/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

Wantedly, Inc.'s job postings
- バックエンド / リーダー候補
- PdM
- Webエンジニア(シニア)
- Other occupations (17)
- Development
- Business

こんにちは!Wantedlyの久保長です。
この記事では、「定着型成長エンジン」を強化するために重要な「MAUと継続率を機能ごとに分解し分析する手法」について説明します。また、紹介する分析手法は非常にたくさんの計算リソースが必要になりますが、BigQueryを使うことで、必要な処理を10s以内に実行することができます。BigQueryはなかなか学習することが難しいと思いますが、StackOverflowの公開データを使って実際に分析し、サンプルクエリも載せました。
エリック・リースは、リーンスタートアップの中で、スタートアップの成長できるエンジンは大きく分けて三つあると話をしています。「定着型成長エンジン」「バイラル型成長エンジン」「課金型成長エンジン」です。
定着型成長エンジンとは、ユーザが定期的にサービスを使い続けてもらうことで成長していくことです。バイラル型成長エンジンとは、SNSなどを通して成長を広めていくことです。課金型成長エンジンとは、ユーザから得られるLTV(ライフタイムバリュー)とCPA(ユーザ獲得)のバランスを改善し、ユーザ獲得にかけるお金を増やすことで成長することです。
スタートアップでは上記の三つそれぞれをうまく使い成長を加速させています。今回、MAUと継続率の分析でフォーカスするのは、「定着型成長エンジン」です。
サービスで行うアクションを全て、MAUと継続率で分解し、評価していくことです。
サービスで行うアクションとは、サイトに訪問・サイト上でアクションを行う、長くコンテンツを見るなど全てです。同じエンドポイントでも、流入や属性などで分解することでより深い知見が得られることもあります。
各機能ごとのMAUと重なり(和集合やベン図)を調べることで、ユーザに使われている機能が何か、機能ごとの利用傾向が分かります。ユーザのエンゲージメントをあげるためには、サービスが提供している様々な機能を使う方が、サービス全体としての価値が高まります。
各機能ごとの継続率を出すことで、使い続けている人が多いかどうかを機能ごとに比較することができます。各機能ごとの満足度と、各機能ごとの継続率は一致していることが多いため、それぞれの機能を改善していく目安になります。また、UIの表示を優先度を変更することで、ユーザの使い方を変えていくこともできます。各機能ごとの継続率を改善することで、結果的に、全体のMAUや継続率を改善していくことにも繋がります。
例えば、Wantedlyでは、フィルターの種類ごとの利用継続率を分析し、良いフィルターと悪いフィルターの判断を行なっています。また、新規でリリースしたサービスの良し悪しに関しても、利用継続率の違いで比較して評価を行なっています。
Wantedly内部のデータはもちろん公開できないため、StackOverflowが公開しているデータを使って行います。
Stack Overflowには、いくつか公開されているデータがありますが、今回は、users, posts_questions(質問), posts_answers(回答), comments(コメント)のデータを使って分析を行います。公開されているデータのみでサービス分析を行うので、「非ログインユーザからログインユーザになる割合」「SEOやSNSからの流入の分析」などサービスを見ていく上で、重要な分析ができていませんが、Q&Aサイトにおける「質問」「回答」「コメント」という重要な三つのユーザの行動について分析が行えました。
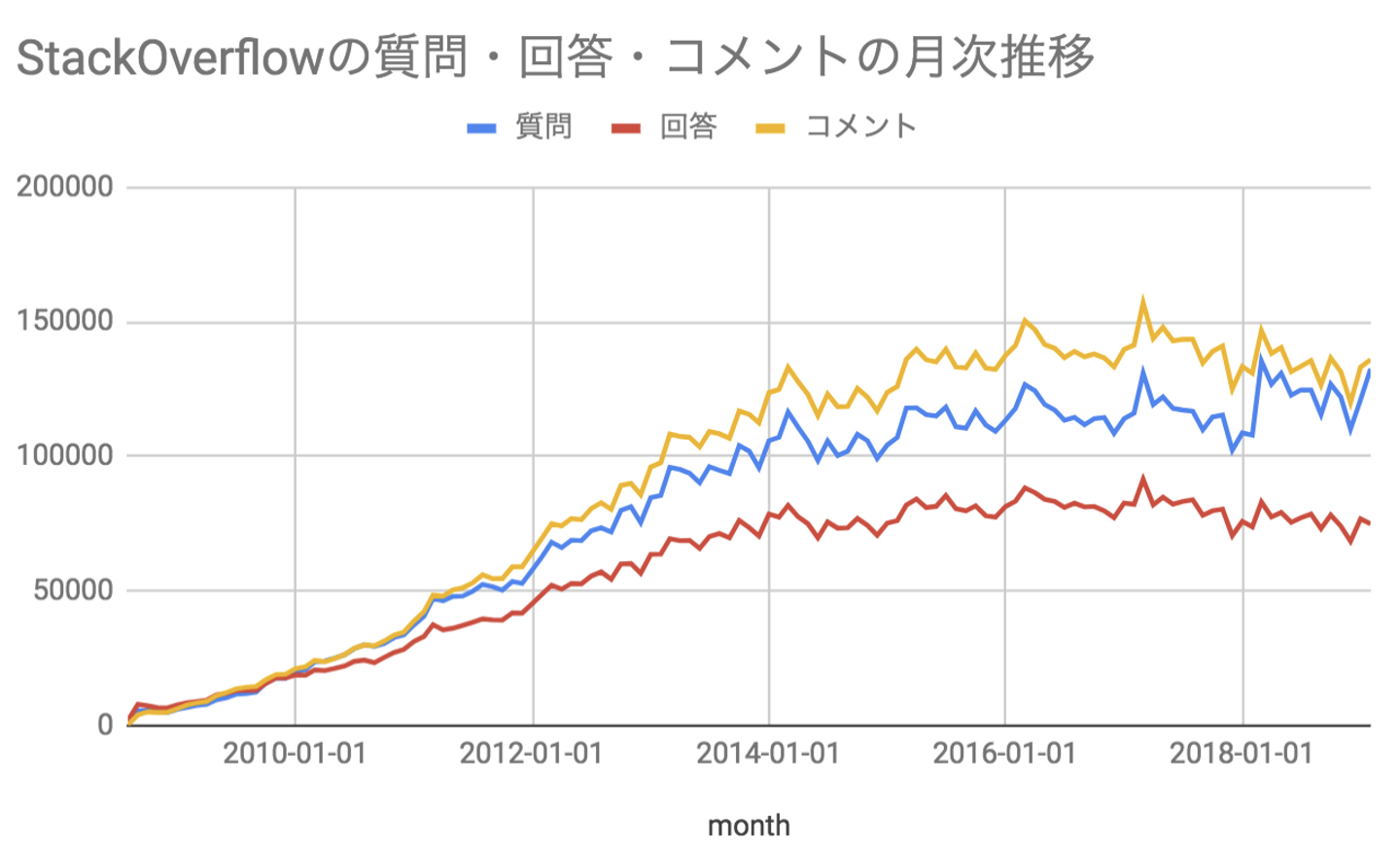
