/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


Wantedly, Inc.'s job postings
- バックエンド / リーダー候補
- PdM
- Webエンジニア(シニア)
- Other occupations (17)
- Development
- Business
※ Looker Advent Calendar 2020 15日目の記事です。
WantedlyでBI Squadのリーダーをしている永島 (@hedjirog) です。グロースに取り組んでいた延長でBI Squadを新設して、開発チームの開発優先度を決める際の意思決定支援や提言を行なっています。BI Squadの新設以降、Looker移行に加え、North Star Metric選定やユーザーセグメント定義といったグロースの経験を活かしたアウトプットに取り組んできました。
この記事は、Year End Looker Meetup 2020における登壇内容の前半部分で扱ったDAU/WAU/MAU集計の詳細について、説明を加えた上で改めて書き起こしたものになります。発表時の資料もあるので、併せてご覧ください。
BIツールを扱う上で集計時のパフォーマンス(集計結果が返却される速さ)が良好な状態にできているかということは重要です。集計時のパフォーマンスは欲しいデータが即座に取得できるかといったエンドユーザーの体験に直結します。
特に、データ探索を目的としてBIツールを利用する際はこの重要性がさらに高まります。データを探索する際は様々なフィルター条件を指定しながら集計を繰り返すため、集計時のパフォーマンスが悪い状態にあるとエンドユーザーの体験が悪化しやすくなると言えます。
