エンジニアの富岡です。2ヶ月ほど前まで、Wantedly 利用企業向けのプラン契約や料金請求周りのシステムの改修と機能追加を行うプロジェクトをやっていました。1年半ほどの長期プロジェクト、かつステークホルダーの多いプロジェクトだったので、プロジェクトマネジメントの観点でも書くべき話題はあるのですが、今回はより技術的な部分に焦点を当てて、プロジェクト開始時点でレガシー化していたシステムの状態を改善するために行った取り組みを紹介したいと思います。
背景
Wantedly は SaaS 型のビジネスを提供しており、利用企業の契約プランに従って毎月の料金の請求を行ったり、契約の自動更新を行ったりといった処理が発生します。こうした処理を行うシステムは、今から8年ほど前までにそのベースとなるものが作られました。それ以降は消費税率の変更や、新しい支払い方法の対応など、必要に応じて散発的に変更は行われていましたが、ベースとなる部分は変わらずに運用していました。
その間、システムに対してビジネス、オペレーション、コーポレートなど社内の様々なステークホルダーの要望や課題が溜まっており、そのいくつかは骨格となる部分を見直す必要のあるものでした。しかし、プロダクト指標に対するインパクトが小さいことから、なかなかそのような大きな改修は優先度を上げて行うことができていませんでした。その結果、運用で頑張ってカバーしたり、ものによっては目をつぶって諦めるといった形になっていました。
加えて、この領域は登場人物や連携箇所も多くドメイン的にそれなりに複雑なのですが、システムのベースを作ったメンバーは何年か前に退職しており、また変更も散発的にしか行われない領域であることから、システムの全体像を把握している人がいなくなっていたことで、より手が付けづらくなっていました。
このような状況が数年間続いていましたが、事業的な重要度が高く、先延ばしの効かない開発要件がいくつか出てきたことから、システムの抜本的な改修やメンテナンス性の改善もスコープに入れて、新規要件や積年の要望の実現に取り組む大がかりなプロジェクトがスタートしました。
モデリングの見直し
