/assets/images/8938972/original/474e8d94-0e78-42ef-bac2-bce8cc93748e?1645852843)


/assets/images/3498840/original/34146727-902d-42e5-898f-7c9de258e514?1653291802)
モノグサ株式会社's job postings
- ソフトウェア/データエンジニア
- PdM(Study領域)
- カスタマーサクセス・事業開発
- Other occupations (21)
- Development
- Business
- Other
Monoxerは記憶のプラットフォームであり、ソフトウエアの力で記憶にまつわる問題を解決して人類の発展と繁栄に貢献したいと考えています。
記憶は目で見ることができないこともあり、記憶をコンピュータで扱うためには、記憶をどのような方法で表現するかが大きな課題になってきます。何を対象として記憶度を管理するのか、という点と、記憶度自体をどのように表現するのか、という2つの問題があります。
この問題に対しては様々なアプローチがとられてきました。人力でタグ付けをし、問題の習熟度を管理する方法や、限られた範囲の単語のデータを持っておく方法、要素間の関係性は特に扱わず、ユーザの入力をそのまま扱う方法、などがしばしば採用されています。
しかし、これらの手法では
・手間をかけずに誰でもコンテンツの作成が可能であること
・記憶すべきもの間の関係性が利用できる(例えば同じものは同じであるとわかる)
を同時に満たすことができません。Monoxerは記憶のプラットフォームを志向しており、誰でも簡単にコンテンツ作成が可能であるということを重視しています。記憶の効率化のためにも、これらの条件を両立させることのできる手法を採用したいと考えました。
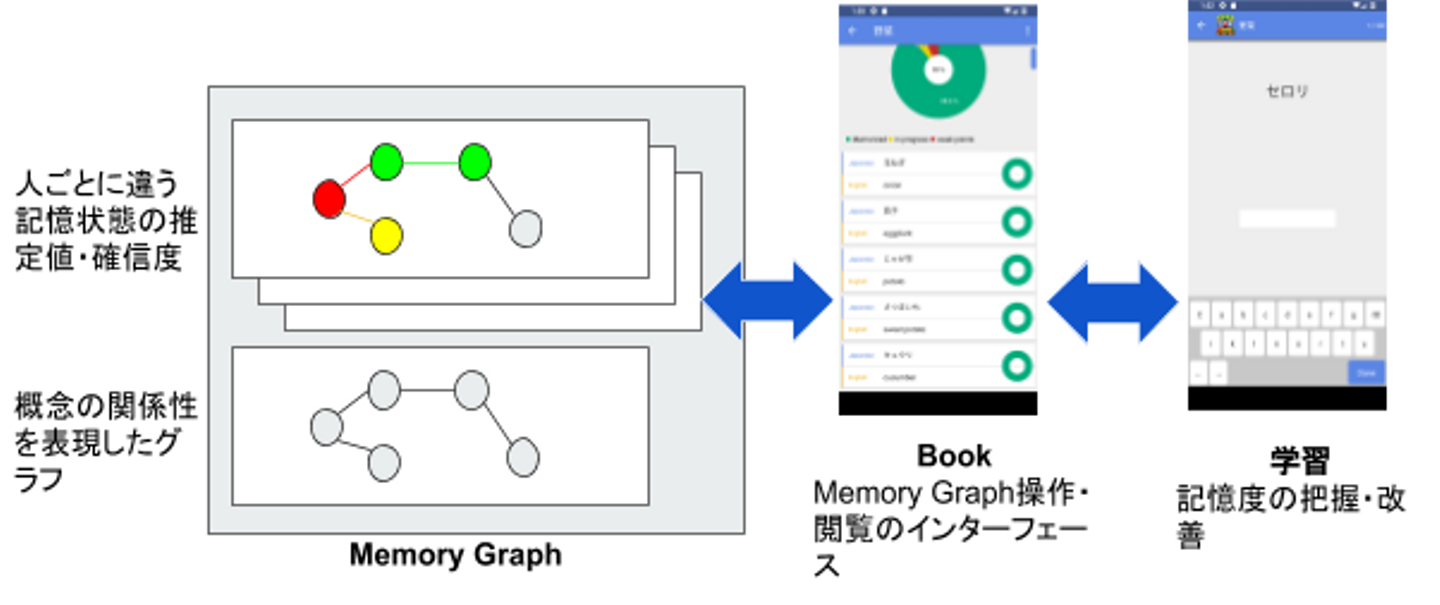
MonoxerではMemory Graphと呼んでいる表現方法を設計・開発し、採用しています。
Memory Graphは基本的な概念間の関連性を表現したグラフとそのグラフ内のノード・エッジに対する個人個人の記憶情報をまとめたものです。それぞれのノードは種別(単語・画像・手書きなど)、言語、文字列の3つの要素をもっており、それらが同じものは同一のノードとして扱われます。
