/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

Wantedly, Inc.'s job postings
- バックエンド / リーダー候補
- PdM
- Webエンジニア(シニア)
- Other occupations (17)
- Development
- Business
こんにちは、ウォンテッドリーの合田(@hakubishin3)です。私は推薦チームに所属していて、機械学習領域のテックリード兼プロダクトマネージャーとして会社訪問アプリ「Wantedly Visit」の推薦システムの開発・運用を携わっています。この記事では、ウォンテッドリーの推薦チームが実践している推薦システムの開発プロセスについて紹介します。
まず初めにお伝えすると、私たちの開発は広く実践されているプロダクト開発やデータ分析プロジェクトの流れと基本的に同じです。しかしながら、同じような流れでもその工程の中には、継続的な推薦システムの開発を通じて重視するようになった観点や改善を積み重ねてきた取り組み方が各所にあります。推薦システムを開発している人だけでなく、推薦以外の切り口でプロダクトやクライアントの課題解決に取り組まれている人にとっても、何かしらの参考になるかもしれません。是非ご一読いただければ幸いです。
本題に入る前に、この記事における「推薦システム開発」という言葉のスコープを定義します。
『推薦システム実践入門』(オライリージャパン、2022年)において、推薦システムは「複数の候補から価値のあるものを選び出し、意思決定を支援するシステム」と定義されています。推薦システムは、アイテムの価値の推定と選定(推薦アルゴリズム)の機能だけではありません。ユーザーにとって価値のあるアイテムを、どのような場所・タイミングで(推薦の枠)、どのような形式で提示するのか(推薦結果の見せ方)まで含めて、意思決定のサポートのためのシステムとして成り立ちます。
そのため以降では、アルゴリズム開発に閉じず、UI/UX改善など広いアプローチを想定した推薦システム開発について紹介していきます。
私たちがプロダクト開発において最も避けたいと思っていることは「使われない機能を作り込む」ことです。開発リソースの浪費やユーザー体験の低下、複雑性・メンテナンスコストの増加など、長期的に見てユーザーに提供できるであろう価値の総量を大きく減らしてしまうからです。
「機能が使われない」とは、ユーザーが抱えている真の課題に対して適切でない解決策をユーザーに提示していることだと言えます。つまり、以下のような状態で突き進んでしまうと、このようなことが起きてしまいます。
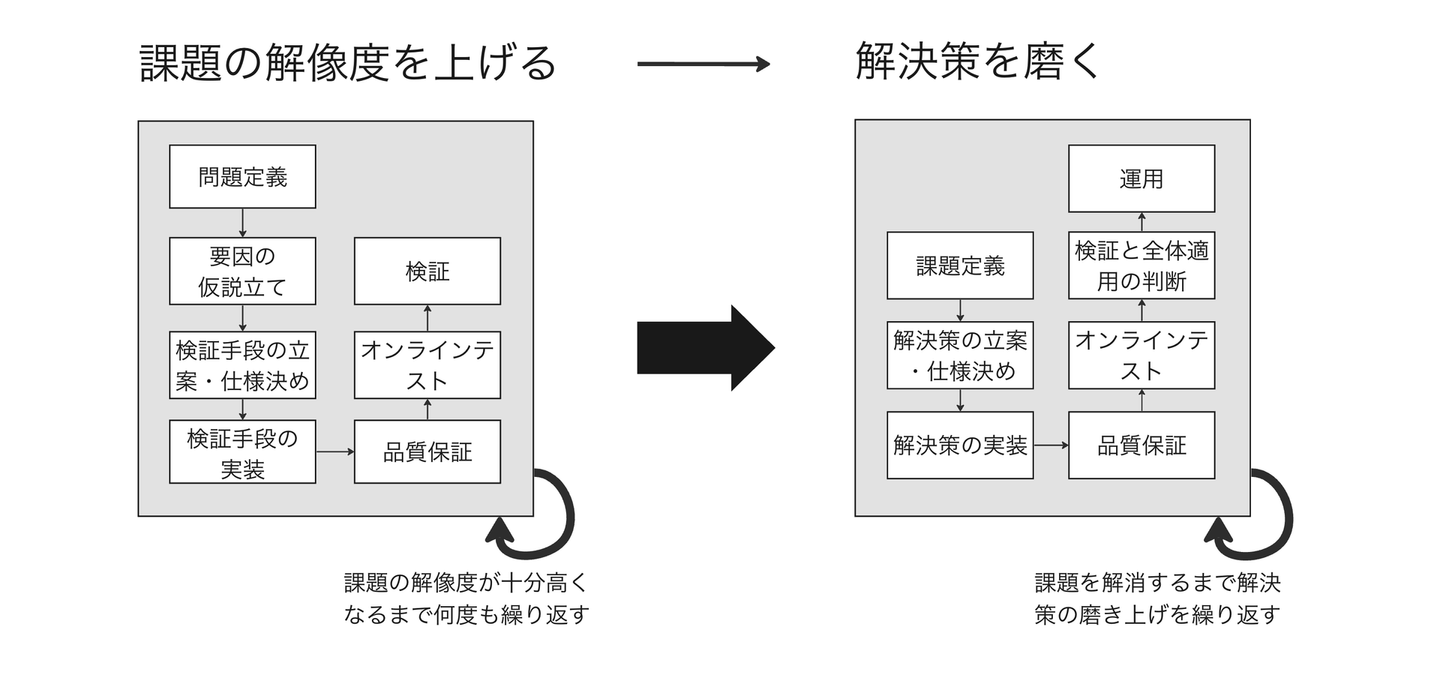
上記の課題感を踏まえると、ユーザーに価値を提供できる機能を作るために必要な開発の手順は「課題の解像度を上げる→解決策を磨く」になるでしょう。この手順に基づくと以下の流れが理想的だと考えます。課題の解像度を上げるフェイズと課題に対する解決策を磨くフェイズの2つで構成されており、それぞれのフェイズにおいてイタレーションを回すのが特徴です。このように課題の理解と解決策の磨き上げを小さく素早く進めていくことが、「使われない機能を作り込む」ことを避けるための基本形になります。
