こんにちは!Wantedly でバックエンドエンジニアをしている縣です。
この記事では、先日行われた RecSys2020 での発表の中から個人的に興味を惹かれたものをいくつかご紹介しようと思います。
この記事は Wantedly から RecSys 2020 に参加したメンバーのブログリレーの一環です。これまでの記事は以下から参照ください。
この記事の内容は、僕の個人的な趣味により Matrix Factorization や Embeddings に関連するものが多くなっています。
これらの手法は、(大雑把な表現ですが)複雑な構造を持つデータや Item-User 間の Interaction を多次元のベクトルとして表現して機械的に扱いやすくするものです。
推薦に限らず自然言語処理など様々なユースケースで登場するのですが、推薦システムという観点から見ると、協調フィルタリングとのアナロジーからも理解しやすく親和性が高いです。
多次元のベクトル表現という中間生成物を介することによって、推薦の精度のみならず、推薦システムのスケーラビリティや説明性などの要求に対しても良い性質を持っていて、研究や応用例が多く、個人的にもとても興味を持っています。
Embedding ベースのシステムの利点などについては以前 builderscon 2019 で登壇した時に話したのでそちらをご参照ください。
今回の RecSys 2020 も、既存の Embedding を用いた手法の発展系の発表が多く見られました。
この記事ではその中から 2 本ご紹介します。
(今回紹介するものは、特定のセッションテーマに縛られるものではなく、Real World Application や Explaination など様々なテーマに散っていたものを、僕が勝手に集約したものです。このことからも、これらのアプローチが推薦システムにとって汎用的・一般的な概念になりつつあることを感じています。というよりもはやテーマとして Embedding というのは不適切な気すらしてきました。)
さて、それでは本題です。(記事中の画像は発表資料からの引用です。)
The Embeddings that Came in From the Cold: Improving Vectors for New and Rare Products with Content-Based Inference