ユーザがコンテンツ作成を行う上では様々な問題が発生します。例えば、英単語学習サービスでは同綴異義語をどう表現するかという問題があります。システム提供側がコンテンツをすべて作成するならば、個別に対応すれば問題ないのですが、ユーザが自由にコンテンツを作成する上では避け難い問題です。”lead”を例にとってみると、Memory Graph上では”lead”はただのノード”lead”で、“鉛”でも “導く”でもありません。”lead”は“鉛”や “導く”といった別のノードと結合されて初めて単語としての意味が表現されるようになります。結果として、作成者による追加情報の入力なしにそれぞれの意味を学習者は正しく学習できます。これは一例ですが、Memory Graphはユーザがコンテンツ作成を行う上での様々な問題をスケーラブルに解決することができるように設計しています。
MonoxerではMemory GraphのNode, Edgeの追加/取得、類似Node取得、記憶度の取得・集計などを効率的に行える、基盤となるシステムを開発し、そのシステムを利用して記憶の管理や適切な問題の生成を行っています。
また、グラフ構造の難点として操作のための簡潔なUIが構成しにくい(と私は思う)のですが、MonoxerではBook(単語帳)をインターフェースとして用いることで直感的に、データ構造を意識することなく、コンテンツの操作が行えるようになっています。
Memory Graph上のノード・エッジの記憶情報を用いて、Book(単語帳)のコンテンツの記憶度を表現します。Monoxerではコンテンツの記憶度はそのコンテンツに対する最も難易度の高い問題に対する予想正答率としています。ですので、記憶度は0から1の数値となります。
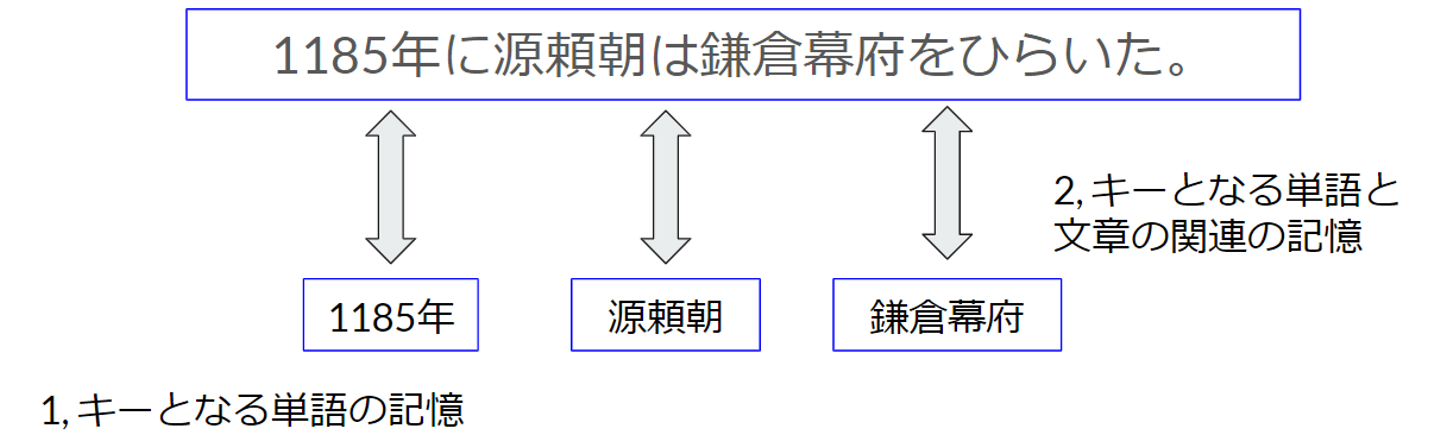