まずは対象となる三つのデータの月次の利用ユーザ数推移を見てみましょう。2008年にサービスがスタートし、順調に質問数・回答数が増えていますが、2015年から成長が止まっており、直近は減少していることが分かります。
どうして成長は鈍化しているのでしょうか?
-- 以下のように with句を使い、それぞれの項目の月ごとのidを計算すると計算しやすくなります。
-- HyperLogLog++の関数を使うことで精度は落ちますが、実行結果を高速化できます。
-- HLL_COUNTのprecisionは、基本的には精度が落ちないように高い値を設定する方が良いと思います。
WITH posts_questions_users AS (SELECT
DATE_TRUNC(Date(creation_date), MONTH) as month,
HLL_COUNT.INIT(owner_user_id, 20) AS user_ids_hll
FROM
`bigquery-public-data.stackoverflow.posts_questions`
GROUP BY
month
)
, posts_answers_users AS (
SELECT
DATE_TRUNC(Date(creation_date), MONTH) as month,
HLL_COUNT.INIT(owner_user_id, 20) AS user_ids_hll
FROM
`bigquery-public-data.stackoverflow.posts_answers`
GROUP BY
month
),
comments_users AS (SELECT
DATE_TRUNC(Date(creation_date), MONTH) as month,
HLL_COUNT.INIT(user_id, 20) AS user_ids_hll
FROM
`bigquery-public-data.stackoverflow.comments`
GROUP BY
month
)
SELECT
posts_questions_users.month AS month,
HLL_COUNT.EXTRACT(posts_questions_users.user_ids_hll) AS posts_questions_users,
HLL_COUNT.EXTRACT(posts_answers_users.user_ids_hll) AS posts_answers_users,
HLL_COUNT.EXTRACT(comments_users.user_ids_hll) AS comments_users
FROM
posts_questions_users
JOIN
posts_answers_users
ON
posts_questions_users.month = posts_answers_users.month
JOIN
comments_users
ON
posts_questions_users.month = comments_users.month
ORDER BY
monthまず、月間のアクセスユーザを計算します。Stack Overflowでは現在、175万のユーザがアクセスしています。その上で、公開データを使って以下の4つのユーザを分けてみます。右に実際に使っているユーザ数と割合を書きました。
アクセスしているユーザのうち、質問をしたり答えているユーザは全体の10%以下だということがわかります。このように機能ごとにMAUを作ることで、それぞれの機能がどのように使われているか正確に把握することができます。
- アクセスしたユーザ(データを同期された時間が分からないため、最新のアクセス日を同期されたとしています。
WITH calculation_term AS (
SELECT
TIMESTAMP_SUB(MAX(last_access_date), INTERVAL 28 DAY) AS beginning_date,