挙がっていた要望のいくつかや、新規で開発することになっていた重要案件は、現行のモデルの延長線上では実現が難しいものでした。そこでまずはモデリングの見直しに取り組みました。
(一応公平を期すると、元のモデルもそれが作られた当時の状況では必要十分なものだったのだろうと思っています。そこから事業の成長に伴って、売り物の種類が増えたり、顧客ごとに柔軟な対応をしたりするようになる中で、少しずつモデルとの間で無理が来ていたのだと捉えています。)
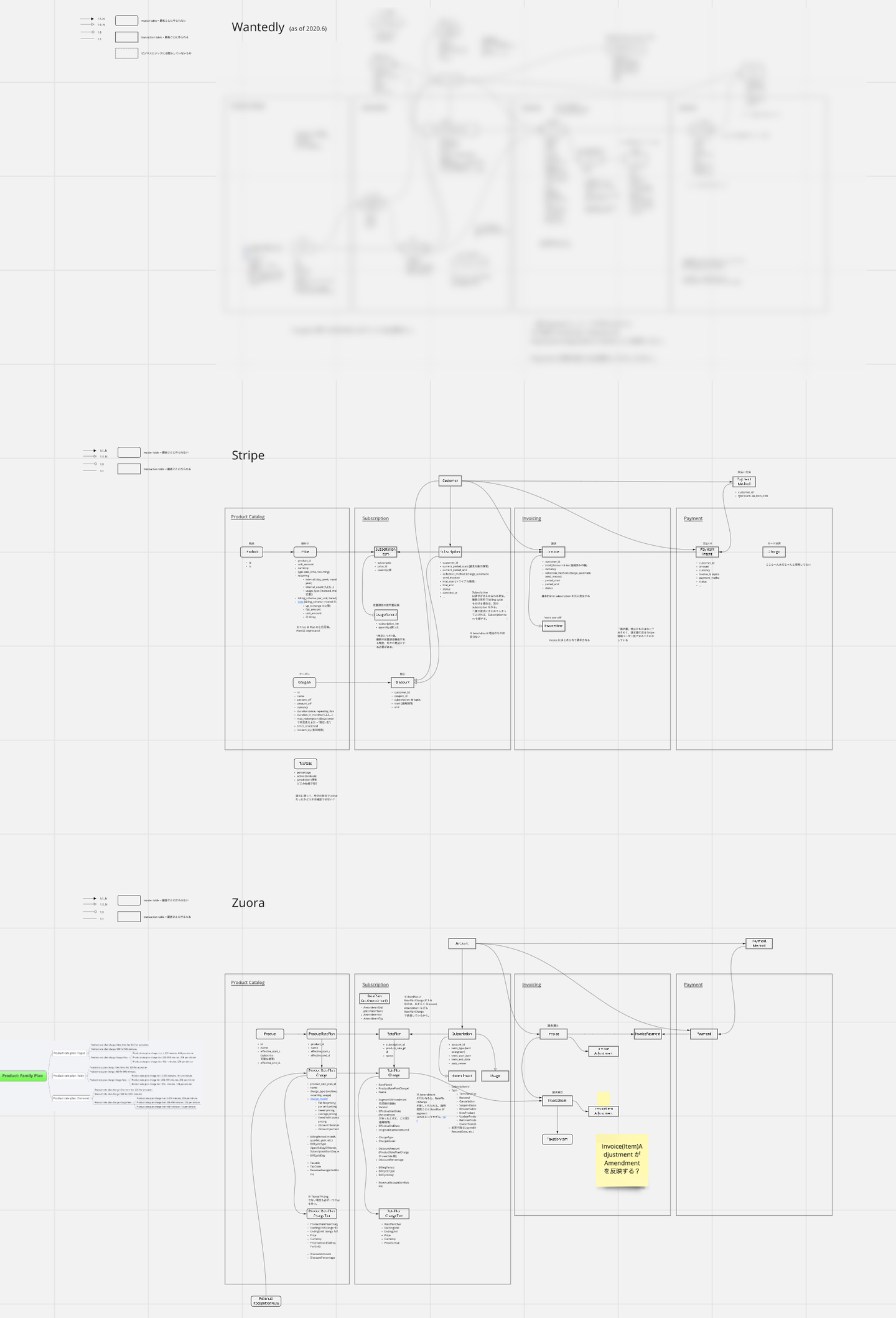
まず、同じドメインの SaaS である Zuora や Stripe のモデルを参考にして、自分たちの既存システムのモデルとの違いを比較しました。Stripe は比較的シンプルなモデルで、対して Zuora は重厚なモデルであり、自分たちの事業においてはどのあたりに落ち着かせるのがよいだろうかという点でも参考になりました。
![]()
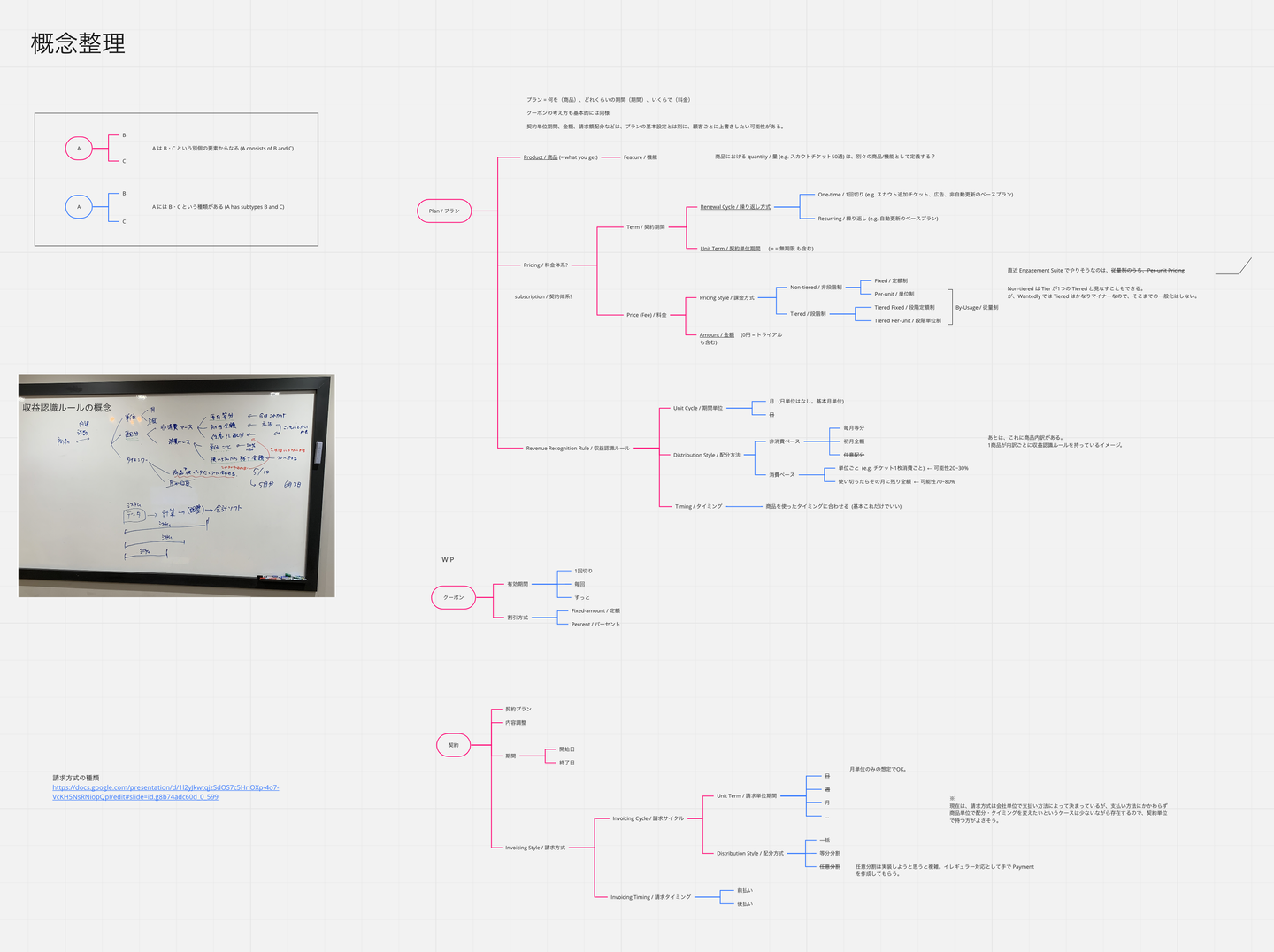
次に、これらのモデルを昇華し、一度概念レベルでの整理を行いました。ここはドメインエキスパートである経理やコーポレートのメンバーと一緒に確認し、今ビジネス的に提供しているものだけなく、将来的に対応するかもしれないちょっと広い範囲まで含めて行いました。
![]()
そこから将来的な拡張として想定しておいた方がいい部分と想定しておかなくていい部分を取捨選択し、再び具体的なモデルに落とし込んで、あるべき姿を考えていきます。とは言ってもフルスクラッチで作り直すのは移行が大変すぎるので、ある程度焦点は絞り、変えなくてもいいところはそのまま残しておきました。
ある程度形ができたら、ビジネス、オペレーション、経理などドメインの関係者を集めてこのモデルの評価を行いました。具体的なユースケースにおいてどういう動きをするのか説明し、うまく動きそうかを一緒に確認していきます。ここで例えば、プランや契約の金額は月額でなく、総額で持った方が扱いやすいのではないかといった洞察が生まれたりしました。このプロセスを何回か行い、モデルをブラッシュアップさせていきました。
