【re:Invent 2017】DynamoDB上級セッションレポート [DAT326, DAT403]【エンジニアブログより】

こんにちは。re:Inventから帰ってきました照井です。
re:Invent関連のブログでこれだけは書き上げておきたかった、re:InventでGameDayやAll-inハッカソンなどの体験型イベントを除いた通常のセッションの中で一番内容が濃く面白かったDynamoDBの上級者向けセッションのレポートをお送りしたいと思います。一つはイマイチでしたが、もう一つが最高に濃くて面白かったです。
DAT326: How DynamoDB Powered Amazon Prime Day 2017
Sales on Prime Day 2017 surpassed Black Friday and Cyber Monday, making it the biggest day ever in Amazon history. An event of this scale requires infrastructure that can easily scale to match the surge in traffic. In this session, learn how AWS and Amazon DynamoDB powered Prime Day 2017. DynamoDB requests from Amazon Alexa, the Amazon.com sites, and the Amazon fulfillment centers peaked at 12.9 million per second, a total of 3.34 trillion requests. Learn how the extreme scale, consistent performance, and high availability of DynamoDB let Amazon.com meet the needs of Prime Day without breaking a sweat.
こちらは、正直微妙でした。AmazonのECサイトでおそらく一番のアクセス数と注文数が来るであろうPrime Dayを支えたDynamoDBの中身や使い方を聞けると期待していたのですが、AmazonのDatabaseの歴史やDynamoDBの基本的な部分の話が多かったのと、ほとんどスライドを使用せずに漫談風というか説明ではなく冗談などを交えた語り口調でのセッションだったので英語が得意ではない私にはかなり聞き取りにくかったです。。。
そんな中で少し興味深かったのは、Prime DayにおけるDynamoDBの読み取り瞬間最高が
12.9M RPS(Read Per Seconds)という驚きの数字だということが明かされたのと、Amazonの注文データのスキーマが一部見ることができたことでした(写真がその注文データサンプルです)
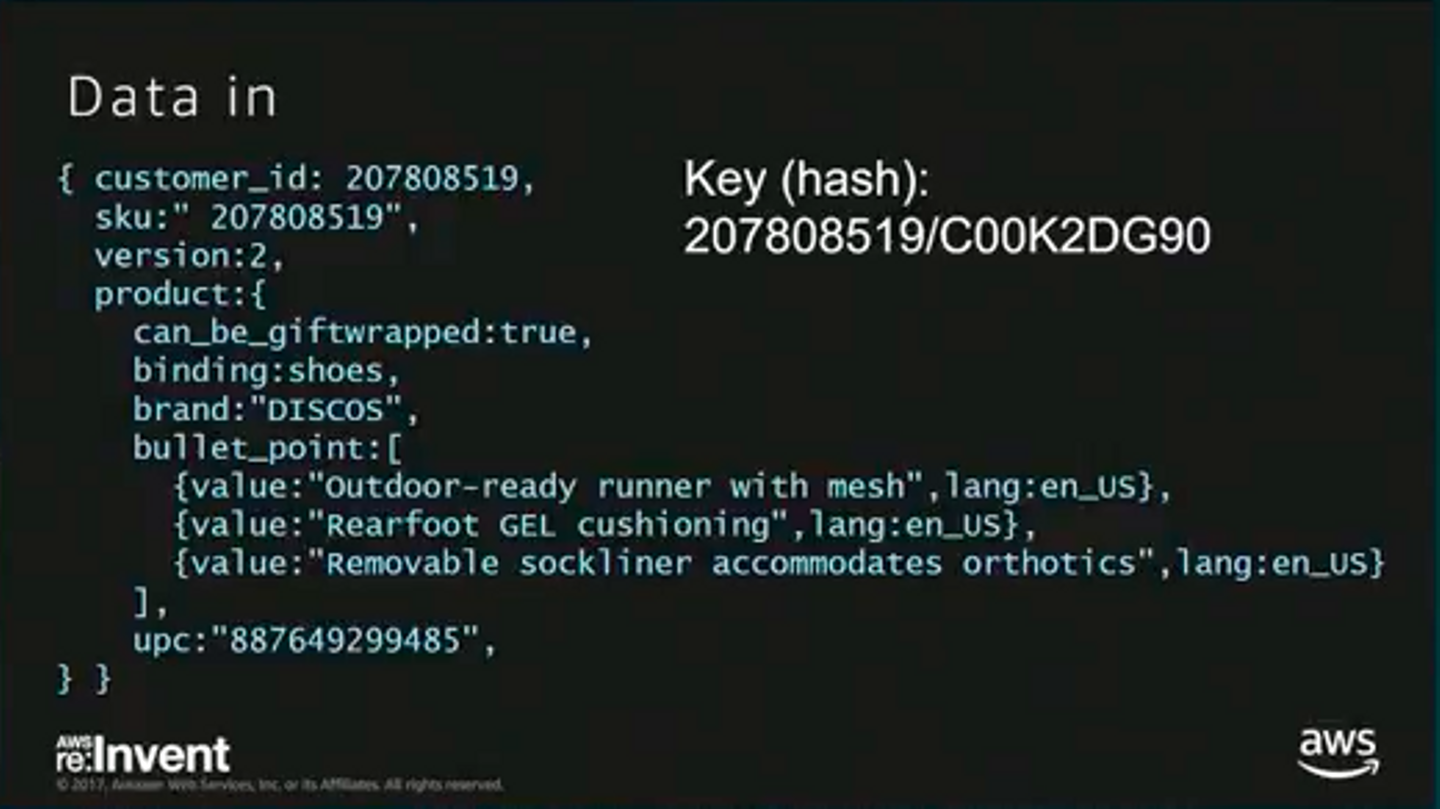
お分かりいただけるでしょうか?ポイントはHash Keyがおそらく
<customer_id>/<sku>であるということです。おそらく多いであろう顧客IDとSKUの組み合わせを一番高速に引けるようにHash(Partition) Keyにしてしまっているんですね(サンプルデータのskuがcustomer_idと同じになっているのは記載ミスと思われます。SKUの採番ルールと違うので)
そして、最後のまとめが偶然にもなんとなく次の良い感じの布石になっているのでご紹介しておきます。最後の
Remenber: schma, ACID, streamsが良いですね。
Summary
- Prime day is big
- single instance doesn't cut it
- Dynamo for scale--up and down
- Remenber: schma, ACID, streams
DAT403: Advanced Design Patterns for DynamoDB