MAX(last_access_date) AS end_date
FROM
`bigquery-public-data.stackoverflow.users`
)
SELECT
COUNT(*)
FROM
`bigquery-public-data.stackoverflow.users`
WHERE
last_access_date >= (SELECT beginning_date FROM calculation_term) AND last_access_date <= (SELECT end_date FROM calculation_term)
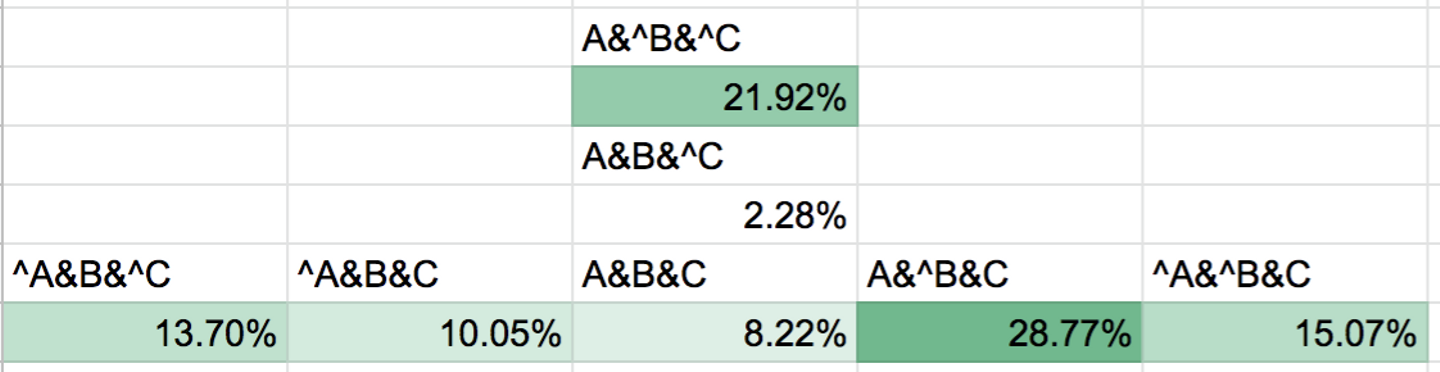
次に、それぞれの集合の数と和集合の数を計算することで、ベン図に関わる数字を全て把握することができます。以下のように図にしたり、数値として割合を計算します。
グラフ化することで、質問を行うユーザは回答を行うユーザより多いことや、質問したユーザはあまり回答をしていないこと、質問や回答を行うユーザはよくコメントをしていることが分かります。具体的な数字だと、回答をしているユーザのうち53%のユーザがコメントを返しており、質問したユーザのうちコメントをしたユーザが60%いることが分かりました。また、質問をしているユーザの17%のユーザが回答を行なっていないことが分かります。
回答や質問したユーザがコメントするということは、自分が作った質問や回答に対してコメントを返すことが多いために高いと想定通りの結果になりましたが、質問をしているユーザの17%のユーザしか回答をしていないことは想定外のことでした。
WITH calculation_term AS (
SELECT
TIMESTAMP_SUB(MAX(last_access_date), INTERVAL 28 DAY) AS beginning_date,
MAX(last_access_date) AS end_date
FROM
`bigquery-public-data.stackoverflow.users`
),
posts_questions_users AS (
SELECT
HLL_COUNT.INIT(owner_user_id, 20) AS user_ids_hll
FROM
`bigquery-public-data.stackoverflow.posts_questions`
WHERE
creation_date >= (SELECT beginning_date FROM calculation_term) AND creation_date <= (SELECT end_date FROM calculation_term)
),
posts_answers_users AS (
SELECT
HLL_COUNT.INIT(owner_user_id, 20) AS user_ids_hll
FROM
`bigquery-public-data.stackoverflow.posts_answers`
WHERE
creation_date >= (SELECT beginning_date FROM calculation_term) AND creation_date <= (SELECT end_date FROM calculation_term)
),
comments_users AS (
SELECT
HLL_COUNT.INIT(user_id, 20) AS user_ids_hll
FROM
`bigquery-public-data.stackoverflow.comments`
WHERE
creation_date >= (SELECT beginning_date FROM calculation_term) AND creation_date <= (SELECT end_date FROM calculation_term)
)
SELECT
a,
b,
c,
a + b - a_b AS a_b,