集計時のパフォーマンスを向上させるための手段としてどのようなものがあるでしょうか。考えられる手段のひとつに、集計の対象となるデータセットをユースケースに沿って事前に集計しておき、適切な粒度に整形しておくということがあります。このような解決の類いは、限定的な条件下での集計を事前に行なうために、エンドユーザーがデータ探索できる条件の幅を狭めてしまうことになり兼ねません。
データ探索時における柔軟なフィルタリングと集計時のパフォーマンス向上をどのように両立させるか。これが、この記事で扱いたいテーマです。
なお、この記事ではLookerのExplore機能を用いたデータ探索を前提として進めます。
この記事では、Lookerのデータ探索時における柔軟なフィルタリングと集計時のパフォーマンス向上を両立させる具体的な手法を提案します。
提案する手法では、集計を行なう派生テーブルの実装時に以下の2点を工夫します。
以降では、DAU/WAU/MAU(アクティブユーザー数)の集計を例にして、これらの工夫について説明します。
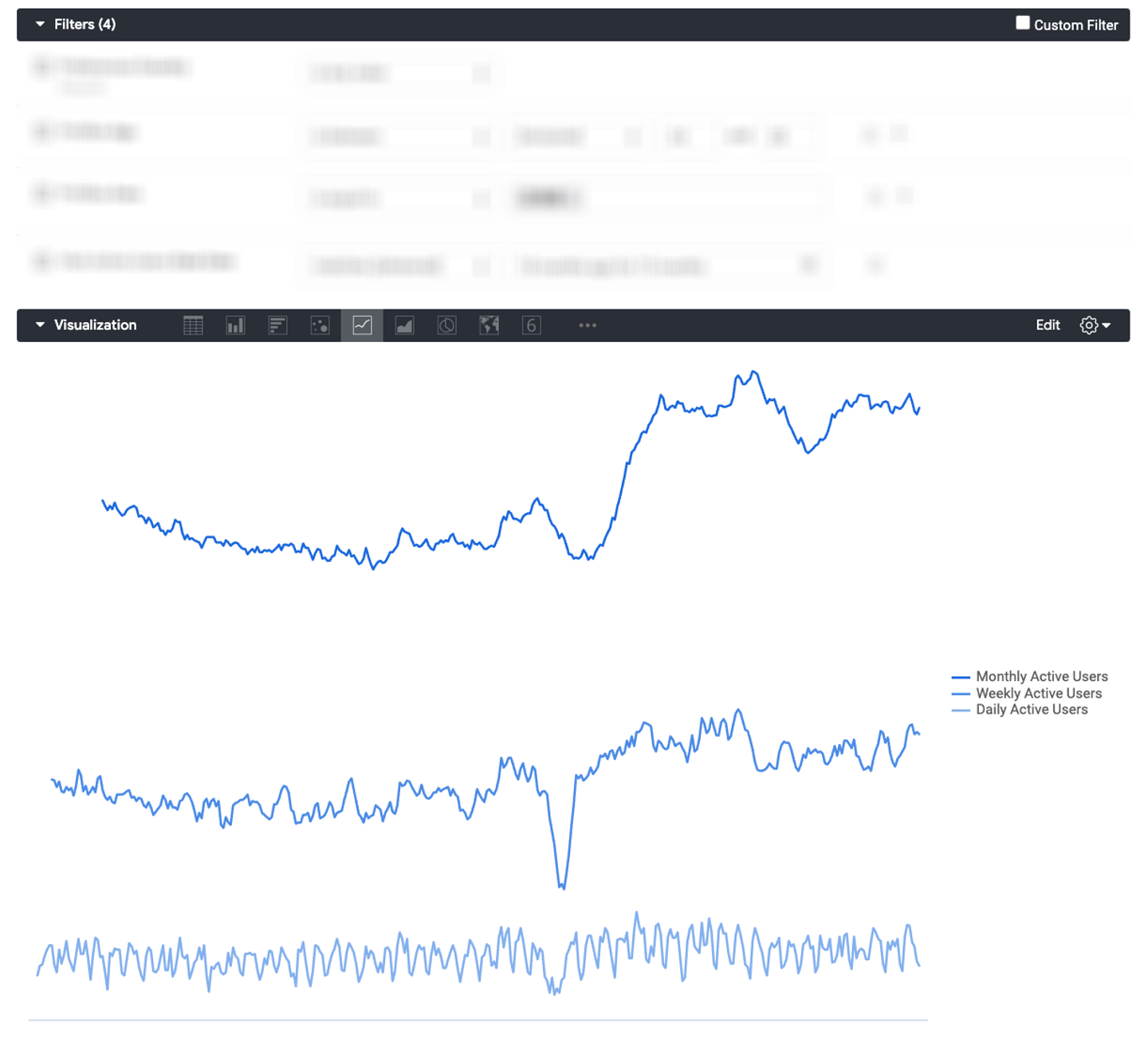
Wantedlyでは、DAU/WAU/MAUの集計が可能なExploreを利用しています。
これは、実際のExploreで出力した日次のDAU/WAU/MAUの推移です。
Exploreでは、ユーザー属性の情報をフィルター条件として指定することで、様々な条件で集計を行なうことが可能です。ユースケースとして、例えば、21卒の学生は増加傾向にあるかといった属性ごとの動向を把握したり、学生のピークは例年いつ頃かといった属性ごとの季節性や周期性を把握したりすることを想定しています。*1
