【記事移行のおしらせ】
こちらの記事はバンダイナムコネクサスのTechBlogへ移行しました。
下記Linkよりご覧ください。
https://zenn.dev/bnx_techblog/articles/2694cbbda8b99b
データ戦略部データインフラストラテジーセクションでデータエンジニアリーダ兼、データストラテジストをしている藤井です。
現在、私の所属しているデータインフラストラテジーセクションは昨年12月に出来たばかりのセクションで名前のとおり、ネクサスの必需品である「データ」という必需品の基盤を支えるセクションです。
データインフラストラテジーセクションに関する詳細は、以下の記事を参照ください。
データ戦略部に関する詳細は以下の記事を参照ください。
今回は現在、データストラテジーセクションがグループ会社向けに構築しているデータ基盤について紹介したいと思います。
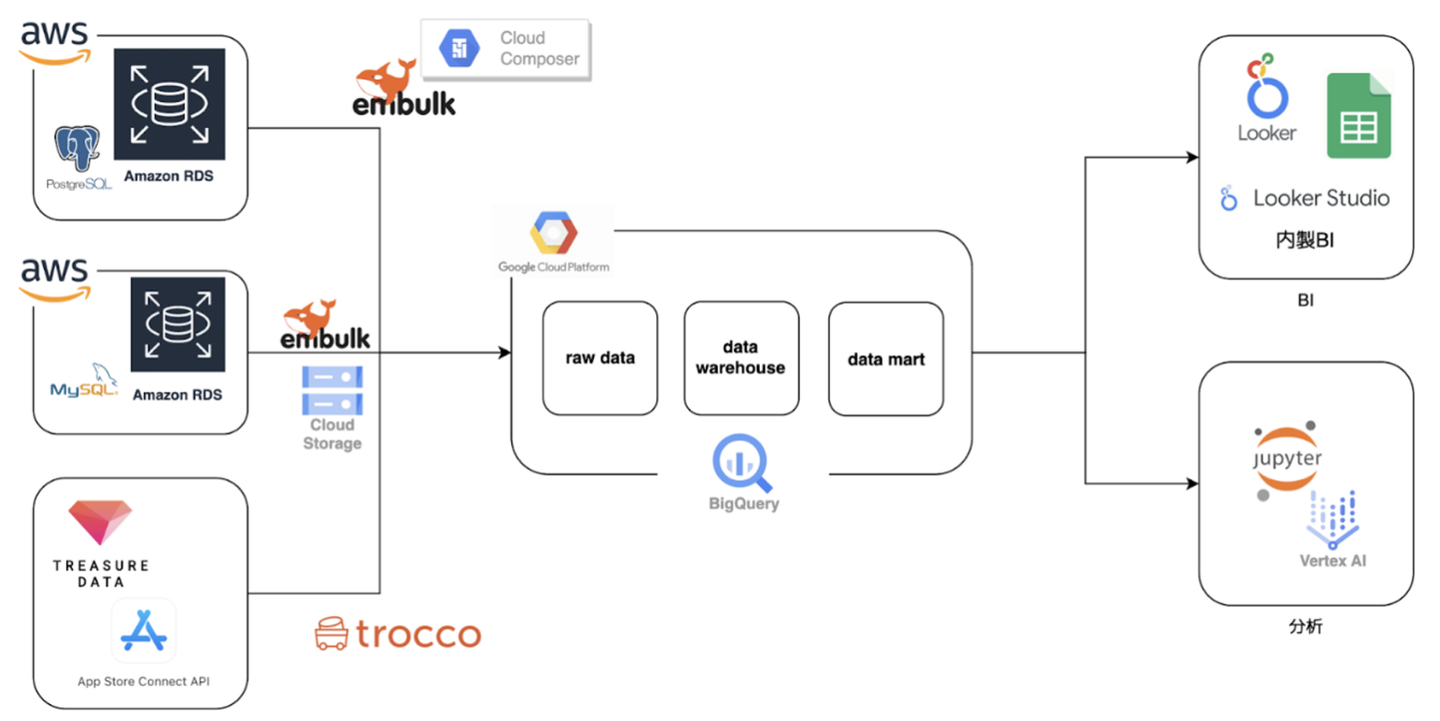
アーキテクチャ
アーキテクチャは以下のようになっています。よくあるデータ基盤構成になっているかと思いますが、今回はグループ企業、規模の大きい会社ならではのことを記述しつつ構成について詳細に紹介したいと思います。
![]()
技術スタックと採用基準
弊社では上記のとおりシステム環境としてGCPを採用しており、データレイク、データウェアハウス、データマートを全てBigQueryを利用しています。ワークフロー管理にはcloud composerまたはtroccoを利用し、シーンによって使い分けています。
BIは、Looker及びLooker studio、スプレッドシートを活用しており、分析環境はGCEまたはVertex AIを利用しています。
一方で、グループ各社のシステム環境はAWS、Azureといったクラウド環境をはじめオンプレで稼働しているシステムもあり、多種多様なデータ環境を考慮する必要があります。
アーキテクチャ自体はシンプルなのですが、この構成を採用した背景には以下のことが挙げられます。
