こんにちは。ウォンテッドリーでデータサイエンティストをしている林 ( @python_walker ) です。この記事では、推薦システムにおける重要な課題の一つである 人気バイアス をテーマに、最近発表された論文を紹介します。また、単に理論を紹介するだけでなく、論文で提案された手法を Wantedly の実データに適用して検証した結果 についても紹介します。
目次 人気バイアス
人気バイアスとは
ウォンテッドリーにおける課題
ユーザー・アイテム双方に着目した人気バイアス緩和:PAIR
「ニッチなものを好むヘビーユーザー」の存在
提案手法:PAIRのロス関数
Wantedly のデータセットを利用した再現実験
Q1. Wantedly 上にはニッチな募集を好むユーザーが一定存在するのか
Q2. ユーザーと募集のウェイトを調整することで人気バイアスを軽減することができるか
Q3. ウェイトを掛けることによってモデルの性能が大幅に低下しないか
Q4. ニッチな募集を好むユーザーに対するモデル性能は向上しているか
まとめ
人気バイアス 人気バイアスとは 人気バイアスとは、アイテムの本来の質や内容に関わらず、「すでに人気がある」という理由だけで、さらに多くの注目や高い評価が集まってしまう現象を指します。
人気アイテムは多くのユーザーに好まれるため、推薦システムも高いスコアを算出しやすくなります。その結果、人気アイテムがより頻繁に表示され、さらに人気が高まるという フィードバックループ が生まれます。このような状態は、エコシステムの健全性を損なう要因となります。例えば、ニッチな好みを追求したいユーザーは求めるものが見つけづらくなり、提供側(クリエイター等)にとっても、一部の層に利益が過剰に集中してしまうといった問題が発生します。