https://doi.org/10.1145/3383313.3411477
まず1本目は Industry Track から、推薦システム一般の問題である “Cold Start” 問題の、 Embeddings に関する側面に注目し解決を試みている発表です。
初見の感想としては、若干遠回りな解決を提案しているという印象を受けたのですが、「既存の Interaction ベースの推薦(それに基づいて作られたシステムを含む)に、ほぼ無料で乗せられる新規アイテムサポート」と捉えると実利のあるものに感じられたので紹介してみます。
Cold Embeddings
一般的な Embedding ベースの手法では、アイテムのベクトル表現を得るために過去のログなどを用いた学習を行います。
推薦のために利用することを考えると、多くの場合、購入などの Interaction のログを用いた学習をすることになります。
学習がうまくできれば、似たアイテム同士の距離が短くなるようなベクトル表現が獲得され、ベクトル同士の類似度ベースで推薦を出したり、別の推薦モデルの入力として有益に利用できたりします。
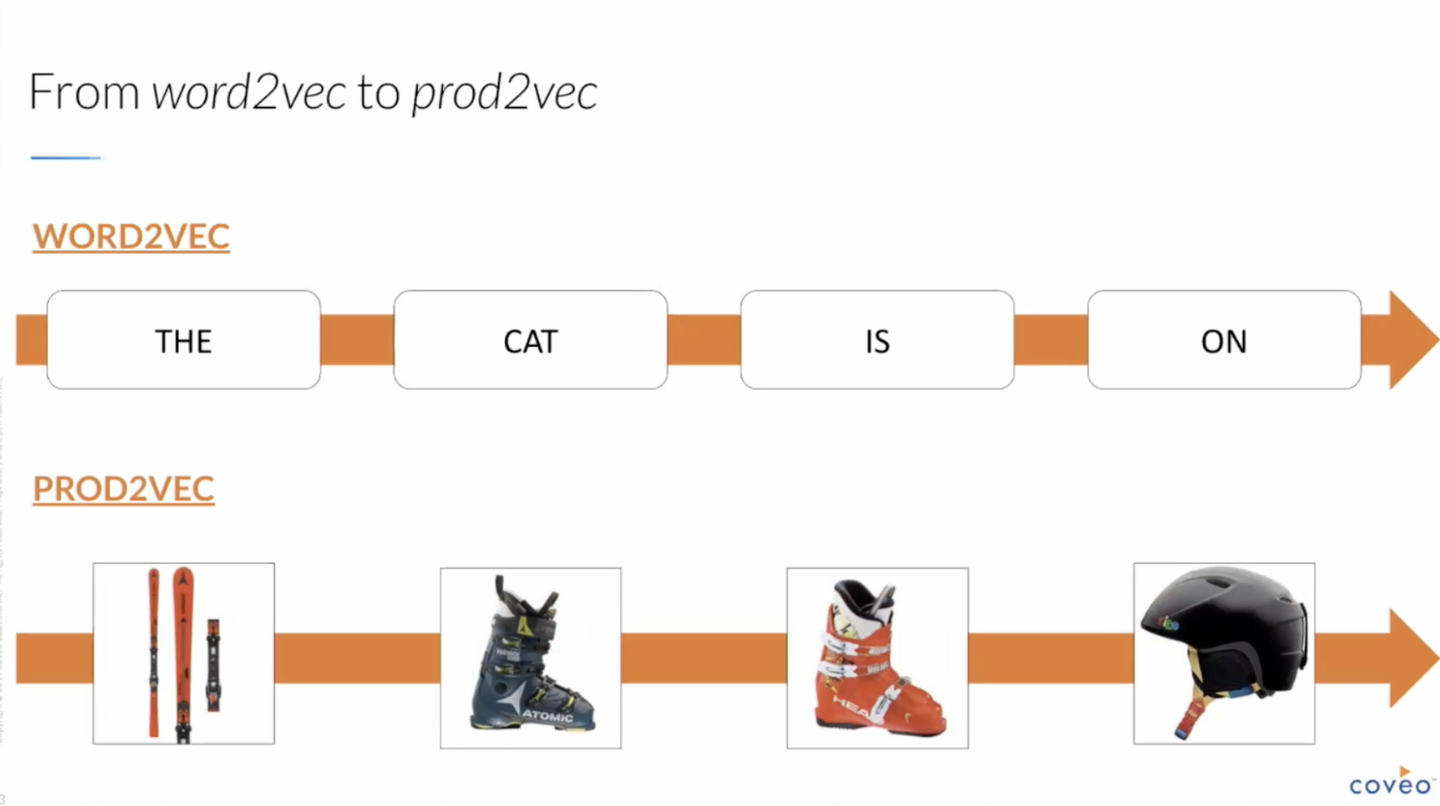
学習にはいろいろな方法が採用されますが、ここでは「同一セッションで閲覧したアイテムの時系列順の並び」を基に word2vec 的な方法で学習する prod2vec が紹介されています。
![]()
より伝統的でメジャーな手法としては、 U x V (ユーザ数×アイテム数)の行列で購入情報を表現し、 U x d と d x V に行列分解することで、ユーザとアイテムそれぞれに対して d 次元のベクトルを得る Matrix Factorization が挙げられます。
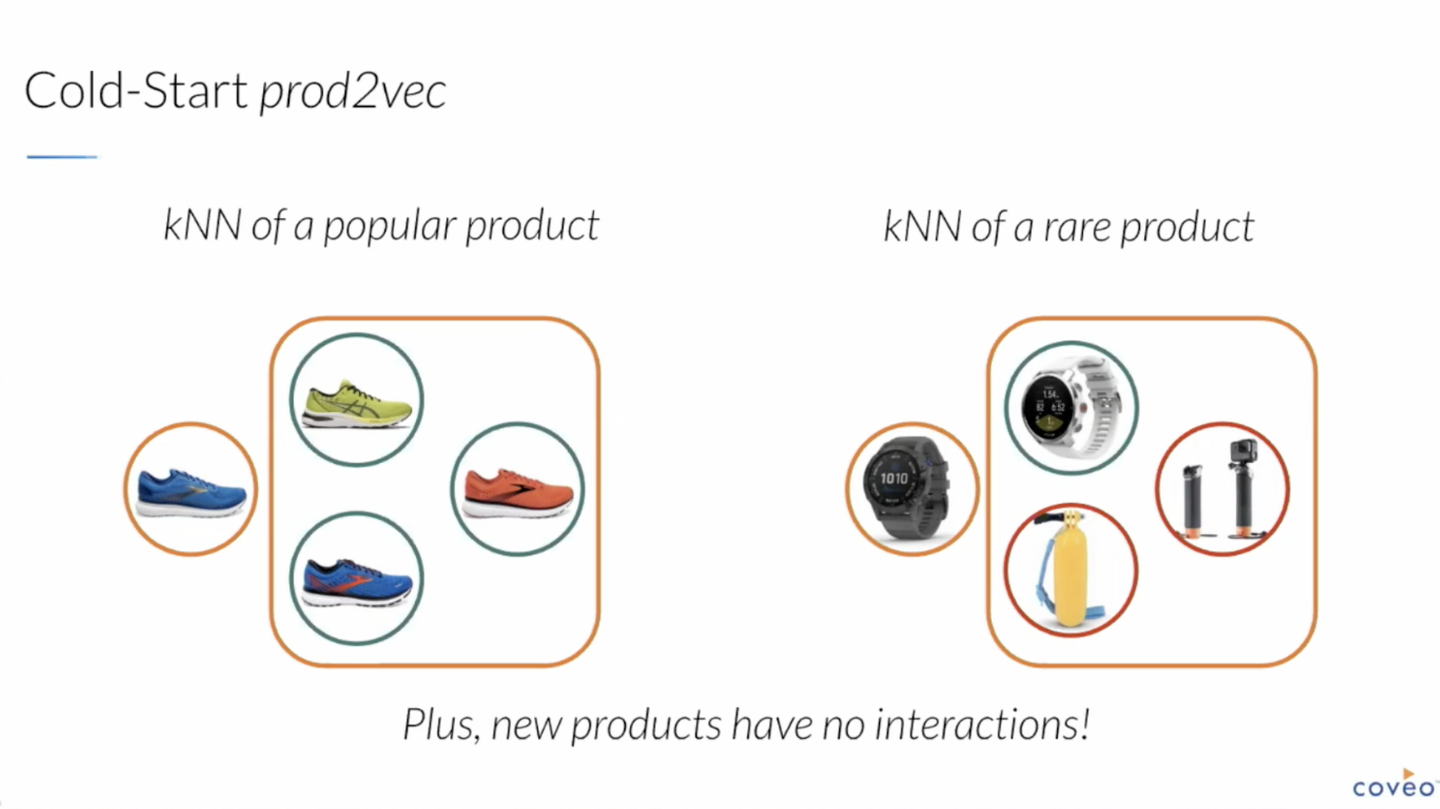
このとき、より多くの Interaction に紐づいたアイテム(一般的で人気なアイテムや古くから存在するアイテム)は教師データが多く、クオリティの高い有用なベクトル表現が学習できます。
一方で、関連 Interaction が少ないアイテム(限定的、不人気なアイテム)は教師データが少なく、ベクトルのクオリティがあまり高くできない場合があります。