a + c - a_c AS a_c,
b + c - b_c AS b_c,
(a + b + c - a_b - a_c - b_c + a_b_c) AS a_b_c
FROM
(
SELECT
HLL_COUNT.EXTRACT(posts_questions_users.user_ids_hll) AS a,
HLL_COUNT.EXTRACT(posts_answers_users.user_ids_hll) AS b,
HLL_COUNT.EXTRACT(comments_users.user_ids_hll) AS c,
(SELECT HLL_COUNT.MERGE(user_ids_hll) FROM UNNEST([posts_questions_users.user_ids_hll, posts_answers_users.user_ids_hll]) AS user_ids_hll) AS a_b,
(SELECT HLL_COUNT.MERGE(user_ids_hll) FROM UNNEST([posts_questions_users.user_ids_hll, comments_users.user_ids_hll]) AS user_ids_hll) AS a_c,
(SELECT HLL_COUNT.MERGE(user_ids_hll) FROM UNNEST([posts_answers_users.user_ids_hll, comments_users.user_ids_hll]) AS user_ids_hll) AS b_c,
(SELECT HLL_COUNT.MERGE(user_ids_hll) FROM UNNEST([posts_questions_users.user_ids_hll, posts_answers_users.user_ids_hll, comments_users.user_ids_hll]) AS user_ids_hll) AS a_b_c
FROM
posts_questions_users
CROSS JOIN
posts_answers_users
CROSS JOIN
comments_users
)
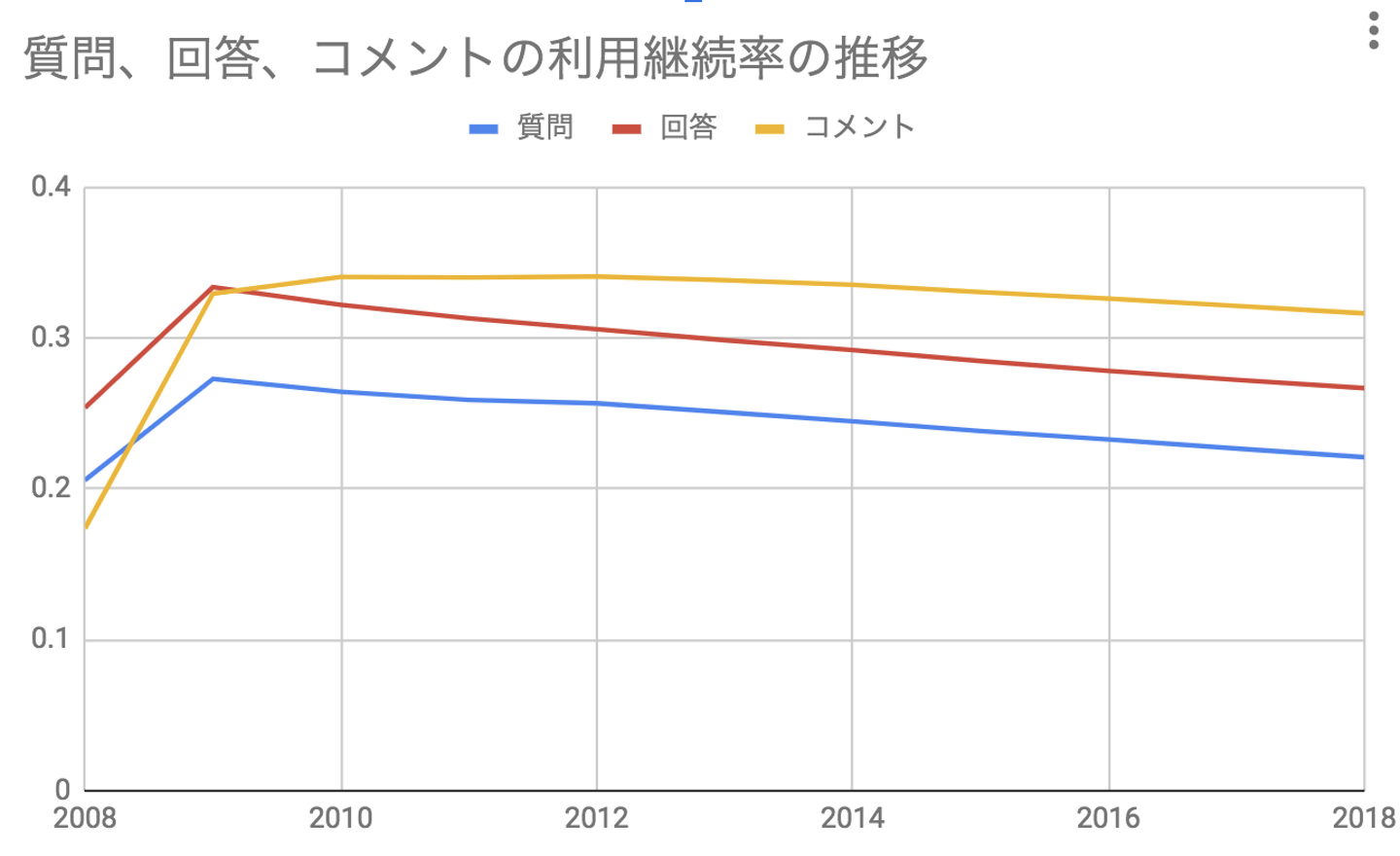
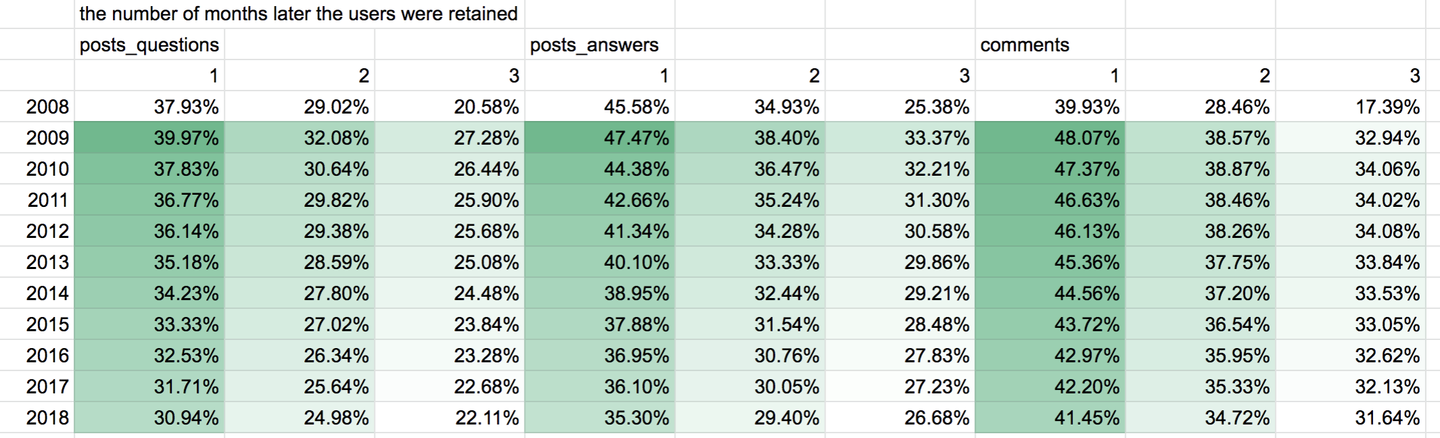
継続率は、コメント、回答、質問の順であることが分かりました。具体的には、1ヶ月の継続率は質問が31%回答が36%コメントが42%、3ヶ月の継続率は質問が22%回答が27%コメントが32%ということになります。
(実際には、毎月同じような継続率ではないですが、ある程度目安になる数字になります)
月ごとの機能ごとの継続率を比較してみると、継続率の変化を確認できます。2009年をピークに継続率は、特に質問と回答を行う人が減少していることが分かります。現在でも継続率は毎年2%ほど減少しています。この継続率の減少がstackoverflowの投稿数が伸びてない原因になっていることが分かります。
WITH posts_questions_users AS (
SELECT
DATE_TRUNC(Date(creation_date), MONTH) as month,
HLL_COUNT.INIT(owner_user_id, 20) AS user_ids_hll
FROM
`bigquery-public-data.stackoverflow.posts_questions`
GROUP BY
month
)
, posts_answers_users AS (
SELECT
DATE_TRUNC(Date(creation_date), MONTH) as month,
HLL_COUNT.INIT(owner_user_id, 20) AS user_ids_hll
FROM
`bigquery-public-data.stackoverflow.posts_answers`
