吸収します。これには2つのケースがあります。
コメントアウトからの復元は、簡単に言えば先ほど説明した処理の逆です。
{
"example/greeting": msg("Hello, {name}!"),
// "example/link": msg("You have <link>unread messages</link>."),
} ↓
{
"example/greeting": msg("Hello, {name}!"),
"example/link": msg("You have <link>unread messages</link>."),
} ところが、これは以下の理由から簡単ではありません。
コメントアウトされた部分はAST上は単なるコメントでしかない。 コメントアウトされたコードのほかに、通常の意味でのコメントが含まれる可能性があり、それらとの峻別が必要。 アンコメントの結果が文法的に正しくないコードになってしまうと、ESLintのautofix処理全体が止まってしまう。 また、コメントアウトされた翻訳の検出は別のルール (翻訳ID順にソートされていることをチェックするルール) でも使いたいので、全てのコメントアウトされた翻訳を検出できるような形で実装します。
これらの目的を達成するため、hi18nでは コメント部分を実際にJavaScript/TypeScriptのコードとしてパース する処理を行っています。ただし、以下の理由からJavaScript/TypeScriptのサブセットをパースできる パーサーを 自前で実装 しています。
ProgramやExpressionなどではなくPropertyをゴールシンボルとしてパースする必要があり、このようなAPIは一般的には提供されていない可能性が高い。 ストリームを完全に読み切るのではなく、ゴールシンボルの終端を報告するような形式で結果を返してほしい。 ただし、翻訳データ部分で使われる構文はそれほど多くないため、あくまでそれらを補完できる程度の内容として実装しています。
現時点ではこのパーサーは一般的なJavaScriptのパーサーと異なり、字句解析器と構文解析器が分離されています。一般的なパーサーでこれらが分離されていないのは理由があります。それは、 字句解析の挙動が文脈依存になっている箇所が2箇所存在する という点です。
1つ目は除算と正規表現リテラルの判定です。正規表現リテラルは式が開始できる位置でのみ採択されます。
const u = 1;
const x = 1 / 2 /u;
// ^ これは除算として扱われる
const y = / 2 /u;
// ^^^^^^ これは正規表現リテラルとして扱われる もう1つは波括弧とテンプレートリテラル断片の判定です。テンプレートリテラルの中間断片と末尾断片は、これらが構文的に存在できる位置、つまりテンプレートリテラルの補間部分の式が終了できる位置でのみ採択されます。
const u = 1;
const x = { u }; //`;
// ^ これは波括弧として扱われる
const y = `foo ${ u }; //`;
// ^^^^^^ これはテンプレートリテラル断片として扱われる また、 JSX はJSX構文全体にわたってJavaScriptとは異なる字句構造が使われているため、数多くの文脈依存性を持ちます。
このように本来JavaScriptの字句解析器は文脈に応じて異なる結果を返す必要がありますが、今回対応する必要がある構文に限ればこのような対応は必要ないため、暫定的に字句解析器と構文解析器を分離する実装を採用しています。また、単一のトークンが複数のコメントにまたがってコメントアウトされているようなケースは考えないことにします。この前提のもとでは、 各コメント内の字句解析は1度ずつ行えばいい ことになります。 (おそらく実用的にはパフォーマンスメリットはほぼないですが)
たとえば、以下のように4つの連続したコメントを考えます。
// This is a normal comment.
// "example/unused-greeting": msg(
// "Good night, {name}!"
