こんにちは、技術3課の峯です。
先日2018/07/11にAmazon Transcribeでアウトプットの場所に自身のS3バケットを指定できるようになりました。これまではAmazon Transcribeで管理されているS3バケットに結果が保存され、ユーザーは署名付きURLから結果をダウンロードする必要がありました。今回は、Amazon Transcribeでアウトプットの場所に自身のS3バケットを指定した場合と、デフォルトであるAmazon Transcribe側のS3バケットを指定した場合を比べてみました。
自身のS3バケットを指定した場合
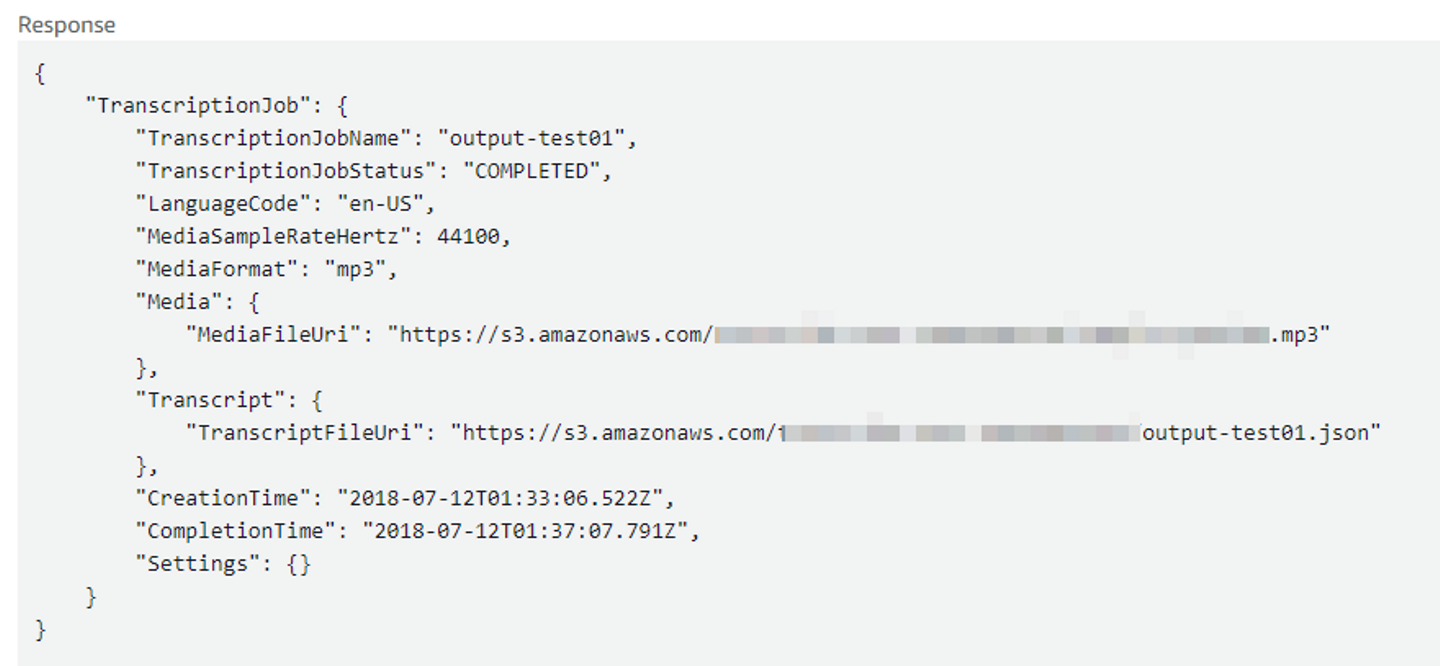
自身のS3バケットを指定した場合、GetTranscriptionJobのレスポンスのTranscriptFileUri には保存された結果ファイルのリンクが入ります。ちなみにファイル名は「”ジョブ名”.json」になります。
メリット
なんといっても、結果ファイルを一度どこかにダウンロードして自身のS3バケットへ保存する手間や仕組みが不要となることでしょう。実際のユーズケースとして、Amazon Transcribeのみを利用して、とりあえず文字起こしだけしたいということはほとんどないかと思います。結果ファイルを自身のS3バケットへ保存しておくことで他のAWSサービスと組み合わせやすくなります。これまでは自身のS3バケットへ保存するのにジョブのステータスの確認、結果のダウンロード、S3バケットへアップロードする手間・仕組みが必要でしたが、これが不要になるというわけです。
