-Qiita記事Part.10-【Python】位置情報解析ライブラリscikit-mobilityについて② ~前処理編・前編~

こんにちは、ナイトレイインターン生の田中です。
Wantedlyをご覧の方に、ナイトレイのエンジニアがどのようなことをしているか知っていただきたく、Qiitaに公開している記事をストーリーに載せています。
少しでも私たちに興味を持ってくれた方は下に表示される募集記事もご覧ください↓↓
1. scikit-mobilityとは?
scikit-mobilityは位置情報データを使用して人の動きを解析したり、可視化することができるpythonライブラリです。
公式ドキュメント:https://scikit-mobility.github.io/scikit-mobility/index.html
GitHub:https://github.com/scikit-mobility/scikit-mobility
公式ドキュメントは英語しかありませんが結構充実していて、
GitHubにはチュートリアル等も載っているので試してみるのがおすすめです。
scikit-mobilityの主な機能と、チュートリアルについて解説しているQiitaもありますのでこちらも是非参考にしてください。
2. 今回紹介する関数について
カテゴリ:preprocessing(前処理)
preprocessing(前処理)に分類される関数には、以下の二種類の関数があります。
- 生の緯度経度データを解析、加工がしやすいように不要なデータを削除したり、データ量を減らす処理を行うことができる関数
- ある程度同じ条件下にあるデータをクラス分けすることができる関数
今回はpreprocessing(前処理)で用意された4つの関数のうち、
