Cloud Functions と Cloud PubSub を利用した並列処理からCloud Run Jobsに移行したらいい感じになった

Photo by Christopher Burns on Unsplash
.tl:dr;
- CloudFunctions + Cloud Pub/Sub(Fanout)の構成だと終了を検知する方法が複雑
- Cloud Run Jobs なら終了判定をサービスに任せることができるし、並列化も容易
- Cloud Run Jobs はイイゾ
やりたいこと
社内のとあるプロジェクトにおいて、以下の要件を満たすようなバッチ処理のアーキテクチャを設計・実装することになりました。
- 定期的に外部より提供される数GBのデータ(以下、`フィード`という)をRDBに取り込みしつつ、RDBからElasticsearchにも同期させる。
- この処理を1時間で終わらせたい
- フィードの種類はリリース段階では1つだけの予定だが、その後は継続的に増えていく予定のため、初期構築時からある程度の処理時間とスケーラビリティを確保する必要がある。
- インフラ基盤に Google Cloud を利用する。
処理の全体像
いわゆる ETL と呼ばれる方法で取り込んでいくイメージです。(※説明のためかなり単純化しています。)
- フィードをダウンロード(Extract)
- フィードを正規化する(Transform)
- RDBに書き込む(Load)
このプロジェクトではバックエンドに Ruby on Rails を採用していたので、書き込み処理(RDB への import )はRuby on Rails で実装した方が工数・管理の削減に繋がるだろうと判断し、import のステップ自体はRuby on Rails で実装することになりました。
構成案
一番のボトルネックになるのがRDBへの書き込み処理です。フィードを正規化すると約数百万件のレコードに膨れ上がるため、ただ単にバルクインサートで直列で処理するだけでは数時間かかってしまうことが目に見えていました。
そこで、最初から並列処理を前提に、並列処理の管理のしやすさ・スケールのしやすさをポイントに、構成案を出しました。
1つの巨大なインスタンスを利用したマルチプロセス/マルチスレッドによる並列化
ある程度のスペックを搭載したGCEを利用し、マルチプロセス/マルチスレッドによって並列処理を行う方法です。
インスタンス単体なので管理はしやすいですが、データ数が増えたときのスケーリングを行うためにはスペックの変更・コード内の並列数の変更などをそれぞれ手動で行う必要があり、運用負荷が高いことが懸念点としてあり、見送られました。
Dataflowを利用した並列処理
Dataflowとは
Dataflow は、ストリーミングとバッチのデータ処理パイプラインを実行するためのフルマネージド サービス
Apache Beamというバッチ パイプラインとストリーミング パイプラインの両方を定義するオープンソースの統合モデルをベースとしている
ETLのパイプラインをこれ1つで記述できるという特徴があり、また、内部では Kubernetes が動いており、Worker Node のCPU負荷を基準にオートスケールするため、データ量の増大による調整が不要になりそうでした。
しかし
- ベースとなっている Apache Beam は Ruby をサポートしていないので、書き込み処理で Rails を利用することができない
- 自動スケーリングを検証した結果、主な負荷はRDB側で、書き込みリクエストを送るインスタンス側はCPU負荷が高まり辛く、インスタンスが自動スケーリングせず、全体的な処理速度のパフォーマンスが出ない
という理由から、採用を見送りました。
※インスタンスの自動スケーリングの条件
・The CPU utilization of existing instances over a one minute window, targeting to keep scheduled instances to a 60% CPU utilization.
・The current request concurrency, compared to the maximum concurrency over a one minute window.
