今回は Industrial Talks の Netflix のセッションで発表された『A Human Perspective on Algorithmic Similarity』という調査報告について紹介します。 これは Netflix の様々な推薦システムのアルゴリズムでも利用されている「Similarity / 類似性」という概念、つまり、アイテムとアイテムが「似ている」とはどういう意味や状態を表すのかについて調査した結果についての報告発表です。
Netflix は推薦システムの研究開発・実サービスでの応用に大変積極的で、推薦システムのトップカンファレンスである RecSys のスポンサーにも RecSys2010 から今回の RecSys2020 までの11回のうち RecSys2013 を除く(なんでだろ) 10回なっており、論文もたくさん通しています。推薦システムの関するブログなどの発信もたくさんあり私自身普段から大変お世話になっています。Netflix のサービスにおいて推薦システムは大変重要な立ち位置にあり、少し昔のブログでの言及にはなりますが、Netflix の全ての視聴のうち 75% はユーザの能動的な検索活動ではなく、推薦システムによるレコメンドから発生しているとのことです。 ちなみにこのブログで語られている「Everything is a Recommendation」という言葉が私は好きです。
We have adapted our personalization algorithms to this new scenario in such a way that now 75% of what people watch is from some sort of recommendation.
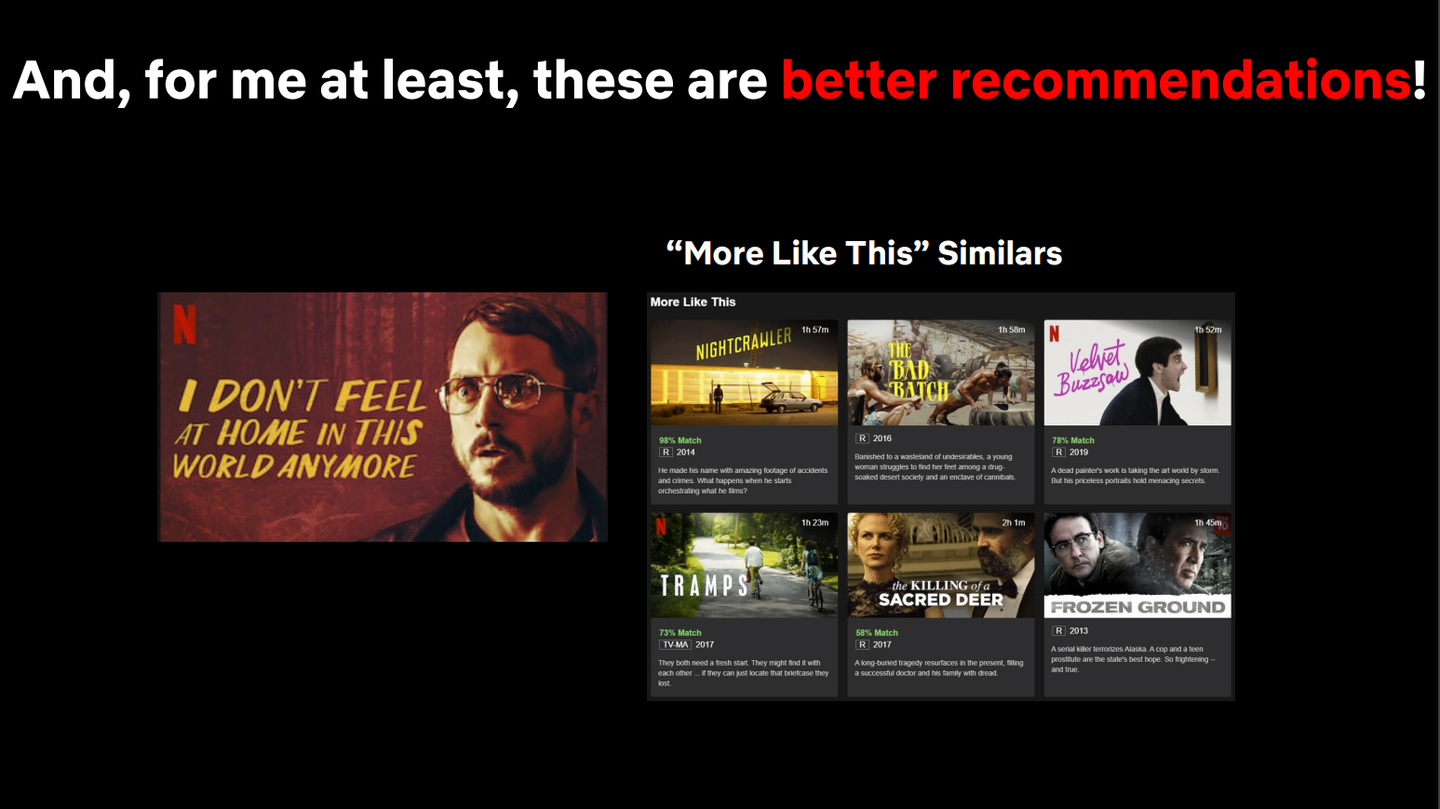