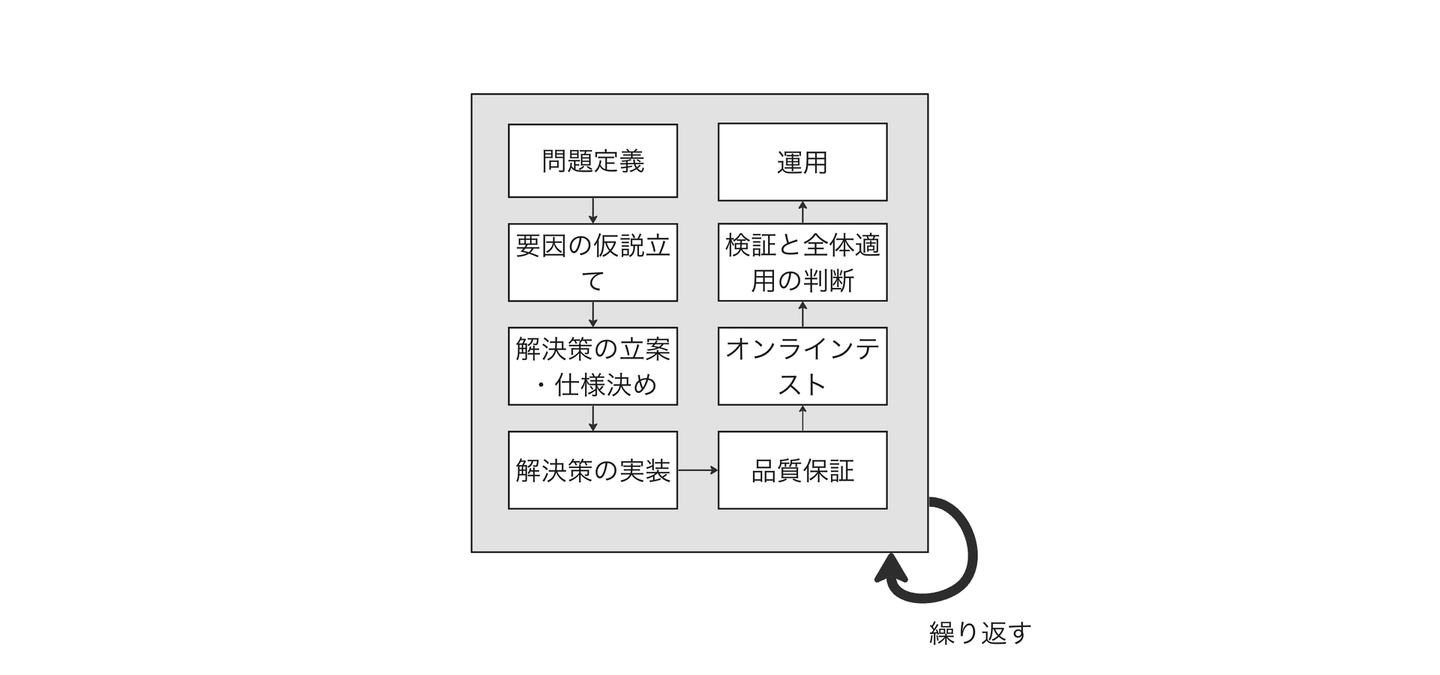
しかし、課題の理解だけに注力していると、いつまで経ってもユーザーの課題を解決できない状態になってしまう懸念があります。このようなことを防ぐために、ユーザーの体験改善を各イタレーションで狙いつつ、ユーザーの反応を見ながら「課題が存在するか」と「解決策が適切か」の両方を検証する、以下の形式を取ったりします。
ユーザーへの価値の提供の速度感と不確実性の大きさを鑑みてどっちを取るかを判断します。例えば、定量分析や定性分析によって課題の解像度を上げられる、もしくは解決策に対するユーザーの反応を見て課題が存在するかどうかをまとめて検証できるのであれば、パターンBの形式を採用します。そうでないならば、まずは課題の検証に専念するパターンAの形式を採用します。
以降では、パターンBの形式をもとにして、各工程での具体的な取り組み方について詳しく紹介します。
まずは「問題は何か」および「問題が発生している場所はどこか」を定義します。問題とは、目標にしているものと現状とのギャップです。ギャップの大きい箇所を見つけ、そのギャップを小さくしていくことがプロジェクトの目的となります。
ギャップを見つける方法としては、一般的には KPI ツリーを基に分析・集計を行ってボトルネックを特定します。さらに、セグメント分析やファネル分析を用いて詳細に分解していき、どこに問題があるのかを明らかにしていきます。
問題を見つけた!となっても、すぐには次のステップに進めないです。困ったことに、問題は至る所にあり、切り出し方は多様です。大きな粒度で問題を定義してしまうと解くべき課題が曖昧になりやすく、逆に問題を小さい粒度で考えてしまうと解決策のインパクトが小さくなってしまいます。そのため、適切な粒度に問題を落とし込んでおく必要があります。
どのような粒度で問題を切り出せばいいのか、に対する明確な答えはわかりません。開発チームに多くの知見が溜まっている場合はこれまでの経験則に基づいて決めるでしょうし、そうでないならば、このステップと次のステップ(要因の仮説立て)を何度も往復して最終的に注力するべき課題を決定することになるでしょう。
次に、問題がなぜ起こるのかを考えます。例えば、ユーザーが商品一覧にあるアイテムをクリックしない理由として「ユーザーの興味と合致しない」や「UIが理解しにくい」、「レスポンス速度が長い」といった多岐にわたる要因が挙げられます。問題の要因が分からなければ、効果的な解決策は出てきません。逆に、要因の解像度が高いほど、解決策もフォーカスした問題に対して的確に刺さるシャープなものとなり、結果的に小さいコストで大きな改善が期待できます。
要因の仮説を見つけるには、以下のような定量的もしくは定性的なアプローチを用います。
気をつけるべき点として、ユーザーやクライアントからの不満の声が必ずしも真の要因(本質的ニーズ)とは限らないことが挙げられます。定性的な情報の裏に隠れている真の要因とは何かを常に意識しつつ、仮説を考えていくことが求められます。同様に、定量的な結果だけに依存して物事を解釈すると、真の要因を見逃すリスクがあります。表層的なものに惑わされないよう、単一のアプローチに頼るのではなく、定量と定性のそれぞれのアプローチを組み合わせて、仮説の確度を高めることが効果的です。