- システム環境が会社ごとに全く異なることに加え、同じグループ会社といえど求められる機能・非機能要件も少しずつ異なる
- 少人数で対応する必要がある(立ち上げ当時メンバーは2名)
- スピーディーにデータ基盤、データレイクを構築したい
- 運用コストをできるだけ下げたい
特に1つ目のポイントのインパクトが大きく、取り扱っているデータの性質が多種多様で、グループ会社の数が多いバンダイナムコグループならではのポイントです。
後に必要となる品質チェックを含めた処理の共通化が非常に難しいですが、SaaS、GCPマネージドサービスに頼れる時は頼り、複雑性が増して来た時などいざという時は自前で開発できるような構成、体制にしています。
データパイプライン
データパイプラインは現在、接続元からBI層まで一気通貫のワークフロー管理はできておらず、様々な歴史的背景から、「DWH(またはデータレイク) ⇒ BI」の処理の多くは自社製のスケジュール管理システムまたは、BigQueryのスケジュールクエリを利用しています。
「接続元 ⇒ データレイク」へのパイプライン構築においては、以下の点に注意し構築しています。
これらの点に注意している背景としては、弊社は自社内で完結するパイプラインを組むことはほとんどなく、各グループ会社の環境に合わせたパイプラインを組む必要があることに由来しています。
- 管理、運用コストを下げられるものについては可能な限り下げる
- 「技術スタックと採用基準」に記述したとおりの背景で、パイプライン選定の基準をつくり、データの性質やセキュリティ要件を踏まえ、スクラッチ開発するか否かを判断する
- 組織をまたぐ体制であるため、一度決めたデータパイプラインのリアーキテクチャには時間がかかることに注意する
- 修正には開発コストだけでなくコミュニケーションコストも含めたコストを考慮して判断する
- 各組織や各プロダクトのデータ戦略を踏まえた取捨選択をする
- 全会社の全データを対象にすると時間も費用も膨大にかかってしまうため、データ戦略を踏まえて構築するデータ基盤の優先度決めや取捨選択を行う