This session, we go deep into advanced design patterns for DynamoDB. This session is intended for those who already have some familiarity with DynamoDB and are interested in applying the design patterns covered in the DynamoDB deep dive session and hands-on labs for DynamoDB. The patterns and data models discussed in this presentation summarize a collection of implementations and best practices leveraged by the Amazon CDO to deliver highly scaleable solutions for a wide variety of business problems. In this session, we discuss strategies for GSI sharding and index overloading, scaleable graph processing with materialized queries, relational modeling with composite keys, executing transactional workflows on DynamoDB, and much, much more.
こちらはDynamoDB関連セッションの本命で最高難度のレベル4(expert)のセッションになります。Advancedなデザインパターンということで、色々興味深いパターンが見られるのではないかと期待していったのですが、端的に言って最高でした。対象となるシステムの特性を踏まえながら、インデックスのアクセスパターンやデータモデリングに深く踏み込んで語られており、「俺はこういうのを求めてたんだ!」という感じでした。正直、こんなに齧りついてセッションを聞いたのは久しぶりでした(ボリュームがめっちゃあったので早口で聞くのに必死だったというのもありますがw間違いなどあったらすいません)
まずはじめに簡単なDynamoDBの特性とポイントが語られました。いくつか納得感があり印象的だったものだけご紹介しておきます。
- RDBはストレージに最適化している、NoSQLはコンピューティング(CPU処理)に最適化している
- リレーションシップはないのでnomalize(正規化)はせずに開き直ってde-normalize(非正規化)するように考える
- 関係性のあるデータはAggregation(集約)することを考える
- Event Driven Programing(DynamoDB StreamsやTriggerを上手く使う)
そして、具体的なデータ処理パターンを元に実践的なデータ設計パターンが語られていきました。出来る限りパターンを紹介したいと思います(超大作になりそうw)
書き込みのシャーディング(ハイトラフィックなデータエントリをハンドリングする)
まず、ハイトラフィックな書き込み処理はキューを使ってバランシングすべきであると語られました。
その上で、複数のテーブルに分散してデータを書き込むようにします。読み取り時は分散した書き込みを並列で読み取る、あるいは事前に分かっているパターンなら集約用のテーブルを用意し、定期的にAggrigationしておきそこを読みに行かせる、というパターンが紹介されていました。
また、一つのシャードテーブルから特定のデータを取り出すようなクエリを投げたいなら、テーブル名のSuffix(接尾辞)をキー項目のhashを取ることで得られるようにしておくと良いとのことです。
このパターンと合わせてDynamoDBのテーブル毎のパーティション数を計算するための計算式が紹介されていましたのでご紹介しておきます。