いくつかの仮説を作ることができたら、どの仮説に対して解決策を検証していくかの優先度を決める必要があります。仮説の確度、解決した場合のインパクトの大きさ、かかるコストといった観点を元に最終的な優先順位を決定します。
仮説の確度が低ければ、その要因の仮説に対する検証(その問題はその要因によって生じているのか?という問いに答えるための検証)を行って、要因の追求にフォーカスする必要があります。つまり、パターンAの方の開発プロセスを取り直す必要があります。
このステップでは、課題を解消するためのアプローチを考えて解決の方向性を定めます。ここでは、推薦システムに関する主な解決策を以下の4つのカテゴリーに分けて説明します。
1. 新しい推薦の導入
サービス内外で新たな推薦枠を設け、ユーザーがコンテンツをより多く探索・発見できるようにします。
具体的には、商品の詳細ページで「こんな商品もおすすめかも」と関連アイテムの推薦を表示するセクションを作ったり、カルーセル形式のページを追加したり、新しいメールやプッシュ通知を配信する、などがあります。
2. 推薦アルゴリズムの改善
新しい機械学習技術やルールベースアプローチの導入や、特徴量の更新・追加といった、既存の推薦精度を向上させる取り組みになります。最適な手法が試行錯誤を通して見えてくることもあるので、細かいところまで決めきらず、柔軟に進めていくのが望ましいです。
しかし、ユーザーやアイテムに関する新しいデータの取得を検討する場合は、データの形式や取得方法、保持方法など、詳細な仕様決めが必要になります。
3. 推薦システムのUI/UX改善
主にUIの変更を通じてユーザビリティの向上を図るものです。具体的には、アイテムのおすすめ理由を表示したり、表示されたアイテムがユーザーの好みと合致する根拠を強調したりするなどの改善が考えられます。具体的なUIの変更だけでなく、メールや通知といった推薦結果の配信タイミングの調整などもこのカテゴリに含めます。
上記の「新しい推薦の導入」カテゴリーでも同様の話になりますが、UI改善の場合は、ユーザーの体験がどのように変化するべきなのか、そのためにどのデザインが最適化なのか、を明確にするためのプロトタイプ作成が必要です。
4. レスポンス速度・パフォーマンスの向上
推薦システムに限らず、レスポンス速度はユーザー体験に直結します。また、データの更新頻度やモデルの更新頻度を早くすることで、推薦の質を高める取り組みも重要です。
どの手段を取るにしろ、評価方法とリリース基準を早期に設定しておくことが望ましいです。解決策の実装中どこまでやればいいのか分からないことで必要過多な機能を作ってしまい、ユーザーへの価値の提供が遅くなってしまうこと、そして検証結果がボヤける問題を防ぐためです。このような認識のズレを抑えることで以降のステップが進めやすくなるので、分かる範囲でいいからプロジェクト関係者内でリリース基準を早めにすり合わせておくことを意識しています。
最後に、解決策が目的に合致しているか、また大きなリスクがないかを、改めて振り返って確認します。以下は開発チームで使っている確認用のチェックリストになります。