GROUP BY
month
),
comments_users AS (
SELECT
DATE_TRUNC(Date(creation_date), MONTH) as month,
HLL_COUNT.INIT(user_id, 20) AS user_ids_hll
FROM
`bigquery-public-data.stackoverflow.comments`
GROUP BY
month
)
SELECT
month,
month_diff,
ANY_VALUE(t1_cnt) + ANY_VALUE(t2_cnt) - HLL_COUNT.MERGE(user_ids_hll) AS cnt
FROM
(
SELECT
t1.month AS month,
DATE_DIFF(t1.month, t2.month, MONTH) AS month_diff,
HLL_COUNT.EXTRACT(t1.user_ids_hll) AS t1_cnt,
HLL_COUNT.EXTRACT(t2.user_ids_hll) AS t2_cnt,
[t1.user_ids_hll, t2.user_ids_hll] AS user_ids_hlls
FROM
-- posts_questionsでなく他のデータを分析する場合は以下の二点(t1とt2のテーブル名)を変更します。
posts_questions_users t1
-- posts_answers_users t1
-- posts_comments_users t1
JOIN
posts_questions_users t2
-- posts_answers_users t2
-- posts_comments_users t2
ON
DATE_DIFF(t1.month, t2.month, MONTH) IN (0, 1, 2, 3, 4, 5, 6)
),
UNNEST(user_ids_hlls) AS user_ids_hll
GROUP BY
month, month_diff
ORDER BY
month, month_diff日々のユーザの動きを見る場合は、MAUよりもDAUを見る方が分かりやすくなります。ウォンテッドリーでは、DAUを分解してリテンションを見るようにしています。
具体的に、どのように分解するかというと、以下のように分けていきます。
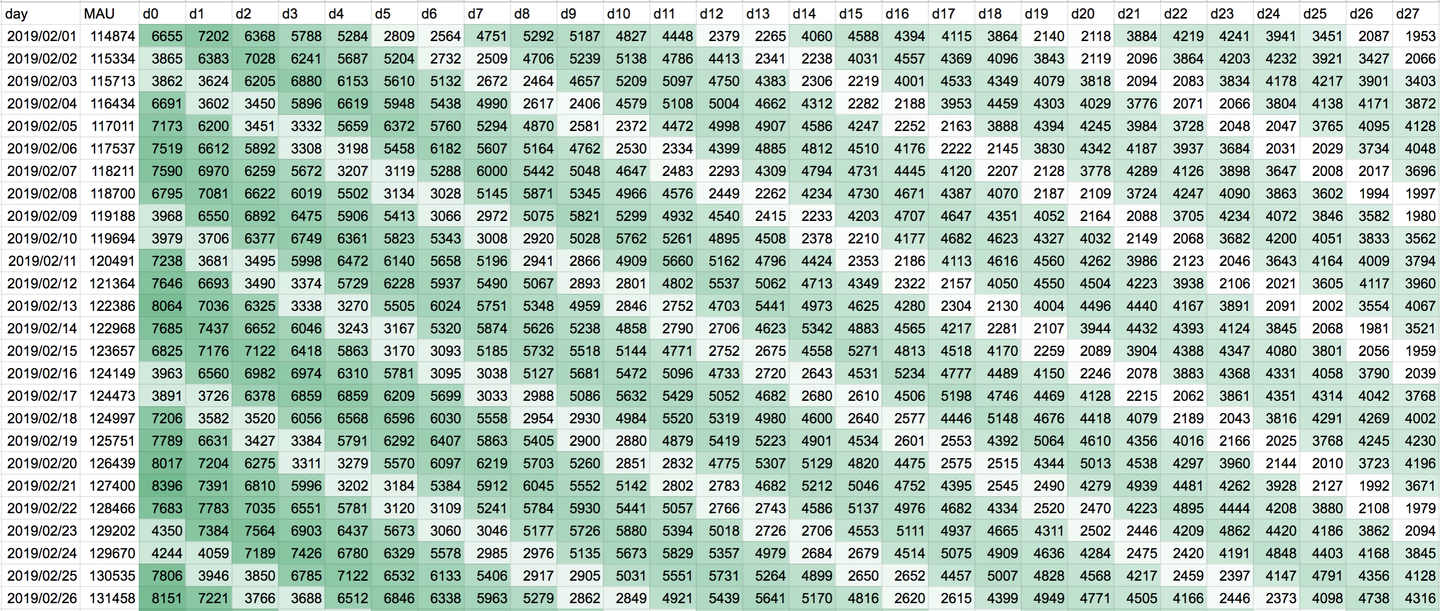
MAU = 0日目にアクセスしたユーザ(DAU) + 1日前にアクセスして0日目にアクセスしてないユーザ + 2日前にアクセスして0日から1日前にアクセスしてないユーザ + .. + 27日前にアクセスして0日から26日前にアクセスしてないユーザ
表として出力すると以下のようになります。DAUが日にちごとにどのように変わっているのか、27日目にMAUになってから抜けるユーザが何人かなどが分かります。またデータに周期性があり、土日に利用するユーザが少ないことや、DAUの変動が少ないことが分かります。
この表の良いところは、キャンペーンやプレスリリースなどを行なった後、登録ユーザが一気に増えた場合に、そのキャンペーンのユーザがどのくらい継続したかが一目で見えることです。
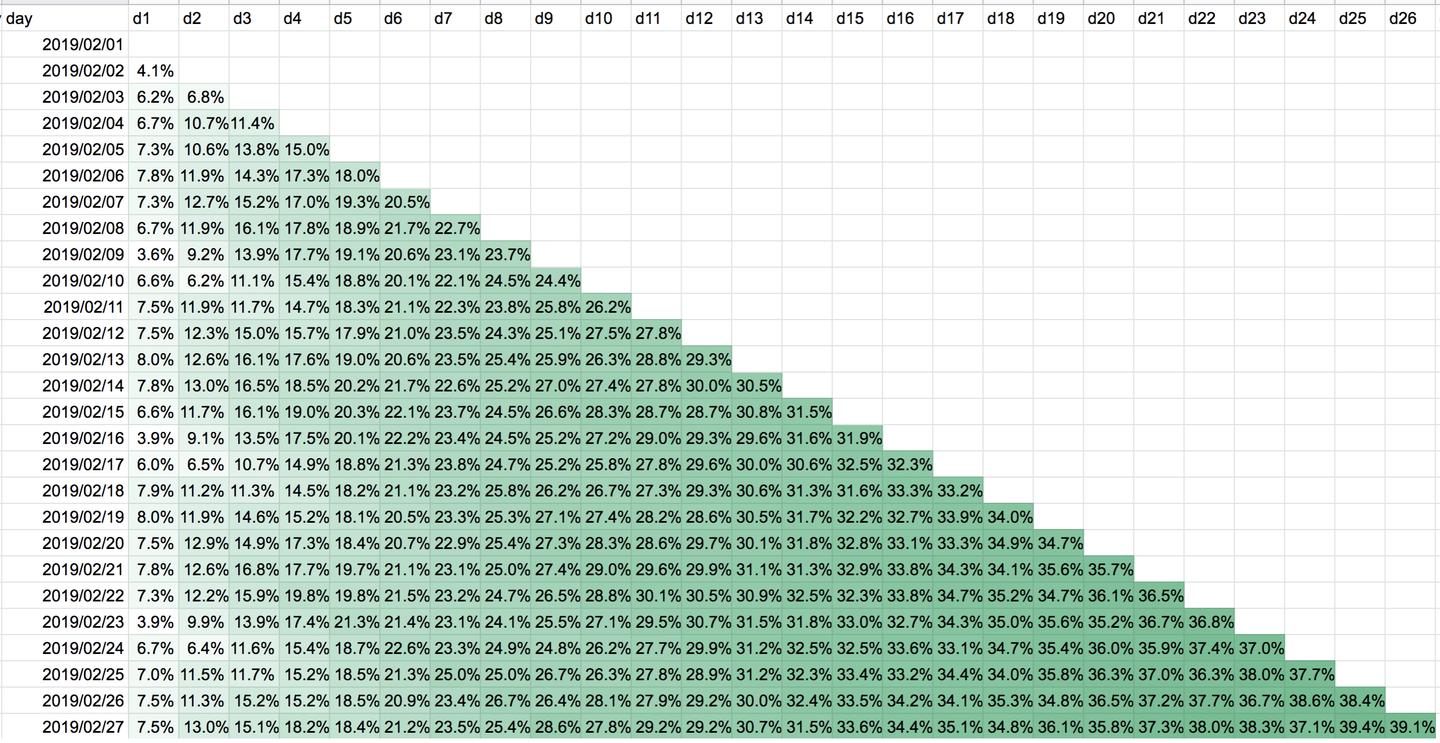
こちらは出力したデータから生成しましたが、コホートも上のデータから簡単に出力することができます。以下のデータからは、金曜日にアクセスしたユーザは土曜日にアクセスしないこと、週のリテンションだと23%でほとんど日によって変化がないこと、月のリテンションだと40%くらいになることが分かります。つまり毎週質問している人がある日に質問している人の20%、毎月質問している人がある日に質問している人の40%になります。
WITH posts_questions_users AS (
SELECT
