
相互推薦システムを活用したユーザーと企業の双方の嗜好を考慮した推薦 | Wantedly Engineer Blog
こんにちは、ウォンテッドリーでデータサイエンティストをしている林 (@python_walker) です。ウォンテッドリーでは、テクノロジーの力で人と仕事の適材適所を実現するために推薦システムの...
https://www.wantedly.com/companies/wantedly/post_articles/903172
こんにちは。ウォンテッドリーでデータサイエンティストをしている市村です。
Wantedly Visit ではユーザーへの募集の推薦などにおいて相互推薦システムによる推薦を提供しています。相互推薦システムでは、推薦を受け取るユーザーの嗜好と、推薦される側の嗜好の両方を考慮して推薦を生成します。この2つの嗜好スコアをどのように集約するかは重要な設計ですが、現状ではすべてのユーザーに対して固定の重みを使用しています。
本記事では、この集約機構をユーザーごとにパーソナライズする手法について、先行研究の再現実装と Wantedly Visit のプロダクトデータを用いた検証の結果を報告します。
はじめに
相互推薦システムとは
相互推薦における嗜好の集約
関連研究:Kleinerman et al. (2018)
検証
タスクと実装
評価方法
結果
考察
まとめ
参考文献
相互推薦システムとは、ユーザーを互いに推薦し合うシステムのことです。ユーザーは推薦を受け取る立場でありながら、他のユーザーに推薦される立場でもあるという特徴があります。求人マッチングやデーティングサービスなどがこの形態に該当します。
このようなシステムでは、推薦を受け取るユーザーが推薦されたものを気に入るという一方向の嗜好だけでなく、推薦される側が推薦を受け取るユーザーを気に入るというもう一方向の嗜好も必要です。この双方向の嗜好が成り立たなければマッチングは成立しません。
たとえば求人マッチングでは、ユーザーが気に入って応募した求人であっても、企業側がそのユーザーに興味を持たなければマッチングには至りません。ユーザーからすると良い返事が来ないという体験になり、企業からするとミスマッチな候補者からの応募が発生するという体験になり、ユーザー体験上の問題が生じます。
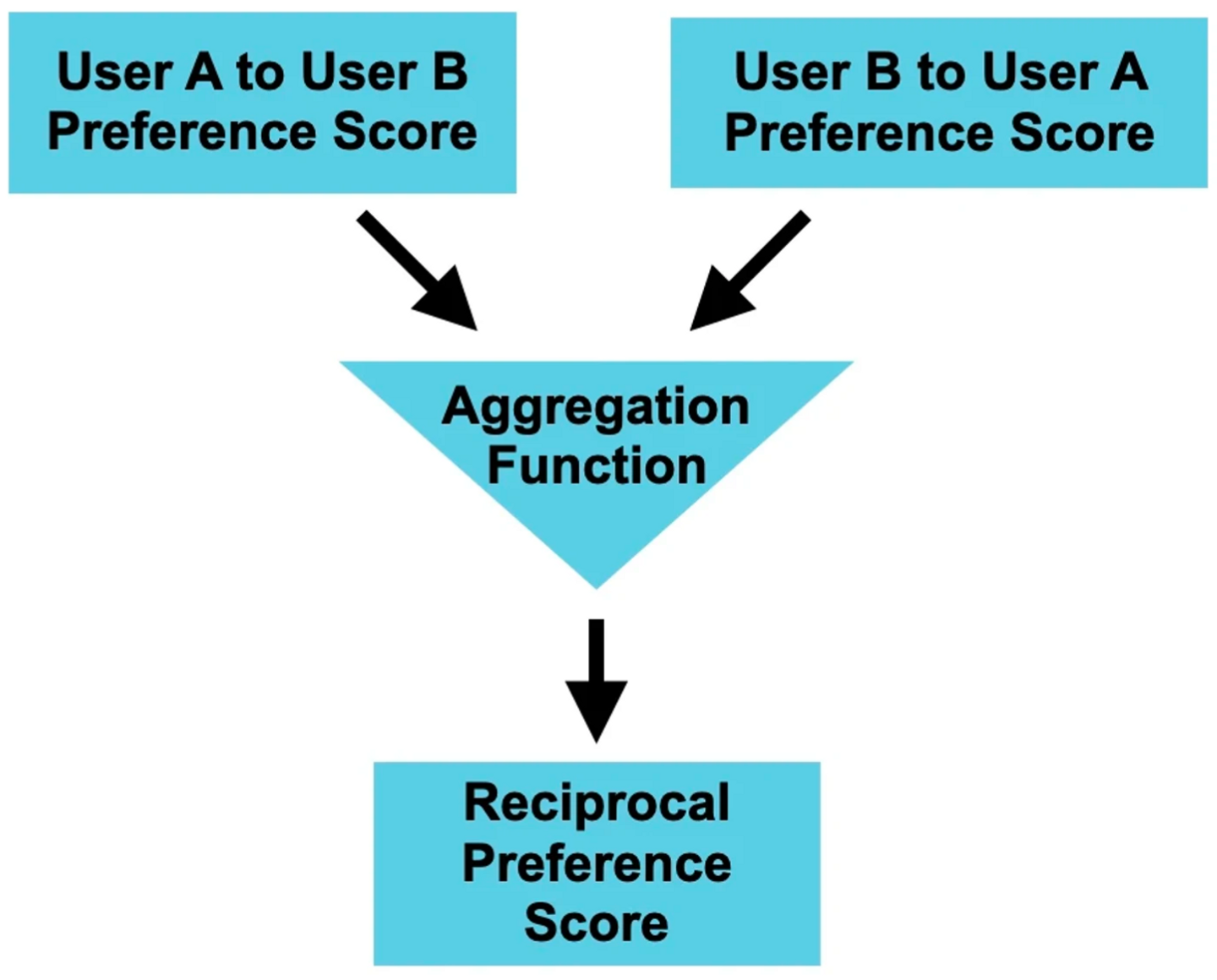
この課題に対応するため、相互推薦システムは一般的に以下の3つのモジュールで構成される、双方向の嗜好を考慮したアーキテクチャが採用されます。
私たちが開発・運用する会社訪問アプリ「Wantedly Visit」においても、ユーザーに対する募集の推薦や企業に対する候補者の推薦といったタスクで、このアーキテクチャを採用しています。詳細については過去にブログで紹介していますので、ご参照ください。