これでいけそうという感覚が持てたところで、最初のマイルストーンである新規機能要件の土台を実装してみました。そうすると、モデリングではよさそうに見えていた契約テーブルの持ち方が、コードが冗長になる・テストが書きづらいなどの扱いにくさがあることがわかりました。そこで設計を見直し、2日ほどでがっとリファクタリングを行いました。やっぱりコードに落とし込んで実装してみてはじめて気づくことがあるなと感じました。
データの移行
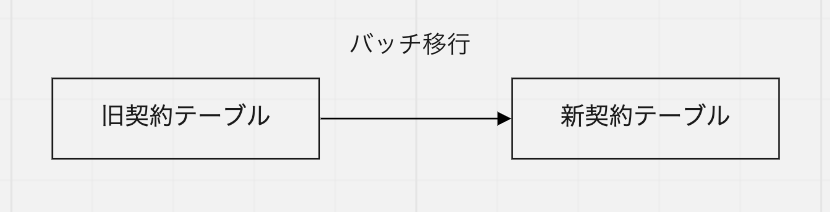
モデリングを見直してデータベースのテーブル構造を一部変えることにしたので、旧モデルのテーブルから新モデルのテーブルにデータを移行する必要がありました。
ただし、契約や請求といったデータはお金に関わる部分であり、データをバッチ移行してすべての読み込み・書き込み先を一気に置き換えるといった移行のしかたは危うすぎます。データの移行やアプリケーションコードにどこか一つでもミスがあれば、顧客に誤った請求がされてしまう可能性があるからです。
今回はより安全な方法として、一定の期間新旧両方のテーブルに同時書き込みを行い、両者の整合性が取れていることを確認した上で、徐々に読み込みを新テーブル側に置き換えていくという戦略を取りました。具体的には、以下のステップで進めました。
- 既存データのバッチ移行
- 新旧テーブルへの同時書き込みの有効化
- 一定期間、新旧テーブルの整合性チェック
- 読み込みを新テーブル側に徐々に切り替え
- 旧テーブルへの書き込みを停止
(ちなみに、このあたりの戦略は書籍『モノリスからマイクロサービスへ』の「3.7 同時実行」「4.8 パターン: アプリケーションでのデータ同期」あたりが参考になるので、より詳しく知りたい方はあわせて参照してみてください。)
以下で各ステップをもう少し詳しく見ていきます。
1. 既存データをバッチ移行する
![]()
まずは旧テーブルのデータを新テーブルにバッチ移行します。ここは基本的にはスクリプトで機械的に移行するのですが、今回は旧テーブルに比べて新テーブルの方が情報量が増える (今まで持っていなかった情報を持つようにする) 部分があったので、その部分は目で見て値を入れていきました。
