/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

Wantedly Visitの2-Stage推薦システムを改善し、多様な募集をおすすめできるようにした話 | Wantedly, Inc.
こんにちは、ウォンテッドリーでデータサイエンティストをしている樋口です。今年の4月にウォンテッドリーはミッションを新たにし、「究極の適材適所により、シゴトでココロオドルひとをふやす」と掲げました...
https://www.wantedly.com/companies/wantedly/post_articles/538673
こんにちは、ウォンテッドリーでデータサイエンティストをしている林 (@python_walker)です。私は普段、Wantedly Visitの推薦システムの開発に携わっています。この記事では、推薦システムのジョブを高速化することによって開発プロセス全体の効率を高めたことについて書きたいと思います。
Wantedly Visitの推薦システムについては↓の記事で詳しく紹介されているので興味のある方はぜひ読んでみてください!
私達は普段、ユーザーがより良い仕事や人に出会えるようにするということを目的として推薦システムの開発を行っています。開発の際には多くの場合解決したいユーザーの課題が存在し、それに対する解決策を考えてシステム上に実装します。しかし、自分たちの考えた解決策がユーザーの課題を解決するかという点に関しては実装時点では仮説でしかなく、検証を行うステップが必要不可欠です。検証の方法としてはオンラインテストを行ってユーザーの反応を実際に見てみるという方法が最も直接的ですが、検証には時間がかかるという欠点も持っています。これに対して私達は、オンラインテストを行う前にユーザーの過去の行動データを使ったオフラインテストを挟むことによって、解決策の価値を手早く見積もるということを実現しています。推薦システムをどのようにして開発しているのかもっと知りたいという方は下の記事を読んでみてください。
しかしながら推薦システムでは、扱うデータが大きかったり機械学習を使っていたりするために、ジョブを一回実行してそれをもとにオフラインテストをするのにも多くの時間を必要とします。このような状態では、解決策のブラッシュアップする回数が少なくなってしまったり、ユーザーに価値を届けるのが遅くなってしまうという状況を生み出します。そのため、ジョブの高速化を行うことはユーザーに良いものを早く届けるためにとても重要なものだと考えています。
まず、私達が扱っているジョブがどのような手順で実行されていくかについて簡単に紹介します。
データ取得やエクスポートのステップでは、DWHとの間で大量のデータのやり取りが発生し、その分実行時間が長くなりやすいです。また、ローカルで計算が行われる間のステップにおいても、扱うデータの量が膨大であることや処理の複雑さから、多くの時間を使っていました。このように、高速化以前の機械学習ジョブにおいては改善の余地がたくさんあるといった状態になっていました。
そのためまず、ジョブの高速化を進めるにあたって問題を以下の2つに分割して考えました。