1. 生の緯度経度データを解析、加工がしやすいように不要なデータを削除したり、データ量を減らす処理を行うことができる関数
に該当する2つの関数をコードを交えて紹介します。
紹介する関数
- filtering.filter:ノイズ、または外れ値とみなされるデータポイントを削除する関数
- compression.compress:近くにあるデータポイントを一つの点にまとめてデータポイント数を減らす関数
※ 今回この記事で使用するデータは社内検証用のデータになります。
3. 前提処理
ライブラリのインストール
$ pip install scikit-mobility
詳しい環境構築はこちらを参考にしてください
TrajDataFrameデータの作成
- 以下の項目を含むデータを用意します。
latitude(type: float); 緯度(必須)
longitude (type: float); 経度(必須)
datetime (type: date-time); 日時(必須)
uid (type: string);(オプション)
tid (type: string); (オプション)
特に使いたいデータがない場合はscikit-mobilityのチュートリアルを参考にこちらのデータをダウンロードするといいと思います。
※自動でデータがダウンロードされるので気をつけてください
# ファイルのダウンロード(google colab等で実行する場合はこうすると楽です。)
import urllib.request
url='https://raw.githubusercontent.com/scikit-mobility/scikit-mobility/master/examples/geolife_sample.txt.gz'
save_name='geolife_sample.txt.gz'