Date(creation_date) as day,
HLL_COUNT.INIT(owner_user_id, 20) AS user_ids_hll
FROM
`bigquery-public-data.stackoverflow.posts_questions`
WHERE
DATE(creation_date) >= DATE_SUB(DATE("2019-02-01"), INTERVAL 28 DAY) AND DATE(creation_date) < DATE_ADD(DATE("2019-2-01"), INTERVAL 28 DAY)
GROUP BY
day
)
SELECT
day,
SUM(CASE WHEN diff = 0 THEN cnt ELSE 0 END) AS d0,
SUM(CASE WHEN diff = 1 THEN cnt ELSE 0 END) AS d1,
SUM(CASE WHEN diff = 2 THEN cnt ELSE 0 END) AS d2,
SUM(CASE WHEN diff = 3 THEN cnt ELSE 0 END) AS d3,
SUM(CASE WHEN diff = 4 THEN cnt ELSE 0 END) AS d4,
SUM(CASE WHEN diff = 5 THEN cnt ELSE 0 END) AS d5,
SUM(CASE WHEN diff = 6 THEN cnt ELSE 0 END) AS d6,
SUM(CASE WHEN diff = 7 THEN cnt ELSE 0 END) AS d7,
SUM(CASE WHEN diff = 8 THEN cnt ELSE 0 END) AS d8,
SUM(CASE WHEN diff = 9 THEN cnt ELSE 0 END) AS d9,
SUM(CASE WHEN diff = 10 THEN cnt ELSE 0 END) AS d10,
SUM(CASE WHEN diff = 11 THEN cnt ELSE 0 END) AS d11,
SUM(CASE WHEN diff = 12 THEN cnt ELSE 0 END) AS d12,
SUM(CASE WHEN diff = 13 THEN cnt ELSE 0 END) AS d13,
SUM(CASE WHEN diff = 14 THEN cnt ELSE 0 END) AS d14,
SUM(CASE WHEN diff = 15 THEN cnt ELSE 0 END) AS d15,
SUM(CASE WHEN diff = 16 THEN cnt ELSE 0 END) AS d16,
SUM(CASE WHEN diff = 17 THEN cnt ELSE 0 END) AS d17,
SUM(CASE WHEN diff = 18 THEN cnt ELSE 0 END) AS d18,
SUM(CASE WHEN diff = 19 THEN cnt ELSE 0 END) AS d19,
SUM(CASE WHEN diff = 20 THEN cnt ELSE 0 END) AS d20,
SUM(CASE WHEN diff = 21 THEN cnt ELSE 0 END) AS d21,
SUM(CASE WHEN diff = 22 THEN cnt ELSE 0 END) AS d22,
SUM(CASE WHEN diff = 23 THEN cnt ELSE 0 END) AS d23,
SUM(CASE WHEN diff = 24 THEN cnt ELSE 0 END) AS d24,
SUM(CASE WHEN diff = 25 THEN cnt ELSE 0 END) AS d25,
SUM(CASE WHEN diff = 26 THEN cnt ELSE 0 END) AS d26,