- Read: パーティションあたりのアイテム数 * 平均アイテムサイズ / 4kb(RCUの最大サイズ) * 平均リクエスト数 / 3000(パーティション毎の最大RCU)
- Write: 一秒あたりのアイテム数 * 平均アイテムサイズ(1kb未満なら1kbとして数える) / 1000(パーティション毎の最大WCU)
※RCU=Read Capacity Unit, WCU=Write Capacity Unit
時間ベースのワークフロー
ここで紹介されていたのは、まず最新のホットデータがありそのレコードは一定期間でexpireする、一定期間以上経過したデータはコールドデータとして別のテーブルに移していく、といったようなよくある時間(というか期間)ベースでデータのステータスが変わるワークフローのパターンでした。
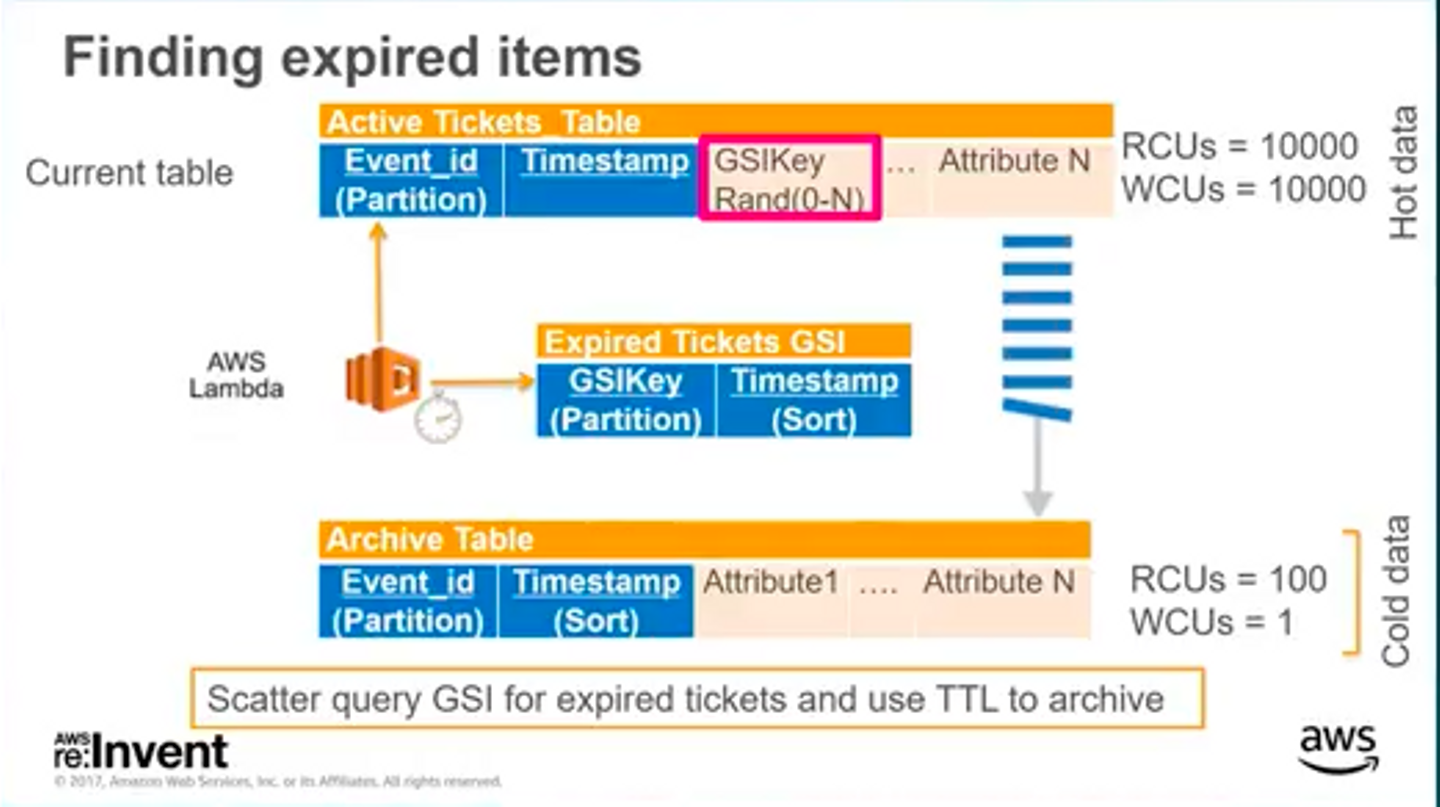
簡単に説明すると、アイテムを特定するIDとタイムスタンプをアイテムに持たせて、タイムスタンプを使ってDynamoDBのTTLでコールドデータに移していく所まではよくあるパターンという感じなのですが、それに加えてGSIで一定の範囲でタイムスタンプで検索できるようにランダムな整数をGSIキーとして付与します(このGSIキーの幅はデータ量やデータの有効期間などを鑑みて決めると良いでしょう)。これによって、TTLで削除されるタイミングはコントロールすることができませんが、expireしている(いない)データはGSIによって厳密に取得することが可能になります。
商品カタログ(人気アイテムのリード)
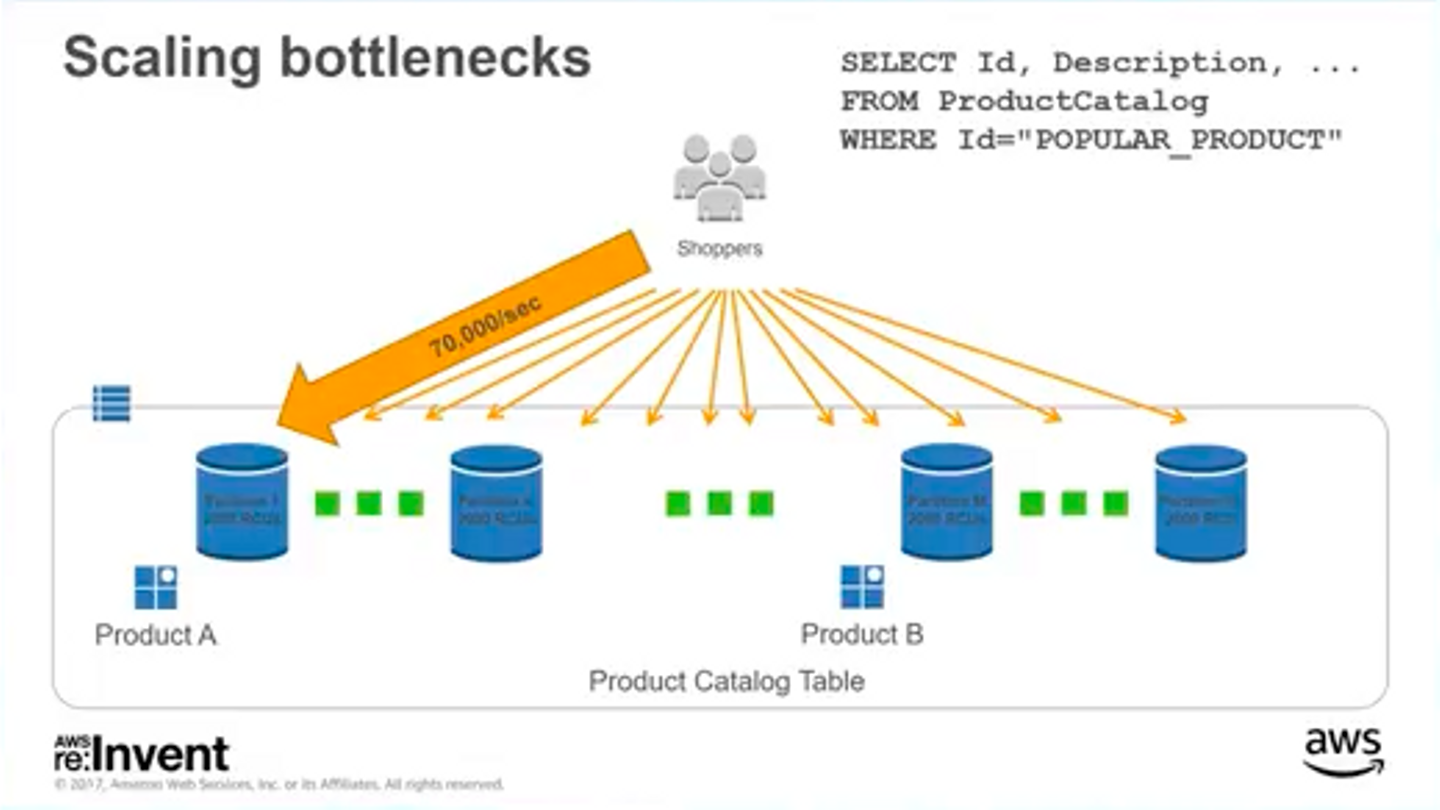
例えば、ECサイトの商品データは人気によってアクセスに偏りがでます、アクセスが偏るとアクセスされるパーティションも偏り性能のボトルネックとなってしまいます。これを避ける方法として、これはシンプルに「DynamoDB Accelerator(DAX)を使う」と紹介されていました(Python Clientまだかな・・・)
