
ウォンテッドリーの Infra Squad に所属している巨畠です。
ある日、社内のURLロギングサービスのDBでレイテンシが急増する事象に遭遇しました。 レイテンシの悪化と聞くと(アプリケーション開発の場合は特に)「重いクエリがあるのかな?」「インデックスが効いていない?」と実装を疑ってしまいますが、今回の問題はそこではありませんでした。
この記事では、どうやって問題となっている状況を理解したのか、そしてなぜ「ハードウェア(インフラ設定)で解決する」判断をしたのかについて共有したいと思います。アプリケーション開発者の方々に向けて、課題の理解・解決のための「インフラ視点」を提供できれば幸いです。
目次
link-tracker とは
メール配信時に発生したレイテンシ増大
原因の深堀り:レイテンシのパターン
レイテンシ増大の真因:Burst Balance の枯渇
Burst Balance とは
問題の発生メカニズム
対策:ストレージを gp2 から gp3 へ変更する
まとめ
link-tracker とは
今回問題が発生したのは、社内で開発・運用している link-tracker というシステムです。データストアとして Amazon Dynamodb と Amazon RDS を使っています。以降、この記事では RDS を対象としています。
link-tracker は、マーケティングメール等に含まれるURLのアクセス状況を追跡するためのシステムです。 メール配信システムから送信されるメール本文内のURLは、一度 link-tracker を経由するように変換されます。ユーザーがこれを開封またはクリックすると、link-tracker がリクエストを受け付け、アクセスログを記録した上で本来のURLへリダイレクトします。