// ), hi18nのパーサーはまず、各コメントごとに字句解析を試みます。
最初のコメント: 6個のトークン 2行目: 4個のトークン "example/unused-greeting" : msg ( 3行目: 1個のトークン 4行目: 2個のトークン この段階で字句解析に失敗した場合は、そのコメントは採用しません。
次に、字句解析できたコメントのうち連続している部分を取り出して、構文解析を試みます。失敗したら最初のコメントは通常のコメントとみなして次のコメントから再度構文解析を試みます。
たとえば上の例ではまず This is a ... というトークン列に対して構文解析を試みますが、これは This is まで進んだ段階で失敗します。そこでこのコメントは通常のコメントとみなします。
次のコメントから再度パースすると、4行目の終わりでちょうど Property (に加えて末尾カンマ) が読み切られます。さらにASTに対して追加のチェックを行い、これがコメントアウトした翻訳データとみなせることを確認します。2行目から4行目まではコメントアウトされた翻訳データとみなせるので、これを記録して、5行目からパースを再開します。
このようにすることで、コメントアウトされた翻訳データの一覧を生成することができます。その中に所望の翻訳IDがあれば、そのコメント開始部分を削除します。これによりコメントアウトされた翻訳データを適切にアンコメントできます。
翻訳データのためのスケルトン生成 もし参考にするべきデータがない場合は、かわりに未翻訳のデータが入ったダミーのコードを生成します。
{
"example/greeting": msg("Hello, {name}!"),
}
// ↓
{
"example/greeting": msg("Hello, {name}!"),
"example/link": msg.todo("[TODO: example/link]"),
} 基本的には末尾にテキストを挿入するだけです。ただし、hi18nでは翻訳データを翻訳ID順に並べることを想定して、できるだけ適切な挿入位置を決定するように工夫しています。
具体的には、翻訳データ (コメントアウトされたものも含む) を翻訳ID順にソートした配列を持っておき、二分探索で最近傍となる翻訳IDを決定します。その後AST (こちらはソート済みではないかもしれない) に戻り、最近傍となる翻訳IDの直後に所定のデータを挿入します。
もし元のデータがソート済みなら、この処理のあともソート済みの状態が維持されます。そうでない場合も、できるだけ関連性の高い位置に挿入されることが期待できます。
型情報の同期 ここまでに説明した同期処理は、翻訳カタログの型定義にも適用されます。
現在、翻訳カタログの型定義は、Bookの定義と同じファイル内にtype/interfaceとして定義されている必要があります。これは、bookとカタログを別ファイルにしたときにモジュールのimport関係が循環的になってしまうことを意味するため、将来的にはその制限を緩和したいところです。
型定義の修正処理は、対象がオブジェクトリテラルのかわりにリテラル型(オブジェクトリテラル型)である点を除けばほぼ同様です。
ESLintを呼び出す すでに説明したようにhi18nのCLIはESLintのエコシステムに乗っかることにしたので、できるだけESLintの高級APIを使うようにします。その第一歩は、 ファイルごとの処理を (実際にはlintではないが) ESLint ruleとして実装してしまう ということです。具体的には以下のルールがCLI向けの内部ルールとして定義されています。
このうちcollect系のルールはオプション (本来はJSONでルールをカスタマイズするためのもの) を濫用してコールバックを受け取るようになっています。これにより呼び出し側で収集結果を受け取ることができるようになっています。
収集フェーズが終わったあと、収集したデータはESLintの 共有設定 (settings) に入れられます。autofix系のルールはこれをもとに処理を行います。個別のルールのオプションではなく共有設定に入れているのには一応理由があり、文字通り複数のルールで共有される外部環境的な意味あいの強いデータだからです。
ここまでに説明した「ESLintを呼び出す」については、主に2つの方法があります。
ESLintは高級APIで、eslintコマンドとほぼ同等のことができます。一方、Linterは低級APIで、Node.jsのシステム環境に依存しない処理 (単一のソース文字列を受け取ってから、診断結果とautofixの結果を返すまで) を提供しています。
現在hi18nでは低級APIであるLinterを使っていて、対象となるファイルの収集などはglob packageを使って独自に実装しています。これにはいくつかの理由がありますが、最大の理由は hi18n内では無関係のルールは有効化したくない という点にあります。ESLintクラスはeslintrcの読み込みからautofixの適用までを全て実行してしまうので、このパイプラインの途中でルールを無効化するタイミングがありません。設定ファイルのオーバーライドを指定することはできますが、あくまで個別のルールの設定を上書きできるだけで、ホワイトリストにないルールを一括で無効化するのは難しそうでした。