urllib.request.urlretrieve(url, save_name)
- 用意したデータをTrajDataFrameに変換します。
import skmob
# リストをTrajDataFrameに変換する場合
tdf = skmob.TrajDataFrame(data_list, latitude=1, longitude=2, datetime=3)
# pandas.DataFrameをTrajDataFrameに変換する場合
tdf = skmob.TrajDataFrame(data_df, latitude='latitude', datetime='hour', user_id='user')
4. preprocessing(前処理)について
参考URL:https://scikit-mobility.github.io/scikit-mobility/reference/preprocessing.html
概要
データ解析をしやすくするための前処理を行うことができる関数
filtering.filter(フィルタ処理)関数
概要
ノイズ、または外れ値とみなされるデータポイントを削除する関数です。
外れ値とみなされるデータの閾値はデータポイント間の移動速度で決めることができます。
inputに必要なデータとパラメータ、outputされるデータ
- inputデータ
- tdf(TrajDataFrame) :緯度経度データ
- tdf(TrajDataFrame) :緯度経度データ
- パラメータ
- max_speed_kmh(default: 500km/h):前のポイントからの速度(km/h)がこの値よりも高い場合は、外れ値としてポイントを削除
- include_loops(default:False):Trueの場合、短くて早いループに属するデータポイントが削除される