- 会社、部署、プロダクトによって利用しているシステムおよびシステム環境が異なることはもちろん求められる機能、非機能要件が異なるため注意する
- 各グループ会社のシステム環境ごとに、機能要件、非機能要件をまとめて、パイプラインの実装を判断する
上記に注意し、どのようにパイプライン、ETLを組むか検討し開発を行なっています。
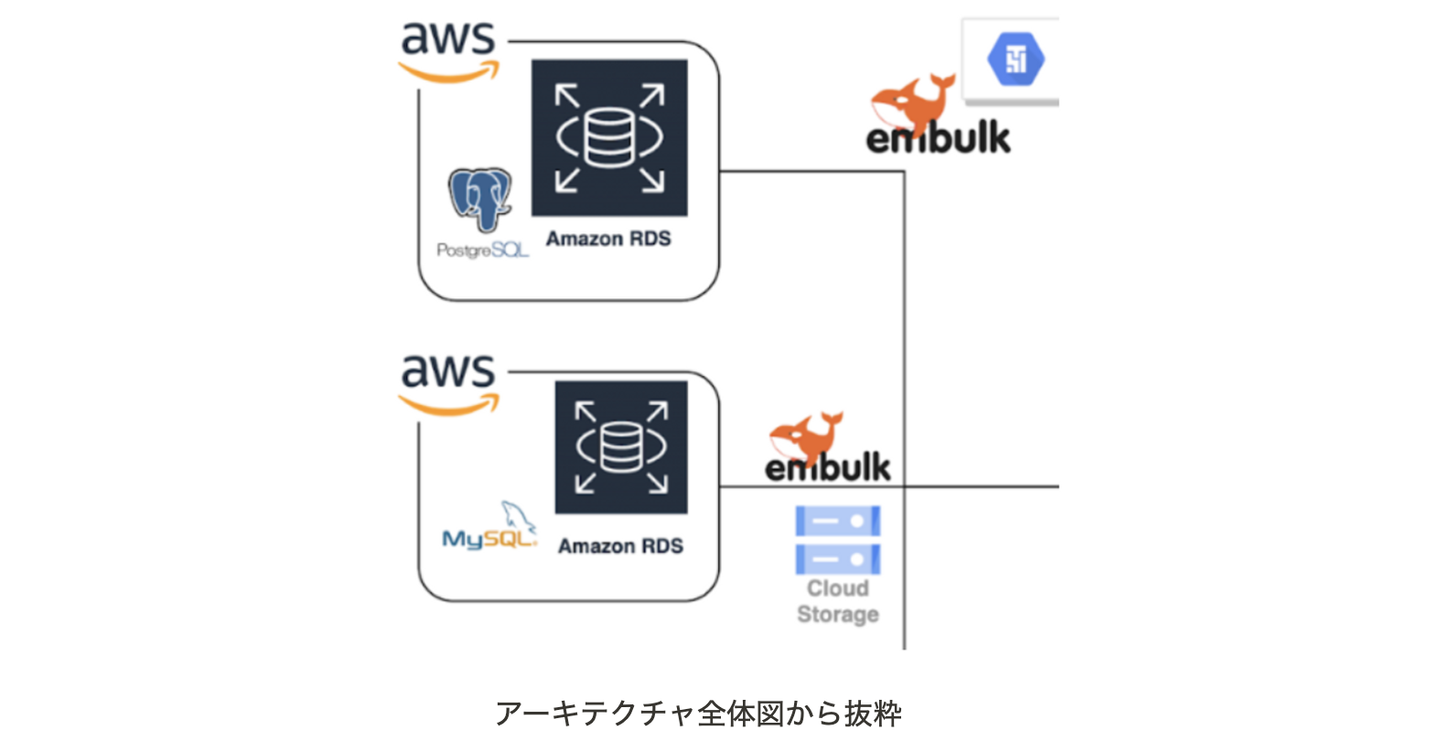
例として1つ挙げると、上記アーキテクチャ左上と左中は同じAWS環境からデータを取得していますが、異なる方法でETL処理を組んでおり、左上AWS環境からの取得はAirflowのマネージドサービスであるGCPのcloud composerを使い、SQLによるDB収集を行なっていますが、左中のAWS環境(MySQL)からの取得ではエクポート取得を選択してます。
![]()
これは、左中のAWS環境においてDBへの負荷考慮やセキュリティ要件から本番DB環境への接続を断念したためです。
代替手段としてエクスポート収集による方法で進めることにしましたが、この取得方法の懸念としてデータ基盤の開発側だけでなく、プロダクトの開発チームの運用、保守コストが増え、想定以上の工数とコストがかかる点が挙げられました。
そこで、ビジネス側と分析側双方に分析に必要なデータは限られていることを確認し、必要最低限のテーブルエクスポートを先方のエンジニアに依頼することで双方の開発、保守コスト、本番環境への影響を小さくする方法を取りました。
また、データ基盤チーム内で統一されたエクスポートファイルの出力形式や配置ディレクトリ構成などGCSへの配置方法を設計し、実装コードの共通化やコミュニケーションコスト削減、エラー検知しやすくする工夫をしました。
例えば、MySQLからエクスポート収集するデータは以下のようなディレクトリ構成に統一して取得しています。
├ raw
└ log
└ mysql_[db_name]
└ [table_name]
└ yyyyMMdd
├ tsv-yyyyMMdd.part1.tsv.gz
├ tsv-yyyyMMdd.part2.tsv.gz
├ ...