Bookのコンテンツとしては、”apple” <-> “りんご”のようなフラッシュカードタイプのものや、”1185年に源頼朝は鎌倉幕府をひらいた”といった文章形式のものが存在します。 フラッシュカードタイプの”apple” <-> “りんご”の場合は単純で、そのエッジの記憶情報をそのままコンテンツの記憶度として利用します(計算法は後述)。”1185年に源頼朝は鎌倉幕府をひらいた”のような文章の場合は、まず、文中の重要なキーワードを抽出します。そのキーワードをノードとしたときの記憶情報(1)と、キーワードと文章の関連の記憶情報(2)を複合して記憶度を計算します。Monoxerは文章を入力するだけで適切なキーワードを抽出し、コンテンツを作成してくれる機能を備えているので、このための作業は完全に自動で行うことができます。
ノード・エッジの記憶情報とBookのコンテンツの記憶度関係は原子と分子の関係に近く、ノード・エッジの記憶情報を組み合わせてコンテンツの記憶度を表現するようになっています。新しいコンテンツをサポートする際には新しい種類のノードを足すこともできますし、既存のノードの組み合わせで新しいコンテンツの記憶度を表現することもできます。
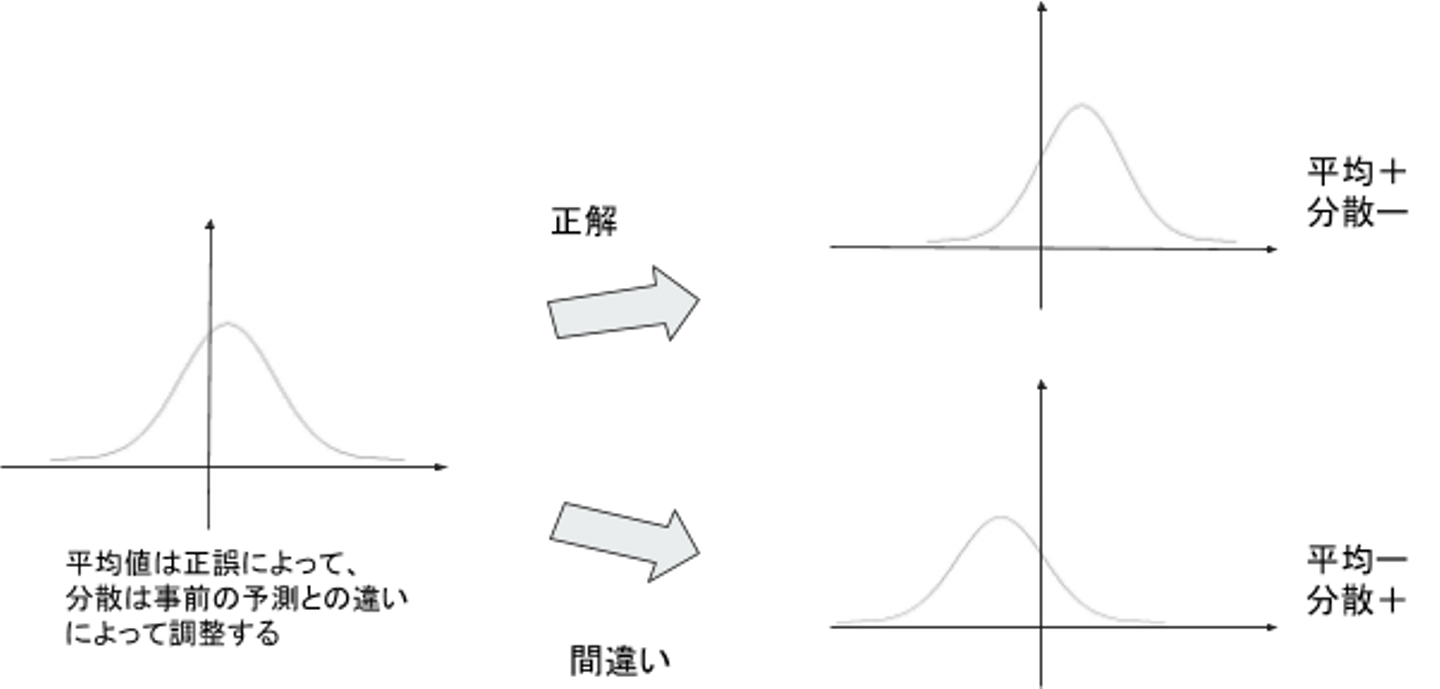
ノード・エッジの記憶情報としては記憶度合いと確信度を持っています。記憶度合いと平均確信度を標準偏差とした正規分布で記憶状況を表現し、[0, ∞]の積分値が記憶度となります。記憶度合いは記憶度算出のための便宜的なもので、その値自体に意味はありません。学習時には記憶度から問題の正誤を予測し、実際の正誤で記憶度合いを調整、予想との一致不一致で確信度を調整します。
Monoxerに触れていないときにも利用者の本当の記憶状況は変化します。忘却もそうですし、生活の中で記憶対象に触れる可能性もあります。Monoxerでは確信度を時間経過に従って下げる(標準偏差を大きくする)ことでこれらの記憶変化を扱っています。出題時にも確信度が下がってきたから確信度を上げるための出題を行います。一般の学習サービスではエビングハウスの忘却曲線に基づいた復習を行うとしているものが多くあります。しかし、エビングハウスの忘却曲線自体は無意味な音節の記憶が対象であり、また、再び記憶するためのコスト削減量である節約率を曲線にしたものであるため、現実的な環境とは差があります。忘却曲線に基づく方式を採用したとしても短期的には大きな効率の差はないかもしれませんが、長期的にはMonoxerの手法によって学習最適化の可能性を広げることができると考えています。