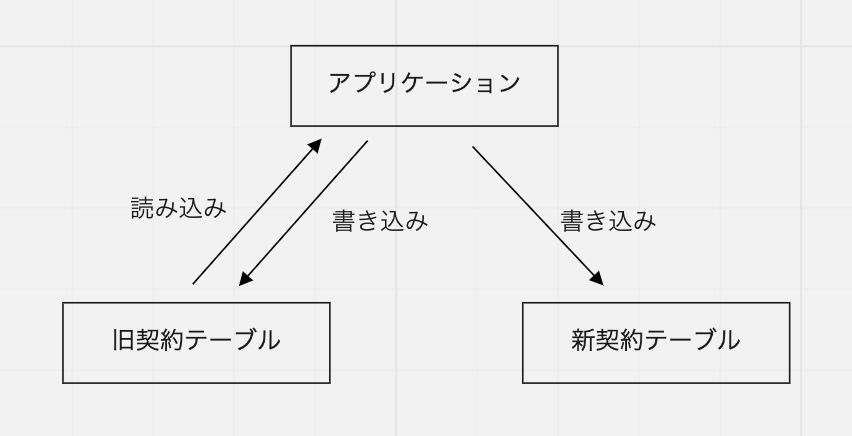
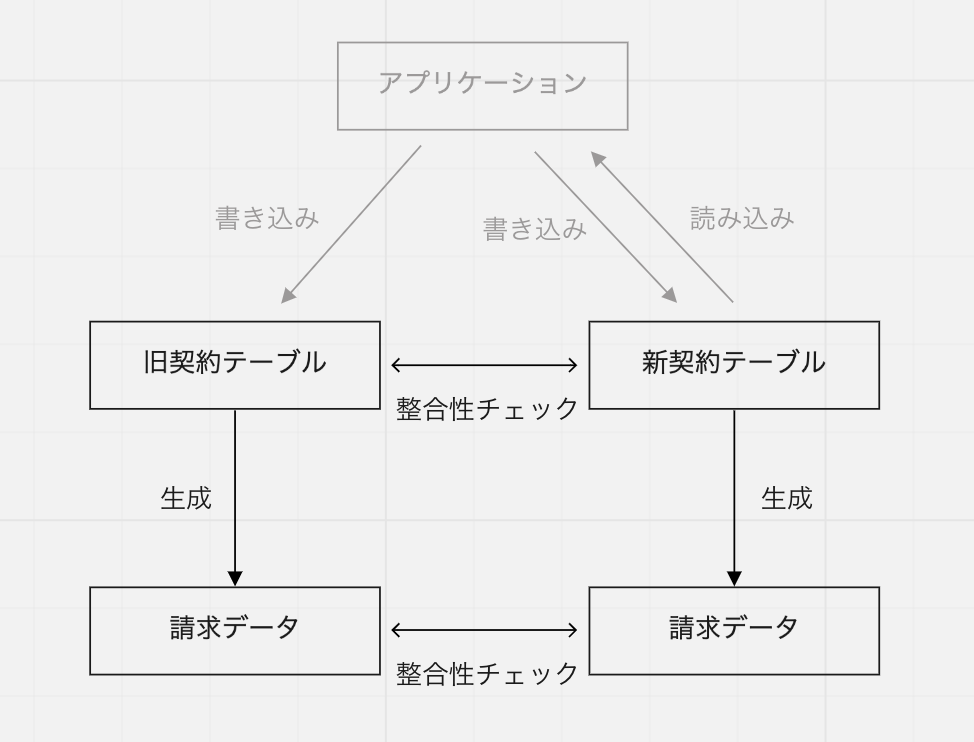
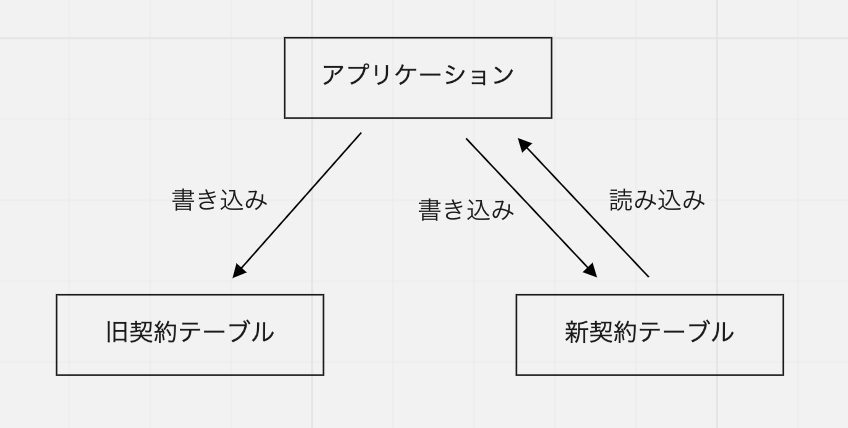
2. 新旧テーブルへの同時書き込みを有効化する
![]()
既存のデータをバッチ移行したら、アプリケーションから新旧両方のテーブルに同時書き込みを行うようにします。実際には、この同時書き込みを行うコードをフラグでオフにした状態で先にデプロイしておき、バッチ移行の実施と合わせてフラグをオンにして有効化しました。
この時点では、読み込みはまだ旧テーブルの方から行います。また、新テーブルへの書き込みが失敗しても、旧テーブルへの書き込みには影響がないようにしておき、アプリケーションは正常に動作するようにしておきました。
3. 一定期間、新旧テーブルの整合性をチェックする
![]()
同時書き込みを有効にした状態で、新テーブルのデータがアプリケーション的に信頼して利用できる状態になっているかを検証するために、日次のジョブで新旧テーブルの整合性チェックを行いました。
ただし、今回の場合上でも書いたように、新しい契約テーブルの方が情報量が増える部分があったので、新旧の契約テーブル間での単純な比較だけでは正しい状態になっていることを保証できませんでした。そこで、新旧の契約データを元にして作られる請求データの突合もあわせて行いました。これにより、契約データから請求データを生成するロジックの部分も含めて、請求システムとして新テーブルに基づいたものに置き換えても大丈夫かどうかが確認できました。
整合性を検証していてずれがあった部分は、その原因となったコードを修正し、ずれてしまったデータも修正します。これを続けて、一定期間ずれが発生しない状態になることを確認して次のステップに移りました。
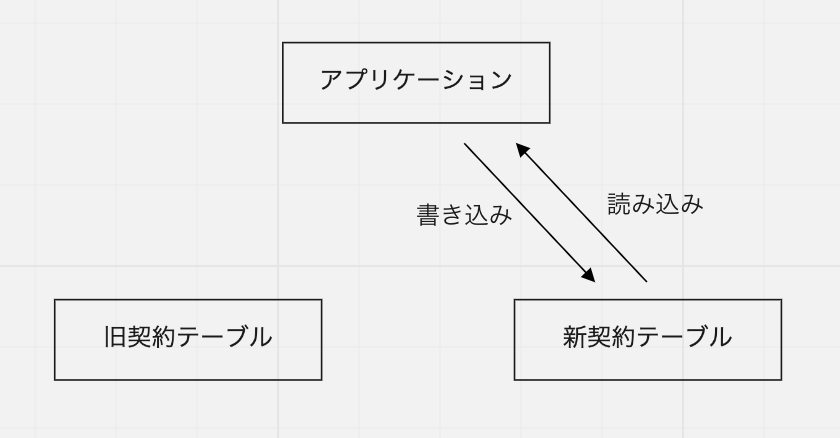
4. 読み込みを新テーブル側に徐々に切り替える
![]()