ウォンテッドリーにおける課題 この問題は、ウォンテッドリーが開発している会社訪問アプリ Wantedly においても同様です。一部の企業の募集に応募が集中してしまうと、以下のような悪影響が生じる可能性があります。
募集を出しているのに全く応募が来ないという状況が発生する 企業の対応キャパシティを超えた応募が届くことで、企業側が一部のユーザーにしか返信できなくなる。その結果、返信をもらえないユーザーが増加する ユーザー・アイテム双方に着目した人気バイアス緩和:PAIR 人気バイアスの緩和は、実務・アカデミアの両面で非常に活発に研究されているテーマです。本記事では、ユーザーとアイテム双方の性質を考慮した PAIR(Popularity-and-Activity Informed Reweighting) というフレームワークを提案した論文を紹介します。
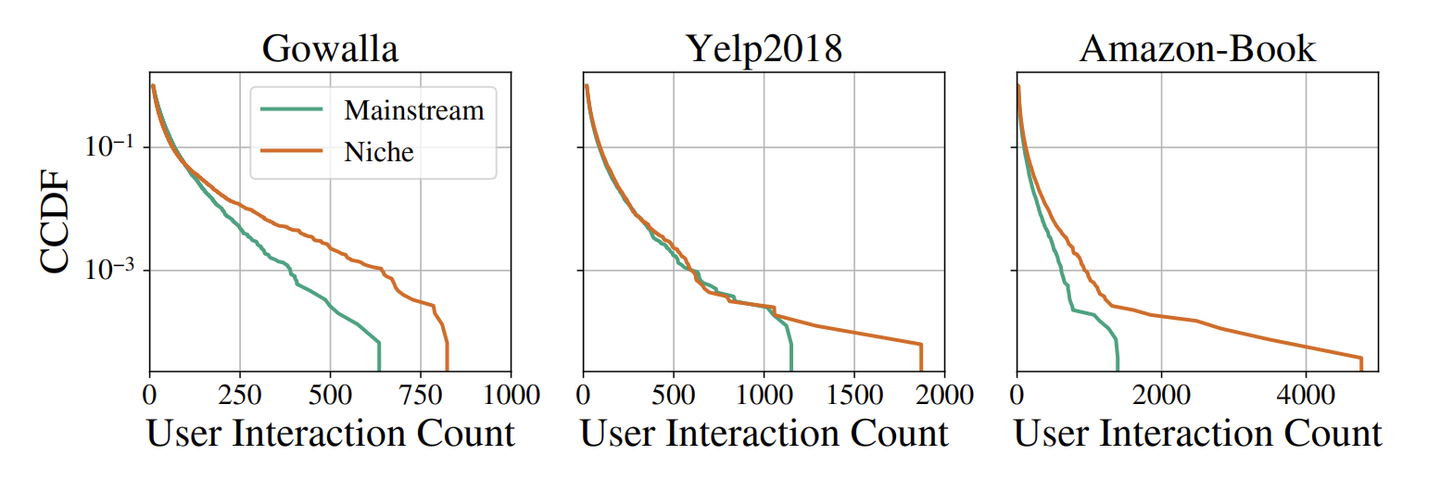
「ニッチなものを好むヘビーユーザー」の存在 この論文ではまず、データセットには一般的に ニッチなアイテムへの嗜好性が強いヘビーユーザー というセグメントが一定存在するということを3つのデータセットを分析することで示しています (下図;論文より引用)。
図中のオレンジ色の線は、ニッチなアイテムを好むユーザーセグメントを示しています。どのデータセットでもロングテールな分布を描いており、論文内では、こうしたユーザーの存在は統計的にも有意(たまたま発生したものではない)であると結論付けています。
提案手法:PAIRのロス関数 論文では、このセグメントがモデルのパフォーマンスを維持しつつ人気バイアスを緩和するのに有用な情報を含むと考えました。このセグメントをより重視するために、以下のようなロス関数を提案しています。
