【CTOインタビュー】エンジニアがもっと楽になれる世界を実現する。データ分析基盤の総合支援サービス「trocco®」開発の背景とプロダクトの未来

※本記事は2023年5月8日に作成されたblogを一部修正の上、再掲しています
こんにちは、primeNumber採用担当です。「データ分析基盤の構築や運用に、工数を大きくとられてしまう」。現場のデータエンジニアのこうした課題を解決するのが、primeNumberの開発するサービス「trocco®」です。データエンジニアの作業負荷をどう減らしているのか、trocco®の市場価値とプロダクトの未来についてどんな展望を持っているか。今回はエンジニア目線でどう感じているかに迫るべく、CTOの鈴木健太に話を聞きました。
——はじめに、鈴木さんがprimeNumberに入社するまでの経緯を教えてください。
東京大学工学部を卒業後、株式会社リブセンスへWEBエンジニアとして入社し、転職口コミサイトの開発、企画、分析などを担当していました。primeNumberとの出会いは、前職の同僚だった小林さんからの紹介がきっかけです。当初は副業だったんですが、ビジネスそのものと、一緒に働くメンバーに魅力を感じて転職を考えるようになりました。
半年ほど副業をしてから、2017年には正式にprimeNumberに入社しました。「systemN」という自社プロダクトを通して、普通の事業会社では扱えない大規模なログデータを扱っている点に魅かれました。会社としてもこれから大きく成長していくフェーズで、めったにないチャンスだと感じたんです。
入社してからは「systemN™」の開発を担当し、その後CPOの小林さんが立ち上げた「trocco®」の開発に加わりました。現在はCTOとして、trocco®の開発リードやエンジニア採用などに携わっています。
エンジニアがやらなくていい業務をプロダクトが自動化。エンジニアをもっと楽にし、価値ある時間を創出。