実は現在ESLintでは Flat Config と呼ばれる新しい設定フォーマットの導入が進められていて、この設定ファイルはNode.js上でrequireするだけというインターフェースのため、ESLintが算出する設定と同じ結果を得るのも簡単な可能性があります。また古い設定フォーマットについても @eslint/eslintrc という互換レイヤを通すことでFlat Configに変換できるようです。実際に試したわけではないですが、これらを使えばESLintが読み込む設定を再現した上で、無効化すべきルールを全て列挙することもできるかもしれません。
もうひとつESLintで注意するべき点として、directiveの扱いがあります。directiveとはこういうものです:
// eslint-disable-next-line @typescript-eslint/no-non-null-assertion
foo.bar!.baz(); このようなdirectiveは、もしルール自体が存在しなければエラーとして報告されます。もし当該プロジェクトがESLintを設定している場合、hi18nはそれよりもプラグインやルールが少ない状態でESLintを呼び出すため、本来であれば妥当なdirectiveが意図せずエラーとして報告されてしまうことがあります。
これはあまりよい対策方法がなかったため、エラーメッセージが所定の正規表現にマッチしたら無視するようにしています。
今後の展望 hi18nのCLIツールの中核であるsyncコマンドの実装について説明しましたが、syncコマンド自体にまだできることが色々あります。
まずはログや統計の表示です。現時点ではhi18n syncは黙って処理を終えるのでユーザーを不安にさせがちです。どういったファイルが同期の対象になったかや更新結果を表示するだけでもだいぶ違いそうです。また、何らかの理由でカタログファイルが同期対象から漏れていると困りますが、ログがあればそういった不備にも気付きやすくなりそうです。
また、カタログファイルが同期対象から漏れる事故を防ぐには、設定ファイルで同期対象を明示する機能があってもよさそうです。
チャンクサイズの削減のために実際に翻訳データを分割してみると、どうしても複数のbookにまたがったほうが自然なデータが発生してしまうことがあります。こういった場合には異なるbook間で同じ翻訳データが入っていることを保証できると安心です。これもファイルをまたがった処理になるためESLint ruleではなくCLIで対応するのが自然でしょう。
別のi18nライブラリからの移行のサポートも改善の余地があります。CLIの同期処理で、使われている翻訳が実際には定義されていないとき、もし同名の翻訳IDに対するデータが移行元ライブラリのデータに存在していれば、そこから自動的にデータを取得できると便利そうです。
また、移行ではなく別のi18nライブラリとの共存というパターンも考えられます。具体的にはRailsとReactの混成プロジェクトで一部の翻訳データが共有されているケースなどがあります。このようなケースでは、外部i18nライブラリとhi18nの間での翻訳データの整合性が自動で検査されると安心です。
syncコマンド以外にも自動化したいものはいくつかあります。まず第一には最初のセットアップです。hi18nはランタイムで完結する部分が多いとはいえ、一定のボイラープレートコードは必要ですし、CLIツールやESLintの設定まで含めるとユーザーに漏れなく行わせるのは大変です。敷居を低くするためにもinitコマンドはぜひ作っておきたいところです。
また導入済みのプロジェクトで新たにロケールやbookを追加するのもできれば自動化したいところです。
まとめ i18nライブラリでは翻訳データとアプリケーションの同期を保つためのツールがしばしば存在する。 hi18nの場合はJavaScript/TypeScriptファイル自体が翻訳データの大元になるため、同期処理ではこれを直接加工することになる。 JavaScript/TypeScriptファイルを加工するためのエコシステムはいくつかあるが、今回はいくつかのメリットを考え、linterのフレームワークであるESLintの仕組みに乗っかることにした。 ESLintや周辺ライブラリはかなり充実しているが、それでも相手はプログラムソースそのものであるため、理想の体験を実現するにはかなり工夫と体力が必要だった。 TypeScriptでESLintプラグインを書くにはeslintパッケージを直接使わず、@typescript-eslint/utilsを使ったほうがよい。 次に読む 
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