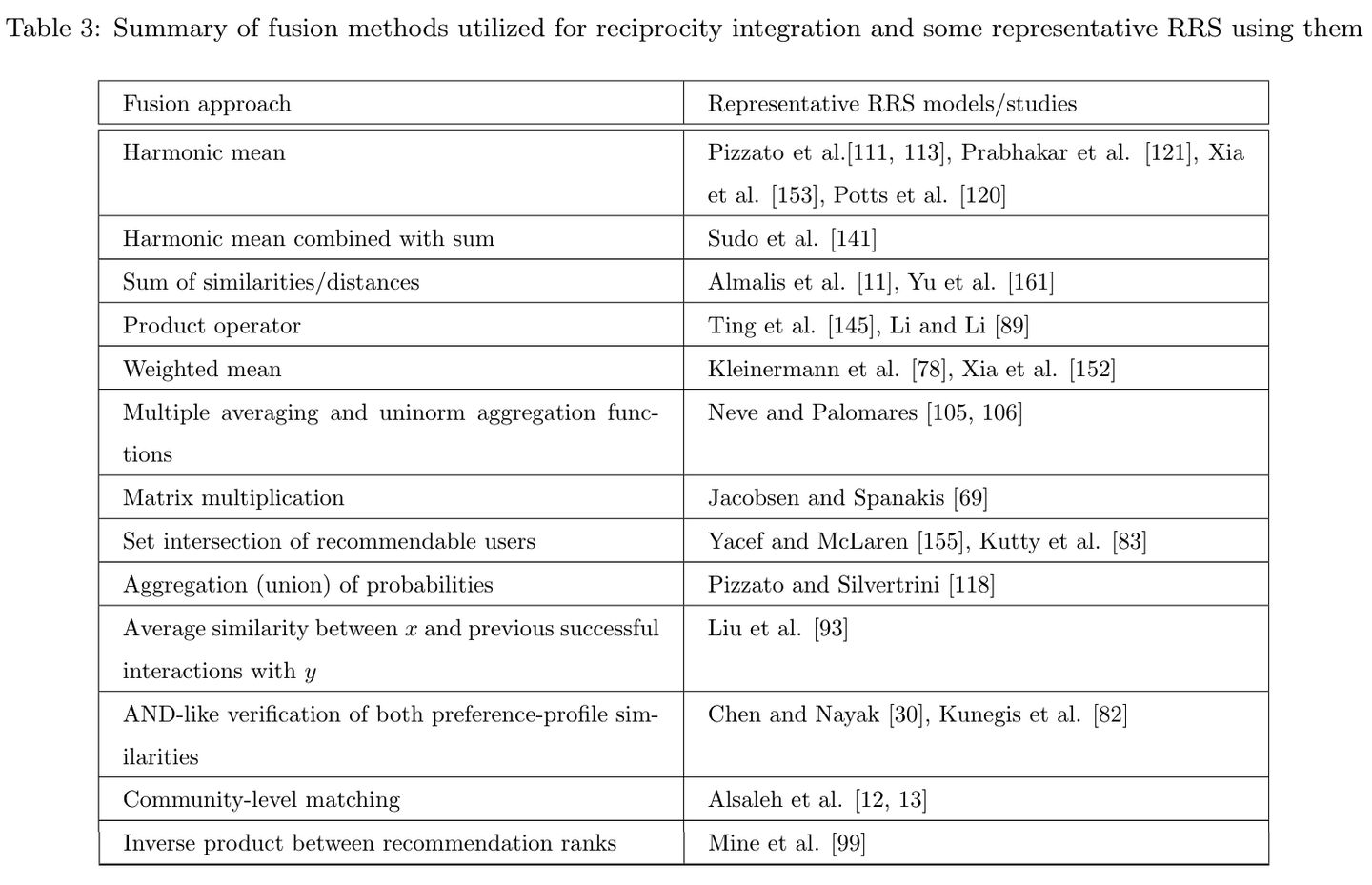
本記事で焦点をあてるのは、前述した3つ目の「嗜好スコアを集約するコンポーネント」です。2つの嗜好スコアをどのように統合するかは自明ではなく、過去の研究では算術平均、調和平均、幾何平均など様々な関数が用いられています。以下の表は、Palomares et al. (2021) で紹介されている、相互推薦に関する研究で取られているアプローチをまとめたものから抜粋したものです。各研究でそれぞれ異なるアプローチが取られており、統一的な最適解が存在しないことがわかります。
集約関数の選択に加えて、それぞれの嗜好をどの程度の重みで考慮するかも重要な設計です。相互推薦システムの最終目標はマッチングを生み出すことですが、マッチングに至るには応募などのアクションが必要です。そのため、相手側の嗜好予測以上に、まず起点となる行動を促すために応募の嗜好予測を重視するという方針も十分にありえます。どちらの嗜好をどの程度重視するかは、プロダクトの目的やユーザーの状況によって変わりうる問題です。
さらに言えば、最適な重みはユーザーによっても異なる可能性があります。条件を満たす募集に積極的に応募するユーザーであれば、応募は自然に発生するためマッチングしやすい募集を優先すべきでしょう。一方、応募に慎重なユーザーであれば、まず精神的ハードルを超えてもらうために魅力的な募集を優先すべきかもしれません。このように、それぞれの嗜好をどのようなバランスで集約するかは、ユーザーごとに最適解が異なる可能性があります。
ユーザーごとに集約の重みを最適化するアプローチに取り組んだ先行研究として、RecSys 2018 で発表された "Optimally Balancing Receiver and Recommended Users' Importance in Reciprocal Recommender Systems"(Kleinerman et al.)があります。
この論文では、オンラインデーティングを題材に、ユーザーの過去のインタラクション履歴をもとに各ユーザーに対して最適な集約重みを決定する手法を提案しています。具体的には、推薦を受け取るユーザーが推薦されるユーザーに興味を持つ度合い(CF)と、推薦されるユーザーがメッセージにポジティブな返答をする確率(PR)の2つのスコアを算出し、これらを重み付き線形結合で集約します。
重み α はユーザーごとに最適化されます。最適化の目標は、過去に成功したインタラクション(ポジティブなメッセージを得た相手)がランキング上位に来るような α を見つけることであり、実装にはブレント法が用いられています。