追跡用のリンクはメール配信時に作成されます。配信先ごとにリンクを発行するため、メール配信時には Write 操作が多くなる傾向にあります。また、データ転送のためのジョブが実行されるため Read 操作が多い傾向にあります。
メール配信時に発生したレイテンシ増大
2024年12月に利用規約および表記規程の改定を周知するメールを配信しました。その際、link-tracker のレイテンシが著しく増大する事象が発生しました。以下の画像は問題発生当時の Watchdog のアラートです。
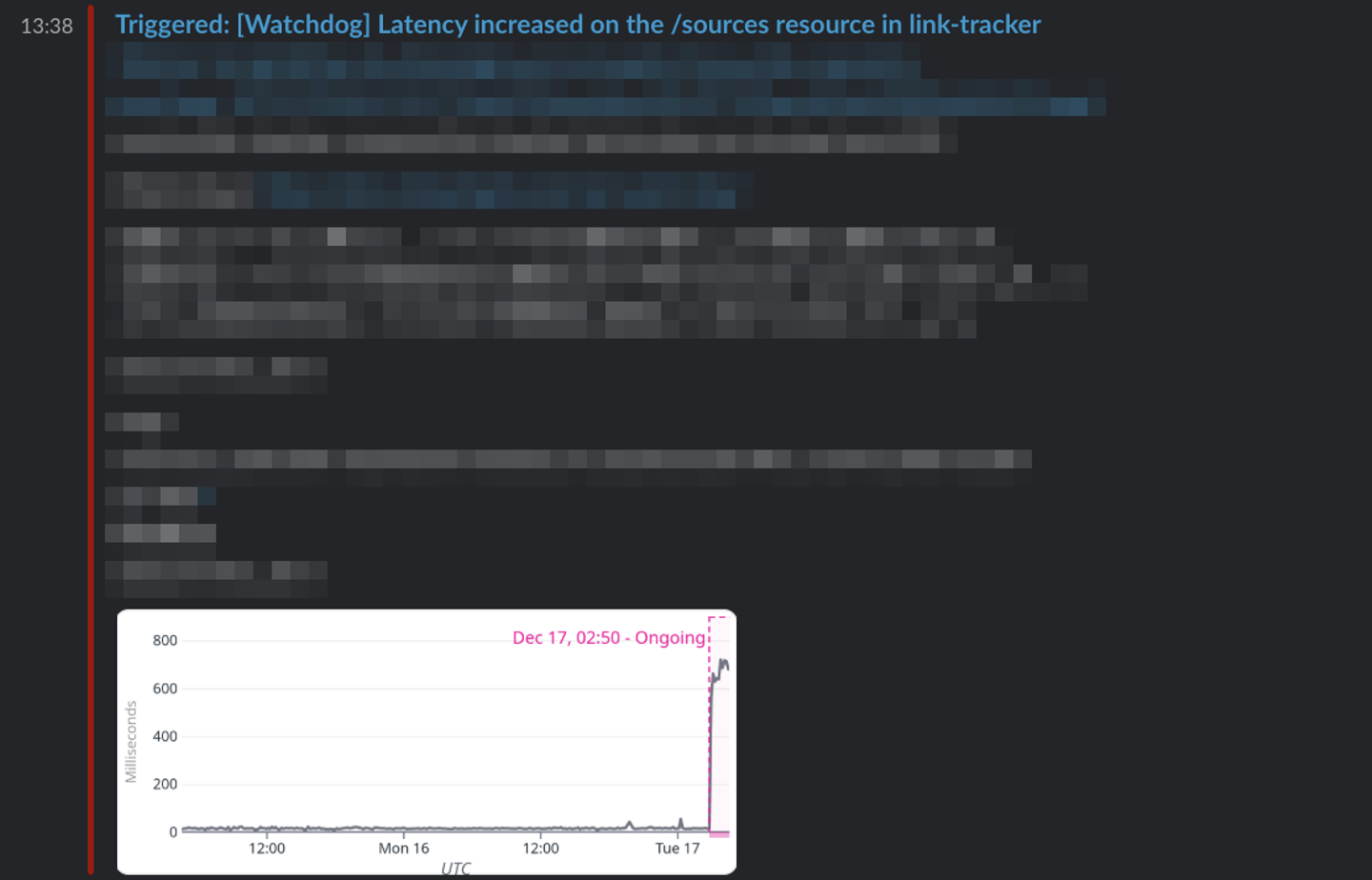
調査の結果、ボトルネックはデータベース(DB)にあることが判明しました。DBの負荷が高まったことで Write 処理が詰まり、システム全体の応答速度が低下していました。遅延は一時的なものでありメール配信自体は完了できたため、当時は静観という判断を下しました。
しかし、その後 2025年4月22日の配信時にも同様の現象が再発したため本格的な調査と対策に乗り出しました。
原因の深堀り:レイテンシのパターン
まず、Datadogを用いてDBのリソース状況を確認しました。CPU利用率やコネクション数の上昇に加え、Write レイテンシが顕著に増大していることが確認できました。
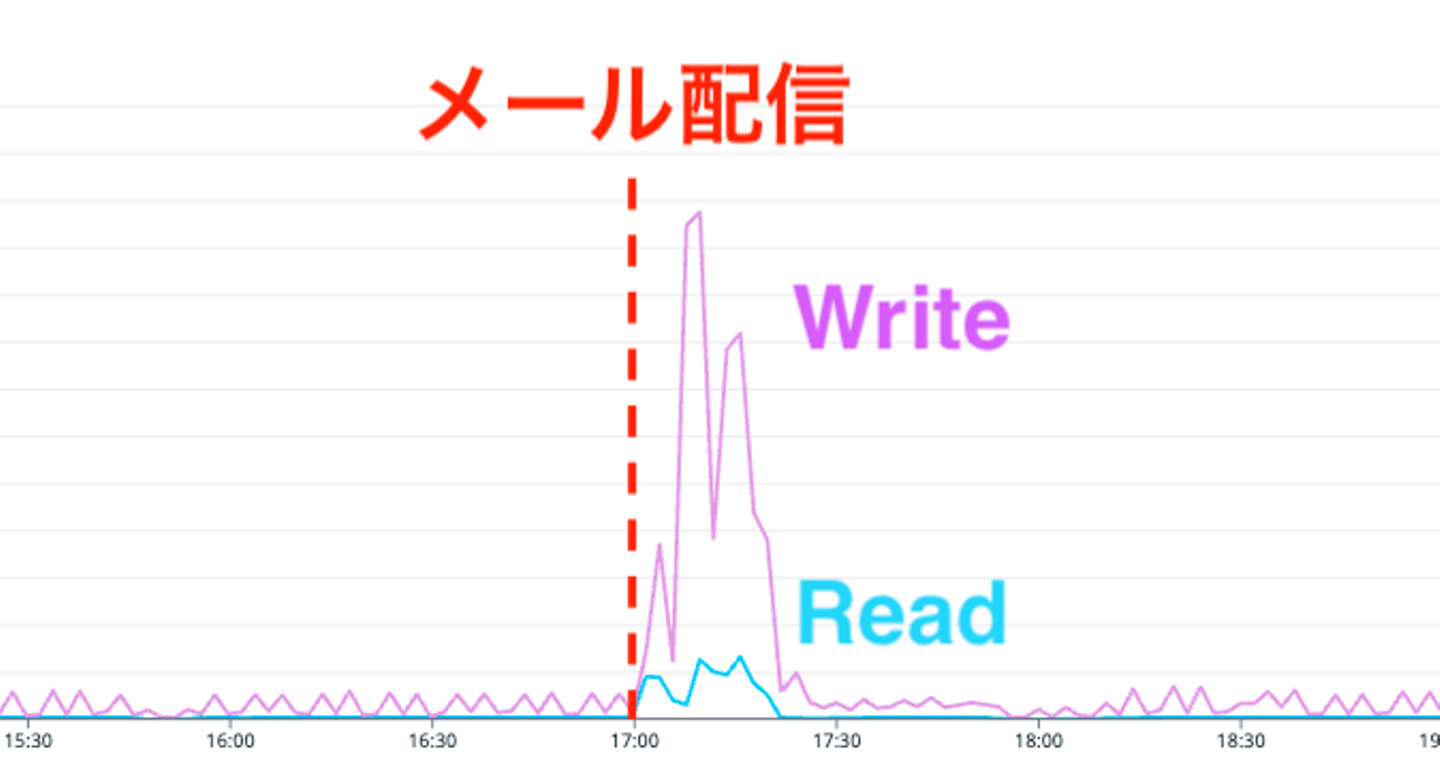
また「EBS IO オペレーション」というメトリクス(定量指標)を確認したところ、Read IOPS と Write IOPS がほぼ完全に一致した状態で推移していました。これは想定されるワークロードとは異なるメトリクスの推移となっていることを示しています。通常、リンクにアクセスする際にはログを記録するため Write が多くなるはずです。また、レイテンシ悪化時には Write の IOPS が低下していることが見て取れます。