Targeting Query(選択的なクエリ)
複数の値でフィルタリングしたりソートしたりする必要があるデータの取得方法について、いくつかのパターンが紹介されていました。
- Query Filter
一つ目はDynamoDBのQueryオペレーションが持つフィルター機能を利用することです。これは一番シンプルですが、フィルタリングした部分はインデックスを使わないため効率が良くないことと、DynamoDBはフィルタリングする前のデータセットのサイズに対して課金が発生するためコストが高くついてしまいます - Composite Key
これは、前述のフィルターを使う手法に対する一つの答えです。クエリに使うキーを結合して1つの属性として保存にしておきます。イメージとしてはPartition KeyとSort Keyの2属性の組み合わせ(Partition KeyはHash IndexのようなものなのでB-treeという意味では1つ)しか利用できないインデックスに対してSort Keyに複数の属性を結合したものを持たせることでRDBなどで言う所の複合インデックスと同じような役割をさせることができます。
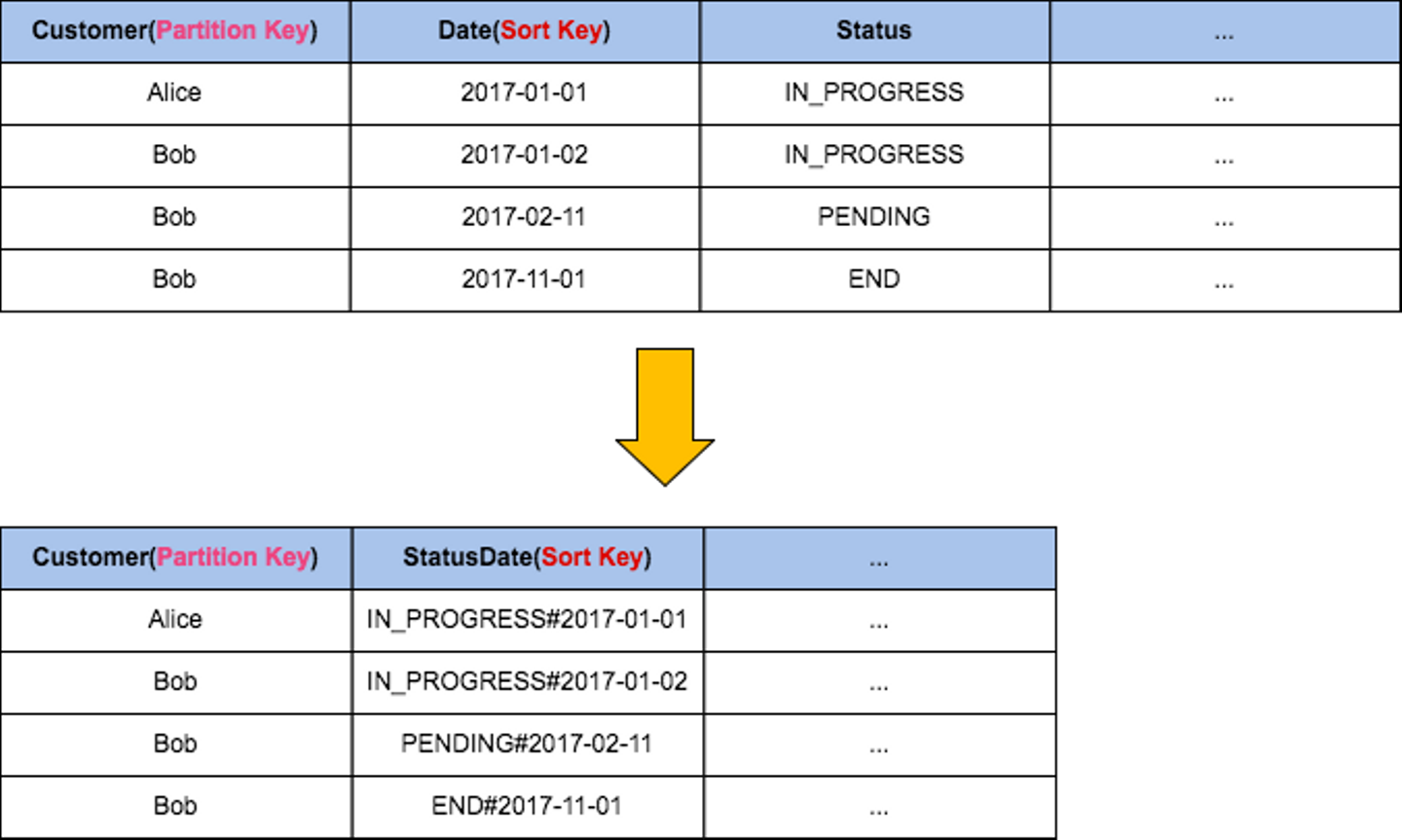
このように、顧客と対応ステータスのようなテーブルを考えてみましょう。上の表ではある顧客のある期間で特定のステータスのデータを取得したいと思った場合には、Customer(Partition Key)とDate(Sort Key)で検索した結果セットをStatusでフィルタリングすることになります。また、期間を指定せずに特定のステータスのデータだけを取得しようとする場合にはPartition Keyしか効きません。ですが、下の表のようにすると期間を指定せずにステータスだけ指定する場合でもB-tree Indexは前方一致はインデックスを利用して探索可能であるため有効になりますし、併せて期間を指定する場合でもインデックスを使った範囲検索が可能になります。ただ、逆にステータスを指定せずに期間だけ指定したい場合にインデックスが効かなくなるので、それも考慮するとDateとStatusDateは両方持っても良いかもしれません(これは私見です)