- speed(default:5km/h):include_loops処理に使う
- max_loop(default:6):include_loops処理に使う
- ratio_max(default:0.25):include_loops処理に使う
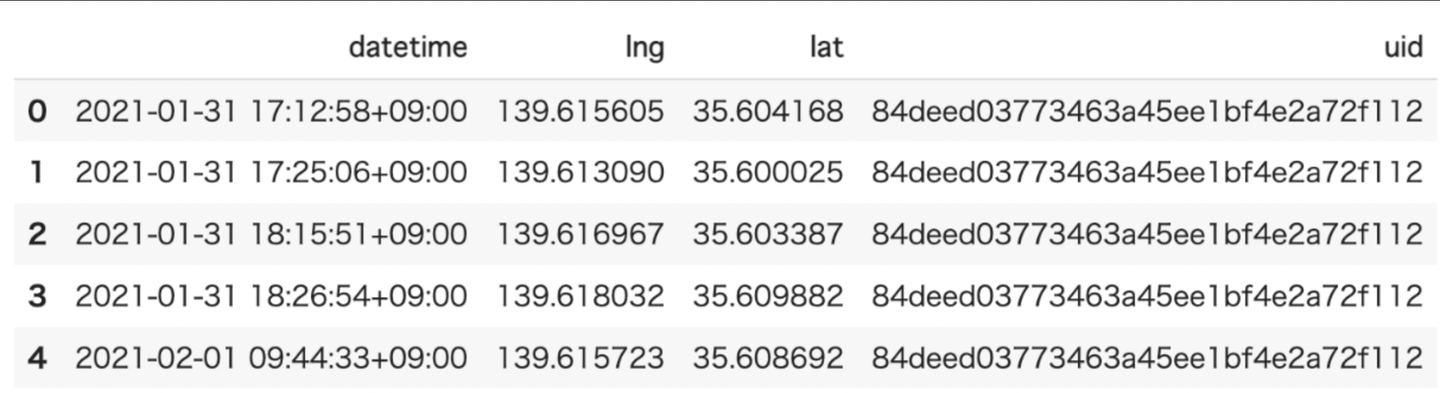
- inputデータ例:
inputデータはTrajDataFrameを使うことができます。
みてみるとこんな感じになります。
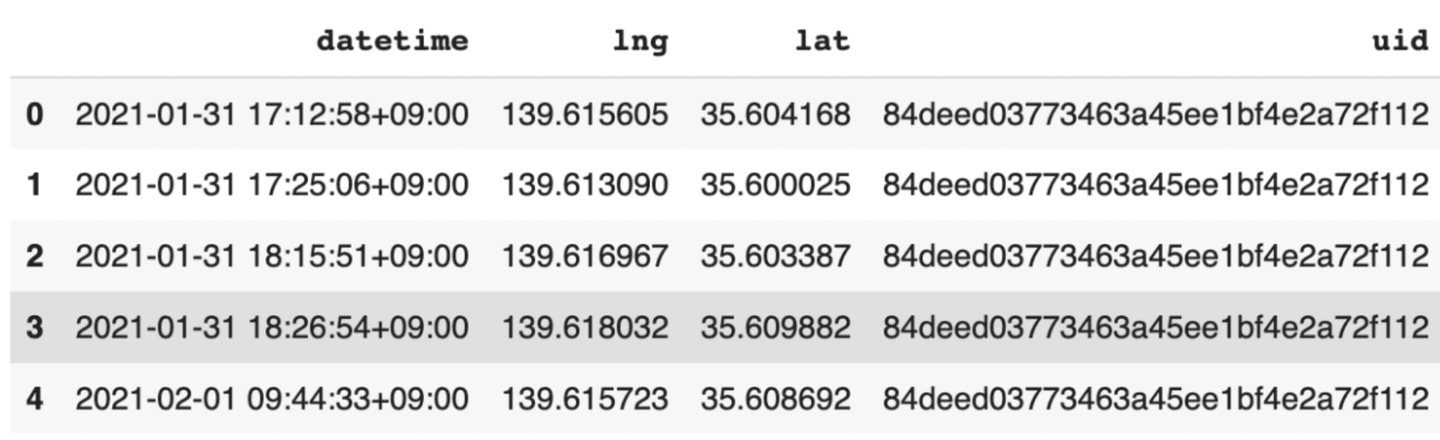
- outputデータ例
フィルタ処理で除外されたデータポイントのないTrajDataFrameが出力されます。
カラム的には特に変化はないですね。
コード例
from skmob.preprocessing import filtering
filtered_tdf = filtering.filter(tdf, max_speed_kmh=1000)
前データポイントからの速さ(km/h)がmax_speed_kmhの引数で指定した値よりも高い場合は、外れ値としてポイントを削除する処理を行ってくれます。
上記のコードの場合は、1000km/h以上の速さで移動していた場合のデータは削除される
という感じになります。
何も指定しなかった場合はデフォルトの500km/hを基準に処理されます。
処理前と処理後のデータポイントを比較してみる
- インプットデータ:
- 特定のユーザーの緯度経度データ(以降元データとする)
- 特定のユーザーの緯度経度データ(以降元データとする)
- アウトプットデータ:
- 元データに対し、max_speed_kmh=500(デフォルト)でfiltering.filter処理を行なった後のtdfデータ