この2つはプロセスの持つ性質が大きく異なるので、このような分け方をして別々に高速化を施していくということを行っていきました。以下では、このそれぞれについてどのような手法を取ったかについて書いていきます。
私達のサービスではDWHとしてBigQueryを利用しており、機械学習モデルの学習のためのデータをここから取得するという形でジョブを作っています。以前のジョブでは、BigQueryからのデータ取得を逐次処理で行っており、ジョブによっては必要なデータを全部取得するのにかなりの時間を必要としていました。この部分を高速化するために、以下のような変更を入れました。
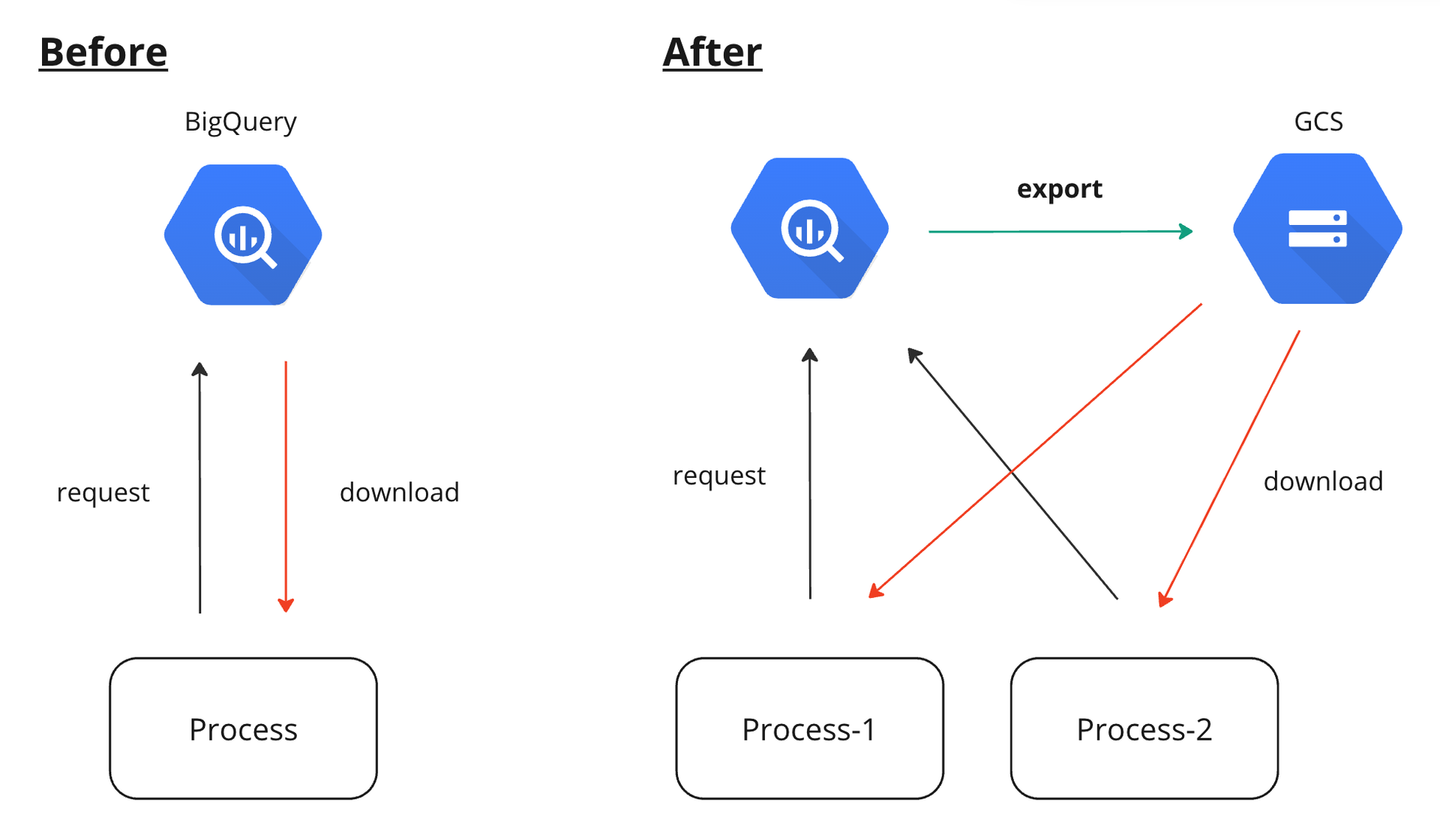
図で書くと下のような感じです。
データ取得時にBigQueryに投げるクエリの多くは互いに依存関係を持っていなかったので、マルチスレッド、もしくはマルチプロセス化で高速にできる状態でした。Pythonの場合にはGIL(Global Interpreter Lock)があるために、マルチスレッドで処理を行ってもCPUを使えるスレッドは1つのみであり、また着目している処理は1つ1つがCPUにも負荷が高い処理だったのでマルチスレッド化による恩恵は少なく、むしろスレッドの切り替えによるオーバーヘッドのほうが大きい状況でした。そのため、この部分の処理はマルチプロセス化を採用することで処理時間の短縮を行いました。
また、BigQueryにリクエストを送る際にはエクスポート先をGCSに設定することができます。直接データをマシンに落としてくるよりもGCSを経由したほうが高速にデータを取得できるため、このオプションを利用することによって高速化を実現しました。
{query}
EXPORT DATA OPTIONS(
uri="gs://hoge*.csv.gz",
format='CSV',
compression="GZIP",
header=TRUE,
overwrite=TRUE
) AS SELECT * FROM {テーブル名} これら2つの改善による効果は非常に大きく、もともと1.5時間ほどかかっていたデータのロードを数分に短縮する事ができました。さらに、これは外部とのデータのやり取りの高速化に分類されるかはわかりませんが、データの保存形式の見直しも行いました。もともとデータはCSV形式で保存して後続のプロセスで利用していたのですが、pandasの to_csv メソッドは遅く、他の形式で保存することで高速化が可能でした。当初pickle形式に変更を行ってこれを実現していたのですが、その後再度見直しの機会があり、利便性の観点から今はParquet形式での保存が採用されています。
# df: pd.DataFrame (100万行 x 100列の乱数から構成されるダミーデータ)
df.to_csv('hoge.csv') # ~90 sec
df.to_parquet('hoge.parquet') # ~8 secこちらの詳細に関しては実際に実装を行った同僚がブログ記事にまとめていますので、ぜひ読んでみてください!