レイテンシ増大の真因:Burst Balance の枯渇
前述したメトリクスを分析したところ原因は EBS(Elastic Block Store)の Burst Balance の枯渇 であると分かりました。
Burst Balance とは
Amazon RDS(およびEC2)で汎用SSD(gp2)を使用する場合、ストレージ性能には「ベースライン性能」と「バースト性能」という概念が存在します。
- ベースライン性能: ストレージ容量に応じて割り当てられる定常的なIOPS
- バースト性能: 一時的にベースラインを超えてスパイク可能なIOPS(最大3,000 IOPS)
- Burst Balance: バースト可能な「クレジット」の残量。ベースライン以下の使用時に蓄積され、バースト時に消費されます
問題の発生メカニズム
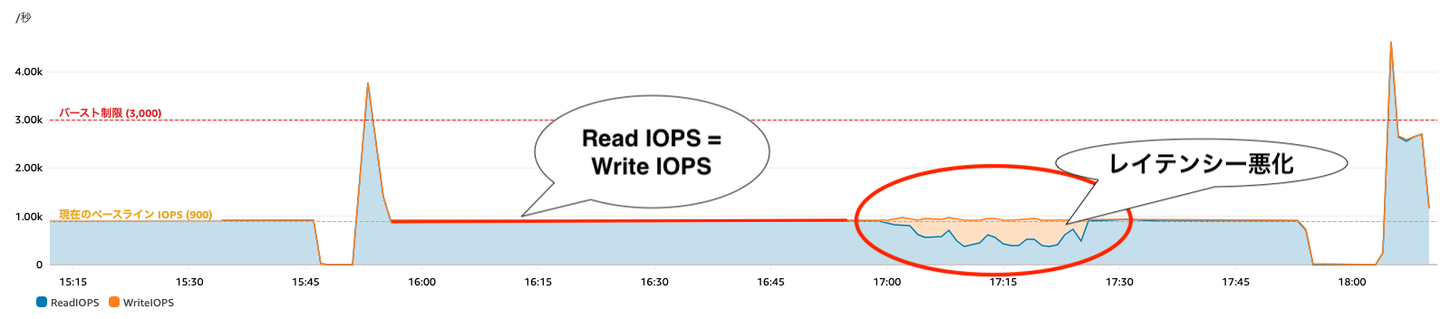
今回のシステムで使用していたDBストレージは、ベースライン性能が 900 IOPS でした。メトリクスの傾向から問題発生のシナリオは次のようになっているのではないかと思われます。
- バッチ処理によるReadスパイク
- 大量メール配信に伴うバッチ処理が走り、短時間に大量のReadリクエストが発生する
- クレジットの急速な消費
- ベースライン(900 IOPS)を遥かに超える負荷がかかり、最大3,000 IOPSのバーストモードで処理を続行する
- Burst Balance 枯渇
- バーストクレジットが一瞬で枯渇してしまう
- IOPS制限
- クレジットが尽きたため、ストレージ性能がベースラインの900 IOPSに強制的に制限される
- メール配信による Write 操作の増加
- 限られた帯域を Read と Write 処理が取り合う状態となりレイテンシが増大した