- 元データに対し、max_speed_kmh=500(デフォルト)でfiltering.filter処理を行なった後のtdfデータ
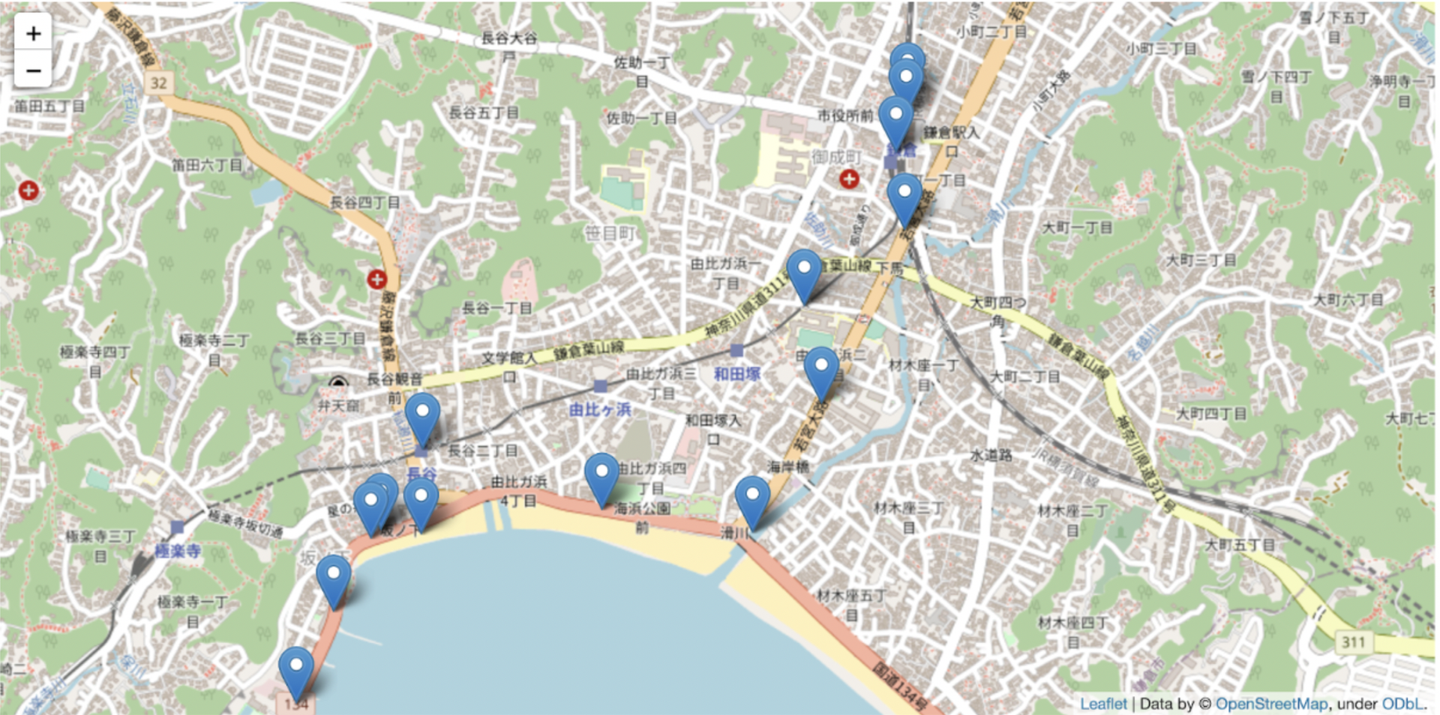
- 元データをマッピングし、一部拡大した図
- アウトプットデータをプロットし、一部を拡大した図
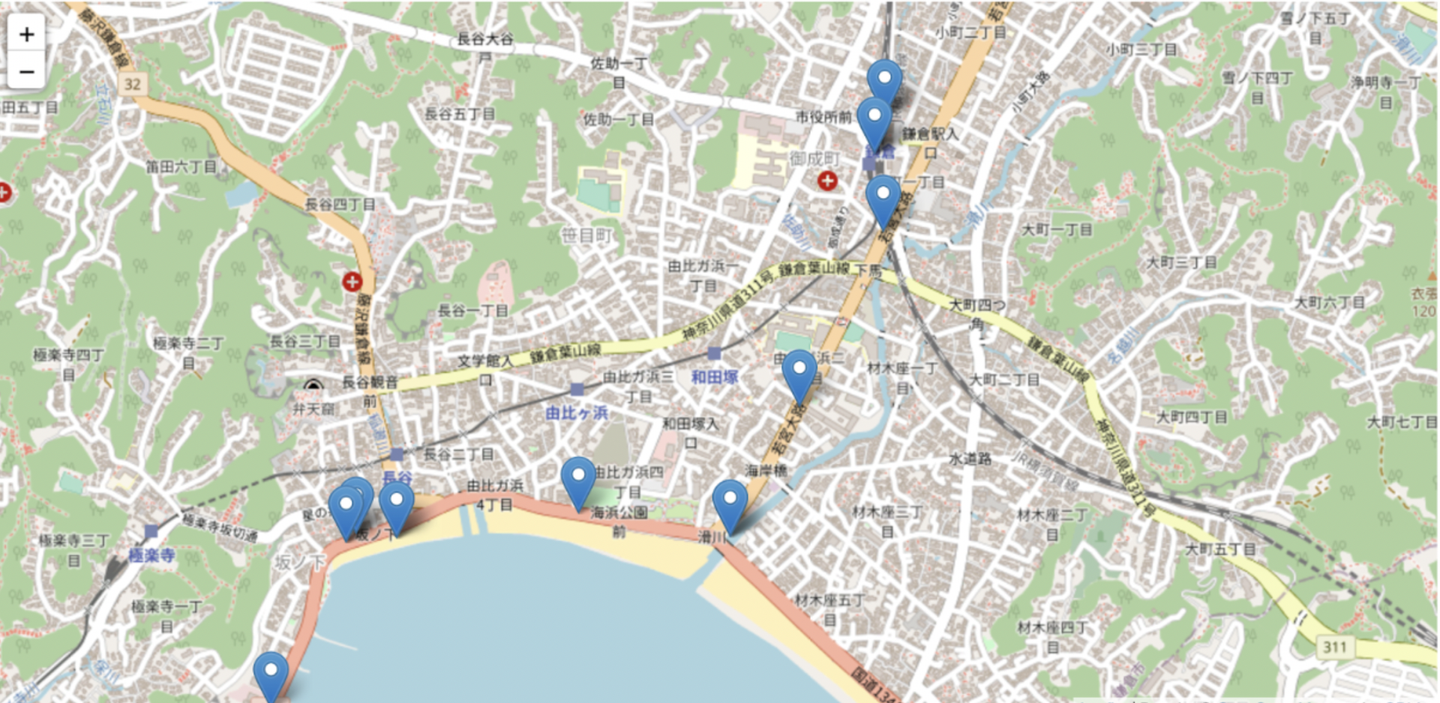
- 少し外れた位置にあるデータが削除されているのが確認できます。
パラメータの変化による出力結果の違いを見てみる。
- inputデータとして全体のデータを入れた場合
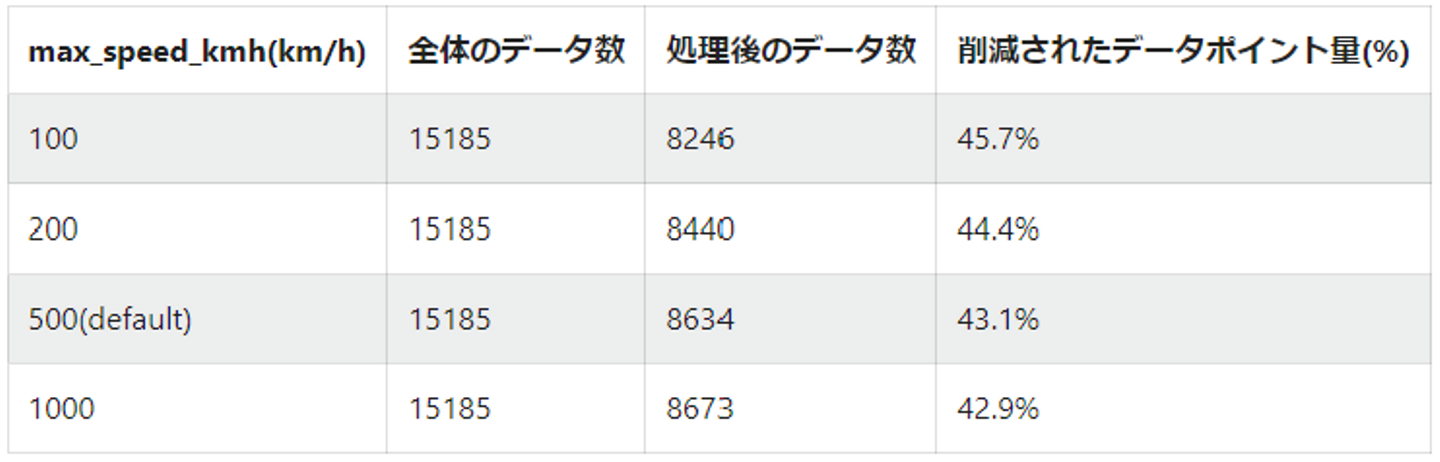
- デフォルトで処理をしても40%程度のデータ削減を行うことができるようです。
- inputデータとして特定ユーザーのデータを入れた場合
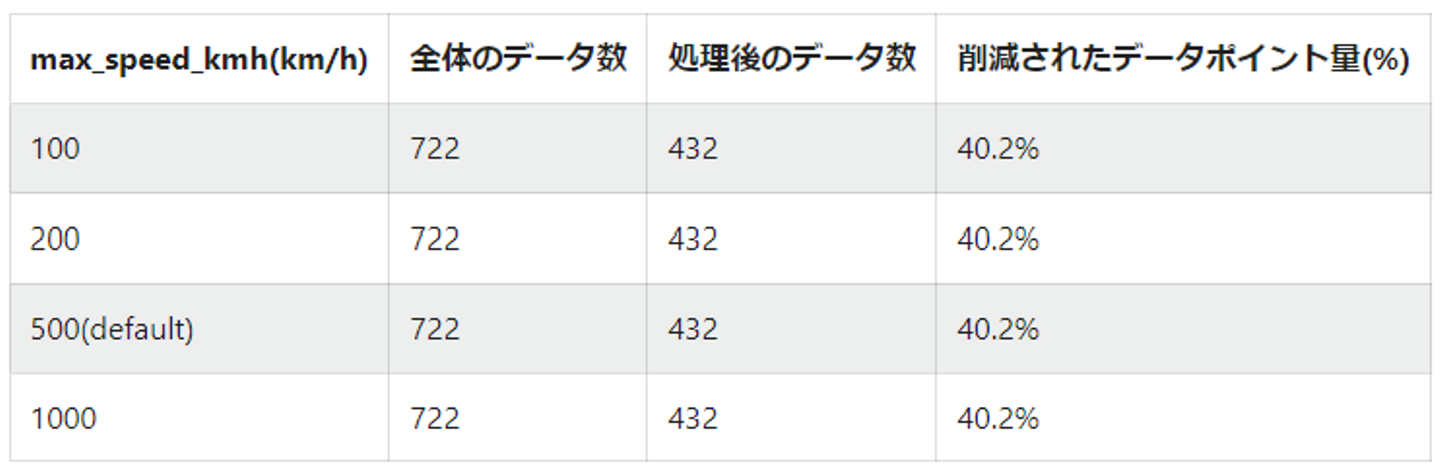
→データ数が少ないせいか、max_speed_kmh をデフォルトから変更してもパラメータごとにデータ数は変化しませんでした。
compression.compress(軌道圧縮処理)
概要
データポイント数を減らすための関数(軌道圧縮)。
与えられた初期点から指定した半径(km)内の全ての点を全ての点の中央座標と初期点の時刻を持つ単一の点に圧縮することができる関数。
inputに必要なデータとパラメータ、outputされるデータ
- inputデータtdf(TrajDataFrame):
- 緯度経度データ
- 緯度経度データ
- パラメータ
- Spatial_radius_km(default:0.2km): 圧縮された軌道の連続するポイントかんの最小距離(km単位)