——鈴木さんが開発をリードするプロダクト「trocco®」は、エンジニアのどのような課題を解決しているのか、あらためて教えてください。
多くの企業で、社内のあらゆる場所に点在するデータを統合、蓄積して分析基盤を構築するニーズが高まっています。そこで課題となっているのが、エンジニアにかかる負担です。
まずは点在するデータを統合するプロセスについてお話します。
統合したいデータについて要件を洗い出し、入力テーブルやファイル、APIといったデータソースを選定します。次に、カラムの内容や仕様を確認し、認証情報を取得。データソースの仕様を調査・学習、セキュリティ・パフォーマンスの要件などを確認した上で、ETLシステムを設計・開発します。その後も、サーバー環境構築、ジョブ実装・スケジューリング、出力結果・エラーといった通知の監視、分析データマート作成、出力データの異常検知など、さまざまな作業が必要です。
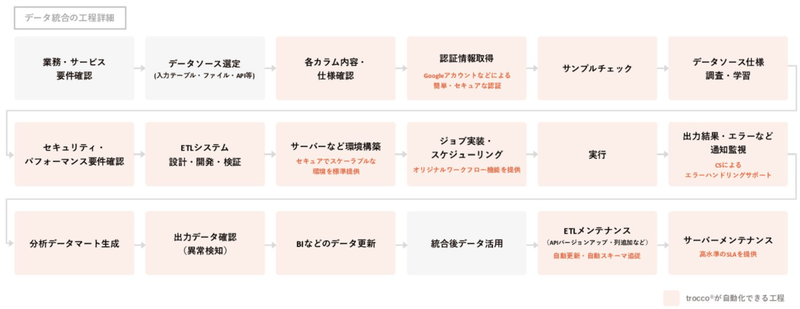
このように、データ分析基盤の構築・運用において、エンジニアがやらなければいけないことはものすごく多いんです。そのせいでエンジニアの開発リソースが不足し、本来やりたい業務ができない。そんな現状を変えたいと考えてリリースしたのが、データ統合を自動化する「trocco®」というプロダクトです。
trocco®を活用すれば、開発いらずでデータ統合ができる。手作業によるエンジニアの負担を減らすことができます。
——プロダクトが解決している課題を、エンジニア目線で具体例を教えてもらえますか?
データを収集していくというフェーズの、Webサービスで提供されるAPIに関連する業務がわかりやすいです。
社内の各部門や部署で利用するWebサービスのデータを集めようとすると、各社のAPIを使ってコネクタを開発し、データ転送を実現するといった流れになります。ですが、数社のAPIならまだしも、全社全部門となるとこの開発工数は大きく膨らみますし、各社のAPIのアップデートへの対応といった運用業務もあり、エンジニアはAPIに関わる業務に大きく手を取られていました。
また、第三者が提供するデータと、自社のMySQLに格納されているデータを統合するのも大変です。たとえば、あるプロダクトの利用ログがMySQLに格納されていたとして、第三者から提供されているマーケティングデータと統合・分析して意味を見出したいというようなケースですね。ユーザーはどういうマーケティング経路でどういう利用をしているのか?最も使ってくれているユーザーはどのチャネル経由なのか?といったような分析がされるわけです。これを実現するにはMySQLをdumpして分析基盤にデータ転送するといった処理を毎回エンジニアが行う必要がありました。
更に、収集したデータを分析する前には、データクレンジングも必要です。実際は同じデータでも、単位が「%」の場合もあれば「小数点」の場合もあります。各社が用意しているカラムの名前も異なっていることもあったり、nullのカラムがまじっていたり。このようなデータを整備し、統合するにも、工数がかかってしまいます。
こういった手のかかる業務を自動化して、エンジニアを楽にすることがtrocco®の価値だと思いますね。
「データ分析基盤のサービスといえばtrocco®」カスタマーサクセスを通じて届くフィードバックに手応え。
——鈴木さんの考えるtrocco®の市場について教えてください。
trocco®はエンタープライズ企業から中小企業まで幅広く使っていただいており、市場が広がっています。グローバルでの可能性も感じてますね。アメリカにはtrocco®と似た機能を持っているプロダクトもあり、市場価値1,000億円を超えるユニコーン企業に成長しているんです。
trocco®も海外展開をスタートしていて、まずはアメリカ市場でこの領域のデファクトとなるようなプロダクトを目指しています。プロダクトの英語翻訳は済んでいて、現在は海外の専任チームを置いて、テストマーケティングやキーパーソンへのインタビュー、パートナー企業の開拓を行っています。
——現場感覚で、trocco®はお客様にどう受け止められていると感じていますか?
trocco®の新しい機能をリリースすると好意的なフィードバックや要望が寄せられます。
具体的には、「trocco®がなかったら分析基盤は構築できなかった」「分析基盤構築といえばtrocco®だ」といった喜びや期待の声をもらうことが多いですね。プロダクトの使い方に関する細かなフィードバックも、カスタマーサクセスチームを通じてエンジニアに届けられています。
現場レベルでは、お客様がしっかりプロダクトを使ったうえでフィードバックをしてくださっている感触があります。
——trocco®を市場に広めていく上での課題や障壁についてはどう感じていますか?
trocco®の普及に関しては、ユースケースの幅広さゆえの難しさがあると感じています。たとえば、「MySQLのデータを統合したい」、「広告のデータを統合したい」、「売上データを統合したい」など、お客様の数だけニーズやユースケースが存在します。
これらのユースケースにすべて対応するのはリソース的にも難しいので、何を優先するか、取捨選択する必要があります。そこで、プロダクトマネージャーやセールス、カスタマーサクセス、エンジニアが集まって、プロダクトの将来性や売上、工数といった観点から、優先順位をつけるための機会を作っています。
前例がない道をチーム全体で歩む。データマネジメント領域の拡張への挑戦。