また、新規に追加されたばかりのアイテムに至っては、Interaction が存在しないため学習することができず、ベクトルを定義することすらできません。
その結果、レアなアイテムに関する推薦の精度が非常に悪くなってしまうなどの問題が生じます。
![]()
Content-Embedding による補完
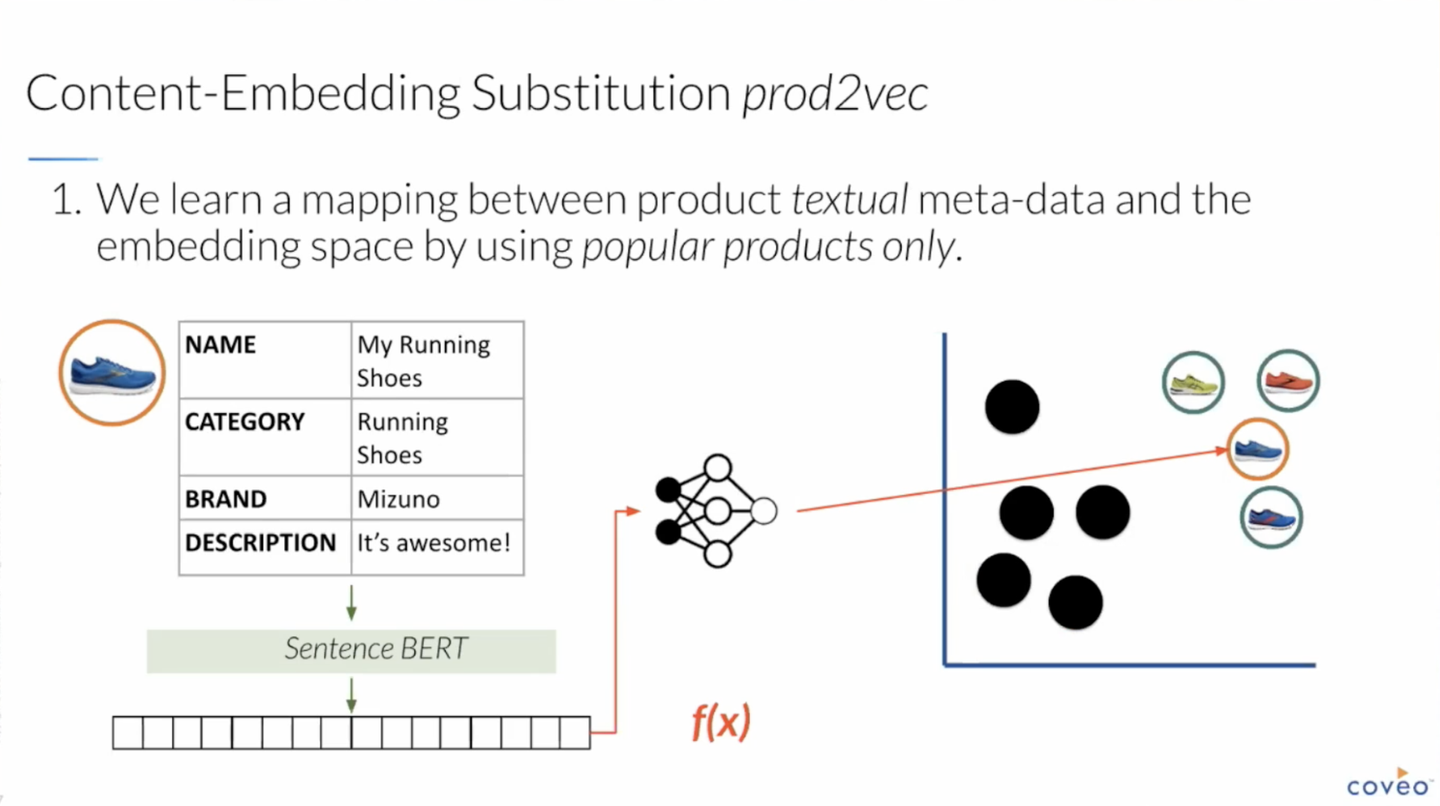
そこでこの論文が提案しているのが、「Interaction から学習する Embedding」と「コンテンツ情報のみからベクトル表現に変換するニューラルネットワーク」を組み合わせる手法です。
多くの場合、アイテムは名前、カテゴリ、ブランド、自然言語での説明文などの Interaction に依存しない情報を持っています。
Interaction の少ない新規アイテムやレアなアイテムであっても、そのような情報は持っているはずです。
そこで、それらの情報を入力とするニューラルネットワーク (NN) を新しく導入し、「Interaction から学習する Embedding」を模倣するように学習します。
このとき、学習データとして「十分な量の Interaction があるアイテム」だけを使うようにすることで、クオリティの高い Embedding をうまく再現できるように学習されることが期待できます。
これによって「コンテンツ情報だけを使って Interaction ベースの Embedding を再現できる NN」を得ることができました。
![]()
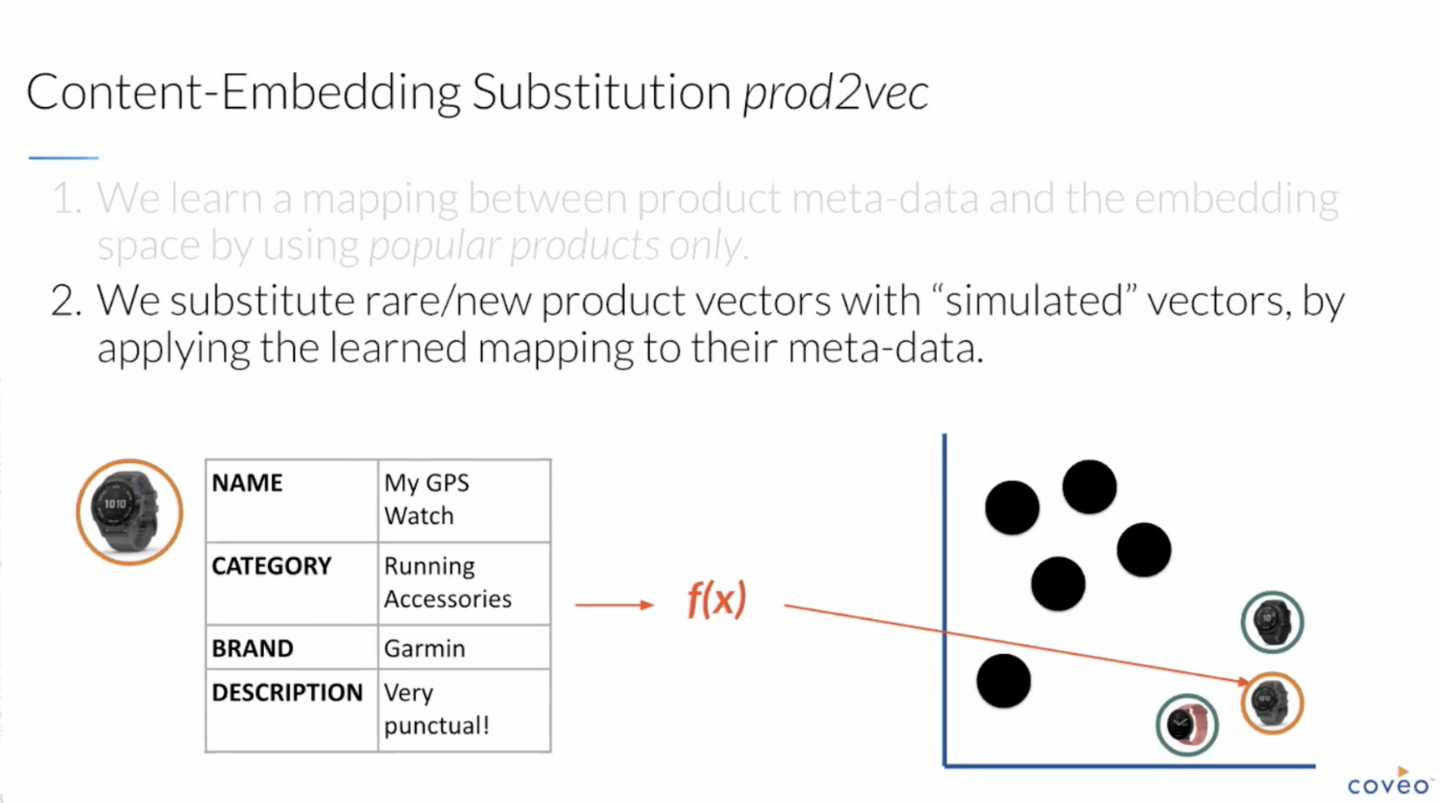
次に、その NN を用いて、Interaction の少ない新規アイテムやレアなアイテムの Embedding を計算します。
それらの Embedding と Interaction ベースの Embedding を組み合わせることで、良いとこどりの Embeddings が得られます。
組み合わせの際には、十分に Interaction のあるアイテムは素直に Interaction ベースの Embedding を採用し、そうでないアイテムは NN ベースの Embedding を採用するようにします。
![]()