論文ではオンラインデーティングサービスでの A/B テストにより、成功したインタラクション数の増加と、人気ユーザーへのメッセージ集中問題の緩和が報告されています。
Wantedly Visit のプロダクトデータを用いて、Kleinerman et al. (2018) の手法を検証してみます。
検証対象のタスクは、ユーザーに対して募集を推薦するタスクです。
原論文では2つのスコアを重み付き加算で集約していますが、今回の検証では調和平均の重みを最適化する形で実装しました。具体的には、以下の調和平均における重み β をユーザーごとに最適化します。
β の最適化には原論文と同様にブレント法を用い、過去の成功インタラクションをもとにランキング損失を最小化する β を探索しました。以下は実装のイメージです。
import numpy as np
from scipy.optimize import minimize_scalar
def personalized_harmonic_mean(apply_score, match_score, beta):
"""
パーソナライズされた調和平均
β が大きいほど応募スコアを重視、小さいほど相手側スコアを重視
"""
return 1.0 / (beta / apply_score + (1 - beta) / match_score)
def compute_ranking_loss(beta, apply_scores, match_scores, is_success):
"""
βに対するランキング損失を計算
損失 = 成功インタラクションの順位の合計
"""
scores = personalized_harmonic_mean(apply_scores, match_scores, beta)
ranks = np.argsort(np.argsort(-scores)) + 1 # 高スコア順にランク付け
return np.sum(ranks * is_success)
def optimize_beta_for_user(apply_scores, match_scores, is_success):
"""
Brent法で最適なβを探索
"""
objective = lambda beta: compute_ranking_loss(
beta, apply_scores, match_scores, is_success
)
result = minimize_scalar(objective, bounds=(0.01, 0.99), method="bounded")
return result.x
# 使用例:ユーザーごとに最適なβを計算
user_betas = {}
for user_id, data in user_data.items():