- Spatial_radius_km(default:0.2km): 圧縮された軌道の連続するポイントかんの最小距離(km単位)
- inputデータ例:
inputデータはTrajDataFrameを使うことができます。
みてみるとこんな感じになります。
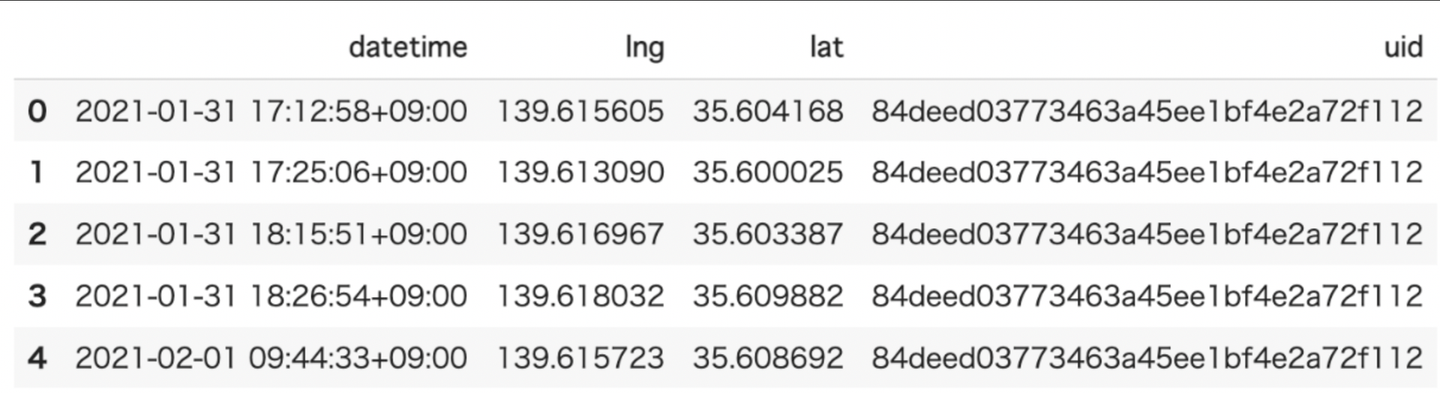
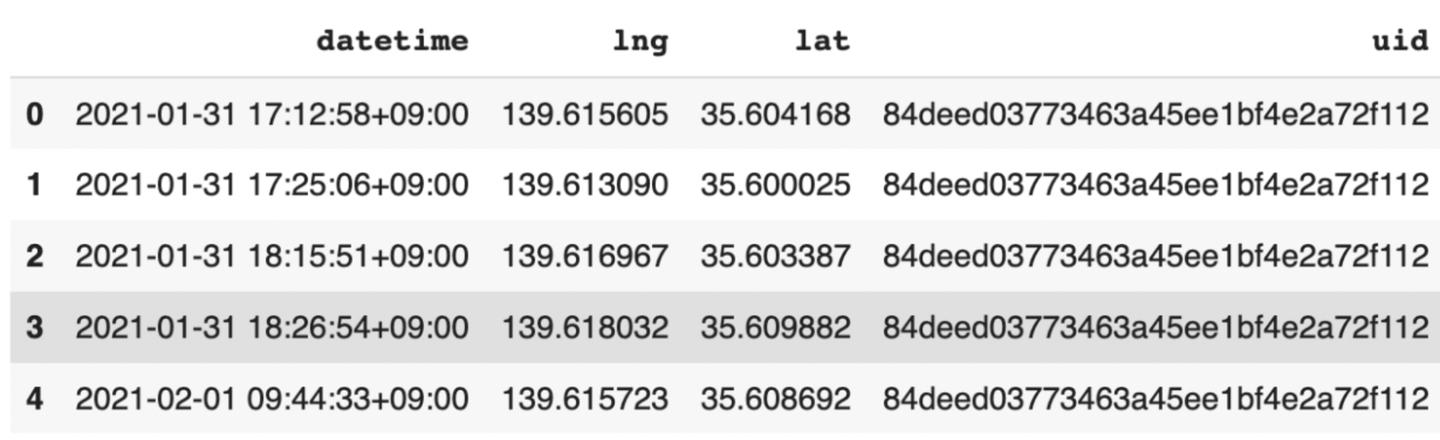
- Outputデータ:データポイントが圧縮されたTrajDataFrameが出力されます。
Outputデータ例は以下のような感じです。カラムはinputデータと特に変わらないです。
コード例
from skmob.preprocessing import compression
# spatial_radius_kmがdefault(0.2km)の場合
ctdf = compression.compress(tdf)
# spatial_radius_km(0.5km)を指定する場合
ctdf = compression.compress(tdf, spatial_radius_km=0.5)
軌道圧縮前と軌道圧縮後のデータポイントを可視化して比較
- インプットデータ:特定のユーザーの緯度経度データ(以降元データとする)
- アウトプットデータ:元データに対し、パラメータspatial_radius_km=1.0(km)でcompression.compress関数を使って軌道圧縮処理を行なった後のtdfデータ
- 元データをマッピングし、一部拡大した図
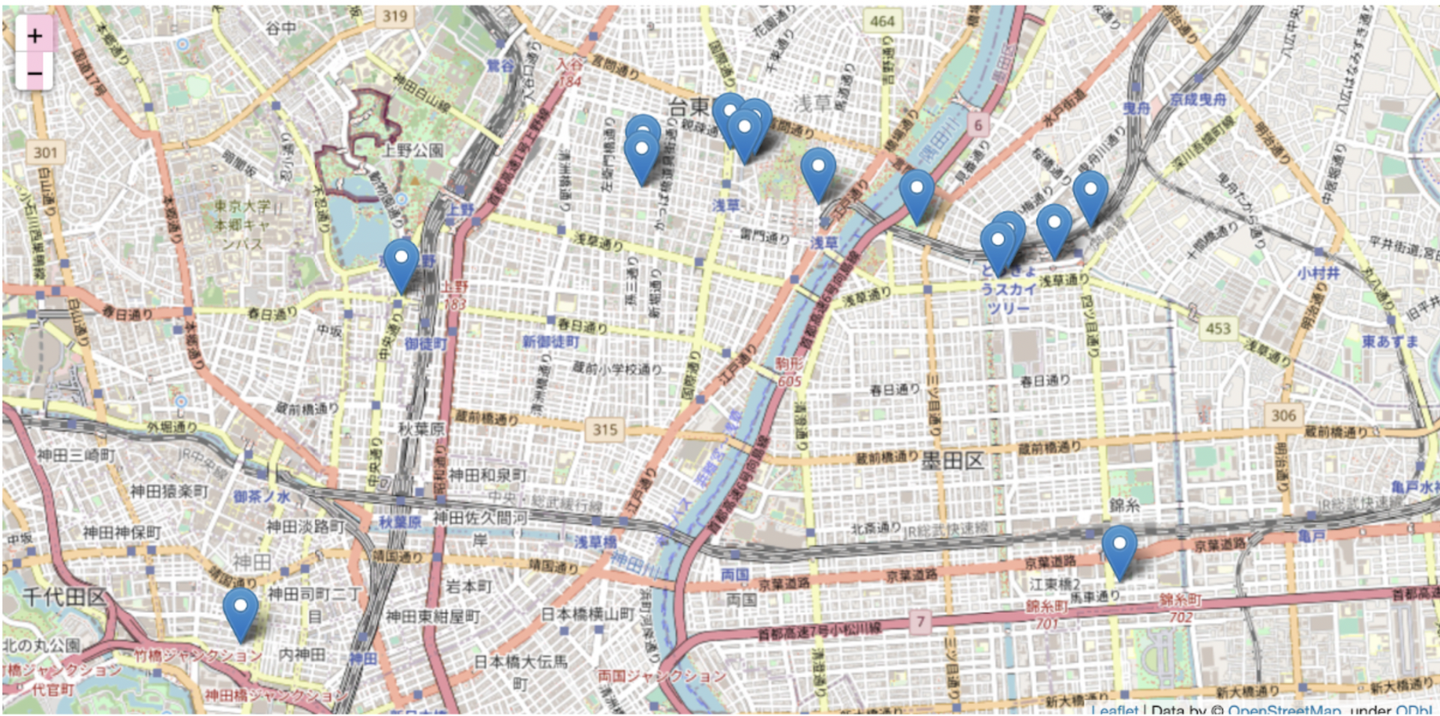
- アウトプットデータをプロットし、一部を拡大した図