この数式には、調整用のパラメータとして α と β が導入されています。
α(ユーザー側の重み) : 値を大きくするほど、行動量 d_u が多いヘビーユーザーを学習時に重視します。 β(アイテム側の重み) : 値を大きくするほど、アイテムの人気度 d_i のウェイトを相対的に減衰させます。 この α, β を調整することで、既存の学習設定も包含できる汎用的な設計になっています。
α = 1.0, β = 0.0 : ユーザーの出現頻度に比例してサンプリングする、Matrix Factorization 等で一般的な設定。 α = 0.0, β = 0.0 : ユーザーの出現頻度に関わらず一様にサンプリングする、LightGCN 等で標準的な設定。 論文の実験結果では、このロス関数を用いることで、 モデルの推薦性能をほとんど損なうことなく(場合によっては向上させつつ)、人気バイアスを有意に緩和できる ことが示されました (結果と議論の詳細については論文を参照ください)。
Wantedly のデータセットを利用した再現実験 論文で提案された手法が、実際のビジネス環境でも有効なのかを検証するため、 Wantedly の募集一覧ページにおけるユーザーと募集のインタラクションデータを用いて再現実験を行いました。
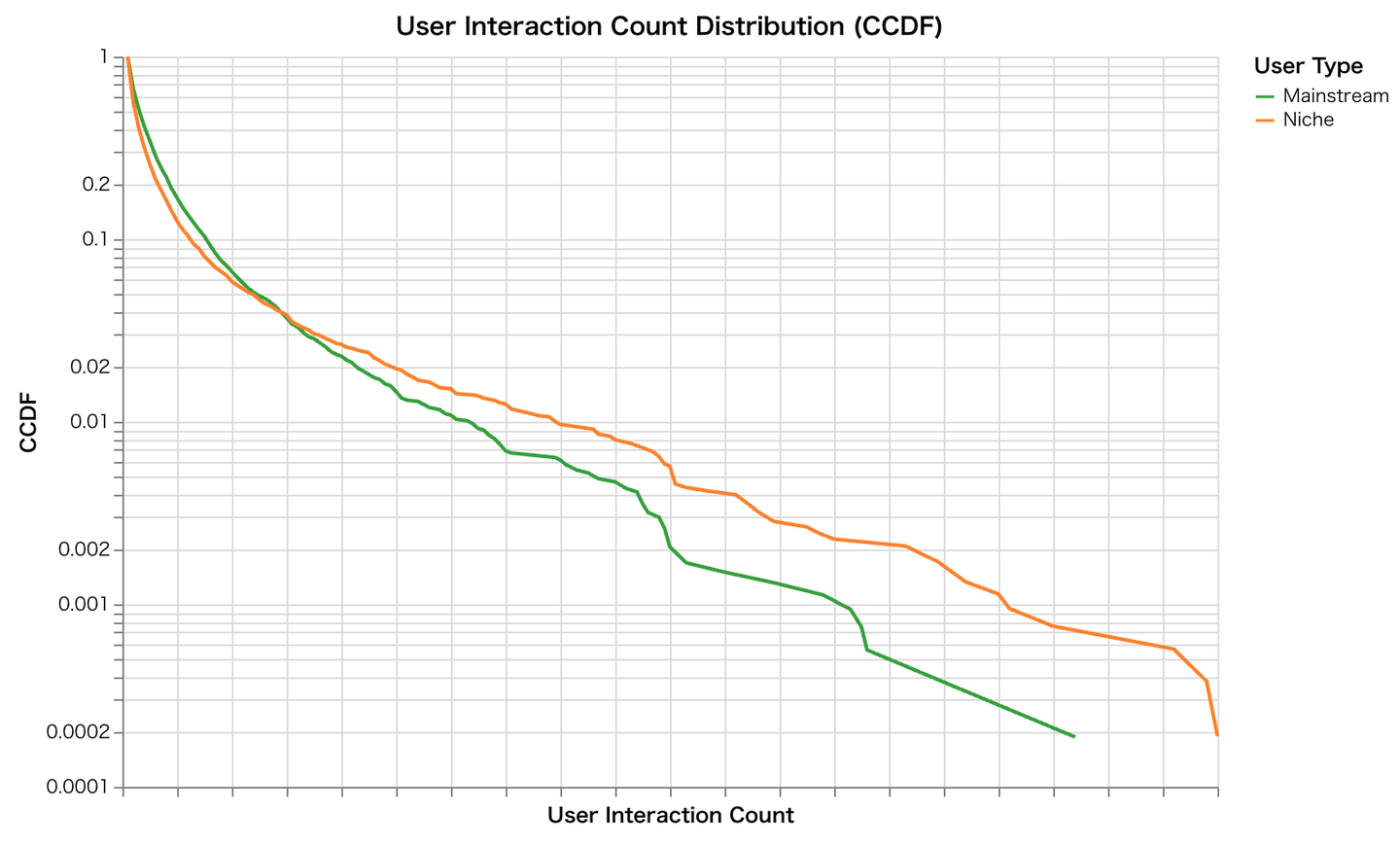
Q1. Wantedly 上にはニッチな募集を好むユーザーが一定存在するのか まず検証の第一歩として、論文の前提である「ニッチなアイテムへの嗜好性が高いヘビーユーザー」が、Wantedly というプラットフォーム上にも有意に存在するのかを確認します。論文と同様の手法で、データの分布を可視化するために CCDF(相補累積分布関数) をプロットしました。CCDF とは縦軸に割合(y)、横軸に指標(x)をとったとき、「指標が x 以上の値を持つサンプルが、全体の何割(y)存在するか」を示す関数です。