SUM(CASE WHEN diff = 27 THEN cnt ELSE 0 END) AS d27
FROM
(
SELECT
day,
min_day,
n2 AS diff,
CASE WHEN n2 = 0 THEN union_cnt ELSE union_cnt - LEAD(union_cnt) OVER(PARTITION BY day ORDER BY min_day) END AS cnt
FROM
(
SELECT
MAX(t1.day) AS max_day,
MIN(t1.day) AS min_day,
DATE_ADD(t1.day, INTERVAL n1 DAY) AS day,
n2,
HLL_COUNT.MERGE(t1.user_ids_hll) AS union_cnt,
COUNT(*) AS cnt
FROM
posts_questions_users t1,
UNNEST(GENERATE_ARRAY(0, 27)) AS n1,
UNNEST(GENERATE_ARRAY(0, 27)) AS n2
WHERE
n1 <= n2
GROUP BY
day,n2
HAVING
day >= DATE('2019-02-01') AND day < DATE_ADD(DATE("2019-2-01"), INTERVAL 28 DAY)
ORDER BY
day,n2
)
ORDER BY
day, min_day DESC
)
GROUP BY
day
ORDER BY
day今回データをみて気づいたことは、以下の三点です。
1つ目は、ライトユーザとロイヤルユーザの割合と捉えられ、実はこの数字だけだと、結論は分かりませんが、もし年々この割合が増加していないのであればもっとロイヤルユーザを増やす必要があります。
2つ目は、今回のベン図を通して発見しました。質問だけ行う、質問に対するコメントだけを行なっているユーザが多く、回答を行なっていません。質問したユーザに回答をする施策は進めた方が良いかもしれません。
3つ目は、今回の最大の目的である各機能の継続率についてです。機能別に見ると特に質問の継続率が低くなっていました。また2009年をピークに年々低下傾向は続いており、この継続率の低下が、「月次の質問や回答やコメントの数の推移の低下」に結びついていることは間違いありません。
HyperLogLogとはCount-Disctinctを高速に計算するアルゴリズムで、Bigqeuryでも利用できます。HyperLogLog++とは、Googleが最適化を行なったHyperLogLogのアルゴリズムの一つです。
今回のSQLの事例のようにHyperLogLog++を使って集計を行うと、以下のように厳密に計算するよりも6倍以上速くなります。実際、今回の分析の場合、月次の継続率の厳密計算は、63.4s実行時間にかかりますが、HyperLogLog++のアルゴリズムを使うと、実行時間が9.2sとなり、6倍以上速くなります。今回、HyperLogLog++の精度を15の時と20の時で比較しましたが、実行時間は変わらず、精度は大きく変わる(precisionが15の時、2.08%の誤差、20の時の誤差は0.04%)ので、データの大きさに合わせて、誤差が0.1%以下になるように調整すると良いです。また、実際に継続しているuserのidが必要な場合は、以下のようなメソッドを利用して厳密に計算を行う必要があります。
CREATE TEMPORARY FUNCTION array_inter(a ARRAY<INT64>, b ARRAY<INT64>)
RETURNS ARRAY<INT64>
LANGUAGE js AS """
a_hash = {}
for (a_i in a) {
a_hash[a[a_i]] = 1
}
outputs = []
for (b_i in b) {
if(a_hash[b[b_i]]){
outputs.push(b[b_i])
}
}
return outputs;