Exploreは日次の集計が可能で、かつ、集計に含める期間を限定しません。様々な条件の指定を許容しながら、数年分を遡って現実的な実行時間で集計を行なうには、先に示した実装時の工夫が重要になります。
ここからは、集計を行なう派生テーブルの実装について順を追って説明します。
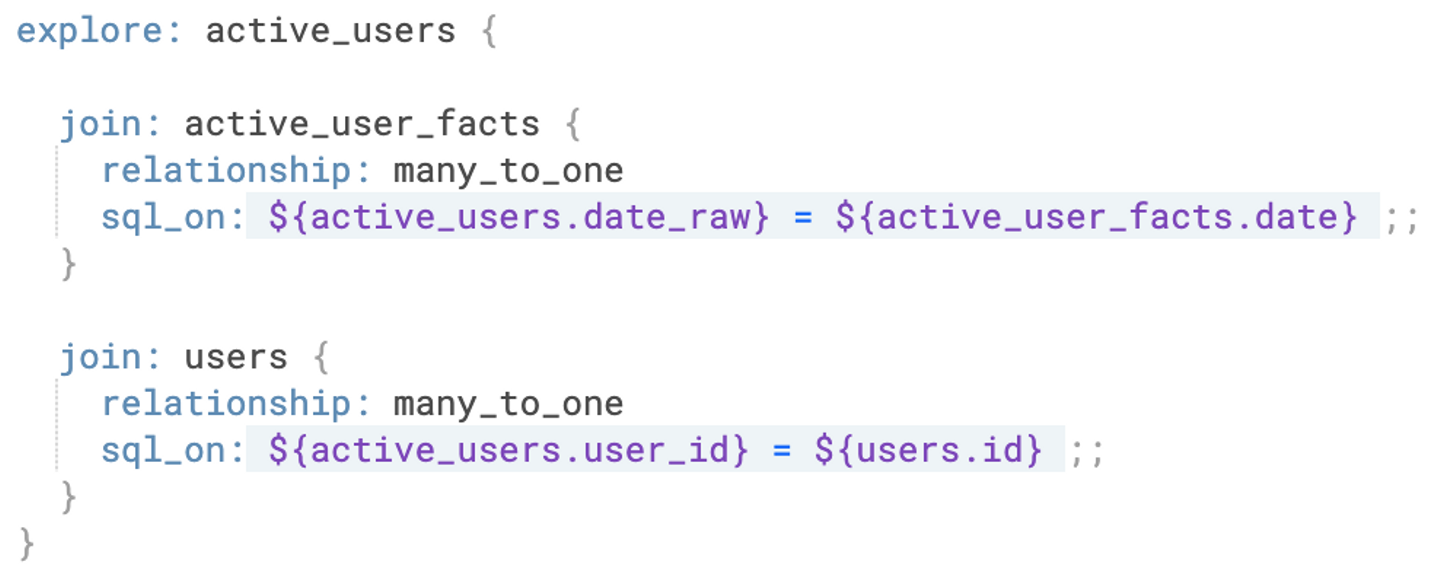
まず、集計を行なう派生テーブルの位置付けを説明するために、exploreの実装を示します。
この実装は、派生テーブルを含むexploreの実装を簡略化したものです。
各ビューの役割は以下の通りです。
集計を行なう派生テーブルであるactive_user_factsは、usersから得られるユーザー属性を用いてフィルター条件を決定し、active_usersのデータの集計を行ないます。
次に、active_user_factsが行なう集計に相当するDAU/WAU/MAUの集計クエリを示します。
このクエリは、派生テーブルを実装する際に想定したBigQueryの集計クエリを簡略化したものです。
各テーブルの役割は以下の通りです。
集計クエリでは得られたスケッチからカーディナリティを推定することで、最終的にDAU/WAU/MAUを近似集計します。これらの近似集計はHyperLogLog++関数を用いて実現しています。COUNT(DISTINCT)などの集計関数と比較すると統計的な不確実性が生じる一方で、大幅なパフォーマンス向上が期待できます。*2
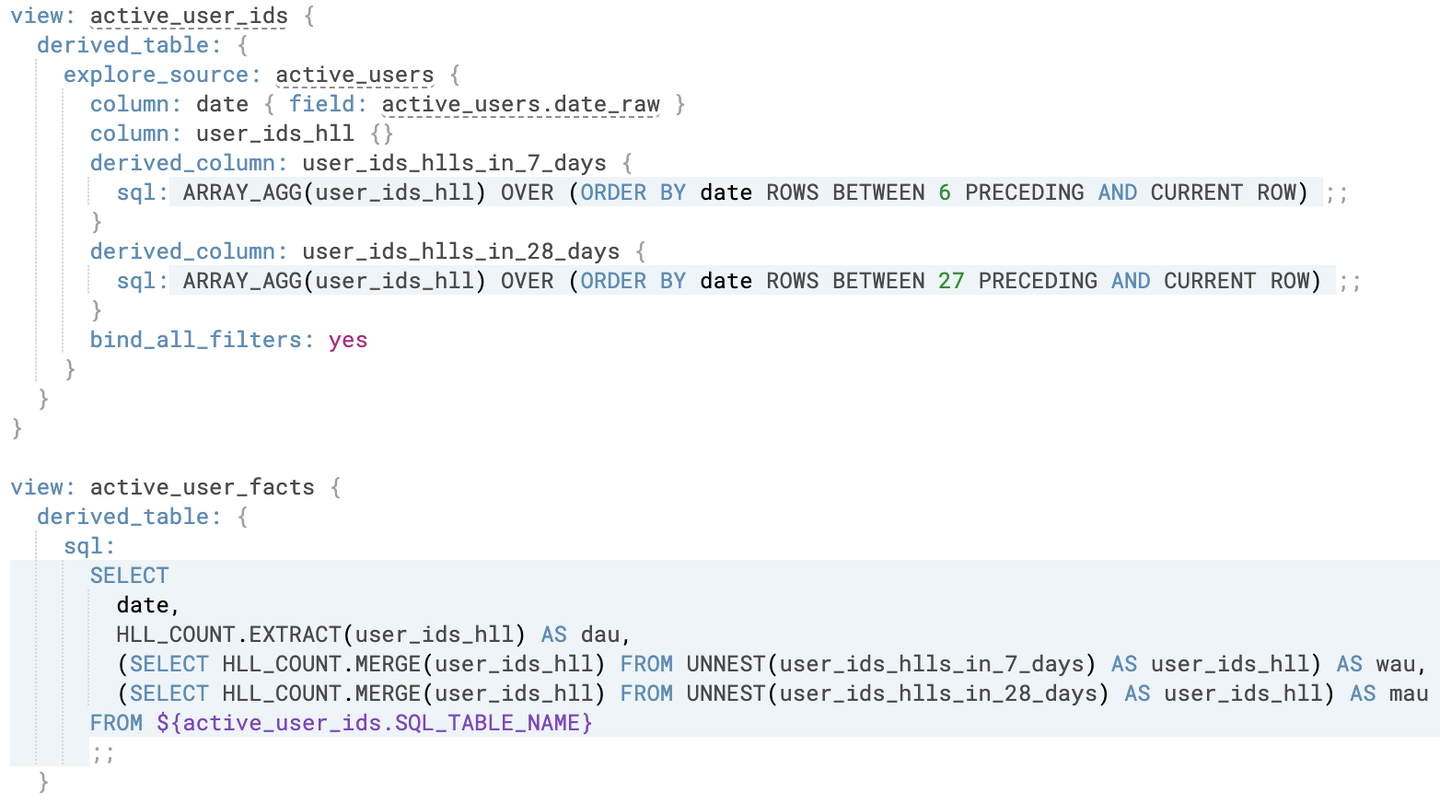
最後に、集計を行なう派生テーブルであるactive_user_factsの実装を示します。