Sparse indexes
Sparse indexesとは、NULL値やundefinedな値を持つレコードをインデックスしない、全てのレコードを含まないインデックスのことです。これを上手く使うと下記のようなスコア一覧とアワードのような関係を効率的に上手く検索することができます。
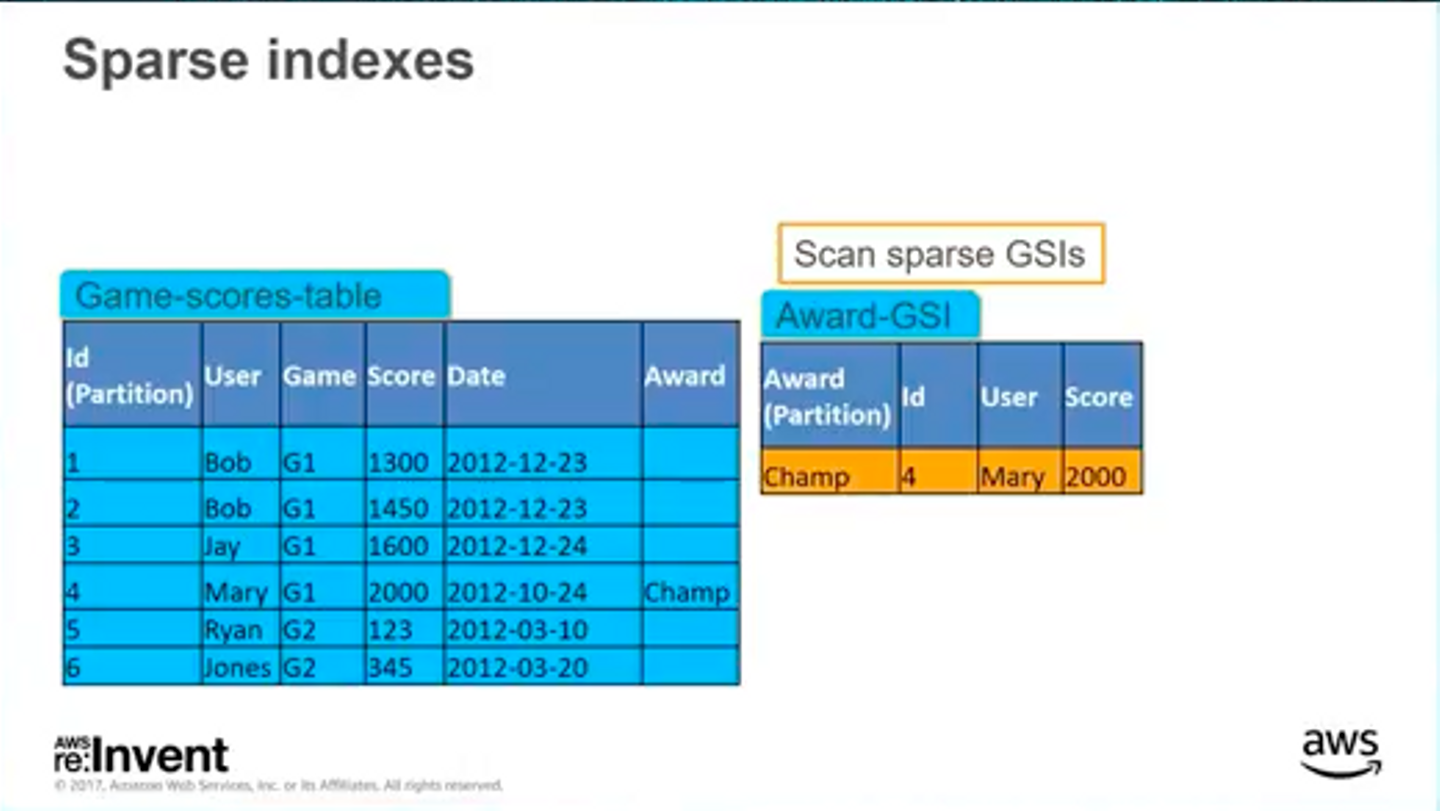
これまたぼやけていて見づらいですが、左表の右端のAward列に特定の値が1つのレコードにだけ設定されています。この属性にGSIを貼ると値が設定されていないレコードは除外されて設定されているレコードだけが検索対象となるため極端に走査対象が減り、とても効率的な検索が可能になります。
巨大なアイテムの垂直パーティショニング
ここでも先程のような顧客と対応ステータスのようなテーブルが例として出されていましたが、このようなデータはステータスの遷移によって必要なデータのサイズにばらつきが出てきます(始まったばかりと長い間対応しているものなど)。こういったデータに全ての情報を付与していると結果セットが巨大になってコストや性能的に厳しいことがあります。そういった場合には詳細なデータ部分を別テーブルに分割し、欲しければjoinさせるイメージで取得させます。
こういったデータはステータスが変わっても詳細なデータの部分については変化がなかったりするようなこともあるため、変化がなければ同じ詳細データを参照するようにすれば格納効率も良くなります。大きなデータはGSIによる射影を上手く使い、M:Nで対応づけることがポイントです。
Multi-version concurrency(複数のバージョンの並行操作)
ここではACIDトランザクションをエミュレートする方法が紹介されていました。
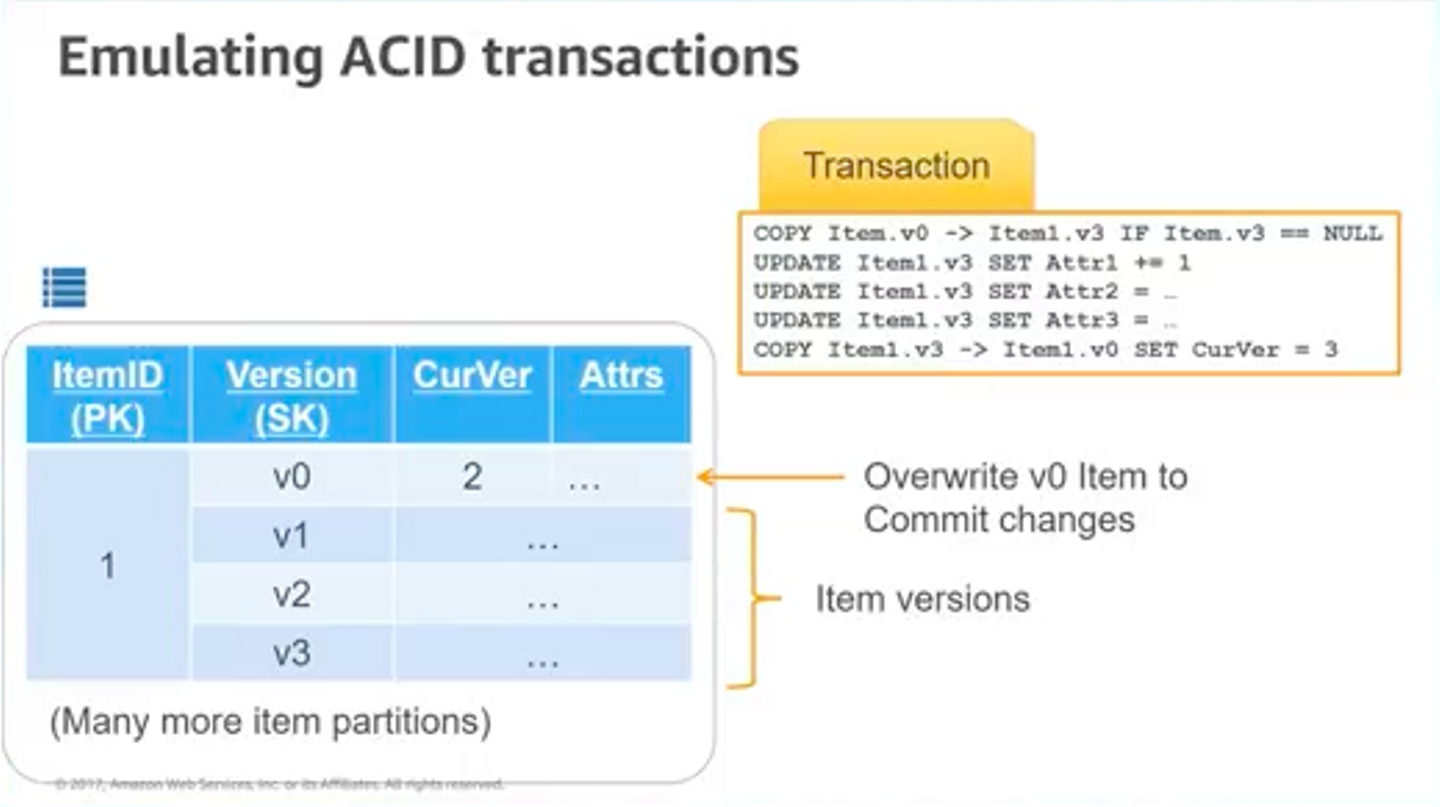
トランザクションをエミュレートする方法として、最新のデータを常に