新テーブルが信頼できる状態になったので、読み込みを徐々に新テーブル側から行うようにしていきます。この段階でもまだ旧テーブルへの書き込みは続けているので、切り替えによって何か問題があれば、すぐに旧テーブルから読み込むように戻すことができます。幸い実際にはその必要はなく、この切り替えはスムーズに進みました。
5.旧テーブルへの書き込みを停止する
![]()
旧テーブルからの読み込み箇所がなくなったところで、旧テーブルへの書き込みを停止します。これで晴れて旧テーブルが引退し、システムは完全に新テーブルに基づく形になりました。
と、ここまできれいに書いてきましたが、実際には書いているほどスムーズに進んだわけではありませんでした。整合性がなかなか合わずに、同時書き込みの方法を一部抜本的に見直してやり直すといったこともしながら、半年ほど書けてようやく移行が完了しました。
コードの構造的な整理 – Fat モデルの分解
ここからはメンテナンス性の改善のために行った取り組みにより焦点を移します。
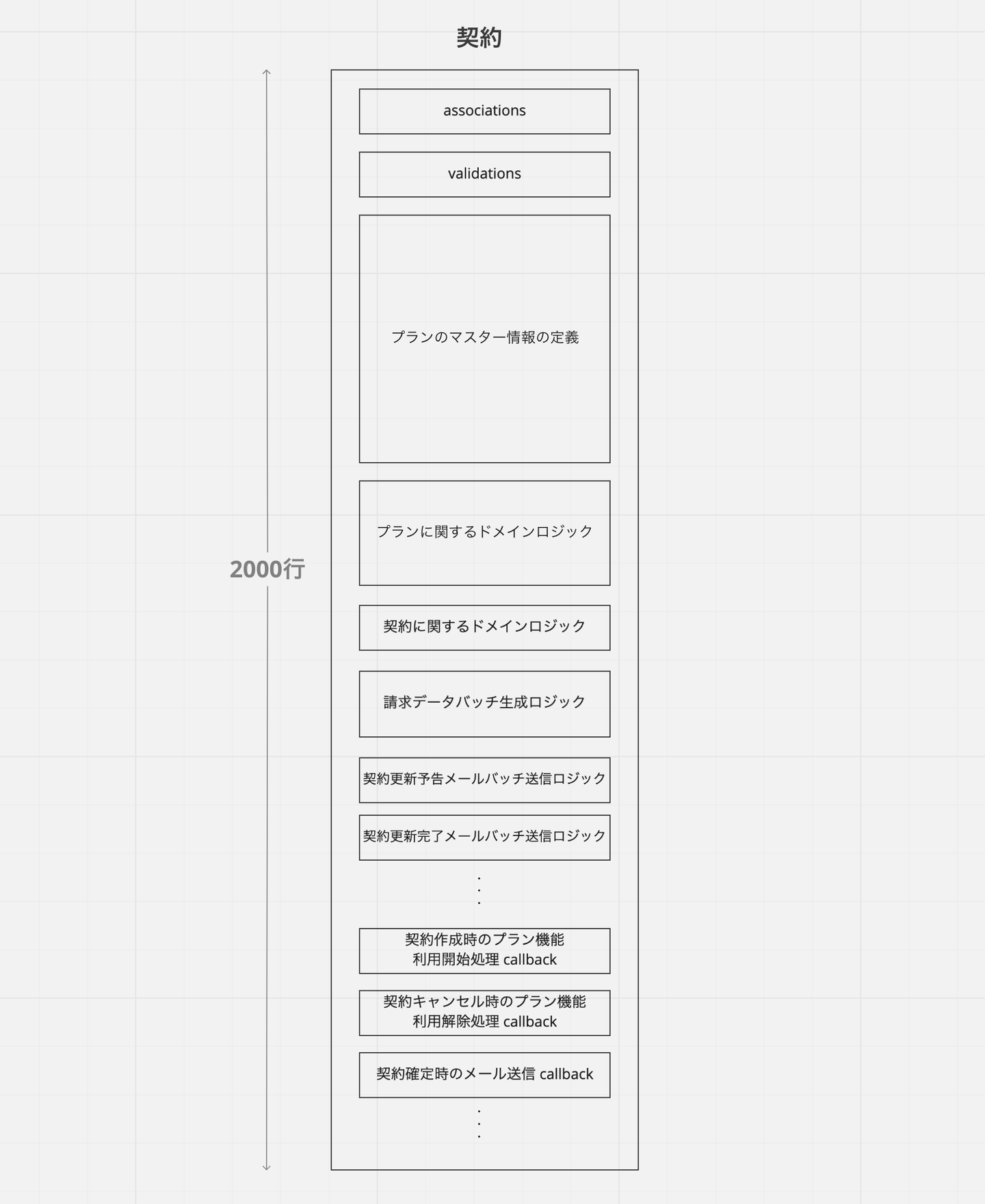
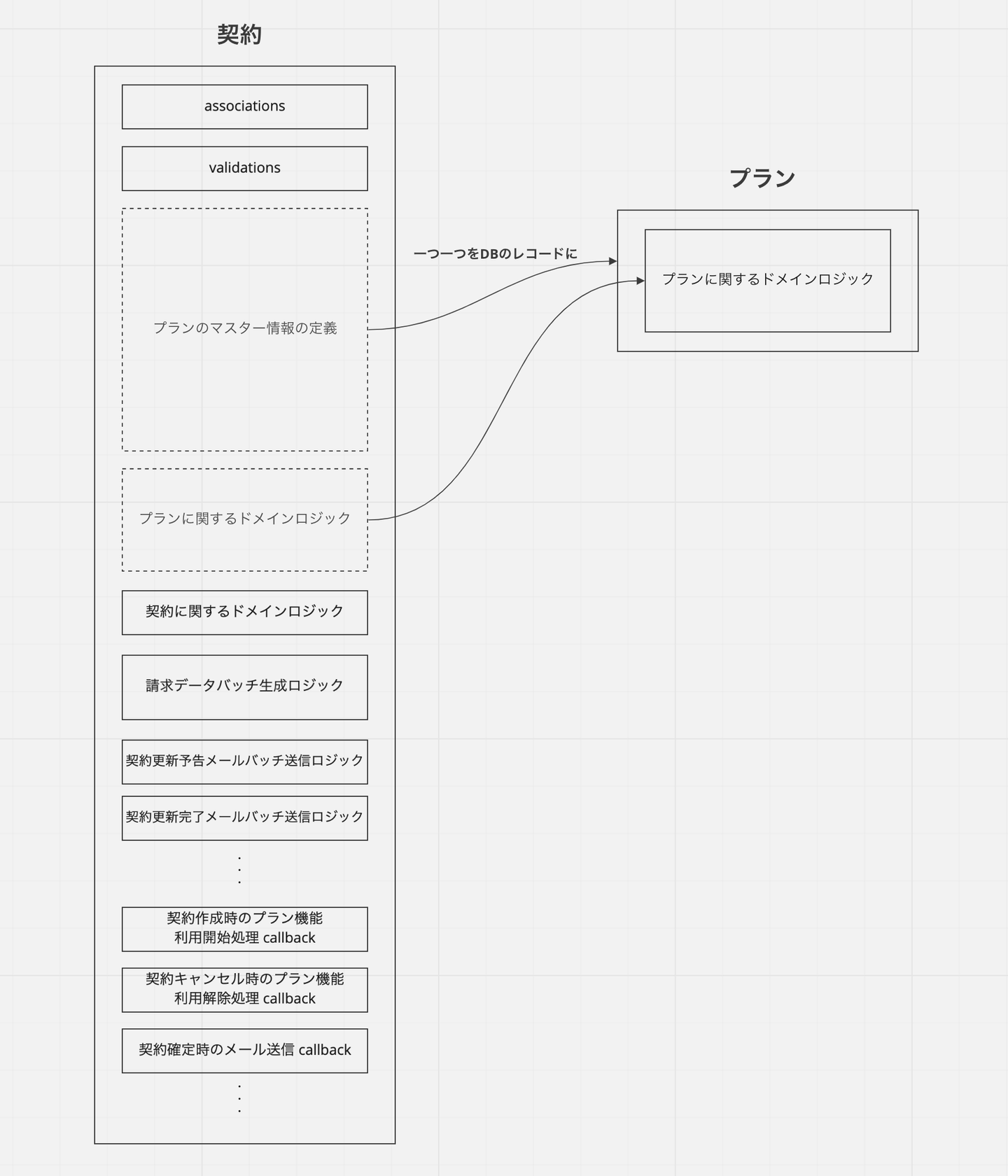
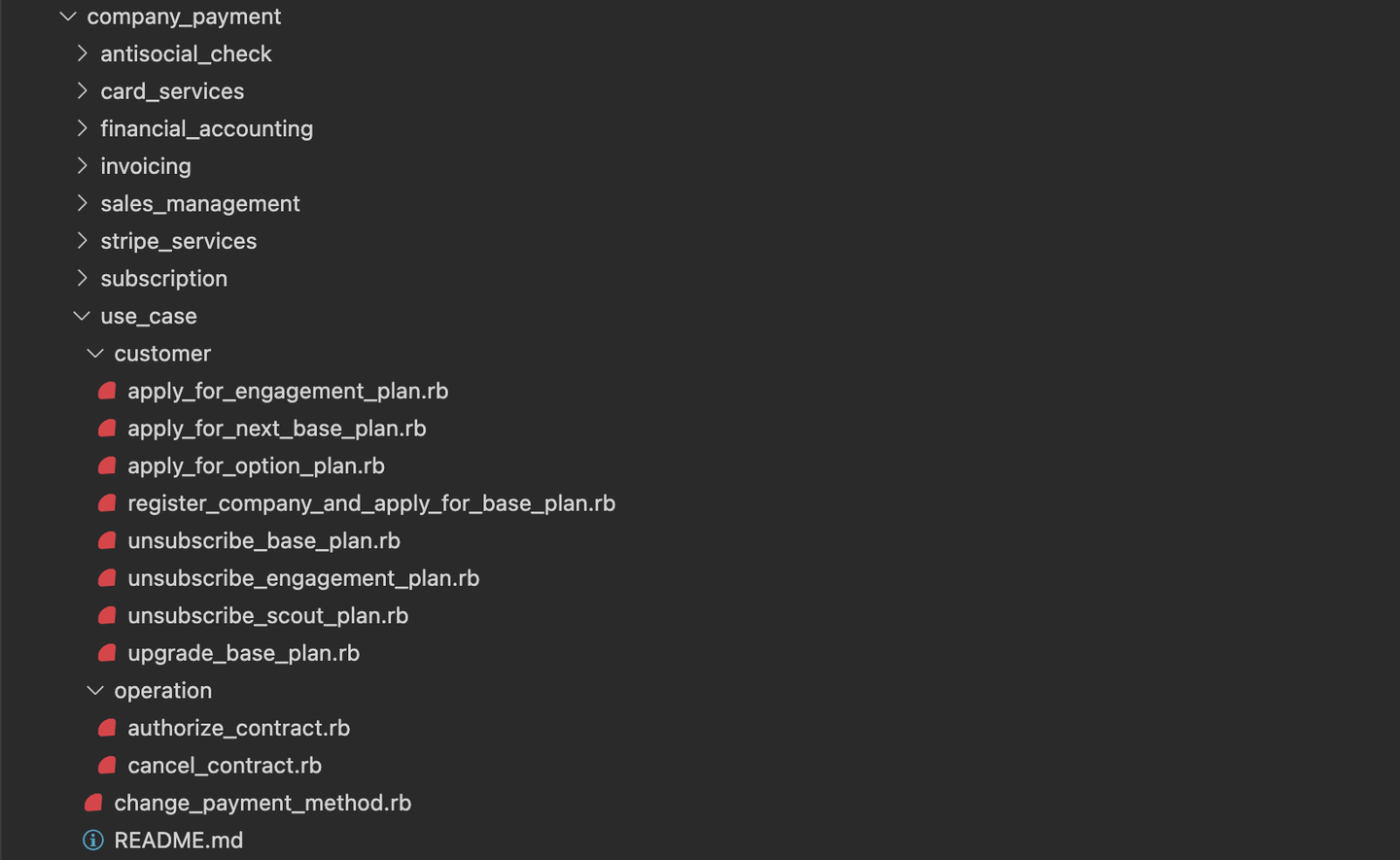
コードが構造的に整理されていることは、システムの理解と変更のしやすさにつながります。中でも最も重点的に取り組んだのは、いわゆる Fat モデルの分解です。例として、プロジェクトが始まる前の旧契約モデルのコードは以下のような構造になっていました。契約モデルの本質的な責務でないような、プランのマスター情報の定義や各種バッチ処理などが数多く書かれていて、コードが膨れ上がっていました。
![]()
これを順番に切り崩していきます。まずプランについての情報は、モデリングの見直しによって独立したテーブルとして持つのがいいだろうと判断していたので、別のモデルに切り出しました。
![]()
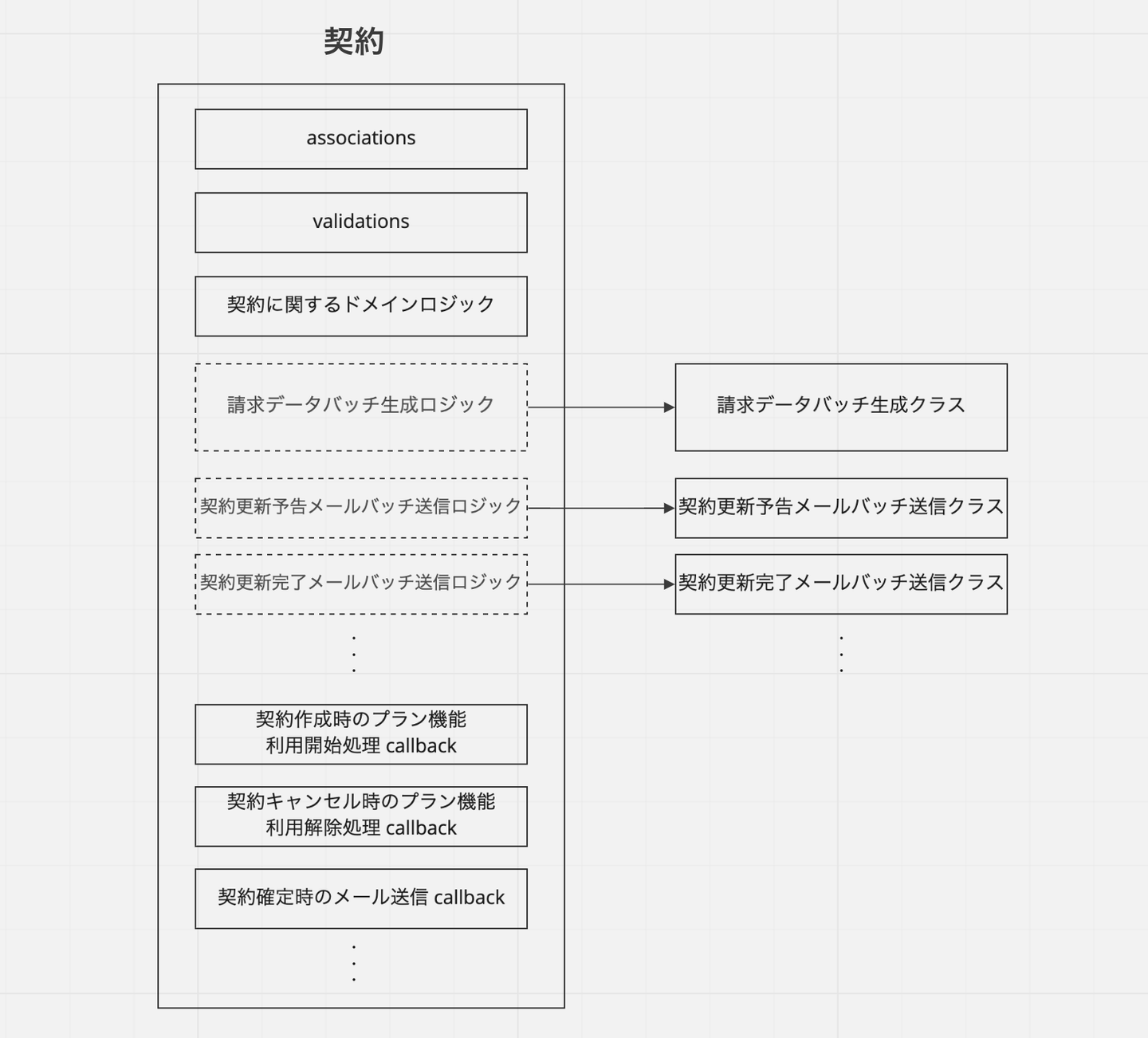
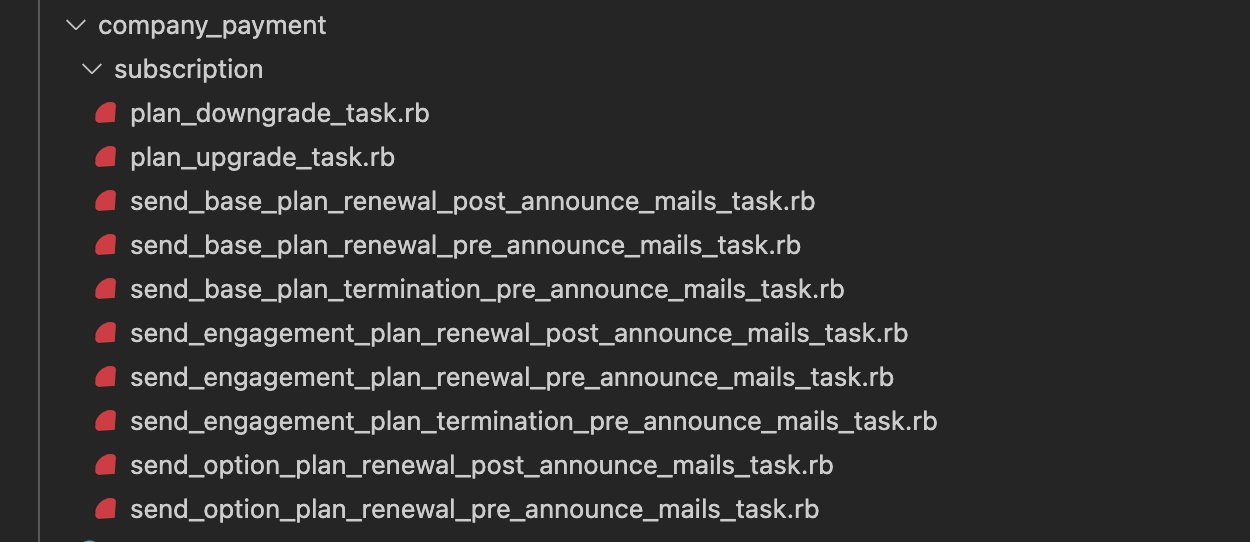