if sum(data["is_success"]) > 0: # 成功インタラクションがあるユーザーのみ
user_betas[user_id] = optimize_beta_for_user(
np.array(data["apply_scores"]),
np.array(data["match_scores"]),
np.array(data["is_success"]),
)今回は A/B テストではなく、過去のログデータを用いたオフライン評価を行いました。ベースラインとして、全ユーザーに固定の重みを適用するロジックを使用しました。また、評価対象は過去に成功インタラクションの実績があるユーザーに限定しています。これは、Kleinerman et al. (2018) の提案手法では、成功インタラクション実績がないユーザーには個別最適化した重みを計算できないためです。
評価指標としては以下の3つを使用しました。
以下は各指標のベースラインからの変化率を記載したものです。
nDCG 指標は 2〜3% 程度悪化し、ユニーク募集数は約 17% 増加しました。原論文の A/B テストでは、成功したインタラクションに至る割合が有意に改善したことが報告されています。今回の検証ではマッチング成立を示す指標が悪化しており、この点は原論文とは異なる結果となりました。
原論文の A/B テストでは、成功したインタラクションに至る割合が有意に改善したことが報告されています。しかし今回の検証ではマッチング成立を示す指標が悪化しており、論文のような性能の改善は確認できませんでした。この原因として、オフライン評価における露出バイアスの影響が考えられます。オフライン評価で用いる正解データはベースラインの表示順序に依存しているため、提案手法によって順位が変わった募集は、たとえ実際には良いものであっても正解データに含まれない可能性があります。特に今回はランキング上位の募集が大きく変化していることがユニーク募集数の変化から示唆されるため、このバイアスの影響は無視できないと考えられます。
一方、ユニーク募集数は約 17% 増加しました。これは、固定の重みを使う場合は全ユーザーに対して同じ基準でスコアが計算されるため似た募集が上位に来やすいのに対し、ユーザーごとに異なる重みを適用することで推薦される募集がユーザー間で分散するためと考えられます。原論文でも推薦される相手の人気度が低下したことが報告されており、重みのパーソナライズによって推薦が分散化するという同じメカニズムが確認できました。