外部とのデータのやり取りを高速化した後は、その後のデータ処理の部分に手を入れました。これまでデータの前処理等ではpandasを利用していました。しかしpandasはよく言われているように実行時に1コアしか使わないので処理の効率が悪く、特に apply といったメソッドを利用する必要があるときには処理の遅さが顕著になることが多いです。この部分を解消するために対応策を検討した結果、利用できそうな方法の候補として以下の2つが挙がりました。
Pandarallelは簡単な手順でapplyメソッドの並列化を実現することができるので導入コストは小さく、こちらを少しだけ使っていた時期もあったのですが、polarsを採用したときの改善幅がかなり大きかったのと、コミュニティの大きさ、開発の活発さから最終的には後者を利用することで落ち着いています。
polarsはRustで実装されたデータ処理ライブラリで、複数のコアを効率的に活用できるので非常に高速にデータ処理を行うことができます。また、pandasとの相互変換も簡単に行うことができるので、一気に全部のpandasコードを置き換えなくても、特に処理速度が遅い部分だけを改善するという使い方もでき、高い柔軟性も持っていました。
import polars as pl
df = pl.from_pandas(df)
# polarsを使った処理
df = df.to_pandas()polarsに置き換えることによって実際にどれくらい処理が早くなったのか、実例を出して紹介したいと思います。下のコードはあるカラムのリストに対して基準日との差分を整数型として計算するということを行っています。datetime型のカラムを一度intに変換する必要があったり、nullのときに処理を分けたりする必要があったので apply を使って処理を行っています。
for col in cols:
_df[col] = _df[col].apply(
lambda x: reference_date_int - int(pd.to_datetime(x).strftime("%Y%m%d"))
if x is not np.NaN
else np.NaN
)このコードを含むジョブでは、df が大きかったことからこの部分だけで50分ほど使っていました。このコードをpolarsを使って書き換えると次のようになります。上のコードでは _df は pandas.DataFrame 型でしたが、下のコードでは polars.DataFrame 型になっていることに注意してください。
for col in cols:
_df = _df.with_columns(
pl.when(pl.col(col).is_null())
.then(np.nan)
.otherwise(
reference_date_int
- pl.col(col).str.to_datetime().dt.strftime("%Y%m%d").cast(pl.Int64)
)
.alias(col)
)一見するとコードが大きく変わっているように見えますが、細かい部分を見てみるとpandasを使ったコードと共通している部分も多く、文法自体も直感的なので移行コストはそこまで高くなかった体感があります。このコードを実行すると処理は1分で終了します。このコードブロックだけで比較すると実行時間が98 %削減できており、かなり大きな高速化が実現できました。
ここまでどのようにしてジョブの高速化を実現してきたかについて書きましたが、書き換える過程で色々な困難にもぶつかりました。特にpolarsに移行する際には、「型」の問題でいくつかの問題が発生しました。polarsはRustで実装されているからかpandasと比べて厳密に型が定義されています。なので例えば以下の処理はpandasではエラーが発生しませんがpolarsではエラーになります。
# pandas
df = pd.DataFrame({'user_id': [1, 2, 3, 4], 'val': [1, 1, 1, 1]})
df2 = pd.DataFrame({'user_id': [1.0, 2.0], 'val2': [2, 2]})
df.merge(df2, on='user_id', how='left')
# → OK
# polars
df = pl.DataFrame({'user_id': [1, 2, 3, 4], 'val': [1, 1, 1, 1]})
df2 = pl.DataFrame({'user_id': [1.0, 2.0], 'val2': [2, 2]})
df.join(df2, on='user_id', how='left')
# → ComputeError: datatypes of join keys don't match - `user_id`: i64 on left does not match `user_id`: f64 on rightこれはデータをDWHからロードしてきたときに問題になることが多いです。データをロードしてきた時点ではデータに型情報は含まれていないので、polarsはデータフレームに変換する際に中身のデータを見て型推論を行うことでカラムごとの型を決定します。このとき、仕様により以下のような型推論が走ることがありました。
このような型推論が走ると、その後段の処理でデータフレームどうしのjoinを行う際に、上に挙げたような型の不整合が発生してジョブが落ちるという問題を引き起こします。データを読み込むときにそのように推論されてしまうのは仕方が無いので、読み込んだ後にcastするといった対応を取ることによりこの問題は解決しました。
この記事では、機械学習ジョブの高速化を行うことにより開発効率やプロダクトの改善効率を大きく改善した取り組みについて紹介しました。これらの改善手法は開発対象のジョブの高速化だけでなく、結果の評価を行うためのコードにも適用可能なものとなっており、ここに書いた改善手法は私達の開発プロセスの広い範囲で大きな効果を生み出しています。これからもユーザーに良いものをより早く届けるために、様々な面からのプロダクトの改善を続けていきたいと思っています。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)