- 同じ時間付近同じ時間付近に圧縮範囲内で得られたデータを中心の一箇所に圧縮してデータを削減しています。
- 元データと比べると似たような場所にあるデータが削減されているのがわかります。
パラメータの変化による出力結果(軌道圧縮処理)
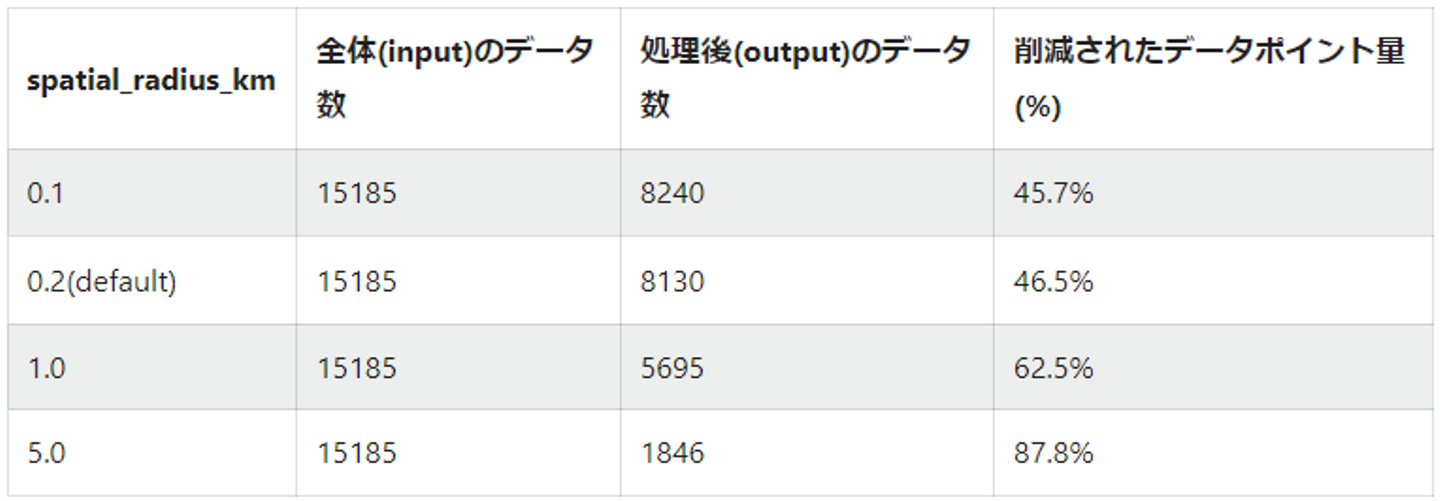
- inputデータとして全体のデータを入れた場合
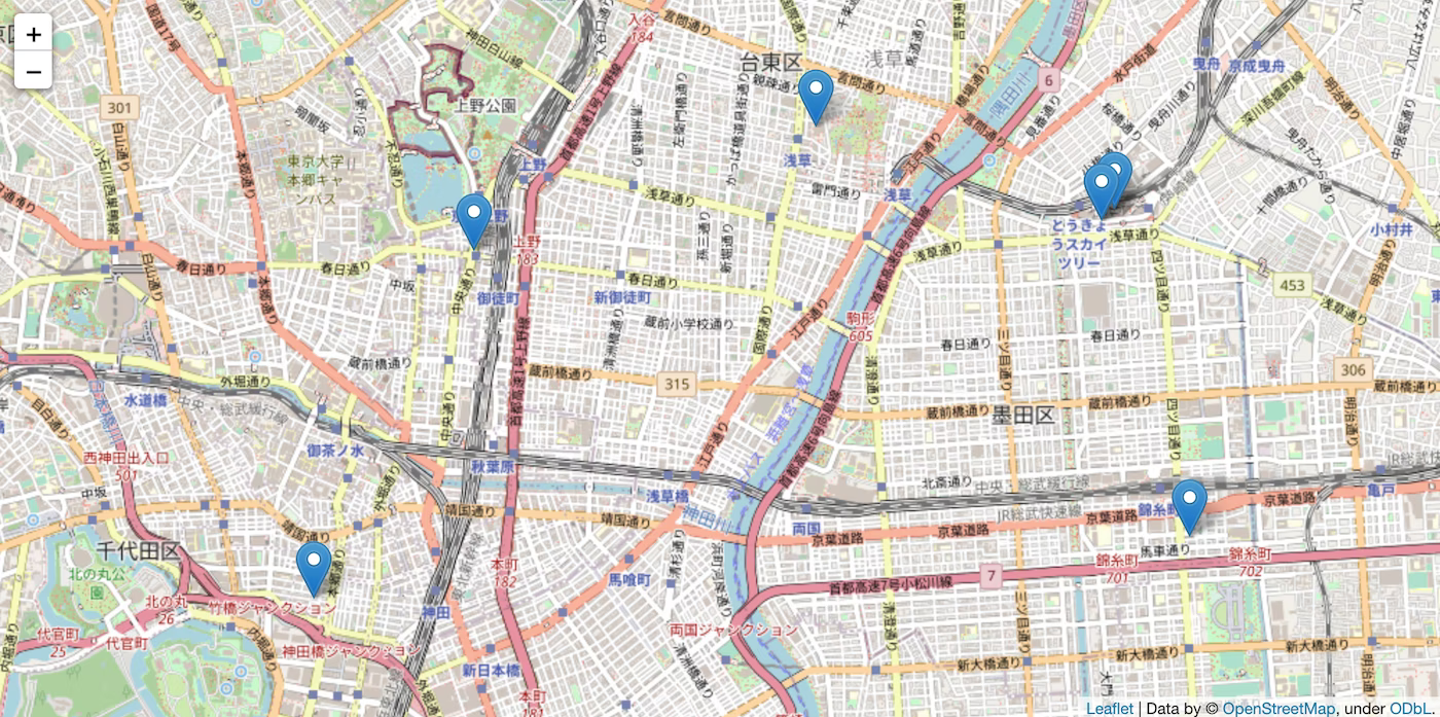
- 特定のユーザーのデータを入れた場合
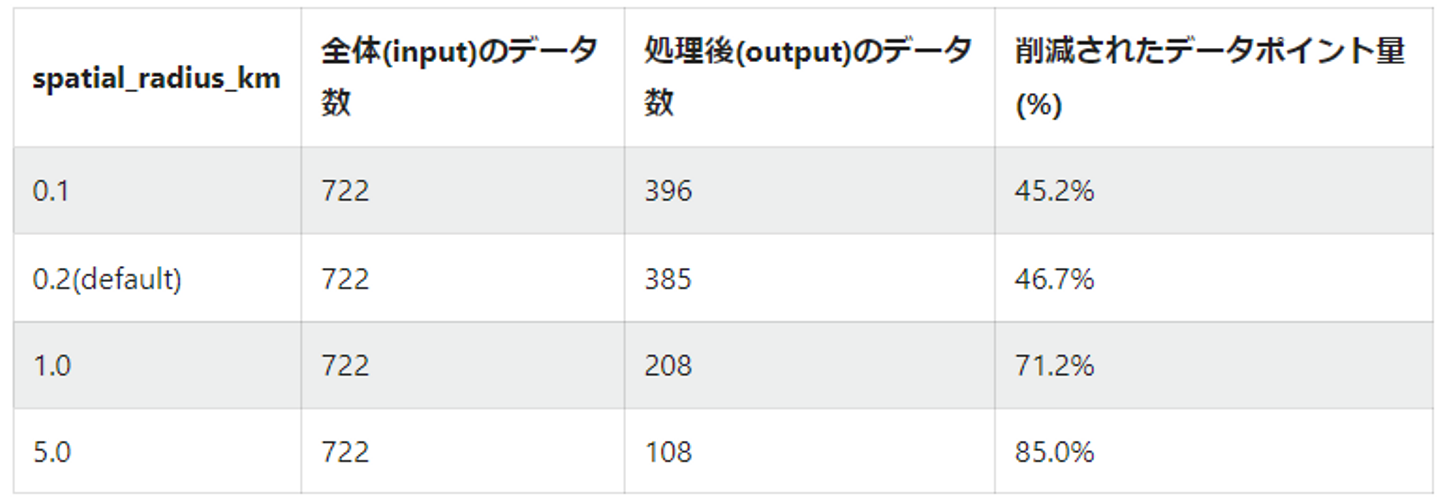
- デフォルトがちょうど50%くらいデータを減らすことができて前処理にはちょうどいい距離設定になっています。
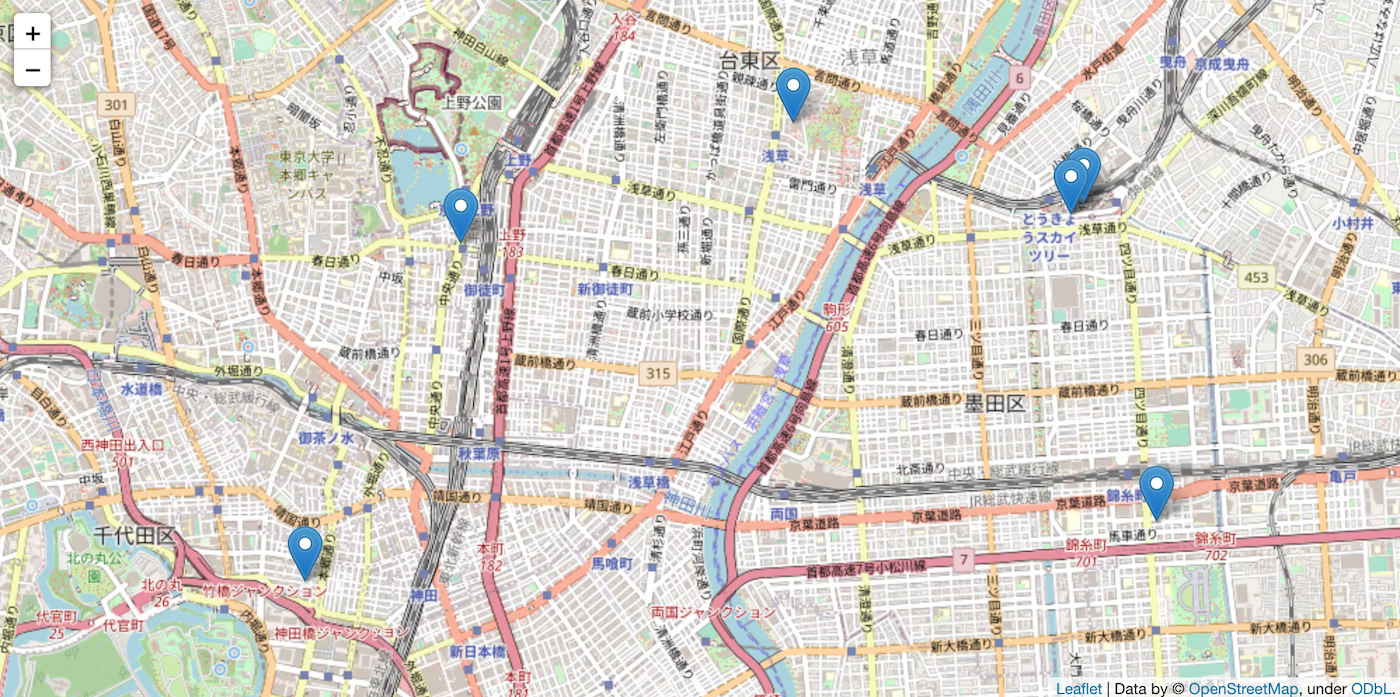
ユーザーデータを入れた場合のパラメータごとのデータポイントのマッピング結果を比較(軌道圧縮処理)
- spatial_radius_km=0.1(km)
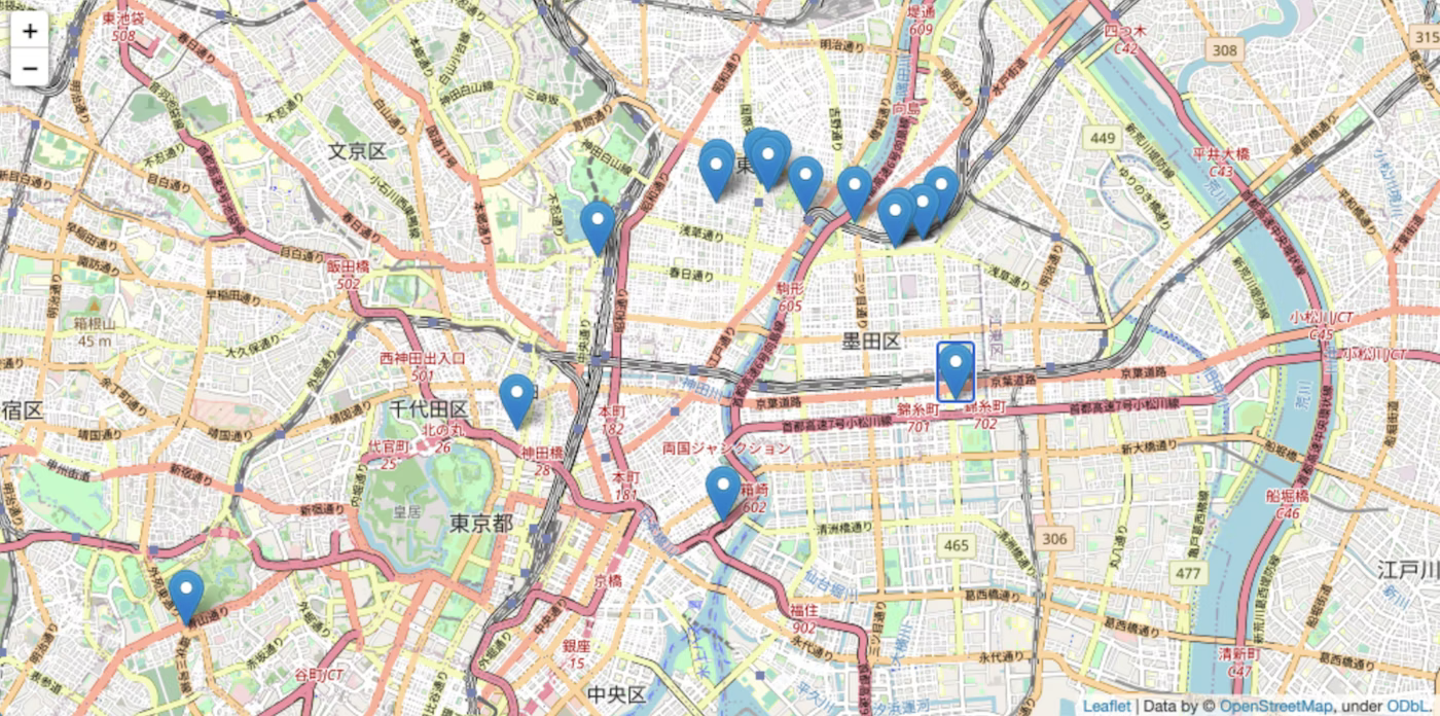
- spatial_radius_km=0.2(km)(デフォルト値)

- spatial_radius_km=1.0(km)
- spatial_radius_km=5.0(km)
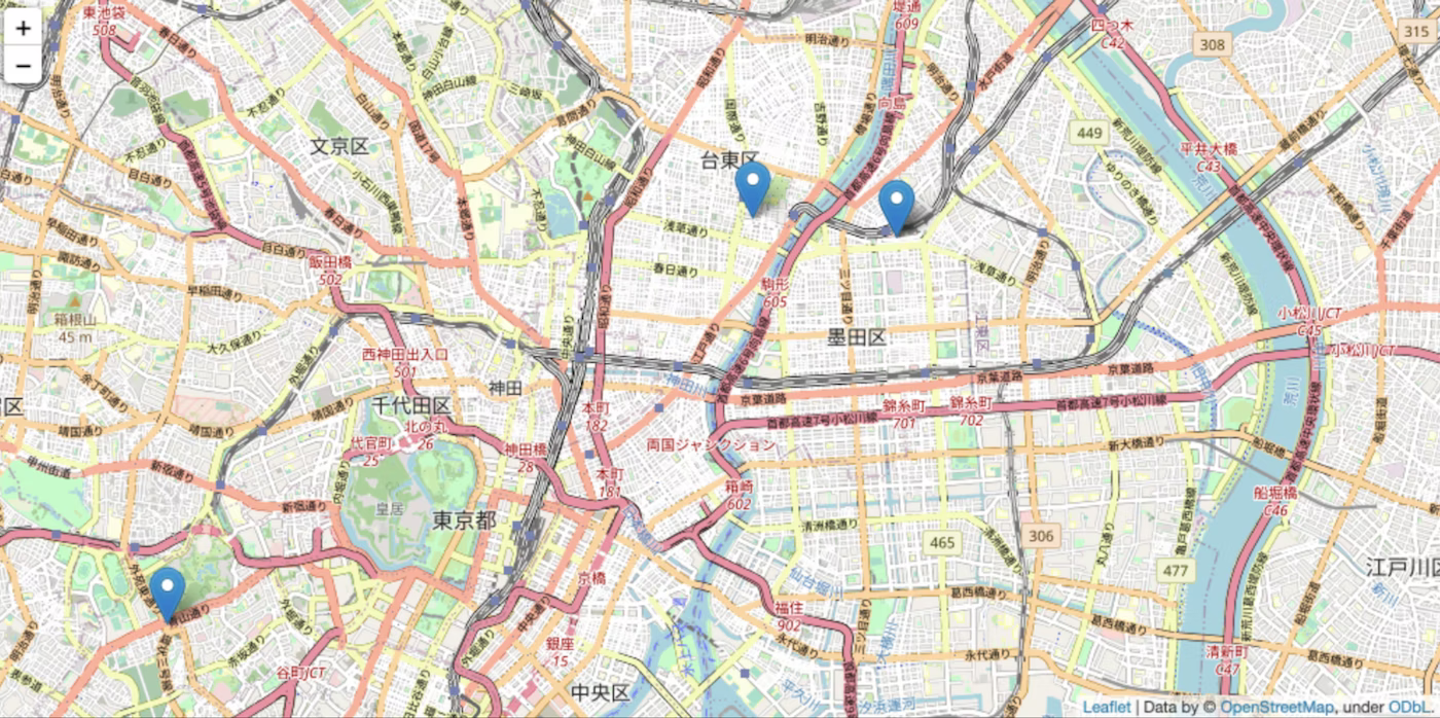
→ 指定する距離が広がるとより多くのポイントが一箇所に圧縮されてデータポイントを減らすことができます。
→ 結構細かく圧縮範囲の指定ができるので自分でカスタムして前処理の精度を決められるのがいいなと思いました。
5. シリーズ記事
scikit-mobilityについて、シリーズで記事を投稿しています。
シリーズの記事もぜひ読んでいただけると嬉しいです。