Netflix の叡智を結集した高度なアルゴリズムによってレコメンドされたコンテンツであっても、コンテンツの詳細を確認する限り自分が視聴したいと思えるものではないと何度も拒否をした(視聴しなかった)というスピーカーの原体験から話が始まります。 実際のコンテンツ(I Don't Feel at Home in This World Anymore)を例に出していて面白かったです。(Netflix オリジナルコンテンツだからセーフなのだろう。)
このスピーカーは、説明文を見るだけではよくわらかないコンテンツが他のどんなコンテンツに似ているのかを知るために「More Like This(こちらもオススメ; 特定のコンテンツの詳細の下部に表示されるコンテンツ推薦セクション)」に表示されるコンテンツを見るのが好きらしく(この使い方がそもそも面白いなと思った。ぼくの思ってるより一般的なのかな?)、実際に見てみると、自分が視聴したことのあるものもいくつかあったのだが、それらが元のコンテンツとどのような関係であるのかは分からなかったとのことです。
最終的にウェブでそのコンテンツについて調べてみると面白そうであったため、視聴してみて実際に面白かったからよかったのだが、「More Like This」をよりよいものにするためには、推薦されるコンテンツを見たその瞬間、その人にとって、そのコンテンツが推薦されている理由が分かりやすく、その推薦結果をユーザが信じられるようなコンテンツを推薦するべきだという思いに至ったとのことだ。
そして、スピーカーと同じように、Netflix における「似ている」コンテンツの推薦に対して不満、たとえば、"もっと「似ている」コンテンツを出してほしい(Want more like it)" であったり、 "これがなぜ「似ている」と言われているのかよくわからない(Cannot understand)" であったり、"「似ている」のは分かるが普通すぎる。こんなのは明らかなのでもっと意外性のあるものを教えてほしい。(Want a surprise)" などのような不満を持っている実際のユーザの声がいくつも見られたそうです(Twitter のエゴサ)。