プロットの結果、論文の指摘通り「Niche」ラベルが付与されたユーザーの活動量は、より顕著なロングテールを描いていることが確認できました。
これにより、 「データセット内には、ニッチなアイテムを好むヘビーユーザーというセグメントが一定数存在する」 という論文の主張は、ウォンテッドリーのデータセットにおいてもあてはまると言えます。
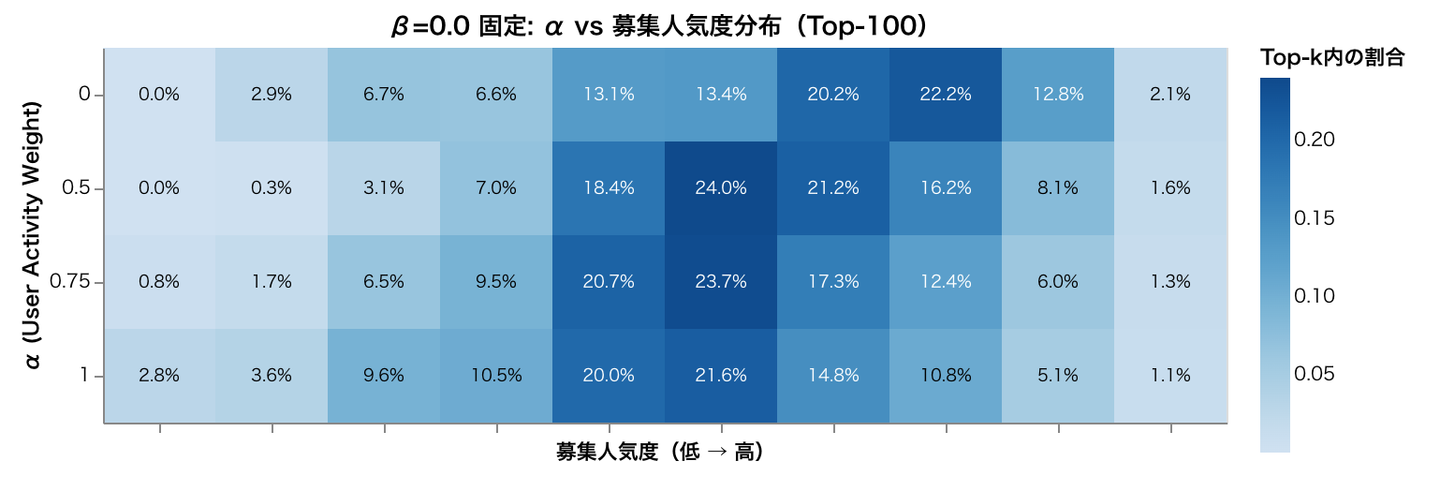
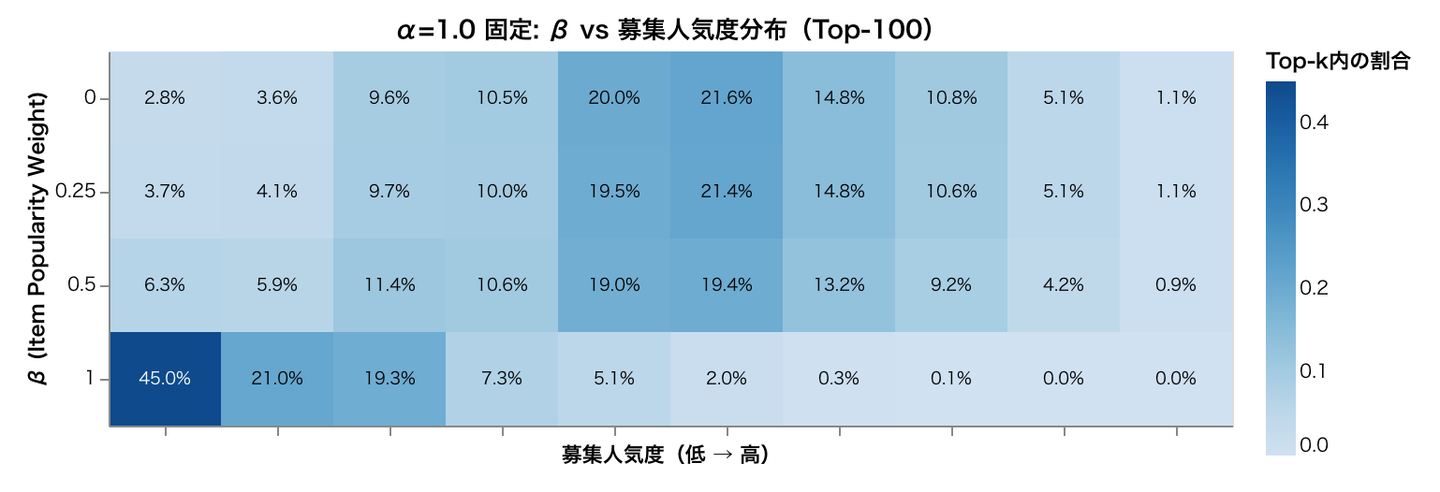
Q2. ユーザーと募集のウェイトを調整することで人気バイアスを軽減することができるか 次に、PAIR フレームワークを用いて、実際に人気バイアスをどの程度制御できるかを検証しました。Matrix Factorization を BPR ロスを使って学習し ( MF-BPR )、各ユーザーに対して100 個の募集を取得するという実験を行った結果を以下に示します。
上は α を変化させたとき、下は β を変化させたときの募集の人気度の分布を示しています。α = 1.0, β = 0.0 が一般的な MF-BPR の設定と等価です。α, β ともに 0 から大きくしていくと色の濃い部分が左にシフトし、人気が高い募集の出現割合が抑えられて 人気バイアスが緩和する方向に変化していく のがわかります。