・The maximum number of instances setting
・- The minimum number of instances setting
https://cloud.google.com/run/docs/about-instance-autoscaling
Fanout
その次に、分散部分のロジックを簡単にコントロールできるような構成として、Cloud Functions と Cloud Pub/Sub を使ったFanout構成を検証しました。
Fanout構成とは
Scheduler と呼ばれる Cloud Functions が処理対象のデータを分散させたい単位にまとめて Pub/Sub に送信して、Pub/Sub の topic を subscribe している Cloud Functions が分散されたデータに対して処理を実行するという構成のこと。
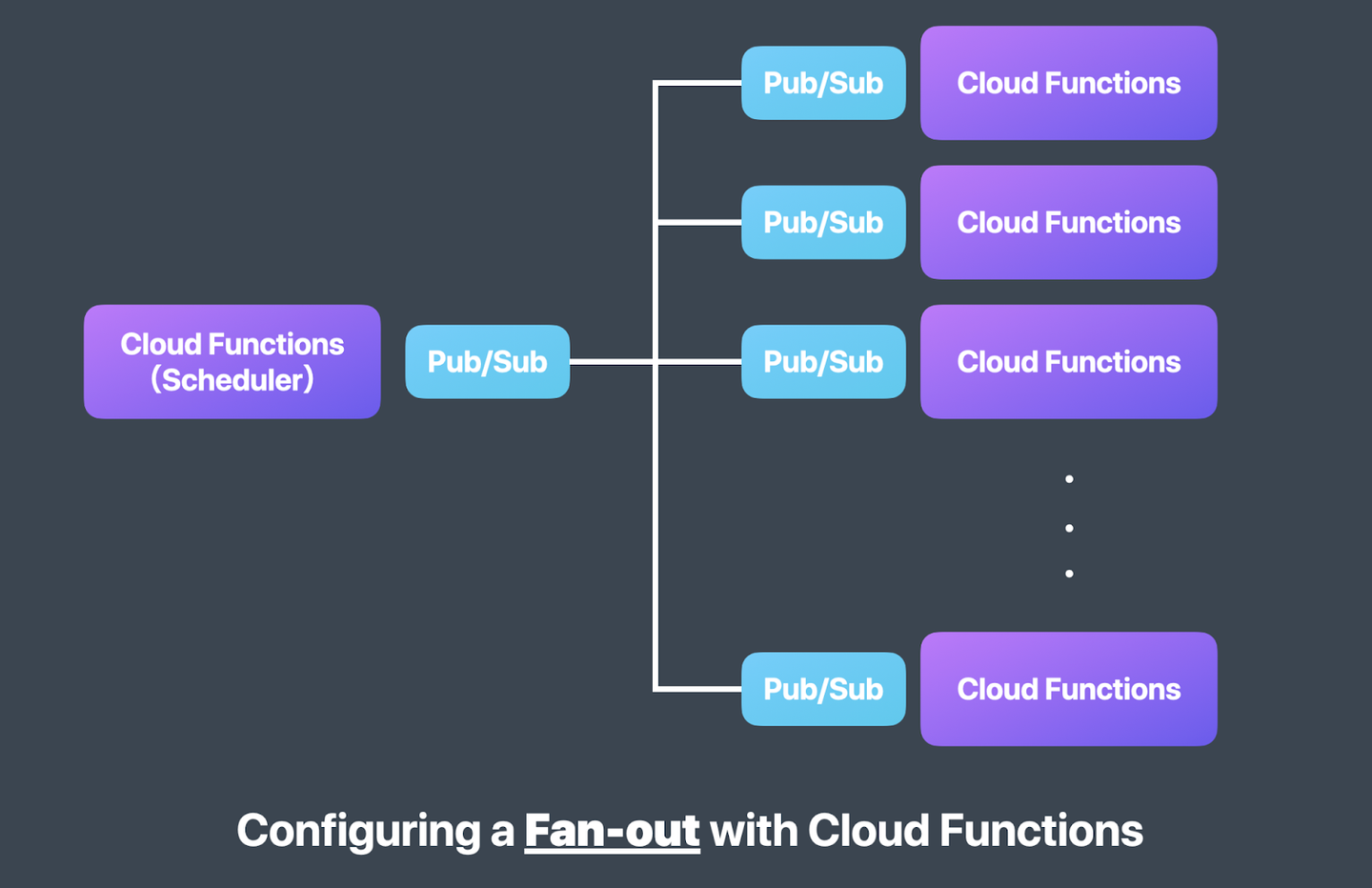
便宜上、前段の Cloud Functions を「投入関数」、後段の Cloud Functions を「処理関数」と呼びます。
今回は処理関数の部分を Rails (Cloud Run)に置き換えています。
処理の流れ
- 投入関数が Cloud Storage より Feed を取得して中身を Pub/Sub に投入
- Pub/Sub が Subscriber である Rails (Cloud Run) にメッセージを送信
- Rails が Pub/Sub より受信したメッセージを RDB へ書き込み(バルクインサート)する。Pub/SubからのリクエストによりCloud RunへのCPU負荷が高まるとオートスケールするため、並列処理になる