デメリット
Amazon Transcribeのコンソールから直接文字お越しされてた文章と話者の識別を確認できなくなります。文字起こしされた文章の確認は、結果ファイルをS3バケットからダウンロードもしくは何らかの仕組みで可視化する必要があります。また話者の識別に関しては結果ファイルには直接書かれていない、どの単語が何秒から何秒まで話されて、どの話者が何秒から何秒まで話したかが別々で記載されているので、それらを突合する何らかの仕組みが必要になります。デフォルトのAmazon Transcribe側のS3バケットを指定すると、コンソールからはどの話者がどの単語を話したかが確認出来るので、直観的な確認が出来なくなるのはデメリットといえると思います。
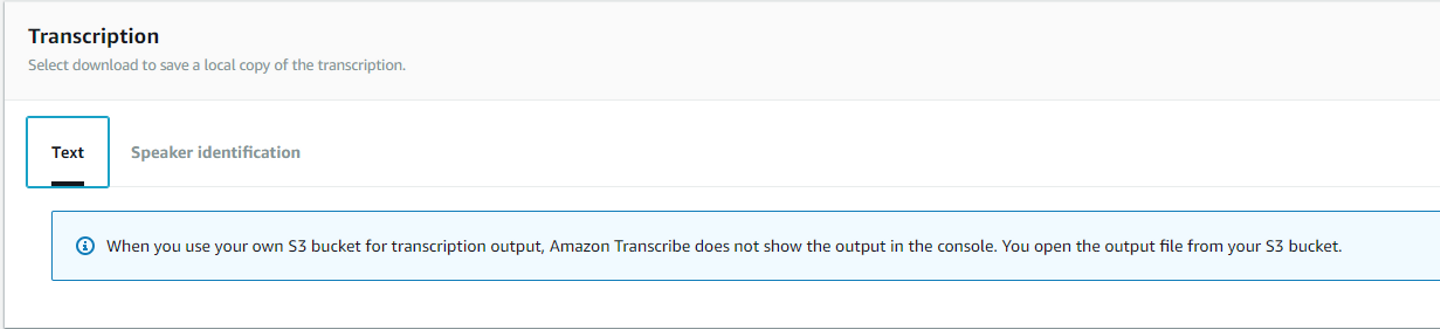
また、今のところ自身のS3バケットを指定する場合、パスまでは指定できないようです。つまり異なるジョブで同じS3バケットの異なるパスへ結果を保存するというのはできなくなります。
Amazon Transcribe側のS3バケットを指定した場合
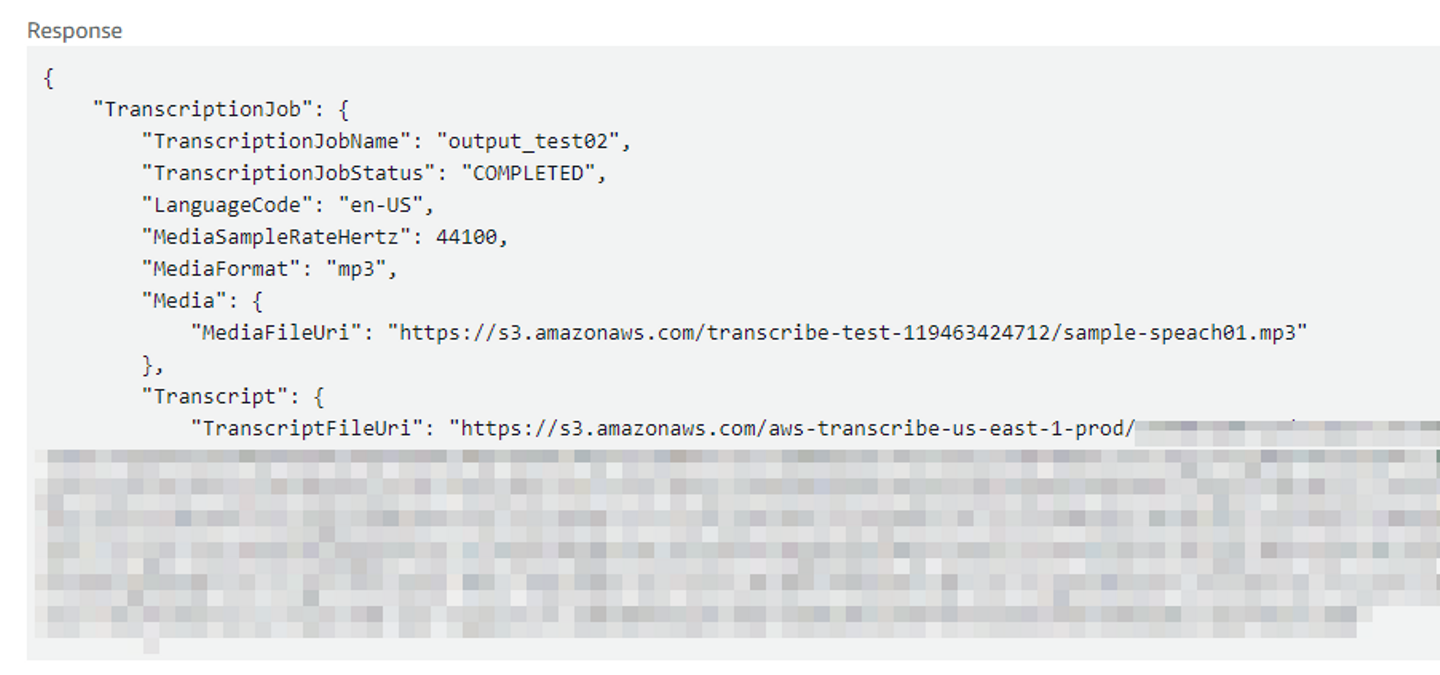
Amazon Transcribe側のS3バケットを指定した場合、GetTranscriptionJobのレスポンスのTranscriptFileUri には結果ファイルをダウンロードする署名付きURLが入ります。