続いて、各種バッチ処理はそれぞれ個別のクラスに切り出していきます。切り出したクラスはサブドメイン領域ごとに名前空間を切って収めていきました。一つ一つが小さいクラスになったことでコードの理解がしやすくなったほか、ディレクトリを見ればどのようなバッチ処理が存在しているのかが把握しやすくなりました。
![]()
![]()
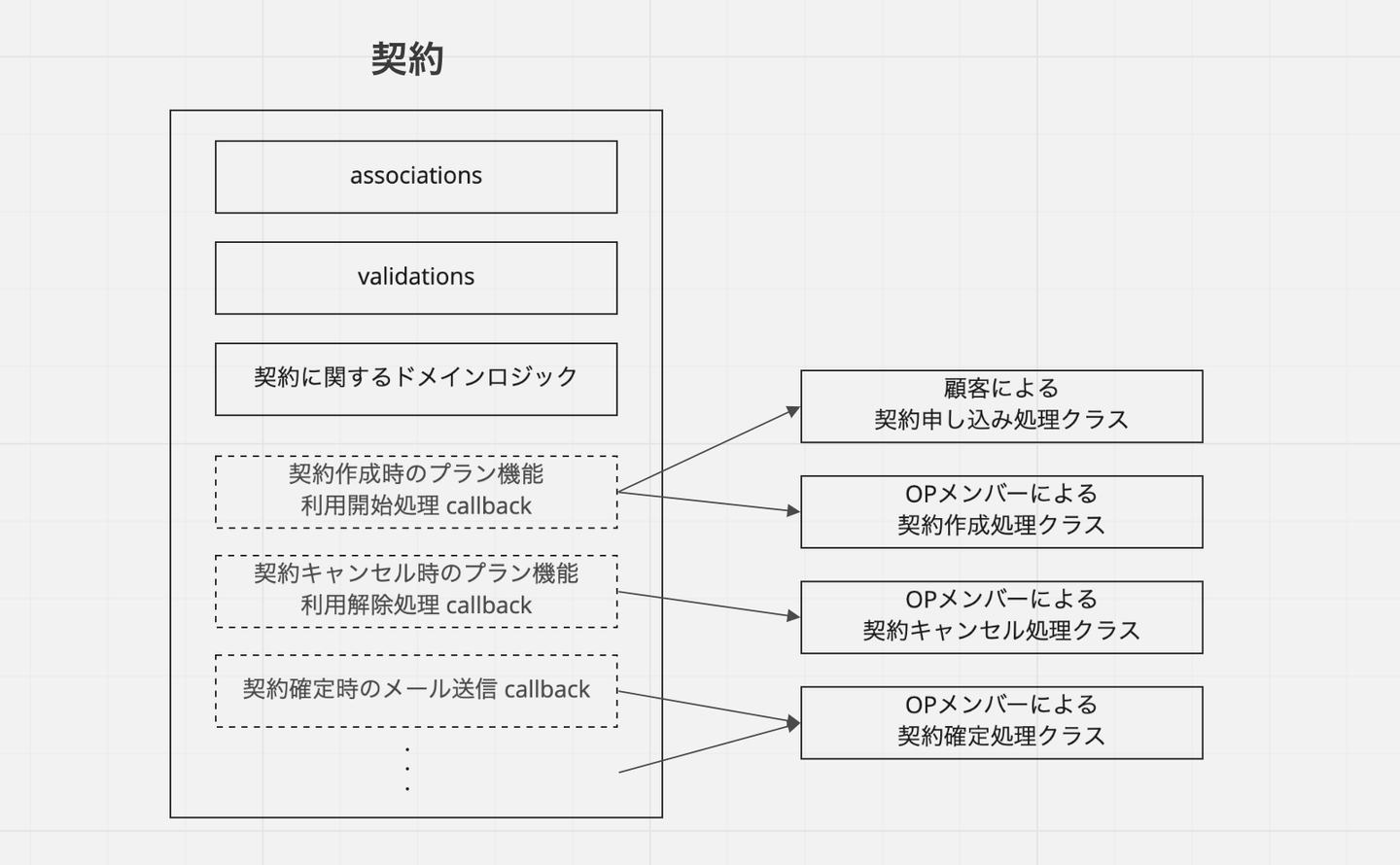
最後に callback 群ですが、これらはドメイン駆動設計で言うところのアプリケーションサービスにあたる、一段上のレイヤーのクラスに移していきました。例えば、契約モデルの create や特定のフィールドの update の callback で行われていた処理は、「契約申し込み処理」「解約申し込み処理」といったドメインの具体的なユースケースを表すクラスに移ります。これにより、特定のユースケースにおける処理のフローがかなり理解しやすくなりました。また、契約データのように、顧客のアクション起点でも、社内のオペレーション起点でも変更が行われるようなものも、変更時の副次処理がそれぞれのアクターごとのユースケースクラスに移動したことで、こっちを変える意図で変更したらあっちにも影響が出てしまったといった意図しないバグが入りにくい構造になりました。
![]()
![]()
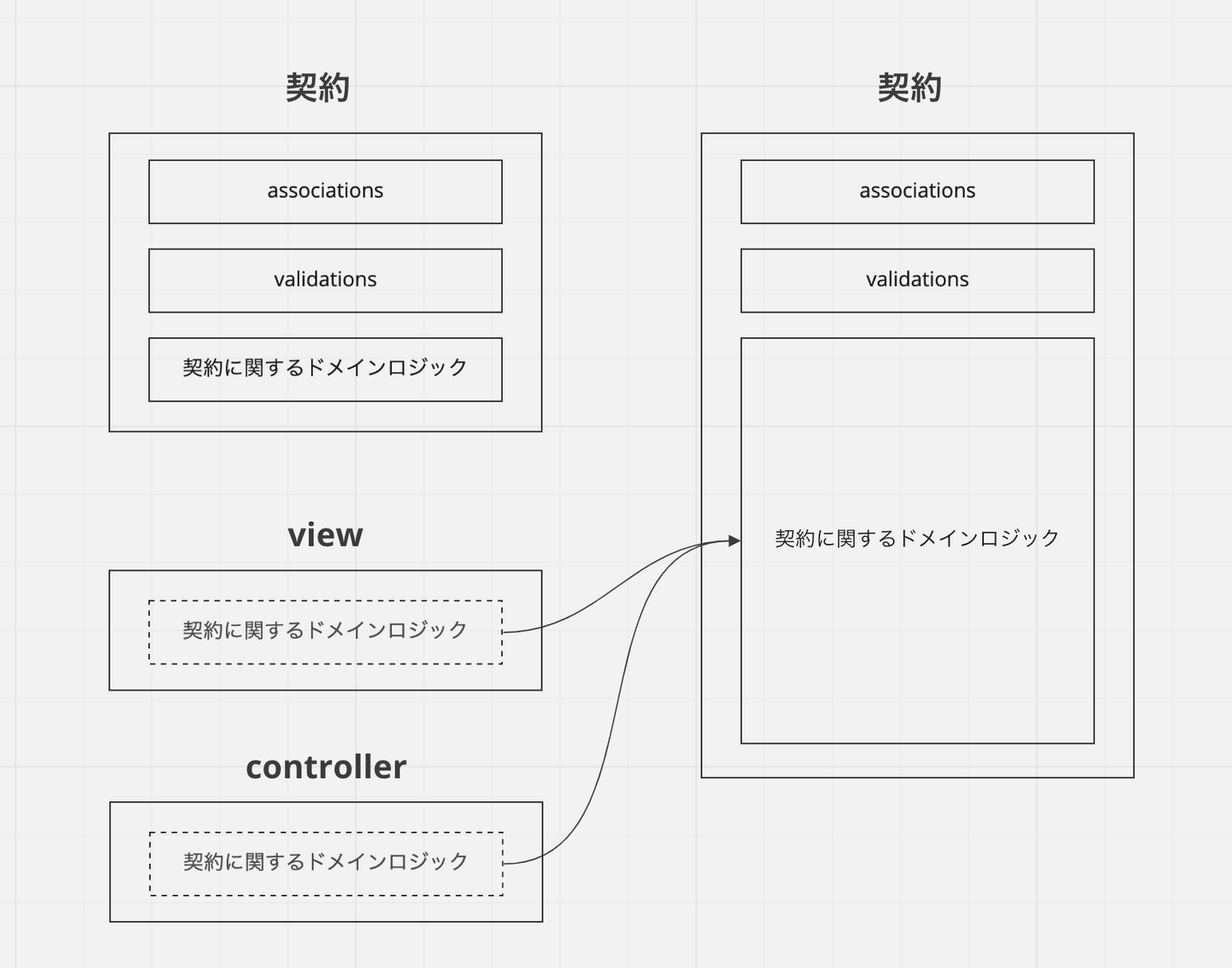
これでめでたしめでたし....では残念ながらありません。責務外の処理を切り出していった結果、実は契約モデルの中身がかなりスカスカだということがわかります。契約というオブジェクトに関するドメインロジックが少ししか書かれていません。
![]()
この現象には名前がついていて、ドメインモデル貧血症と呼ばれます。本来モデルに書かれているべきドメイン知識が、例えば view や controller などの使う側に流れ出てしまっている状態のことです。この状態はモデルがどういう振る舞いをするのかの把握が難しくなるだけでなく、複数箇所でのロジックの重複・不整合などにも繋がります。