ここから実装のステップとなります。例えば UI/UXの改善の場合、仕様が明確に定まってからフロントエンドやバックエンドの開発を進めるのが一般的ですが、推薦アルゴリズムの場合は、どうすれば改善するかは必ずしも明確でないことが多いです。仮説に基づいてモデルに意図した変化を反映させるには、Kaggleのような機械学習モデリングの技術が求められる部分と言えます。例えば、以下のような点を検討する必要があったりします(わかり易い例を挙げているだけで、実際はもっとあると思います)
オフライン評価とオンラインテストの結果が相関していてオフライン評価の信頼性が高い場合、実装とオフライン評価を繰り返すことで、ソリューションの品質を向上させることが可能です。これは、推薦アルゴリズム特有のものであり、一般的なUI/UX改善とは異なるポイントとなります。そのために重要となるのが、オフライン評価の適切な設計です。これについては次のステップで紹介します。
品質保証は、開発プロセスにおいて欠かすことのできないステップです。どのような解決策であっても、新しく実装した機能やアルゴリズムを即座にリリースすることは高いリスクが伴います。ユーザ体験を毀損する可能性があるだけでなく、意図しない挙動によって検証を適切に行えない懸念があります。これを防ぐため、リリース前にテストを実施し、リリースに当たって最低限必要な品質(ユーザー体験を大きく損なわない品質、検証したいものを正しく検証できるような品質)を持っているかを保証する必要があります。
UI改善ではなく推薦アルゴリズムを改善する場合、明確なテストケースを用意することが非常に難しいです。どのアイテムがランキングのどの位置にあるべきか、といった理想の形は、ユーザーや状況、また時間によって異なってくるからです。これに対応するためには、いくつかのアプローチが必要になります。
評価するべき指標に応じてアプローチを使い分ければいいのですが、どの手段を取るにしろ、信頼性の高い評価方法を設計するためには気をつけるべきことが多いです。
実際のプロダクトにおける状態をどれだけ正確に再現できるか、は1つの大事な観点です。例えば、ユーザーテストや定性評価であればアイテムのリストをスプレッドシートで並べるのではなくモックを作ったり、機械学習モデルの出力以降においてランキングに対して適用されるロジックなどを再現して、現実に近い形でシミュレーションを構築する必要があります。
また、評価指標は問題定義から丁寧に落とし込んでいく必要があります。これも本当に解きたい問題に出来るだけ近い形で評価できるよう、妥当性のある前提に基づいて適切な近似をしていく必要があります。
最後に、評価を定量的に行い再現性を高めることが重要です。イタレーションを迅速に進めるため、再現性が必要であり、定性評価においても文字通り定性で評価せず、誰が評価しても出来るだけ同じような結果になるよう明瞭なルールを設定して定量的に評価するべきです。
実装された解決策が問題ない品質だと判断できたら、オンラインテストで見るためのメトリクスや全体適用の基準を設定します。そして、ユーザーに対して解決策を実際にリリースし、本番環境で得られたデータを用いて効果を検証します。
オンラインテストの方法としては、私たちのチームでは主に A/B テストと Interleaving を採用しています。これらの方法はそれぞれ異なるメリット・デメリットを持ち、施策の内容や状況に応じて使い分けています。