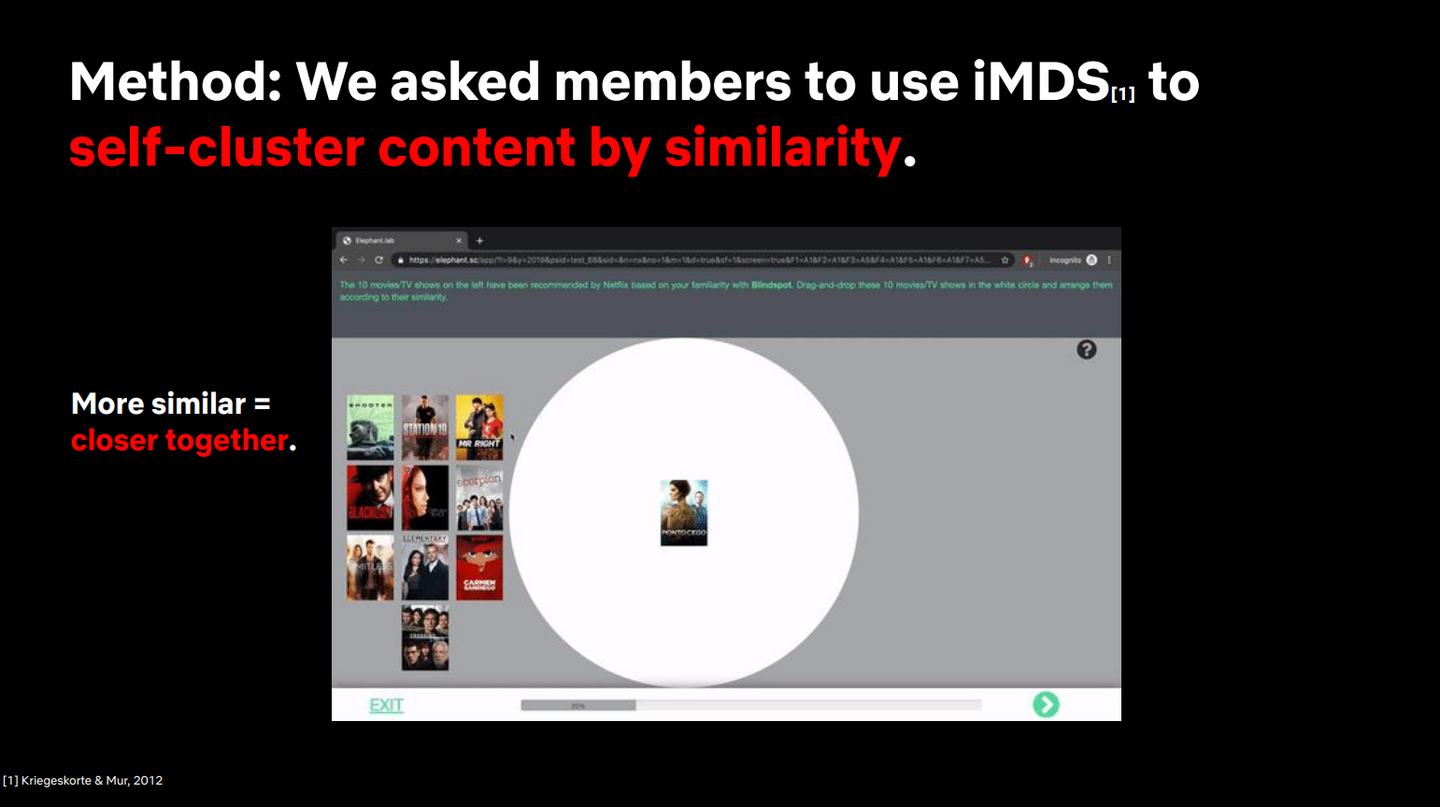
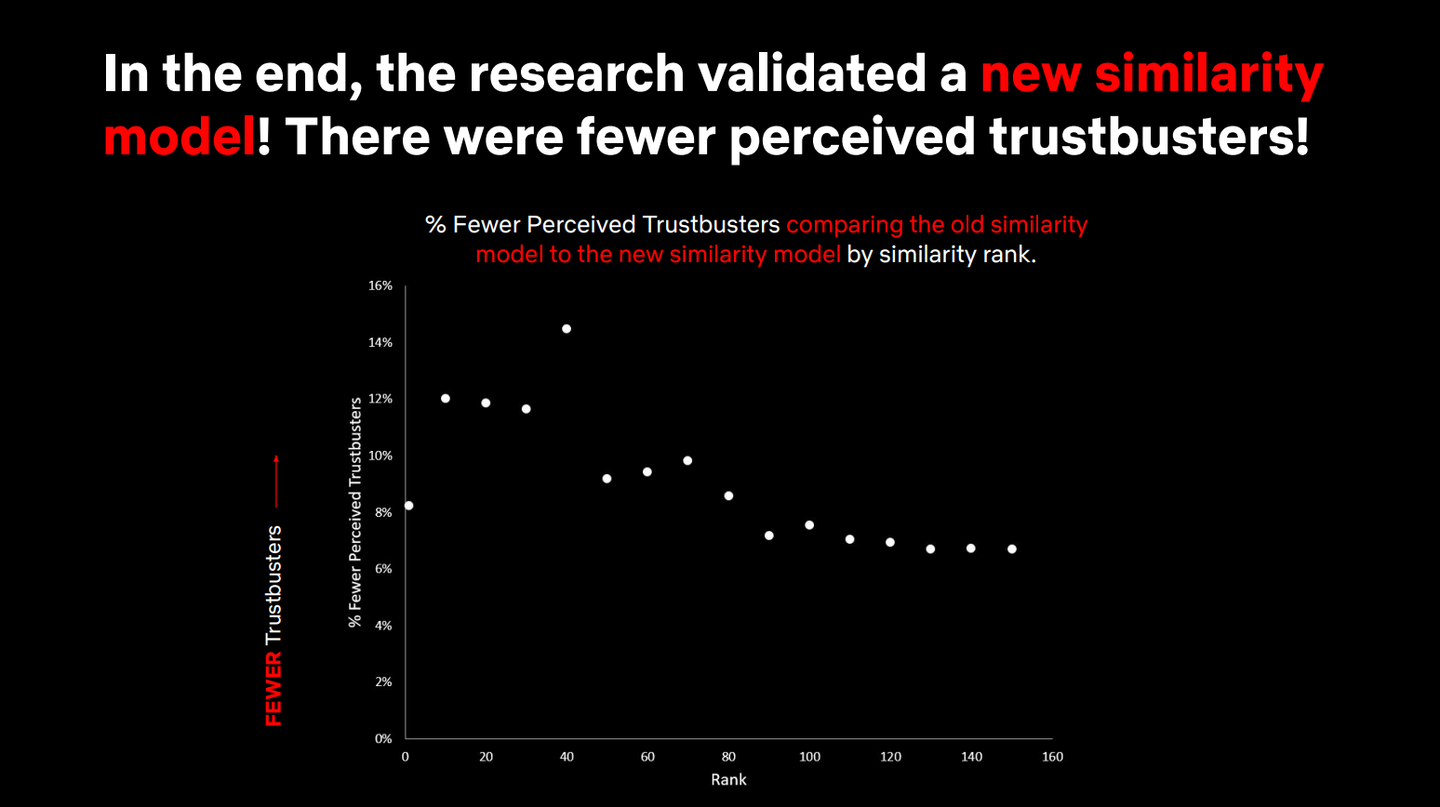
このような経験から、”「類似性」とはいったいなんなのか"という疑問が生まれた。あるコンテンツを説明するためにはどれほど「似ている」コンテンツである必要があるのか。その「似ている」に求められる程度は場合によって変わるのだろうか。「似ている」と「似ていない」の境界線はどこにあるのか。これらの疑問を解消するために、実際に Netflix のユーザ(Netflix は user という表現をあまり使わずにmember とう表現を利用するが、このブログでは特に留意していない。)を対象に調査してみた、というのがこの調査報告の内容となっています。
一方、「specific driver」とは、「Starring Winona Ryder(主演が Winona Ryder)」や「Group of misfit teens in the 80’s(80年代のはみ出しものの若者たちがテーマの作品)」、「nostalgia(懐かしさを感じる)」のように、一部の特定のコンテンツにしか現れないようなそのコンテンツを際立たせる特徴のことです。このような特徴は様々な観点で存在するため種類も豊富であり、推薦システムとしても活用するのが難しいですが、ユーザが満足する可能性も大変高いです。