この論文ではオフライン評価の結果、全体としての推薦精度 (NDCG) はほぼ保った状態で、レアなアイテムにおける推薦精度が 2x ~ 10x になったと主張されています。
また、推薦を外してしまったとき「レアなアイテムに対する推薦の間違え方」が納得感・一貫性のあるものになることも重要な特徴だと述べられています。
クオリティの低いベクトルに基づいた推薦で外した時は、ユーザから見るとなぜそれが推薦されたのかすらわからないものが現れやすかったのに対し、コンテンツ情報を使っている提案手法の場合は「コンテンツ的に類似している」というユーザから見て納得感と一貫性を感じられる間違え方になり、評価指標上はどちらも間違っているがユーザ体験としては改善している、と評価しています。
感想
新規アイテムに対する Embedding が定義できない問題は、現実としてよく直面する問題だと思います。
僕が開発している Wantedly People でも日々新規ユーザ登録は発生しており、それぞれのユーザに対してなるべく迅速に良い推薦を提供したい、というモチベーションがあります。
現状は Daily で再学習をすることでなんとかしていますが、規模次第では頻繁に 0 から再学習することは難しくなっていくでしょうし、登録直後の体験向上にはまだ活かせていない状況です。
ユーザ体験の一貫性という良い性質にも触れられていて面白かったですし、実装も簡単そうなので、ちょっと試してみたい気持ちになりました。
Learning Representations of Hierarchical Slates in Collaborative Filtering
https://dl.acm.org/doi/10.1145/3383313.3418484
続いては poster からです。著者は Netflix のチームです。
アイテムは個別ではなくリストやテーブル状の UI でユーザに提示されるので、それを陽に考慮して Embedding を作るべきではないか、という研究です。
Netflix らしい問題意識で面白かったのでご紹介します。
“Slate”
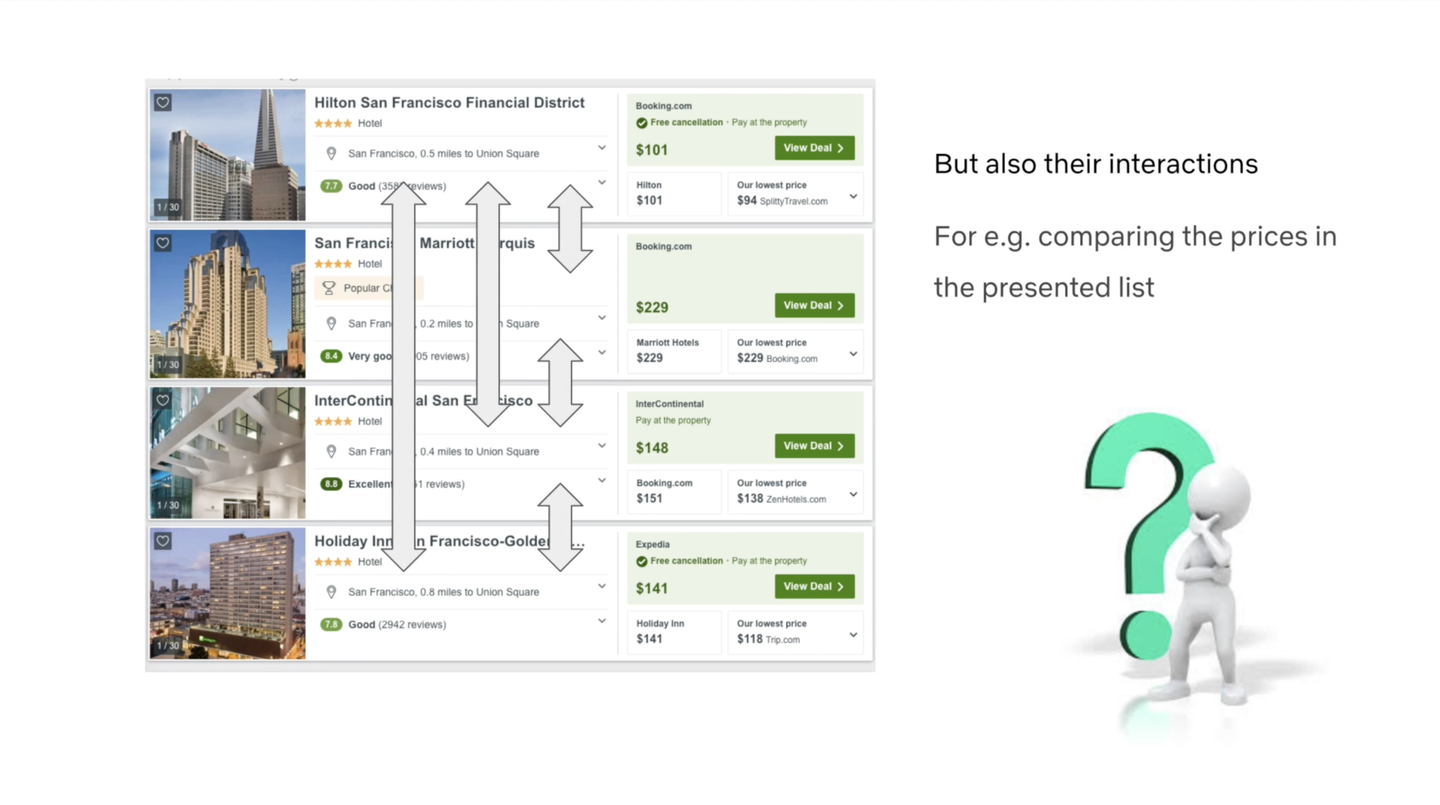
アイテムがユーザに提示されるとき、そのアイテムはどのように評価され、どのようにアクションを選択されるのでしょうか。