オンラインテストの基本や実践については、多くの書籍や文献で詳述されています。個人的には、『A/Bテスト実践ガイド』(ドワンゴ、2021年)や『効果検証入門』(技術評論社、2020年)がおすすめです。
オンラインテストで得られたデータをもとに、問題が解消されたかどうかを評価します。具体的には、指定したメトリクスがベースラインと比較して基準以上に改善しているかを定量的に確認します。
しかし、単に数値が改善されているだけでは十分ではありません。KPIの改善はあくまで結果指標に過ぎないからです。解決するべきと定めたユーザーの課題が本当に改善されているのか、それとも予期しないことが起きているのかを明確にします。ファネル分析やセグメント分析を用いてユーザー行動を定量的に深ぼっていったり、具体的なユーザーサンプルをもとにその行動の変化を定性的に観察する必要があります。
また、全体の数値だけでなく、一部のセグメントで大きな悪化がないかを確認します。もしどこかのセグメントで変化が確認された場合、その変化が偶然によるものかどうかを定量的・定性的に検討します。
これらの検証作業を通じて、期待される効果が得られると判断できれば、全体適用を行い、すべてのユーザーに新しい変更を提供します。
推薦チームでは、全体適用後にも、期待される効果が得られているかを再確認し全体適用の継続判断を行うようにしています。
どんなオンラインテストの形式を採用しても、SUTVAを満たさないことでオンラインテスト時には問題が見られなくても全体適用後に問題が発生するリスクがあったり、介入効果の長期的な影響が存在することで「オンラインテストの結果が Fix 後も継続する」という仮定の妥当性が低いと考えているためです。
そのため、全体適用後もオンラインテスト時と同じパフォーマンスを維持しているかを、メトリクスやユーザー行動を通じて定量的・定性的に確認し、その上で継続の意思決定を行います。この意思決定が完了してようやくプロジェクトは終了となります。
プロジェクトの終了後も、継続的なモニタリングが必要です。推薦システムは、オンラインテスト時の性能を保ちつつ安定的かつ意図通りに動作することで、ユーザに価値を提供し続けられます。しかし本番環境での推薦システムは、運用中に様々な要因によってシステムが劣化したり壊れることがあります。これらの問題への対応が遅くなるほどユーザ体験に大きな悪影響が出てしまうので、問題の発生に早く気づき、対応する必要があります。
推薦システムは大きく分けて「アイテムの価値を推定する」と「ユーザに適切に結果を届ける」の2つの役割がありますが、それぞれにおいて異常が生じることが考えられます。これらの問題を早期に検知するため、推薦モデルの精度やシステムの挙動を確認するための各種メトリクスを継続的に監視することが求められます。
「アイテムの価値を推定する」役割における問題の例
「ユーザに適切に結果を届ける」役割における問題の例
「ユーザに適切に結果を届ける」役割における問題については、推薦基盤エンジニアの一條(Wantedly Profile Link)がPodcastで詳しく話しているので、ぜひ聴いてみてください -> Podcast リンク