前回の記事はこちらです。
最後に
私たちの会社、ナイトレイでは一緒に事業を盛り上げてくれるGISチームメンバーを募集しています!
現在活躍中のメンバーは開発部に所属しながらセールス部門と密に動いており、
慣れてくれば顧客とのフロントに立ち進行を任されるなど、顧客に近い分やりがいを感じやすい
ポジションです。
このような方は是非Wantedlyからお気軽にご連絡ください(もしくは recruit@nightley.jp まで)
✔︎ GISの使用経験があり、観光・まちづくり・交通系などの分野でスキルを活かしてみたい
✔︎ ビッグデータの処理が好き!(達成感を感じられる)
✔︎ 社内メンバーだけではなく顧客とのやり取りも実はけっこう好き
✔︎ 地理や地図が好きで仕事中も眺めていたい
一つでも当てはまる方は是非こちらの記事をご覧ください 。
二つ当てはまった方は是非エントリーお待ちしております(^ ^)
「位置情報×モビリティ.まちづくりetc事業領域拡大の為GISエンジニア募集」
https://www.wantedly.com位置情報×モビリティ.まちづくりetc事業領域拡大の為GISエンジニア募集 by 株式会社ナイトレイ
▼ナイトレイとは?
/assets/images/17514/original/558f701b-5611-44f3-bc41-0c96b473917a.png?1427288547)


/assets/images/17514/original/558f701b-5611-44f3-bc41-0c96b473917a.png?1427288547)


/assets/images/8300070/original/558f701b-5611-44f3-bc41-0c96b473917a.png?1639042247)