「EBS IO オペレーション」のメトリクスで見られた「ReadとWriteが一致している」「レイテンシ悪化時には Write の IOPS が低下」する現象は、IOPSの上限に張り付いた状態で、ReadとWriteが少ないIOPSを奪い合っていたものと分かりました。
対策:ストレージを gp2 から gp3 へ変更する
対策として以下の3案を検討しました。
- クエリチューニング: アプリケーションコードやSQLを修正する。
- デメリット: 工数がかかり、直近のメール配信予定に間に合わない。
- DBエンジンの変更(DynamoDB等への移行):
- デメリット: データモデルの設計変更や移行作業に多大な時間がかかる。
- ストレージのアップグレード: gp2からgp3へ移行し、スループットを増強する。
今回は、コスト、工数、即効性の観点から 「3. ストレージのアップグレード(gp2 から gp3 への移行)」 を選択しました。主なメリットは次の通りです。
- バースト概念の廃止と性能の安定化
- gp3 はベースライン性能を個別にプロビジョニングできるため、gp2 のような「クレジット枯渇による急激な性能低下」が発生しない
- 容量を変えずにIOPSを増強
- gp3 では容量と性能が切り離されているためストレージサイズはそのままで、IOPSのみを従来のベースライン 900 IOPS から 3,000 IOPS へと引き上げられる
- コスト
- 東京リージョンにおいて、gp3 は gp2 と同等以下のコストで利用可能
- 移行時のダウンタイム
- インスタンスを停止せずに変更することができる
移行は AWS のコンソールから実施することができますが、 Terraform でリソースを管理していたので Terraform で実施しました。storage_type を gp3 に変更し、apply_immediately を設定した上で適用します。