一度の取り組みで問題が完全に解消されることは稀です。ユーザーが抱える問題の要因は多岐にわたるため、一つの仮説だけにフォーカスせず、複数の仮説を検証することが必要です。また、解決策を完璧に作り上げてリリースすることは不確実性の多いプロダクトのグロースにおいてリスクが高いです。そのため、問題への理解や解決策の品質を継続的に磨き上げることが重要だと考えています。
必要最小限な実験をデザインして進められるように意識をしています。実装や実験を進めているとついつい多くのことをやりたくなるとは思いますが、ぐっとこらえて検証のための最小限の解決策に留める必要があると考えています。
一つ目の理由は、リリースまで余計な時間がかかるからです。答えを知っているのはユーザーだけであり、答え合わせをしていかないと開発は先に進めないので、ユーザーに早く問い合わせる必要があります。
二つ目の理由は、色々一気にまとめて試すと検証結果が曖昧になってしまうからです。まとめて解消させようとすると、結局どの要因が解消されてるのか分からない、どういう要因が残っているのかも分からない状態になってしまいます。短期的にはそれでいいかもしれませんが、長期的に大きな成果を出せなくなることを懸念します。
要因の仮説の検証は、例えば、メールでの訴求やUIのワーディングの変更など、多様な方法で検証が可能です。私自身、並び順の変更という手段を使った検証に固執していた時期がありましたが、それで検証できる問題は多くはありません。より少ないコストで、より正確に検証する方法は他にもたくさんあります。最短でゴールに到達できるようにするために、検証の選択肢を多く持つことが重要だと考えています。
開発において「取り敢えずやってみる」というスタンスを大切にしています。延々と議論しても答えはでないので、まずはユーザーに問い合わせしよう、という姿勢です。しかしこれは考えなしに進めることを意味するわけではありません。
個人的な経験になりますが、特に機械学習は事前に何が効くのか分からないことが多いため、実験を重ねていくという動きが大事になりますが、実験が目的になってしまうことがありました。施策から学びを得て次の行動に繋げられるよう、「まずは的外れを恐れず今持っている情報をもとに課題をきちんと言語化する」、そして「手段が目的に沿っているかを都度確認する」、「最後に答え合わせを忘れない」ということを大事にしたいと思っています。
私たちは、ユーザーの課題解決にフォーカスし、今回紹介したような進め方で課題解決を積み重ねています。本記事で紹介した進め方が、同じくプロダクトでの課題解決に取り組んでいる方々の参考になれば何よりです。
また、私たちと一緒に、推薦システムという技術活用を促進して人と会社の理想的なマッチングを追求するデータサイエンティスト・機械学習エンジニアの仲間を探しています。転職意欲なくても全然大丈夫なので、少しでも私たちの取り組みに興味を持っていただけたら、以下の募集から「話を聞きに行きたい」ボタンをクリックしていただくか、X(旧Twitter) の DM で気軽にメッセージください。カジュアル面談しましょう!
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()





/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)