そこでドメインロジックをできるだけモデルに戻していきます。具体的には、「総額と月数から月額を計算するロジック」や「期間の変更、自動更新の停止/再開といった契約に対して行えるドメイン操作」、「そうした操作がどういった状態やプランのときに行えるか」などといったロジックです。例えば「自動更新の停止は進行中の状態のときのみ可能で、終了済みやキャンセルされた契約に対しては行えない」といったドメイン知識を view からモデルに移します。
![]()
なお、上のステップでバッチ処理や callback ロジックを切り出していく際も、モデルが持つべき振る舞いまで持ち出してしまわないように慎重に見極めながら行いました。
こういった一連の作業により、モデルに不要なロジックが含まれずにドメインロジックが密度濃く集約され、ドメインオブジェクトとしてより健やかな状態になりました。
その他、使われていない画面やコードを消したり、リファクタリングの過程でテストを拡充したり、といったレガシーシステムに取り組む上でのお決まりの作業も随時行いました。
ドキュメントやコードコメントを増やす
ドキュメントやコード中のコメントもシステムの理解を助け、メンテナンスがしやすくなります。
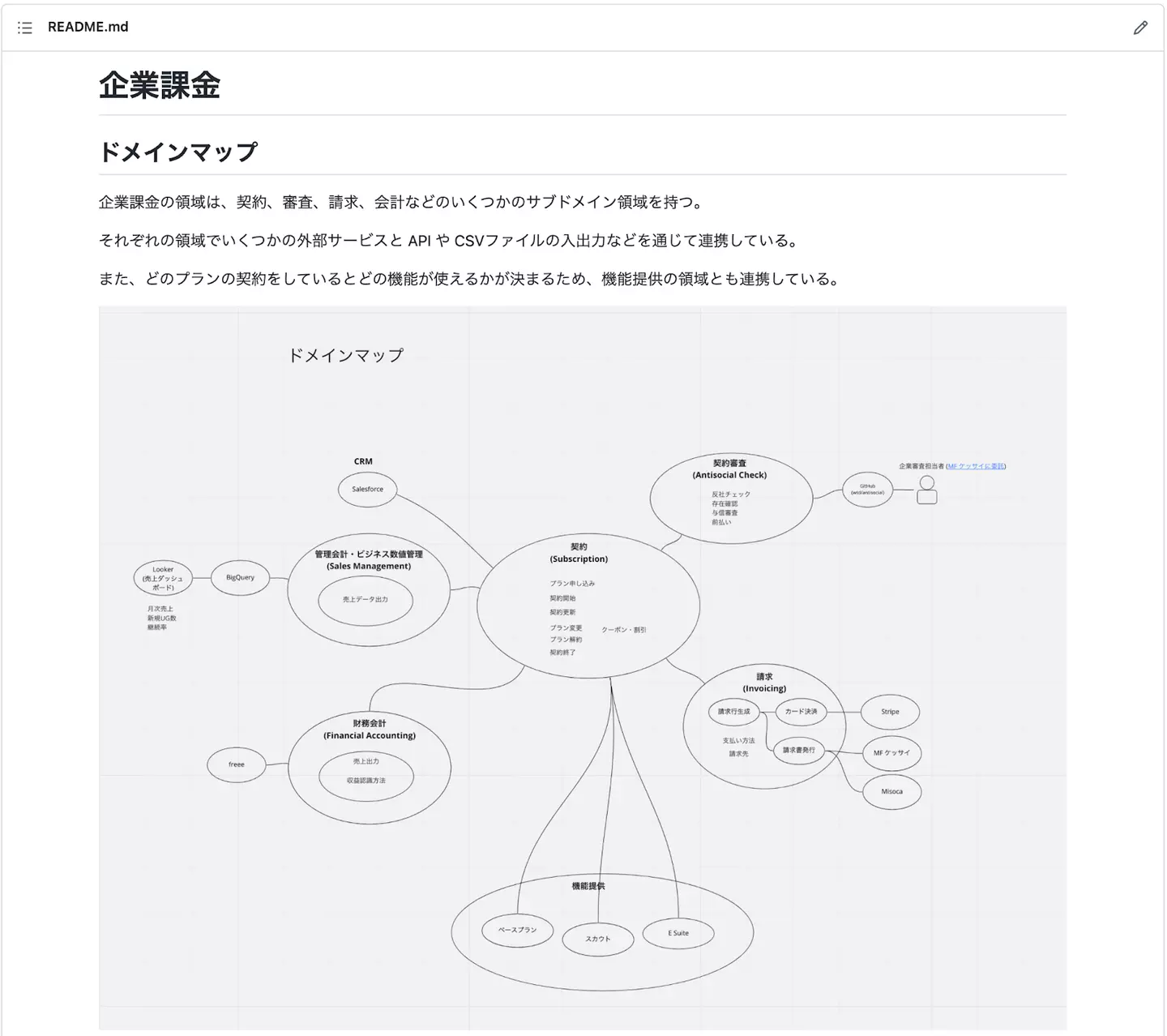
ドキュメントは、まずドメインの概観がつかめるものがあるとよいですね。今回のドメインでは、機能追加で新たに加わった領域も含めて、いくつかのサブドメインが存在したので、入り口としてドメインマップのドキュメントを書きました。
![]()
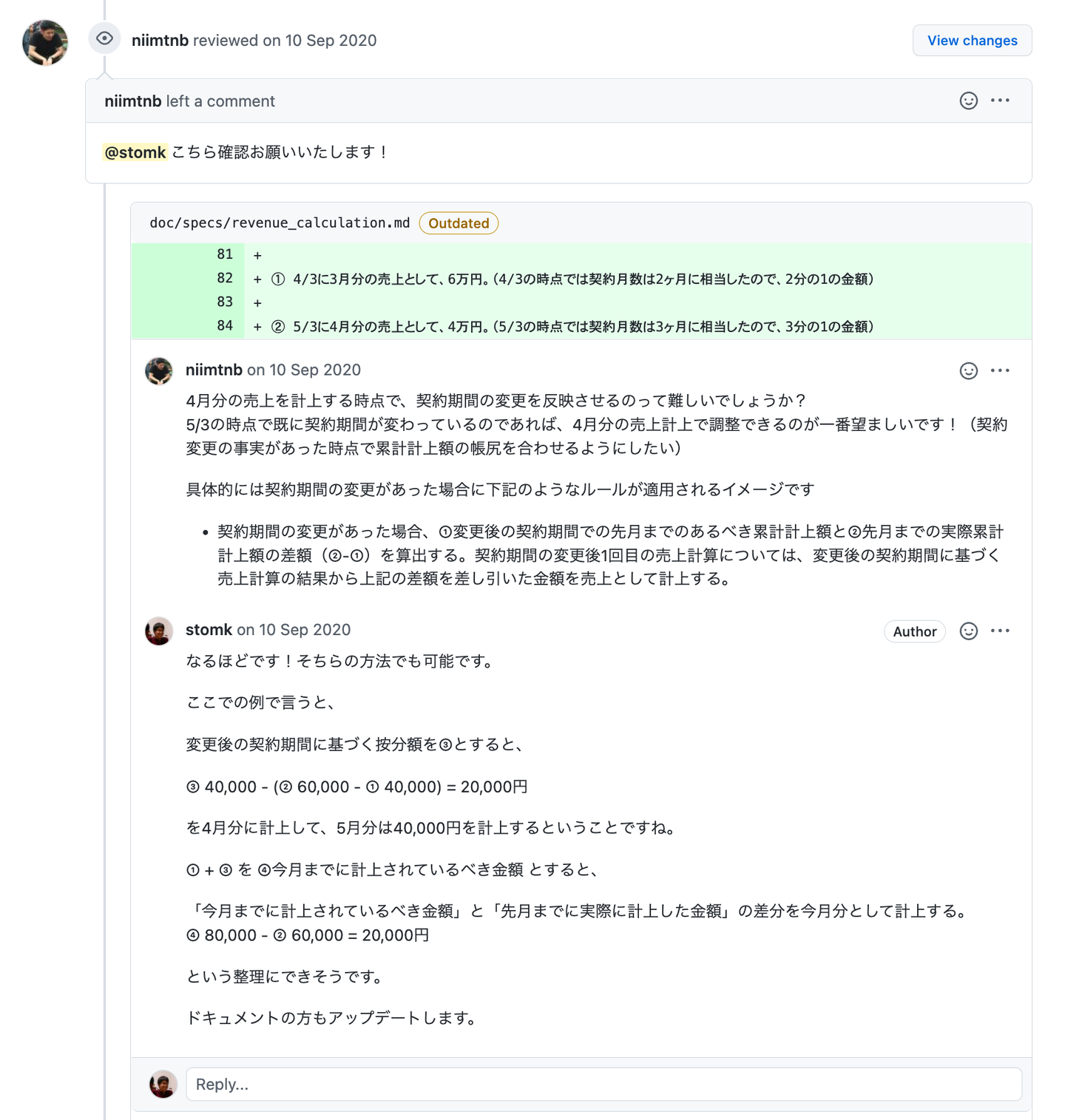
それから、各サブドメインの概要、各機能の仕様、主要モデルの関係図などもドキュメント化していきました。中でも数値計算が関わる部分、例えば今回のプロジェクトで新しく実装した財務会計用の売上データ出力機能では、売上の計算のしかたや出力データの内容について、GitHub でドキュメントを書き、経理メンバーにレビューしてもらいました。こうすることで開発中に仕様を詰めていきながら、同時にドキュメントができあがります。
![]()