一方でこのような特徴が一致しているからといって、コンテンツとコンテンツが「似ている」とすべてのユーザが判断するわけではありません。主演が同じだから似ていると判断するユーザもいれば、主演が同じだからといって似ていると感じないユーザもいます。「Group of misfit teens in the 80’s」という特徴はコンテンツの内容をある程度把握していて知識がないと存在にも気づけません。「nostalgia(懐かしさを感じる)」などはかなりユーザの感性に頼った特徴であり、特定のコンテンツに対して「nostalgia」とユーザが感じるかどうかはその人次第です。ユーザが「nostalgia」と感じていないのにも関わらず「nostalgia」という特徴が一致しているからという理由でコンテンツを推薦してしまうと、そのユーザにとっては推薦を大きく外しているように感じられてしまい、推薦システムへの信頼性を失ってしまう恐れがあります。
たとえば、「nostalgia」という特徴に基づいた推薦がハマってコンテンツを「A -> B -> C」と視聴しているユーザに対して、突然「主演」という特徴が一致しているという理由で全く「nostalgia」でないけど主演が C と同じである D というコンテンツを推薦しても(たとえそのユーザにとって普段は「主演が一致している」という特徴が重要であったとしても)、そのユーザは C と D を「似ている」(というよりも視聴したい)と思わずその推薦は失敗に終わってしまうでしょう。このように、ユーザがまさに今サービス内でどのような観点でコンテンツを視聴しているかという状況によっても「類似性」への認識が変化してしまいます。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)










/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)



/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)