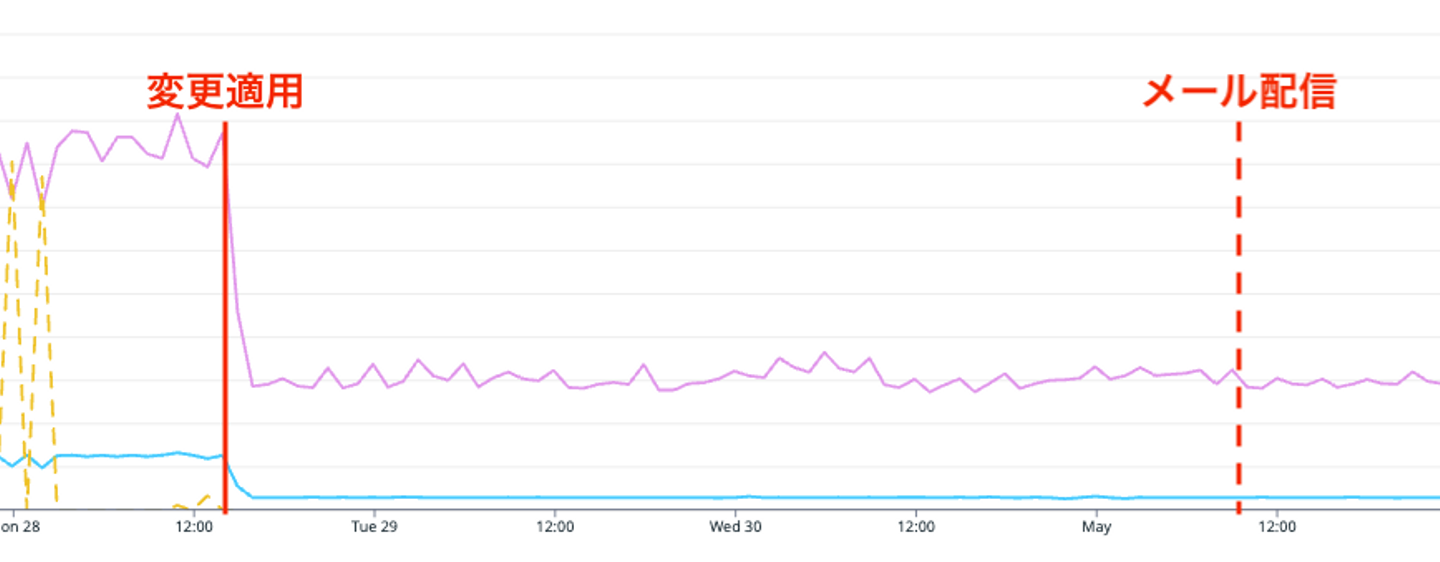
適用後に行われた「Real Wantedly」集客メールの配信において効果を確認しました。結果として、以前のようなレイテンシの増大は発生せず、スムーズに配信が完了しました。メトリクスを見ても Read/Write ともに安定して推移していることが分かります。
まとめ
今回の調査を通して改めて感じたのは、「想定されるワークロードと、実際のメトリクスの動きの乖離」に気づくことの重要性です。
「このタイミングでは大量にINSERTが走るはず」「裏でバッチが回っているはず」といったアプリケーションの挙動(ワークロード)は、普段コードを書いている開発者が一番よく理解しています。 だからこそ、メトリクスを見たときに違和感を持つことができます。これはインフラ専任者だけでなく、アプリケーション開発者だからこそ気づける視点でもあります。
また、「ハードウェア(インフラ設定)で解決する」という選択肢を積極的に取っていいなと感じました。 コードチューニングで粘るのも手ですが、gp2 から gp3 への変更のように、設定変更だけで早く・安く解決できるならそれに越したことはありません。
メトリクスは決してインフラエンジニアだけのものではありません。 ぜひ、日頃からプロダクトやインフラのメトリクスを眺めることを習慣にしてみてください。コードを書くだけでは見えてこない、システムの「本当の姿」が見えてくるはずです。
/assets/images/5673658/original/767e046d-422d-44e3-ac17-74af4a96146e?1709547072)

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