この構成により、投入関数の分散させる単位を調整することで、Railsによる書き込み処理の単位を調整できるようになり、約数百万件のデータを10分ほどですべて書き込みできることを確認できました。
しかし、まだ1つ問題があり、この構成にはすべての書き込みが終わったことを検知する仕組みがないです。
追加で検知方法を調査・検討した結果、最終的に以下のような構成図となりました。
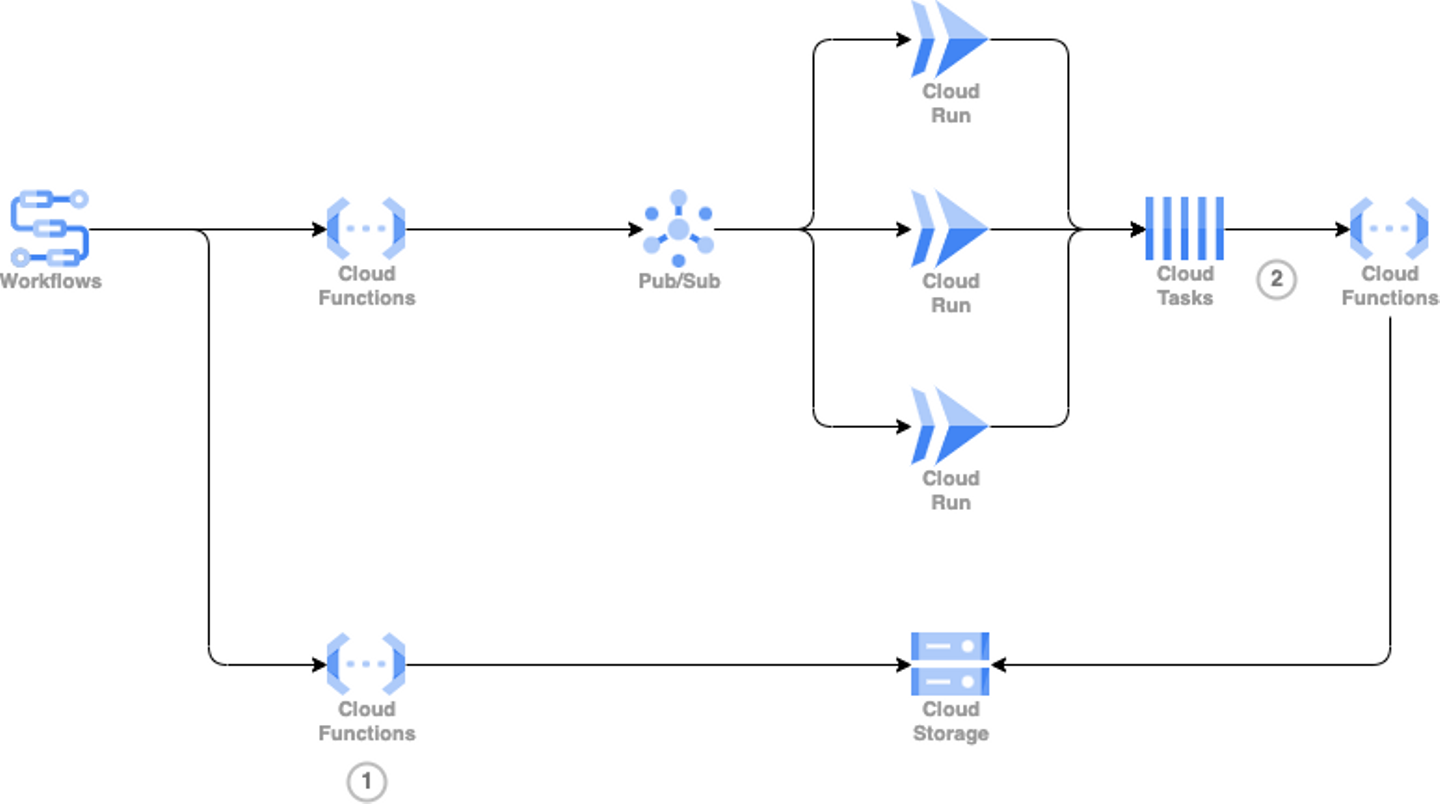
- Fanout構成に付け足す形で処理関数の後段に書き込みデータのソースをアーカイブする Cloud Functions (②)を追加
- データレイクを監視する Cloud Functions (①)を追加したうえで、投入関数の起動と同時に起動させる。空になったら終了しているのでSlackなどに通知。
今回は Cloud Storage をデータレイクとして利用しているため、取り込み終えた Feed を Cloud Storage からアーカイブすることで、すべての Feed を取り込み終えたら Feed を配置している directory は空になります。
この directory を監視することで、Fanout の終了を検知することが可能になりました。
Fanoutの問題点
処理時間も、終了検知の方法も確立したものの、最後にして最大の問題点が発覚しました。
それは構成が複雑になりすぎてしまい、デバッグが難しくなっている点です。