""";
WITH posts_questions_users AS (
SELECT
DATE_TRUNC(Date(creation_date), MONTH) as month,
ARRAY_AGG(DISTINCT owner_user_id) AS user_ids
FROM
`bigquery-public-data.stackoverflow.posts_questions`
GROUP BY
month
)
, posts_answers_users AS (
SELECT
DATE_TRUNC(Date(creation_date), MONTH) as month,
ARRAY_AGG(DISTINCT owner_user_id) AS user_ids
FROM
`bigquery-public-data.stackoverflow.posts_answers`
GROUP BY
month
),
comments_users AS (
SELECT
DATE_TRUNC(Date(creation_date), MONTH) as month,
ARRAY_AGG(DISTINCT user_id) AS user_ids
FROM
`bigquery-public-data.stackoverflow.comments`
GROUP BY
month
)
SELECT
t1.month AS month,
DATE_DIFF(t1.month, t2.month, MONTH) AS month_diff,
ARRAY_LENGTH(array_inter(t1.user_ids, t2.user_ids)) AS cnt
FROM
-- posts_questionsでなく他のデータを分析する場合は以下の二点(t1とt2のテーブル名)を変更します。
posts_questions_users t1
-- posts_answers_users t1
-- posts_comments_users t1
JOIN
posts_questions_users t2
-- posts_answers_users t2
-- posts_comments_users t2
ON
DATE_DIFF(t1.month, t2.month, MONTH) IN (0, 1, 2, 3, 4, 5, 6)
ORDER BY
month, month_diffサービスを改善していく上で、ユーザのエンゲージメントを高める上で非常に重要です。各機能ごとのMAU・継続率を分析し、サービスを改善していくことは非常に強力な分析になります。
分析ツールを利用すると、コホート分析(継続率の分析)は行うことはできますが、イベント実施前にうまく設定しないと分析できないなど自由度が少ないことも多くなります。今回、紹介した分析だと、ログデータでもdbにあるデータでもBigQueryに同期すれば、自由度高く分析することが可能になります。
ぜひ実践してみてください!
Wantedlyの分析の仕組みについてもっと知りたい、知見を交換したいという人がいましたら、こちらから気軽に話を聞きに来てください!
・HyperLogLog++について https://cloud.google.com/bigquery/docs/reference/standard-sql/hll_functions
・今回利用したspreadsheet https://docs.google.com/spreadsheets/d/1ymTHutSaGIp1SrUmpTRT0IG0Yi74MJ9Wh5DBik_RVUA/
・ベン図の生成ツール https://www.meta-chart.com/venn
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()



/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)