メリット
前述したようにコンソールから結果が確認できることです。Amazon Transcribeの検証やデモなどで使う分には自身のS3バケットへ保存する必要もないので十分でしょう。
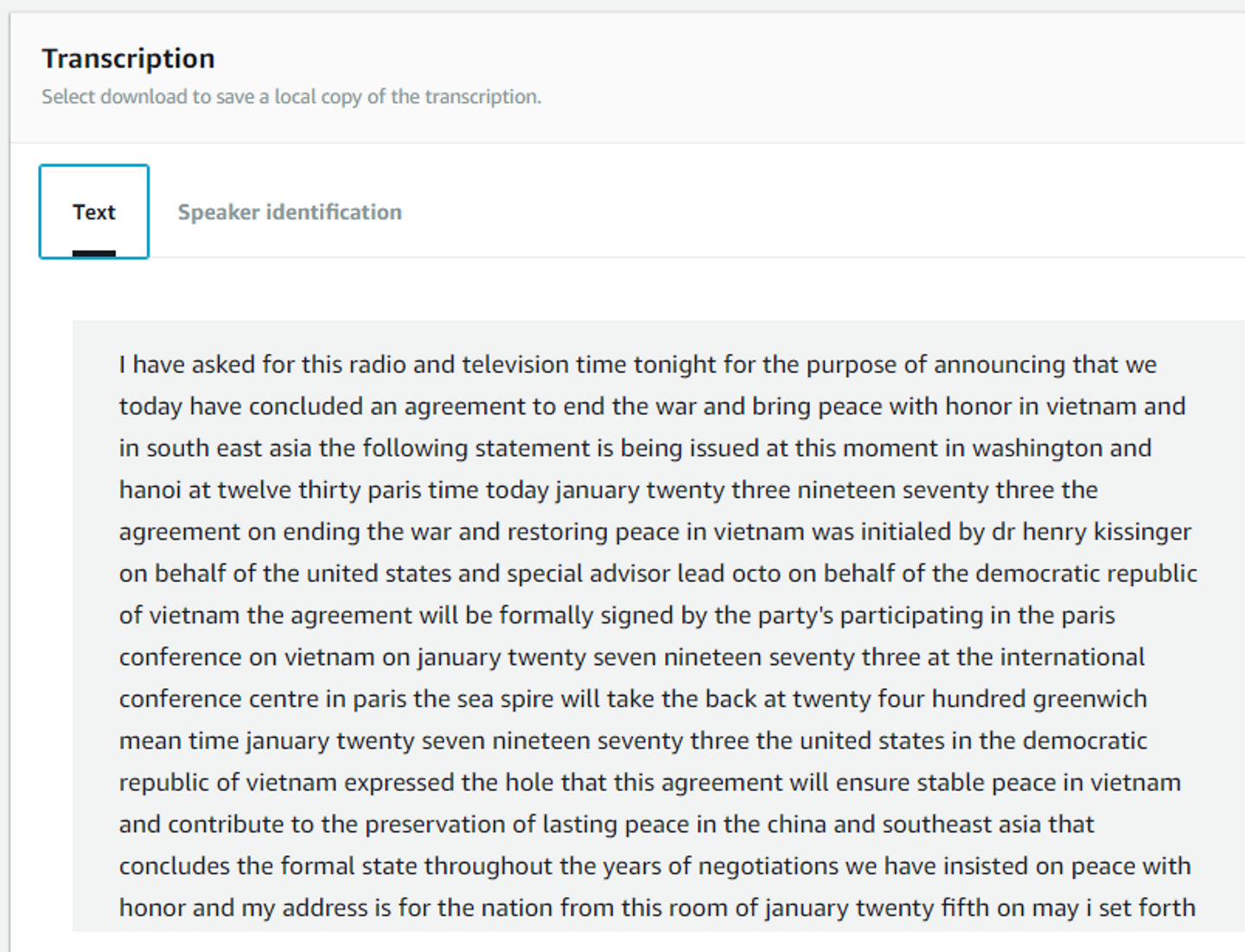
また、結果ファイルを自身のS3バケット特定のパス、もしくは他の場所へ保存したいということがあるかもしれません。その場合、署名付きURLからファイルをダウンロードし、そちらへ保存した方が自由が利きます。
デメリット
ダウンロードしたファイルを自由な場所に保存することはメリットですが、やはりその分、手間・仕組みが必要になります。
まとめ
AWSの他のサービスと組み合わせることを考えると、パスを指定できないという仕様を気にしなければ、個人的には自身のS3バケットへ保存した方がよい気がします。検証等で、文字起こしした文章をいろいろいじくって分析したい!なんてときはデフォルトのAmazon Transcribe側に保存しても全く問題ないと思います。
/assets/images/2686729/original/8eb834ec-052c-45cc-9c45-0f6436562322?1523253116)
/assets/images/1665806/original/e808559b-a750-42e4-b5be-3a629ab84bf2.jpeg?1496907715)