v0として、トランザクション開始時に
v0の値をコピーした新しいバージョンを発行し、全て修了した時に
v0に書き戻す。
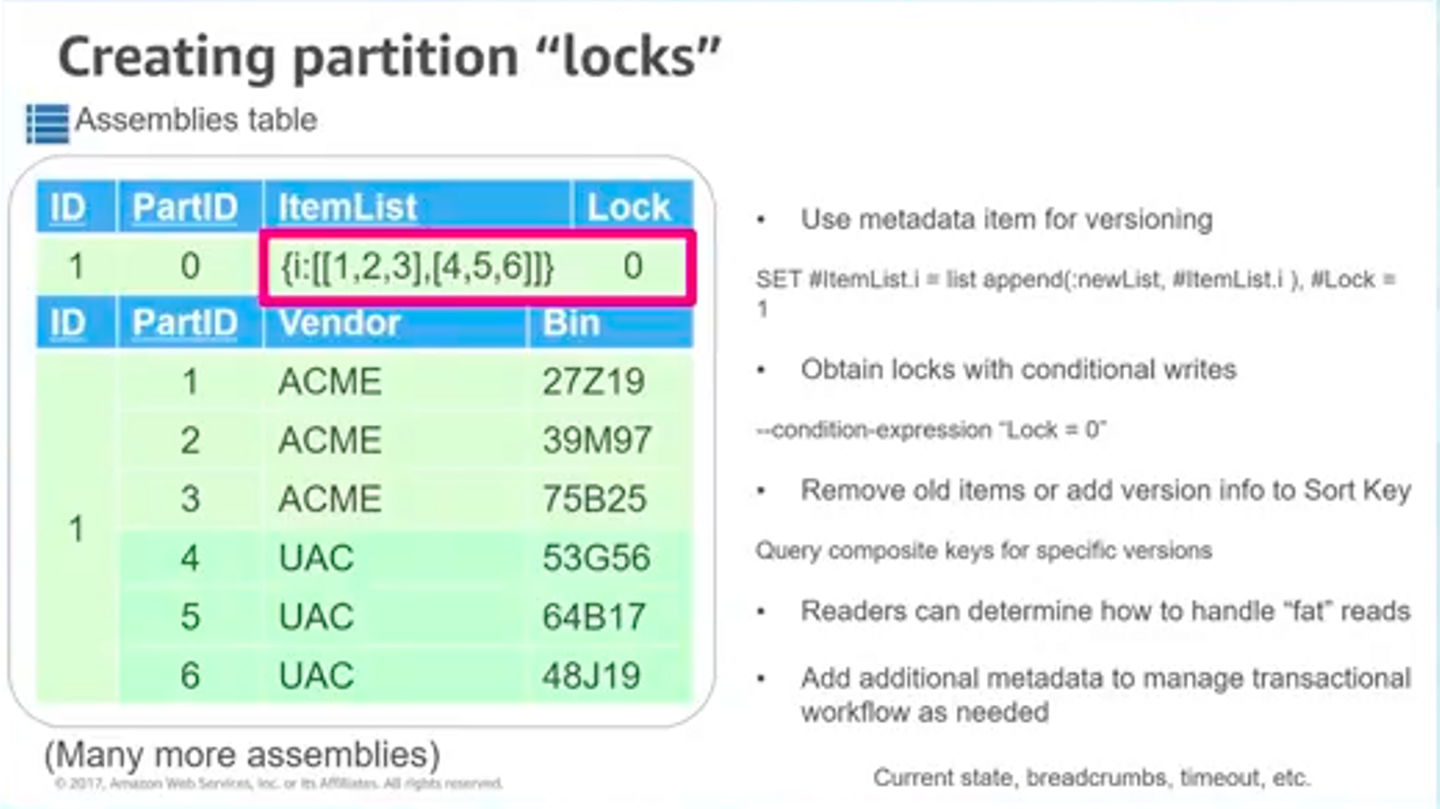
また、現在のバージョンのリストとロックのステータスも別に持たせることでロックを実現する(条件付き書き込みを使うことでロックを取れる)、というような手法が紹介されていました。
階層構造を持つデータ
これは「あ、これ進○ゼミ(SQLアンチパターンのナイーブツリー)でやったやつだ!」って感じだったのですが、関係を表現するのに結合キーを用いる(そのデータへ至るアクセスパスを持つキーを作る)手法が紹介されていました。もしくは階層構造を全てJSONでまとめて保存してしまい、DynamoDB Streams -> Lambdaで検索用のデータを別途作成するという方法もあるよねと話されていました。
その他
隣接リストとマテリアライズドグラフ、ebookの購読ステータスのようにユーザごとのセッションを記録したりユーザごとにマッピングを制御するようなパターンが紹介されていましたが、ちょっと理解が追いつかずまとめきれませんでした。
感想などよくあるセッションではわりと表面的な話が多いDynamoDBですが、データベースの本質はデータであり、データモデルはとても重要です。むしろそれこそが全てと言っても過言ではないと思います。とにかく濃くて頭が活性化する良いセッションでした。動画も公開されているので、見直して復習したいと思います。こういう濃いセッションがAWS Summitあたりで日本語でも聞ける日が来ることを願っています。
/assets/images/2686729/original/8eb834ec-052c-45cc-9c45-0f6436562322?1523253116)

/assets/images/1665806/original/e808559b-a750-42e4-b5be-3a629ab84bf2.jpeg?1496907715)