フィードのデータ内の不整合か、コードの不具合か、あるいは別のエラーなのかを判別するためには一連の処理を1つずつ追っていく必要があり、デバッグが非常に大変な状態になっていました。
これを改善するためには、もっとシンプルな構成で並列処理とその修正検知ができる方法を見つける必要がありました。
これでよかった、Cloud Run Jobs
Cloud Run Jobsとは
Cloud Run ジョブを使用すれば、これまで時間のかかっていた手作業によるプロセスを、スケジュールされたジョブに簡素化したり、単純なコマンドライン オペレーションに減らしたりすることができます。Google I/O のプレビュー版で導入された Cloud Run ジョブを使用すると、開発者は HTTP リクエストに応答しない実行から完了までの長いスクリプトをすべてサーバーレス プラットフォームで実行できます。従来のスクリプトをモダナイズしてサーバーレス環境に移植しようとしている企業の開発者は、コードをイベント ドリブン モデルに再構築しなくてもこれを実施できます。
https://cloud.google.com/blog/ja/products/serverless/cloud-run-jobs-and-second-generation-execution-environment-ga/?hl=ja
つまり、Cloud Run で非同期ジョブを実行するための機能です。
特徴としては、コンテナでバッチ処理を実行できるだけではなく、Cloud Run の特徴であるスケーラビリティを活かしてバッチ処理を構成できる点です。
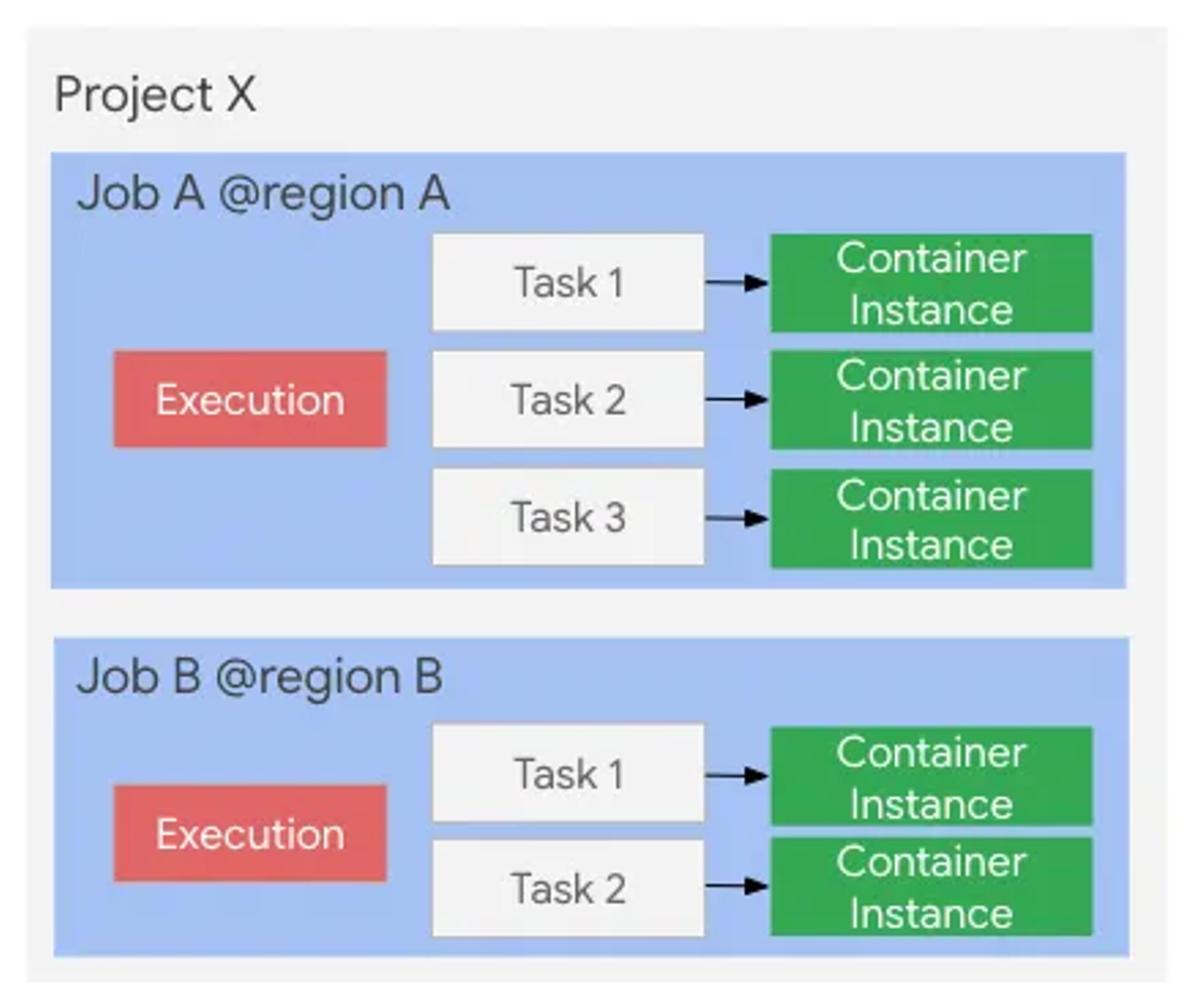
Cloud Run Jobs のリソースモデル