この推薦の分散化は、相互推薦システムにおいて重要な意味を持ちます。推薦が特定のアイテムやユーザーに偏ると、推薦される側にはキャパシティの限界があるため、集中した好意のすべてに対応することができません。一方、まったく推薦されないアイテムやユーザーはマッチングの機会を得られないままになります。推薦の偏りを是正することは、ユーザー体験の向上やプラットフォームの公平性といった観点に加え、キャパシティを超えて無駄になっていた好意が適切に配分されることでサービス全体のマッチング数が増加するという、ビジネス上の観点からも重要です。
以上より、今回のオフライン検証では論文のようなマッチング性能の改善を確認することはできませんでしたが、推薦の分散化という観点では原論文と同様の傾向が確認できました。オフライン評価には露出バイアスなどの限界があるため、マッチング性能についても実効果を正確に測るには A/B テストが必要と考えられます。今後の方向性としては、A/B テストによる実効果の検証や、成功インタラクション経験がなくても何らかの行動履歴があれば重みを最適化できるような手法の拡張が考えられます。
相互推薦システムにおける集約機構のパーソナライズについて、先行研究(Kleinerman et al. 2018)の手法を Wantedly のプロダクトデータで検証しました。
オフライン評価の結果、マッチング性能の改善は確認できなかったものの、推薦の分散化という観点では原論文と同様の傾向が確認できました。推薦の分散化は、ユーザー体験の向上、プラットフォームの公平性、そしてサービス全体のマッチング数の増加という複数の観点で重要な意味を持ちます。集約機構のパーソナライズがこの分散化を促進するメカニズムを持つことが示唆されたのは、今回の検証の重要な収穫です。
マッチング性能については、オフライン評価特有の露出バイアスの影響が考えられるため、実効果を正確に測るには A/B テストが必要です。原論文では A/B テストにおいて成功したインタラクション数の改善が報告されており、Wantedly のプロダクトにおいても同様の効果が得られる可能性があります。今後は A/B テストによる実効果の検証を進めるとともに、成功インタラクション経験がないユーザーにも適用範囲を広げるための手法の拡張や、スカウト推薦など他の相互推薦システムへの展開を検討していきたいと考えています。

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()
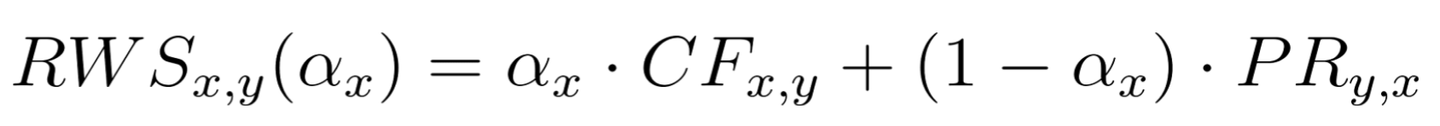
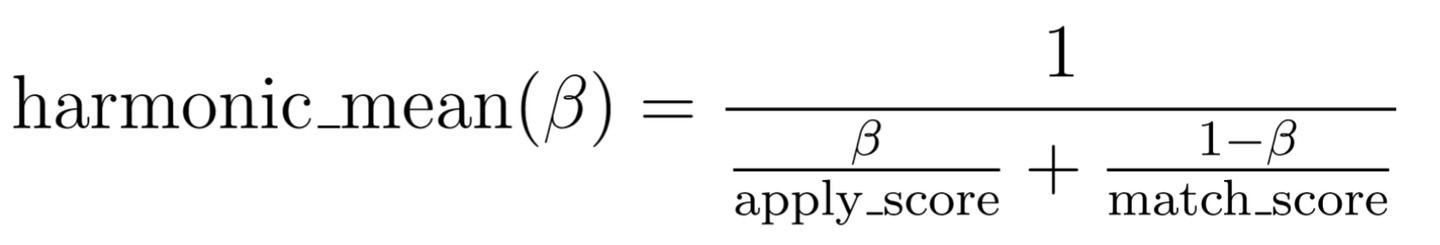
/assets/images/20737273/original/ba3d2c63-f0b7-4bce-899c-fc5d90f59700?1742873917)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