└ endfile.txt
endfile.txtは空ファイルですが、これが配置されていることでプロダクト側のエクスポート処理が正常に終了していることを確認し、後続処理を行っています。
以上のように、純粋な実装だけでなくデータマネジメントを含めた機能、非機能要件に注意した設計をPM、エンジニア、分析官を交えて設計初期段階から行なっています。
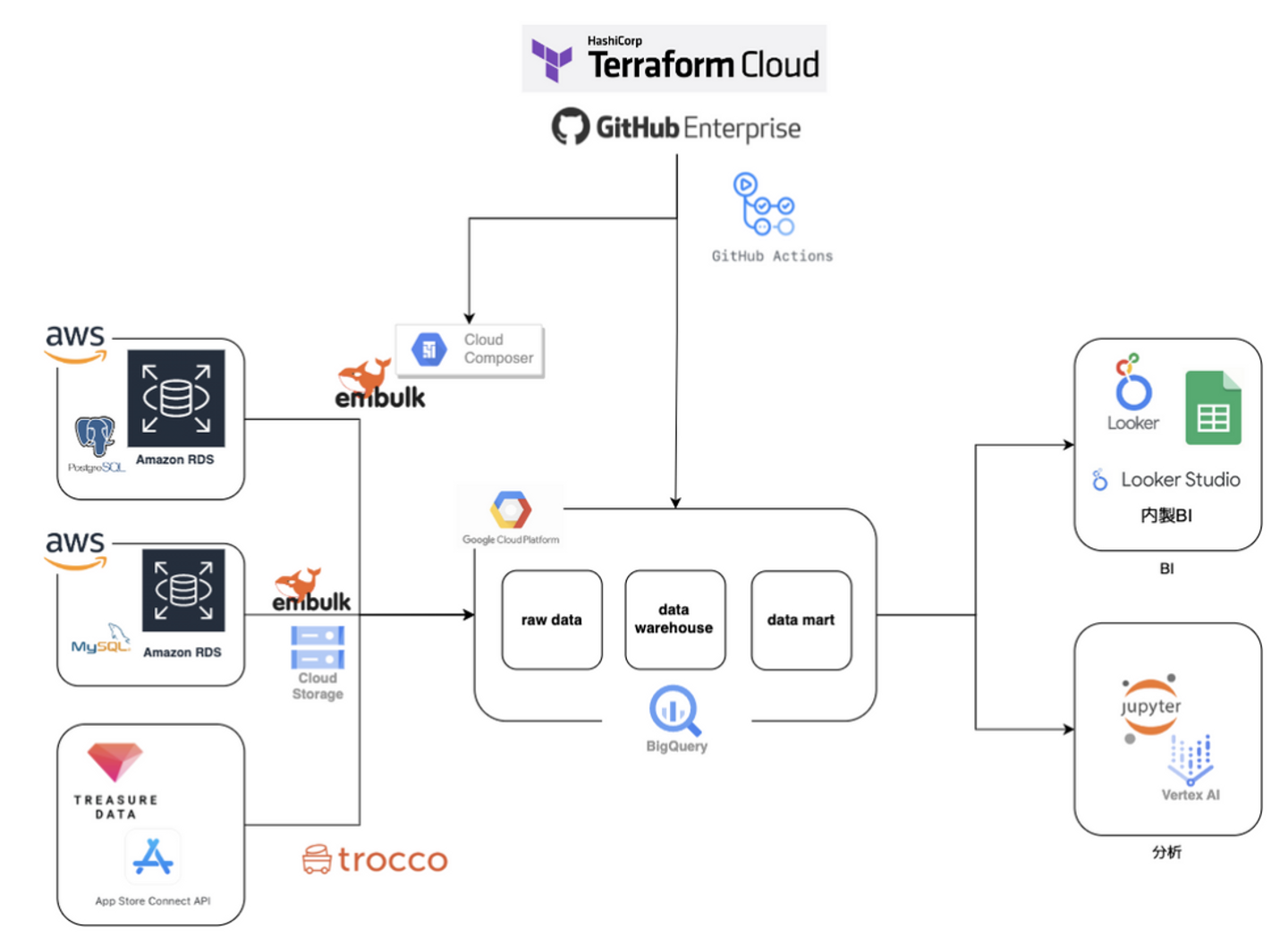
インフラおよびCI/CD
弊社では、インフラの9割以上をterraform cloudでコード管理しており、github actionsでCI/CDを組んでいます。
他の会社の事例や他の会社での経験では、データ基盤やデータレイク構築は本番環境のみしか存在していないケースやCI/CDが組まれていないことは多々ありましたが、弊社では本番環境だけでなく開発(sandbox)環境、ステージング環境を用意し、CI/CDの構築を行なっています。
他社事例で、環境分離を行なっていない背景には、分析案件をスピード感持って進めるために開発が優先されている点やデータ基盤および大量のデータ保持にコストをかけすぎたくないといった背景が考えられますが、弊社では本番環境の汚染によるデータ不具合やセキュリティリスクといったリスク面を考慮して環境分離とCI/CD構築に取り組んでいます。
![]()
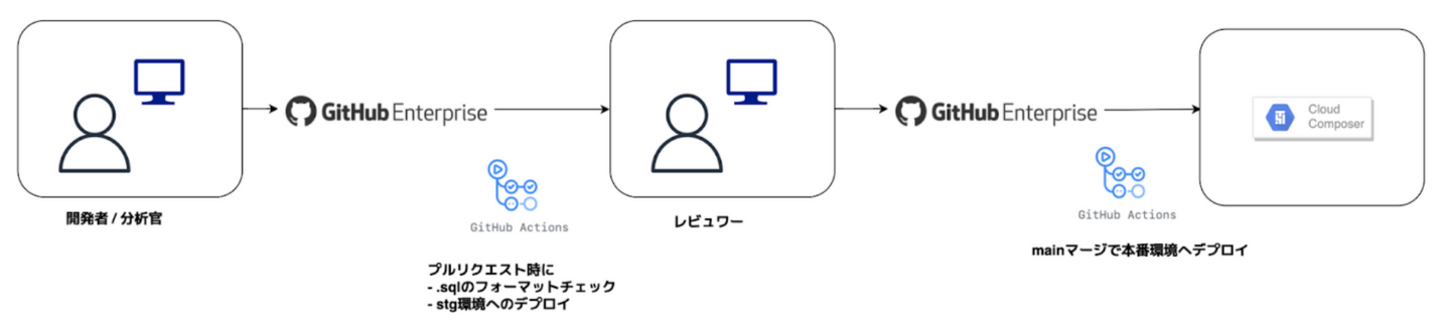
どのようなCI/CDを組んでいるかというと、ETL処理開発を行っている場合、ローカルまたは開発(dev)環境にて開発を行なった後、本番適応のためプルリクエストを出しますが、この時ステージング環境にDAGファイルまたはSQLファイルがアップされ、ここで動作検証、DAG解析結果の確認を行います。
この時SQLファイルはフォーマットチェックも同時に行われます。
その後、レビューを受けてmainマージすることで本番環境へデプロイされます。