個別のアイテムの属性によって独立に決定される部分ももちろんありますが、周囲に並んだアイテム同士の属性の比較によって決定される部分もあるはずです。
例えばホテルの予約をする時には、ホテルのリストの中から価格を比較したりして「そのリストの中で相対的に良い」という判断をしています。
![]()
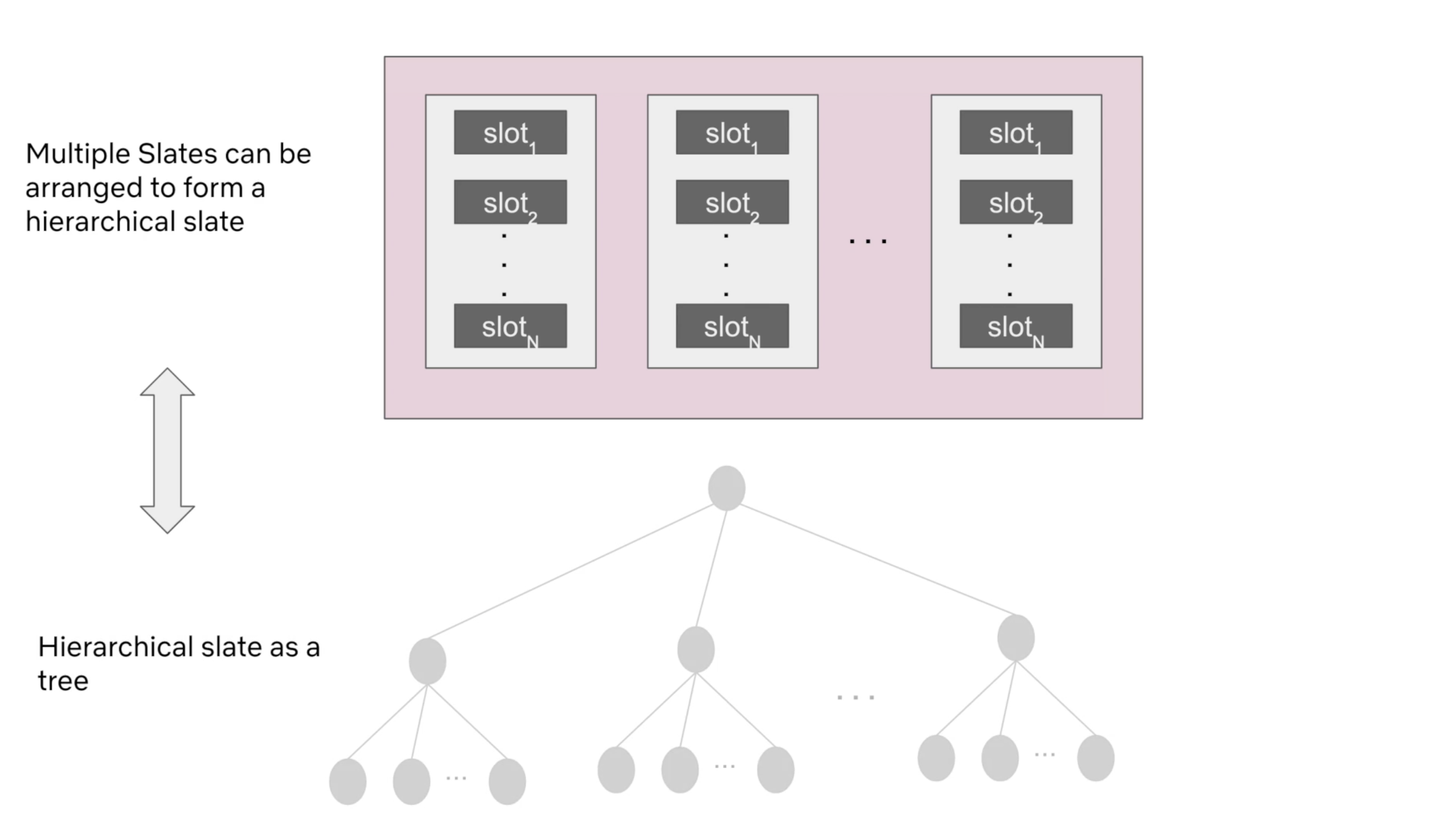
この論文では、このような問題設定を “Slate problem” と呼んでいます。Slate は「板」みたいな意味合いで、板に複数のアイテムが乗っかって表示されるという問題設定を表しています。
また Slate は、「Slate の list」のような構造があり得るため、階層的な構造を取り得ます。まさに Netflix がそういう UI ですね。各行に独立したカルーセルがあり、カルーセルの中にアイテムがある、という構造です。
![]()
Embeddings of slates
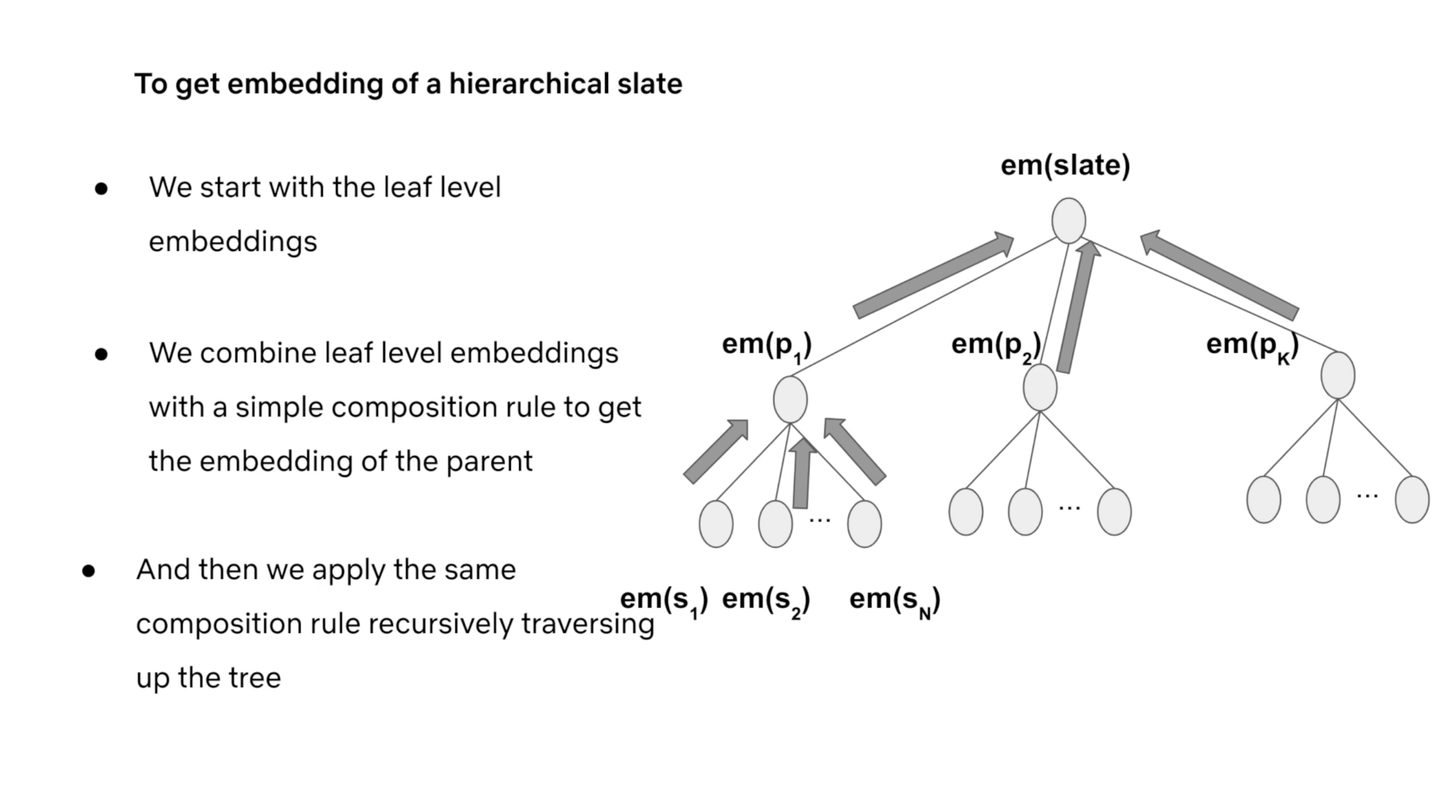
従来の典型的な推薦モデルは、個々のアイテムを独立に評価するものが多く、Slate 内のアイテム間の関係性を捉えきれていませんでした。
そこでこの論文では、複数の子アイテム(Slate)から成る Slate の Embedding を、子アイテム(Slate)の Embedding を集約することで構築する方法を提案しています。
イメージとしては、子供の Embedding の平均をとるような感じです。(実際にはもうちょっと複雑ですが)
![]()
このようにして得た Slate Embedding を、個別のアイテムの Embedding と組み合わせて利用することで、同一 Slate 上に配置された他のアイテムとの関係性を加味した推薦モデルを作れるのではないか、と述べられています。
利用例
実際の評価はいくつかのデータセットで行われているのですが、中でも RecSys Challenge 2019 のデータセットでの検証が面白かったのでピックアップします。
RecSys Challenge 2019 はホテル予約サイトであるトリバゴが協賛したデータ分析コンペです。
データセットは、ユーザがホテルを検索しいくつかの推薦リストを見たあと、最終的に一つのホテルに決定するまでのセッション全体を含むデータセットになっています。