β を増やしたときに人気バイアスが緩和するのは意図どおりかと思いますが、α を増加させてもバイアスが緩和する方向にシフトしたのは意外でした。論文で α を変えたときの人気バイアスについては触れられていませんが、α を大きくしたときに最も影響を受ける、行動量の多いユーザーにはニッチな募集を好む層が多いことが上の CCDF のプロットからわかっていますので、ニッチな募集を好む行動量の多いユーザーのウェイトが大きくなりやすく、結果として人気バイアスの緩和につながっているのではないかと考察しています。
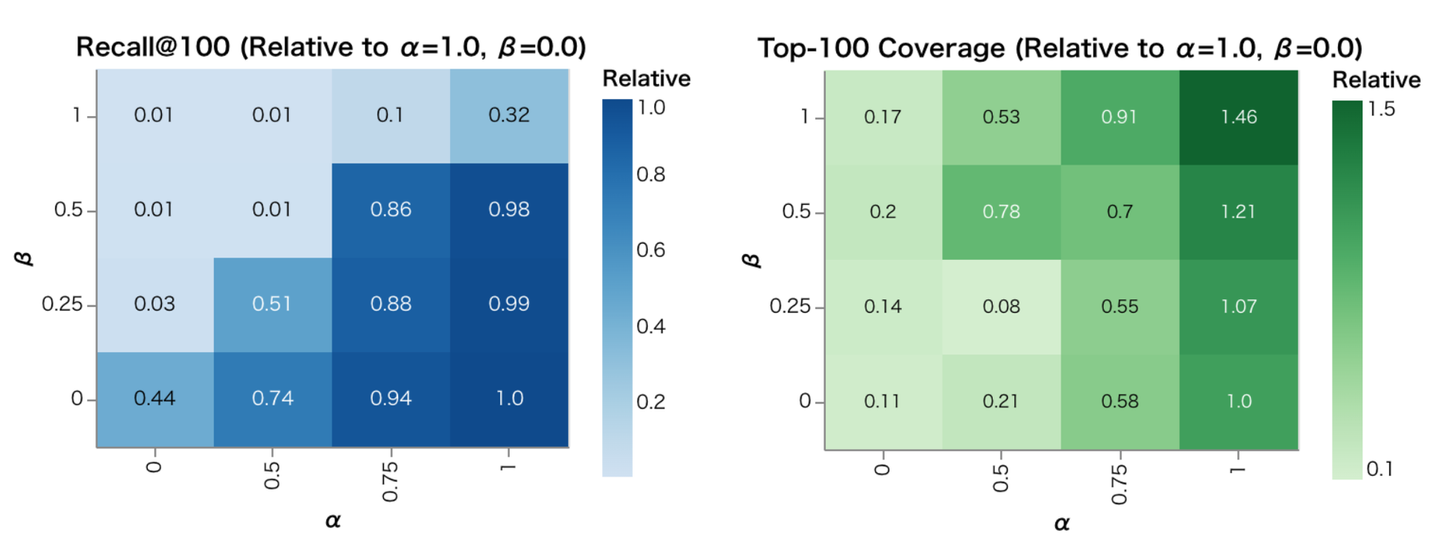
Q3. ウェイトを掛けることによってモデルの性能が大幅に低下しないか 以下は ベースライン (α = 1.0, β = 0.0) を基準とした、相対的な Recall@100 (左) と Top-100に出現する募集の多様性 (右) のパラメーター依存性です。
Recall の面ではベースラインが最も高いという結果になりました。しかし、β によって人気バイアスが緩和されたことが影響しているためなのか、α = 1.0, β = 0.25 では多様性が 7 %増加していました。Recall を 1 %犠牲にして多様性の 7 %増加を取るかどうかはその時のプロダクトの状況にもよるかと思いますが、注目する価値のある結果のように思います。
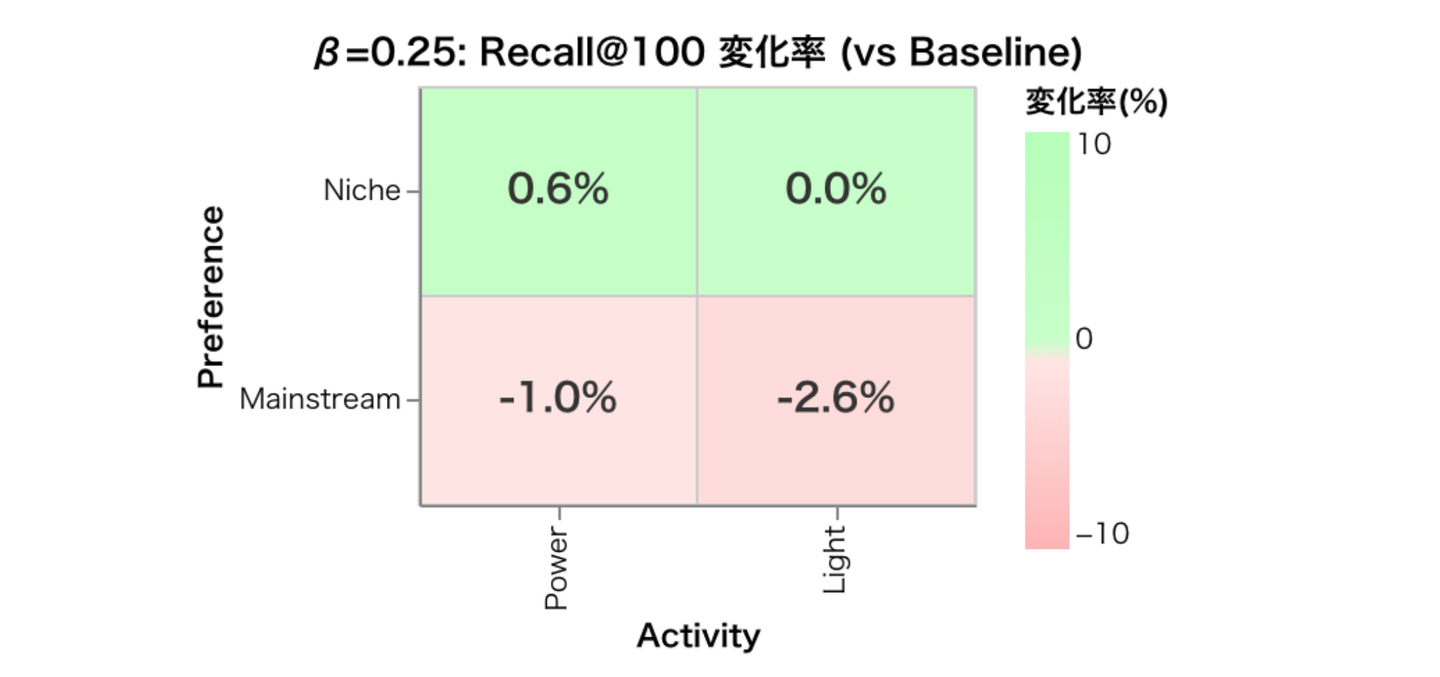
Q4. ニッチな募集を好むユーザーに対するモデル性能は向上しているか ユーザー側のセグメントについても詳しく見てみます。論文と同様の定義によって活動量セグメント (Power user or Light user) と人気な募集への嗜好度合いのセグメント (Mainstream user or Niche user) を分割し、それぞれのセグメントで Recall@100 がどのように変化しているか示したのが以下です。