JobでTask数を指定すると、その数だけTaskが実行されます。このTaskは大きく以下のように3つの使い方に分かれます。
- 1つのTaskを実行する
- 複数のTaskを直列に実行する
- 複数のTaskを並列に実行する
まさにこの3つ目の方法が、私たちの求めていたものでした。
移行した結果どうなったか
- 並列数は手動で管理する必要があるものの、設定(Task数)を1つ変更するだけで良いのでそこまで負荷にもならない
- Fanoutの構成におけるPub/SubやCloud Functionsなど、分散・終了検知のために利用していたサービスが不要になった
- デバッグも該当ジョブのログを確認するだけで済むようになった
総合的に非常にシンプルな構成にすることができました。
感想
やりたいことに対してかなり遠回りした気がしますが、最終的にはサービス1つに寄せることができ、シンプルな構成に持っていくことができました。
引き続きアーキテクチャの引き出しをもっと増やしつつ、構成を更に改善をできないかを検討していきたいと思います。
/assets/images/7395491/original/07f965bc-cf78-49ee-bcec-fbf7e34cb56b?1629769675)


/assets/images/7395491/original/07f965bc-cf78-49ee-bcec-fbf7e34cb56b?1629769675)




/assets/images/7395491/original/07f965bc-cf78-49ee-bcec-fbf7e34cb56b?1629769675)


