/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

/assets/images/5673658/original/767e046d-422d-44e3-ac17-74af4a96146e?1709547072)
Wantedly, Inc.'s job postings
- バックエンド / リーダー候補
- PdM
- Webエンジニア(シニア)
- Other occupations (17)
- Development
- Business

こんにちは。Matching チームの笠井(@unblee)です。
この記事では、おおよそ1年以上前に私が新卒入社して Infrastructure チームで一番最初に取り組んだ Workflow Engine の導入プロジェクトについての振り返り・供養をしようと思います。
記事内で触れている情報・判断は全て1年以上前の時点の社内外の状況に基づいていることを前提としているため現在の最新の情報とは異なることがあります。この前提を承知した上でお読みいただければ幸いです。
Wantedly では以前から推薦基盤へ力を注いでおり、Wantedly Visit におけるユーザと企業の理想のマッチングを実現するための推薦システムの改良や、データサイエンスを活用したプロダクト開発に責任を持つ専門のチーム(現在は Matching Squad)を立ち上げて開発を行っています。
この記事の主題である Argo Workflows 導入のきっかけは、1年以上前に当時の推薦基盤チーム(Recommendation Squad という名前だった)が構築していた基盤で使われる Batch Job の複雑化を解決するためでした。
Wantedly のインフラには以下のような特徴があります。
このような前提の下、当時の推薦基盤は以下のような状況でした。
推薦基盤のスケールが小さい状況では問題無かったのですが、徐々にスケールが大きくなる、複雑性が増してくると以下のような問題が表面化してきました。
以上の問題を解決するために、Batch Job の依存関係の適切な実行とコード上での明示的な管理の実現を狙って Workflow Engine の導入を検討し始めました。
世の中に Workflow Engine は数多く存在します。それらの中から Wantedly のユースケースに寄り添ったものを絞り込むための要件定義と、実際に動かしてみないと分からないこともあるので動作確認を当時 Wantedly に来ていたインターン生と最初に取り組みました。
社内へのヒアリングによって導入においては以下の要件があることがわかりました。上にある要件ほど優先度が高いものになります。
以上の要件から、ざっくりドキュメント等の調査だけをして最低限要件を満たしていそうだと感じた以下の Workflow Engine を導入候補として検証を進めました。
検証内容としては、推薦基盤で実行される実際の Batch Job の依存関係を各プロダクトの表現方法で記述し、検証環境で実際に実行してみるということを行いました。
検証の結果、各 Workflow Engine が要件を満たしているかどうかをチェックしたところ以下のような結果になりました。
この結果を社内のインフラエンジニアや推薦基盤チームといったステークホルダに共有し、最終的にはWantedly の運用基盤である Kubernetes のエコシステムの上に乗りつつ運用知見の蓄積・応用がしやすい Argo Workflows を導入することに決まりました。
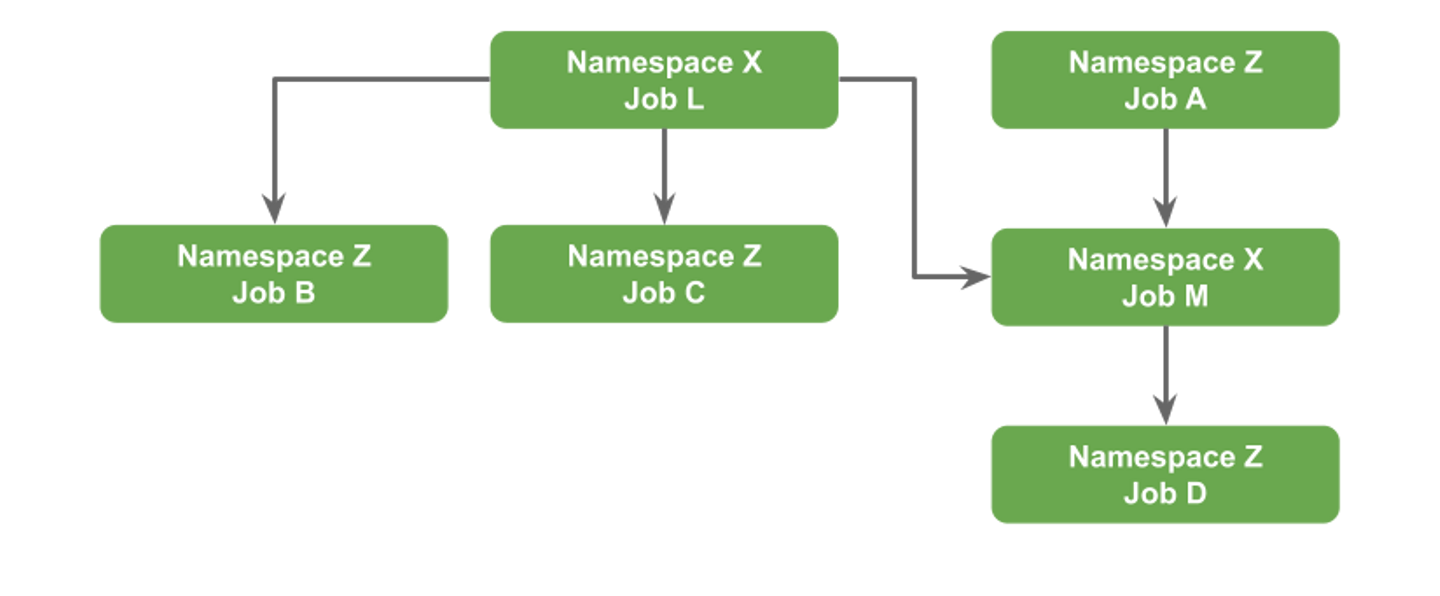
PoC では当時推薦チームが管理している以下の CronJob の依存関係を Argo Workflows に置き換えるということをやりました。画像は載せられませんが、元々はホワイトボードで Job 名とその実行開始時刻の依存関係を管理していました。
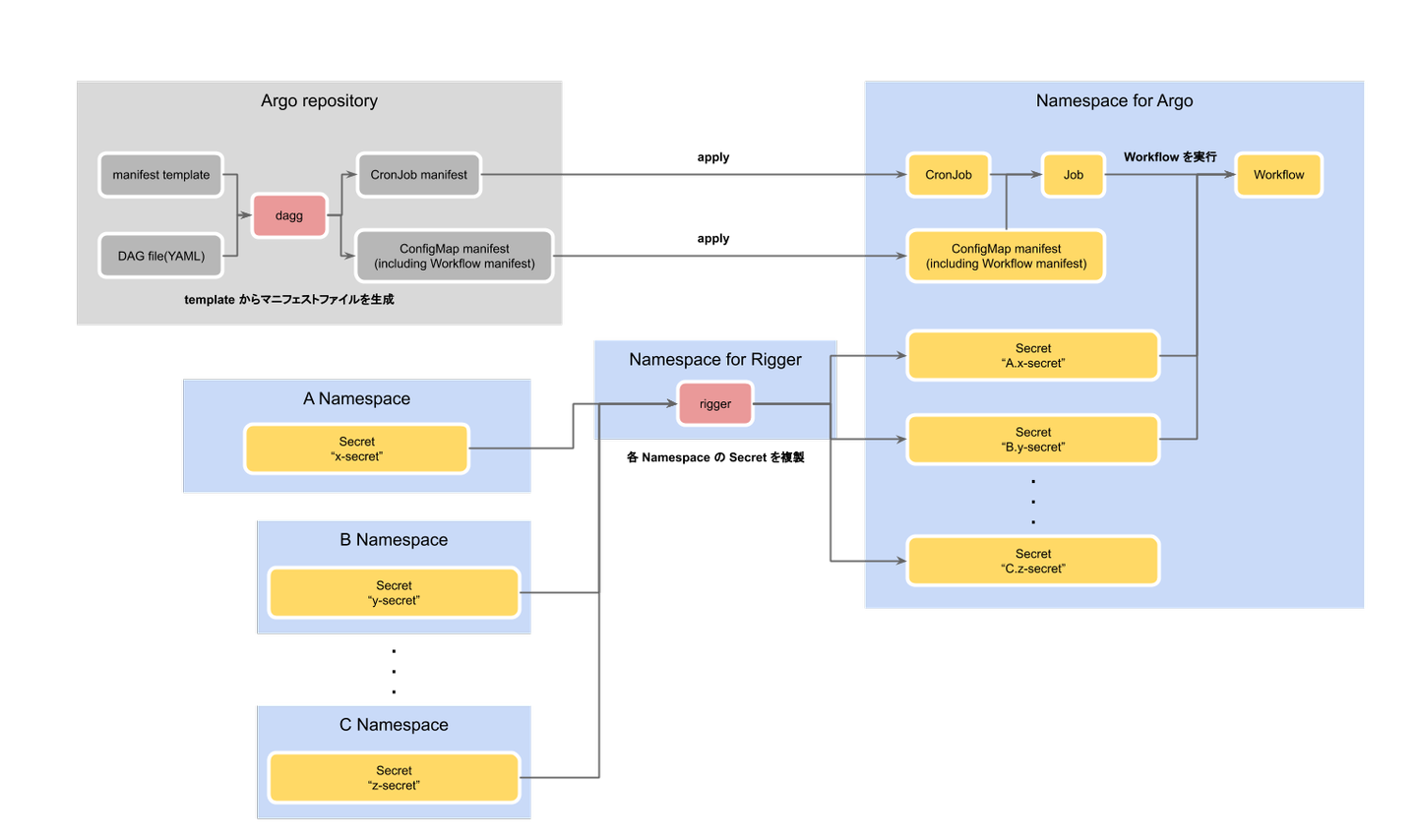
社内環境とユースケースにフィットさせるために小さなツールを自作しつつ、以下のようなアーキテクチャで Workflow を実行しています。