Monoxerをやっていると”理解と記憶は違う”、”理解が大切なのではないか”といったことを耳にすることも多くあります。けれども”理解とは何か?”と聞かれて明確に答えられる人はあまりいないように思います。
私たちは理解と記憶は本質的には同じものであると考えています。具体的には、あるものXに対する理解とは、Xの理解に必要なすべての事象に対する理解、あるいは、Xの記憶である、と再帰的に理解を定義できるのではないかと考えています。
理解をシンプルな記憶の組み合わせで表現できれば、Memory Graphで表現可能なため、すべてをMonoxer上で扱うことができるのです!と、言うのは簡単なのですが、現実は複雑です。
理解に必要な事柄は多くの場合暗黙的に与えられ、時と場合によっても異なります。”足し算について説明しなさい”という問いに要求され知識は、小学生と大学生では異なります。また、”Make America great again.”という文を正しく理解するには単純な文の意味以外の知識が必要になってきます。加えて、個々人によって想定する理解に必要な事柄の範囲が変わりうるというのもこの問題をややこしくしています。
Monoxerでは単純なものから始めて、扱える範囲を増やしてゆきたいと考えています。現時点では、フラッシュカードや文章などシンプルなものです。今後は、ノードの種類として音声などのサポート、Bookのコンテンツとしては数学や複合的な問題も扱えるようにしてゆきたいと考えています。
現在のMonoxerは、記憶についてできることのほんの僅かな部分しか扱えていません。私達は、記憶とは人類の知的活動の根底であり、豊かさの根源であると信じています。
一緒にMonoxerの可能性を広げ、記憶を助ける仕組みを作ってゆける人を募集しています!
少しでも内容に興味をもっていただけた方は、ぜひお気軽にコンタクトください!

/assets/images/8938972/original/474e8d94-0e78-42ef-bac2-bce8cc93748e?1645852843)

![]()




/assets/images/8938972/original/474e8d94-0e78-42ef-bac2-bce8cc93748e?1645852843)