この開発フロー、開発パイプラインはデータエンジニア以外(例えば分析官)も利用しており、分析官が書いたSQLをエンジニアが確認、レビューする体制を取っています。
![]()
インフラの場合は少し違っていて、上記のような仕組みは組んでおらず、プルリクエストのトリガーではterraform palnの実行とフォーマットチェックのみを行い、mainマージで対象の環境にデプロイされる流れになります。
つまり、ステージングと本番それぞれにデプロイをするプルリクエストを出してもらう体制を取っています。
なぜこのようにしているかというと、パイプライン開発のようなCI/CDを組む場合、terraformのコード管理のディレクトリ設計からしっかりと設計する必要があり、純粋な設計と実装難易度に加え、学習コストも高くなってしまいます。
そこで同じリポジトリ内で開発、ステージング、本番のterraformを管理しつつ、ディレクトリとコードは完全分離してしまいシンプルで可読性の高い設計にしています。
├ infra
├── prod
│ ├── iam.tf
│ ├── bigquery
│ │ ├── main.tf
│ │ └── tables.tf
│ ├── composer.tf
│ └── storage
├── stg
│ ├── iam.tf
│ ├── bigquery
│ │ ├── main.tf
│ │ └── tables.tf
│ ├── composer.tf
│ └── storage
└── dev
├── iam.tf
├── bigquery
│ ├── main.tf
│ └── tables.tf
├── composer.tf
└── storage
コード自体は冗長になってしまいますが、terraformのコード共通化の難しさやmoduleの設計から開放され、初学者でも理解しやすく、ステージング環境でしっかり確認をした上で本番反映用コードをデプロイできるのでかなり心理的ハードルは下がっているかと思います。