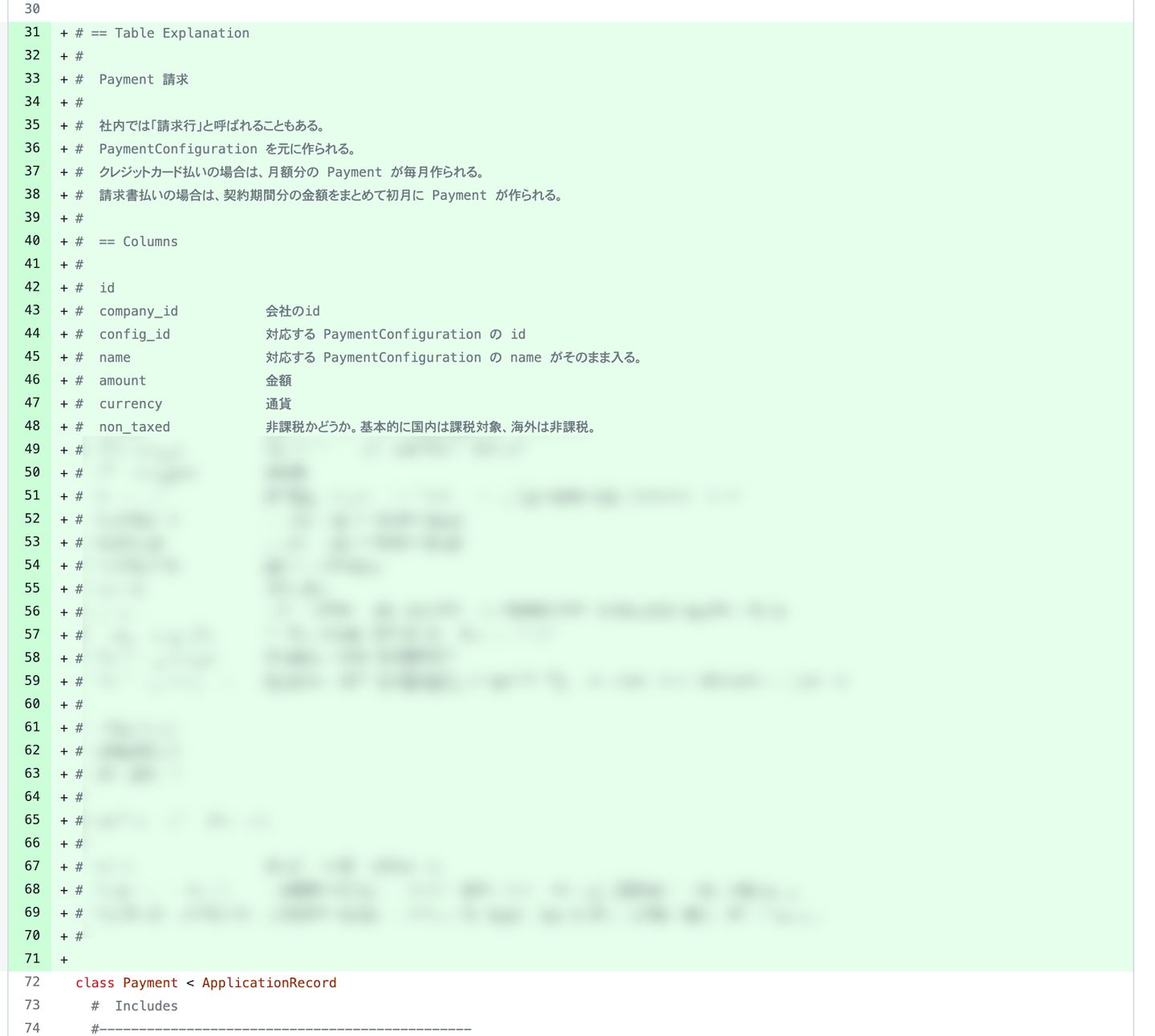
続いてコードコメントですが、プロジェクトの初期に、まず既存システムを理解するために、各モデルの役割やカラムの意味を調べてコメントで書いていきました。これはやってみてとてもいいなと感じたので、以後新しく作るモデルにも同様に書くようにしました。
![]()
また、ロジック部分も既存システムを読み解いていく中で、なんでこうなっているんだろうと思ったところは、理由がわかったらつどコメントを入れていきました。もちろん、新たに実装する部分も、初見でパッとわからないような部分はコメントを書いておきます。このあたりは、今回の領域に限らない一般的な話なので、社内の tech lunch で「コメントをもっと書いていきましょう」という布教活動を行いました。
SaaS に丸投げはできない
以上、複雑なドメインのシステムのリモデリングやメンテナンス性改善の取り組みを見てきました。
実は、今回のプロジェクトの検討段階では、こうしたシステムのメンテナンスコストを今後払わなくてすむようにと Zuora や Stripe などの同じドメインの SaaS に乗せかえることも検討されていましたが、金銭的コストなどの理由で見送られていました。
実際にプロジェクトを通してシステムに向き合ってみると、そこには自分たちのビジネスやオペレーションフロー特有の事情が数多くあることがわかりました。SaaS はこうした自分たちの事情に合わせてテーラーメイドされたものではないため、SaaS を使ったとしてもそこから生まれる複雑さも含めて丸投げできるわけではありません。むしろ SaaS の中のロジックはこちらからはコントロールできない部分があるので、頑張ってつじつまを合わせようとすれば、結果的に自前でシステムを持つよりもメンテナンスが大変になっていたのではないかなと思います。
自分たちのビジネスやオペレーションの事情にしっかりと向き合い、事業の成長に合わせて適切にシステムをメンテナンスしていくことの大切さを強く感じたプロジェクトでした。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)