Mainstream ユーザーに関しては Recall が減少し、Power-Niche ユーザーについては微増するという結果になりました。Power-Niche ユーザーはこの手法で重みをかけた部分になるので Recall の改善があるのは期待どおりでしょう。ついでに Light-Niche ユーザーの体験も向上していたら嬉しいと思っていましたが、そう上手くはいかないようです。
この結果は論文では Figure 5 にあたります。論文ではどのデータセットでも Power-Niche ユーザーでの Recall@20 が向上していることを報告しているので、この結果は論文と合致すると言えます。他のセグメントでは論文でも使うデータセットによってばらついているので、一貫した傾向変化はないようです。
まとめ このブログ記事では、ニッチなアイテムに嗜好性があるヘビーユーザーの存在に着目して人気バイアスの緩和を実現する手法を提案した論文を紹介し、Wantedly における実データを用いた検証の結果も紹介しました。
人気バイアスは、実プロダクトにおけるユーザー体験を考える上では非常に重要な課題です。これからも積極的に最新の知見を取り入れ、データサイエンスの力でより良いマッチング体験の提供とユーザー課題の解決を推進していきます。

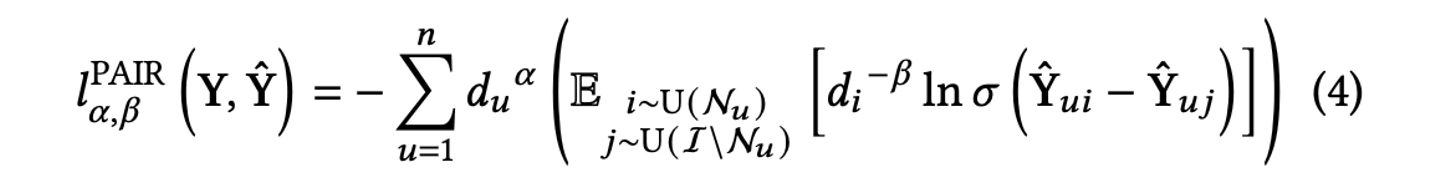
/assets/images/20737273/original/ba3d2c63-f0b7-4bce-899c-fc5d90f59700?1742873917)

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