Argo v2.5.0 からは Cron Workflows があるのでそれを使えば良いと思いますが、当時は無かったので Workflow マニフェストを ConfigMap に書き出してそれを CronJob から argo-cli コマンドで叩くという運用をしました。
例えば、以下のようなマニフェストファイルになります。
---
apiVersion: v1
kind: ConfigMap
metadata:
name: argo.argo-workflow.cm
namespace: argo
data:
argo.argo-workflow.wf: |
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: argo-workflow-
spec:
entrypoint: argo-workflow
imagePullSecrets:
- name: xxx
templates:
- name: microservice-A
container:
image: registry/wantedly/microservice-A:latest
command:
- awesome
- command
envFrom:
- secretRef:
name: microservice-A.dotenv
- name: microservice-Z
inputs:
parameters:
- name: jobname
container:
image: registry/wantedly/microservice-Z:latest
command:
- amazing
- command
envFrom:
- secretRef:
name: microservice-Z.dotenv
- name: argo-workflow
dag:
tasks:
- name: microservice-A-A
template: microservice-A
- name: microservice-A-B
dependencies: [microservice-A-A]
template: microservice-A
- name: microservice-Z-C
dependencies: [microservice-A-A]
template: microservice-Z
- name: microservice-Z-D
dependencies: [microservice-A-B, microservice-Z-C]
template: microservice-Z
---
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: argo.argo-workflow.cj
namespace: argo
spec:
schedule: "0 20 * * *"
successfulJobsHistoryLimit: 10
failedJobsHistoryLimit: 3
startingDeadlineSeconds: 300
jobTemplate:
metadata:
name: argo.argo-workflow.cj
namespace: argo
spec:
backoffLimit: 0
template:
metadata:
name: argo.argo-workflow.cj
namespace: argo
spec:
serviceAccountName: argo-wf-creator
restartPolicy: Never
containers:
- name: exec-workflow
image: argoproj/argocli:vX.Y.Z
command:
- argo
- submit
- /argo-wf/argo.argo-workflow.wf
volumeMounts:
- name: wf-manifest
mountPath: /argo-wf/
volumes:
- name: wf-manifest
configMap:
name: argo.argo-workflow.cm見て分かると思うのですが、かなり構造が入り組んでいて人間が手で編集するのは現実的ではありません。導入当初はテンプレートをコピペして必要な部分を編集するようなことをしていたのですが、複雑さを隠蔽し切れていませんでした。そこで推薦基盤チームの @rerost がテンプレートとパラメータファイルを組み合わせることで Workflow マニフェストファイルを生成する rerost/dagg という小さなツールを作ってくれました。これを使うと複雑なマニフェストが以下のようにユーザが興味のある部分だけ編集すれば良いものになりかなり生産性を向上させる事が出来ました。
name: argo-workflow
option:
team: argo
schedule: "0 20 * * *"
jobs:
- name: microservice-A-A
commands: [awesome, command]
option:
repo: microservice-A
- name: microservice-A-B
commands: [awesome, command]
dependencies: [microservice-A-A]
option:
repo: microservice-A
- name: microservice-Z-C
commands: [amazing, command]
option:
repo: microservice-Z
dependencies: [microservice-A-A]
- name: microservice-Z-D
commands: [amazing, command]
option:
repo: microservice-Z
dependencies: [microservice-A-B, microservice-Z-C]また、Wantedly のインフラの特徴に書いたように推薦基盤用の Batch Job の具体的なコードは複数のリポジトリに分散しておかれています。Secret は Namespace を超えて参照することが出来ないので Argo を実行している Namespace に必要な CronJob を含むリポジトリに対応する Namespace の Secret を複製するツールが必要だと考えました。そこで作成したのが、wantedly/rigger という小さな Kubernetes の Custom Controller です。これによって複数のリポジトリ(Namespace)にまたがって Batch Job のコードが分散している Workflow の実行が可能となりました。詳細は以前私が発表した資料を参照してください。(この資料を発表したとき Argo のメンテナの方からより適切な方法を教えてもらったので社内でもいずれ rigger は使わなくなるかもしれません)
これらのツールを使って以下のような流れで Workflow を実行しています。
プロジェクト進行では現在も意識している基盤チームとアプリケーションチームでプロジェクトをうまく進める方法について学べたと思っています。
当初挙がっていた問題は Argo Workflows の導入によって全て解決することが出来ました。
実際に運用してみて起こった問題として具体的には以下のことが挙げられます。
1年以上前のプロジェクトについて振り返ってみました。当時はまだ新卒入社したばかりで最初のプロジェクトがこれだったので、プロジェクト進行とか初めてのことばかりで苦労していた記憶しかなかったんですが、約3ヶ月前に Infrastructure チームから推薦基盤(Matching)チームに異動して今改めて振り返ると、現在も Argo Workflows によって推薦基盤が構成されていてもう Argo Workflows の無い世界は想像出来ないので、とても重要でインパクトのあるプロジェクトだったんだなと振り返ったことで改めて実感しました。反省点も色々ありますが、このプロジェクトで学んだことが自分の仕事の基礎になっていると実感しているので、最初に取り組めてとても良い経験になりました。
Infrastructure チームや推薦基盤(Matching)チームではインパクトのある面白い取り組みでどんどん攻めていくので興味のあるエンジニアの方や学生の方がいれば気軽に話を聞きに来てください!

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)