「リスク面を考慮して環境分離とCI/CD構築に取り組んでいる」とインフラ紹介の冒頭に記述しましたが、開発者の心理面を考慮した背景もあります。
現在データエンジニアチームメンバーはどこか特定の範囲の業務を行うのではなく、全員が幅広い業務に触れ、アーキテクチャの全レイヤーを触れることがあり、あまり実装経験のない領域にふれる恐怖を下げたい狙いがあります。
全員が幅広い業務に触れるのは少人数で取り組んでいるため、というリソース的側面もありますが、幅広い領域の知識と経験が求められるデータエンジニアリングにおいて担当領域を狭めず、実際に自分で手を動かし、知識共有していくことでチーム全体のスキルアップを目指しています。
今後の展望
お気づきの方もいるかと思いますが、現在のアーキテクチャおよびCI/CDにはデータのテスト、品質チェックプロセスが組まれていません。
現在データ課題、システム課題の整理が完了し、データ品質の軸やSLI/SLOの定義を行なっているところで、標準的なデータ品質チェック体制をつくるための設計、議論段階でまだまだこれからのフェーズです。エラー監視まわりもまだまだ不十分で強化が必要だと課題感を感じています。
データエンジニアチームが立ち上がって2年目となる2023年は上記を中心に力を入れていきたいと思います。
以上、弊社のデータ基盤についての紹介でした。
今後はデータエンジニアリングだけでなく、データマネジメントに関する記事もアップしていきますので是非よろしくお願いいたします!
最後まで読んでいただきありがとうございました。


/assets/images/21398270/original/3d6bad77-a316-4188-9b42-9cc30fa12eb8?1750395813)


/assets/images/21398270/original/3d6bad77-a316-4188-9b42-9cc30fa12eb8?1750395813)



/assets/images/11911367/original/QD3Kxba?1674532040)