各推薦リストは 25 個程度のアイテムから成り、同一セッション内で最大 15 回推薦リストを閲覧しています。
この問題設定は、非常に Slate の考え方とマッチしているといえます。
そこで Slate Embedding を用いたモデリング方法を 2 パターン提案し、それぞれの性能を一般的なモデル(Factorization Machine, NN, GBDT)と比較して評価しています。
ホテルの Embedding を基本の最小単位として、それらを組み合わせて Slate Embedding を作っていきます。
- 内包するホテルの Embedding を集約 → 推薦リスト全体の Embedding
- 閲覧した推薦リストの Embedding を集約 → ユーザが体験したセッション全体の Embedding
また、ちょっと面白いのは、同一 Slate にある自分以外のホテルの Embedding を組み合わせて構築した Remaining Slate Embedding を用いることで、相対的な良さを陽に捉えようとしています。
Embedding 同士の内積に基づいて直接推薦するアプローチと、それをさらに別のモデルの入力の一部として利用するアプローチの両方を実験し、共に高い性能を確認しています。
感想
「相対的な良さ」を陽に考慮したモデリングになっていて単純に面白いなと思って紹介してみました。
Slate の考え方は、Netflix や Spotify など、推薦を中心としたサービスでよくありがちな状況だと思います。
あの手の UI では、複数の推薦理由に基づいた複数のリストが提示されていますが、あれをどう評価してどう改善していくか、というのはかなり難しい問題だと思っていて、実際 Spotify は盛んにその手の研究をしている印象を持っています。
個人的には、この手の全体に関わる手法を Netflix がどういうチーム体制で開発し、どう検証し、どう意思決定するのかが気になります。
この手法が高い性能を発揮するとしても、個別の推薦理由ごとに独立した評価・監視・改善を行っている体制だと、オンラインテストすることもなかなか難しい気がしています。
終わりに