ネイティブ派生テーブルを用いて、集計クエリにおけるactive_user_idsテーブルと同等のデータを取得可能なビュー (active_user_ids) を定義しています。定義の際は、bind_all_filtersパラメーターを有効化する設定を行なっています。これにより、Exploreで指定されたすべてのフィルター条件をネイティブ派生テーブルが生成するサブクエリに反映することができます。
active_user_factsのビューでは、近似集計を行ない、フィールドを定義して集計結果を取得できるようにしています。
Lookerのデータ探索時における柔軟なフィルタリングと集計時のパフォーマンス向上を両立させる具体的な手法の提案と派生テーブルの実装について説明しました。bind_all_filtersパラメーターを利用してデータ探索時における柔軟なフィルタリングを可能にしながら、近似集計関数を用いて集計時のパフォーマンス向上を図るというのがこの記事で提案した手法の要点です。
WantedlyのBI Squadでは、Lookerのグロース用途での活用を進めており、今回紹介したDAU/WAU/MAU集計以外に、コホート分析、継続率分析での利用も進めています。少しでも興味があれば、連絡をください!BI Squadの取り組みやLookerの活用の詳細についてお話しできます。
*1: DAU/WAU/MAUはプロダクトの価値をユーザーが体験したかを示す指標ではないので、プロダクト開発における重要な指標としては扱うということはしていません。
*2: 30億件のデータを用いて5倍弱の高速化を行なえたという検証の報告があります。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)