——技術的な視点も含め、trocco®の今後の展開を教えてください。
trocco®は、日本国内のコネクタを中心に幅広い要望に対応することで、Data Integration、つまりデータ統合の領域で成長してきました。『データマネジメント知識体系ガイド』のホイール図で表された「データマネジメントの11領域」を意識しつつ進めています。
これまでtrocco®は「Data Integration & Interoperability」の部分で主に価値を提供してきましたが、近年「Metadata」や「Data Modeling & Design」といった領域でも開発を進めており、さらには「Data Quality」に関してもカバーできればと考えています。
「Data Modeling & Design」の機能開発を進めたのは、この領域もエンジニアの手間が多いと感じたからですね。trocco®のお客様のデータ分析フローを見ていると、データ統合をしたあとに生のデータを直接活用することはなく、たとえば日ごとの集計データを取得する場合は毎回SQLを叩いてテーブルを作成していました。何人ものエンジニアが毎回同じことをするなら、利用者のニーズに合った形のテーブルを作ればいいのでは?と考えて、Data Modelingに着手しました。
また、「Metadata」に関しても同じく手間が多く、データ統合で持っていた機能とも親和性が高いと思い、開発しました。データウェアハウス内のテーブルに存在するカラム情報など、データの属性情報を示すMetadataは、データを利活用するうえで必ず必要になるものです。しかし、データウェアハウスの中にどんなデータが入っているかはテーブルを作った人であればわかるものの、データを実際に利用する分析者にはわかりません。そのため、分析者がエンジニアに対して「このデータはなんのデータか?」と問い合わせることが多く、コミュニケーションコストがずいぶんかかっていました。また、Metadataをドキュメントにまとめる工数もかかっていた、という状態でした。trocco®は収集したデータの転送元情報をMetadataとして管理していたため、自動的にカラムにMetadataを付与するような機能を開発することでスムーズに分析者が分析できるようにしました。
「Data Quality」はまだ機能としては実装されておらず、これから取り組む領域です。顧客課題は明確なので、どう形にするか議論を進めているところですね。たとえば、サイトのアクセス分析において、ある日突然インプレッション数が急増したら、そのデータは正しいのか?という疑問が生じます。こうしたデータ品質の問題に素早く気づき施策を打つための機能を提供し、信頼性を担保することを目指しています。
こうした取り組みは前例がないので、課題をどう機能に落とし込んでいけばいいか、参考になるものがありません。ベンチマークできるような機能がないんです。だからこそ、決まった仕様通りに開発していくのではなく、そもそもその機能をどう作るか、なるべく早く、質も高くお客様に価値提供するにはどうしたらいいか、そういったことを総合的に考える必要があります。自分たちで正解を見つけに行くようなもののため、常にチャレンジングだと感じています。
怠惰は美徳。エンジニアをもっと楽にするためのプロダクトに向き合って欲しい。

——開発チームの観点から、今後のプロダクトの展望を聞かせてください。
開発チームとしては、引き続きエンジニア向けに、価値あるプロダクトにしていくことを目指しています。私たち自身もエンジニアなので、お客様の困っていることが良く分かるんです。面倒な作業を自動化することで、お客様がより戦略的な仕事に集中できるようなプロダクトを提供したいです。
そのためには、技術的な取捨選択がますます重要になってくるでしょうね。どんな方針で実装すれば品質が高くなるか、より速くできるかを考える必要があります。そういったことを一緒に考え、協力して開発を加速してくれるようなメンバーを募集しています。
何らかの技術にこだわるというよりも、正しいプロセスで機能開発を行い、負債を残さないようにして、組織拡大に耐えられるチームを作りたいですね。
——今後プロダクトをより成長させるために、どんな価値観を持った方と一緒に働きたいですか?
よく、「怠惰」はエンジニアの三大美徳の1つであると言われますが、面倒な作業こそどんどん自動化していくのがエンジニアの美徳だと思っています。私たちのプロダクトはまさにそのためのもの。お客様であるデータエンジニアのみなさんに「楽」をしてもらうことが最終ゴールだと考えています。「trocco®を使うと分析基盤の構築が本当に楽だ」と言われたいですね。
この考えに共感してくださる方、お客様のことを考え、trocco®というプロダクトの可能性を信じて、その一連のプロセスにやりがいを感じていただけるような方を求めています。
BtoBのプロダクトは、BtoCにくらべてお客様は少ないですが、大きな価値を返せるという特徴を持っています。作ったプロダクトに対してお客様からフィードバックをもらえる体制は整っているので、お客様に近い距離でものづくりができていると感じられるのではないでしょうか。プロダクトを成長させることに対して自分ごととして捉えて開発に携わってくれる方に、ぜひ仲間になって欲しいです。
少しでもご興味を持っていただける方は、ぜひカジュアル面談からお話しましょう。
herp.careersエンジニア_カジュアル面談申し込み用株式会社primeNumber

エンジニア採用ページ
primeNumber エンジニア採用 - primeNumber エンジニア採用primenumber.gitbook.io
/assets/images/19932003/original/bbb6e07c-2200-47d9-8f2b-0fc981acfc80?1733918320)


/assets/images/19932003/original/bbb6e07c-2200-47d9-8f2b-0fc981acfc80?1733918320)

/assets/images/19932003/original/bbb6e07c-2200-47d9-8f2b-0fc981acfc80?1733918320)