Embedding ベースの機械学習システムには昔から興味があり、Wantedly People にも各所でいくつか試験的に導入してきました。
Facebook の発信している論文(2006.11632 Embedding-based Retrieval in Facebook Search や https://research.fb.com/publications/bandana-using-non-volatile-memory-for-storing-deep-learning-models/ )を見ても、Spotify, Alibaba, Yahoo! Japan などがこぞって近侍最近傍点探索のアルゴリズムやアルゴリズムを開発しているのを見ても、実サービスに推薦を届けるために Embedding を使うというのは一般的になってきているのではないかと思います。
もちろんこれらは大規模すぎる故の制約などが前提なため、常にこれらを使うと良いというわけではありませんし、もっとそれ以前にやるべきことが多いシーンだらけではありますが、夢があってとても面白いと思っています。
RecSys は「推薦」というテーマに対してバラエティに富んだ問題提起や新規提案がたくさんあり、とても楽しく聴講させていただきました。
エンジニアリング的な視点、社会的な視点、サービス開発的な視点、などなど多岐にわたる視点から「推薦」に向き合う 5 日間でした。
Industry track や問題提起系の話は、いわゆるデータサイエンティストでなくても楽しめるし知っていて損のない話だと思いました。(なのでこのシリーズの他の記事をまだ読んでいない方は是非読んで見てください。)
今回この記事でご紹介したのは 2 本だけですが、個人的にはまだまだ面白かった研究、発表がたくさんありました。(正直論文以上に簡単に説明できる気がしなかったので、ブログにかけませんでした… 詳細は論文を参照してください。)
- Neural Collaborative Filtering vs. Matrix Factorization Revisited
- https://dl.acm.org/doi/10.1145/3383313.3412488
- 伝統的な Matrix Factorization など Embedding 同士の比較に単純な内積を使うモデルに対して、Neural Collaborative Filtering など内積の代わりに MLP を使うモデルが提案されているが、実はパラメータを適切に調整すれば Matrix Factorization のように内積を単に使った方が性能が高いケースが多い、という問題を指摘している。 RecSys 2019 のベストペーパーから続く、進歩を見直す系の論文。
- Contextual and Sequential User Embeddings for Large-Scale Music Recommendation
- Explainable Recommendations via Attentive Multi-persona Collaborative Filtering
- Content-Collaborative Disentanglement Representation Learning for Enhanced Recommendation
- Combining Rating and Review Data by Initializing Latent Factor Models with Topic Models for Top-N Recommendation
- https://doi.org/10.1145/3383313.3412207
- rating 情報(や購入情報)を使った Latent Factor Models の初期値として、レビューの情報から計算したトピックモデルを用いた Embeddings を使うことで、Latent Factor Models の収束速度や性能を改善した。また、一方(e.g. ユーザ)の Embeddings を固定し、もう一方(e.g. アイテム)の Embedding のみを学習することで、トピックモデルの空間を維持した説明性の高い推薦が可能になることを示している。
まだまだ書き切れていない面白さや、RecSys を聞いて生まれた夢みたいなものもあるので、興味のある方はぜひ話を聞きに来てください!

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)



/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


