
SageMakerとは
SageMakerとは、AWSの提供する機械学習のサービスです。
SageMakerのコンソールからノートブックインスタンスを起動して、JupyterNotebookを利用できます。
また、モデルのトレーニング用のコンテナを確保して利用したり、予測モデルホスティングのデプロイ作業を操作したりする機能も備わっています。
2018年6月より、東京リージョンでも利用が可能となっています。
ノートブックインスタンスの起動
SageMakerのコンソールより、「ノートブックインスタンスの作成」をクリックして、インスタンス名を入力するくらいで簡単に起動できます。
このノートブックインスタンスが起動している間は、EC2インスタンスなどと同様に、従量課金が発生します。
利用していない間は、Stoppedのステータスに変更もできます。
ノートブックインスタンス作成後、コンソールから「オープン」をクリックして、Jupyterにアクセスします。
新しく、「conda_python3」のノートブックを作成します。
Jupyter上での操作
今回は以下の流れで進めていきます。
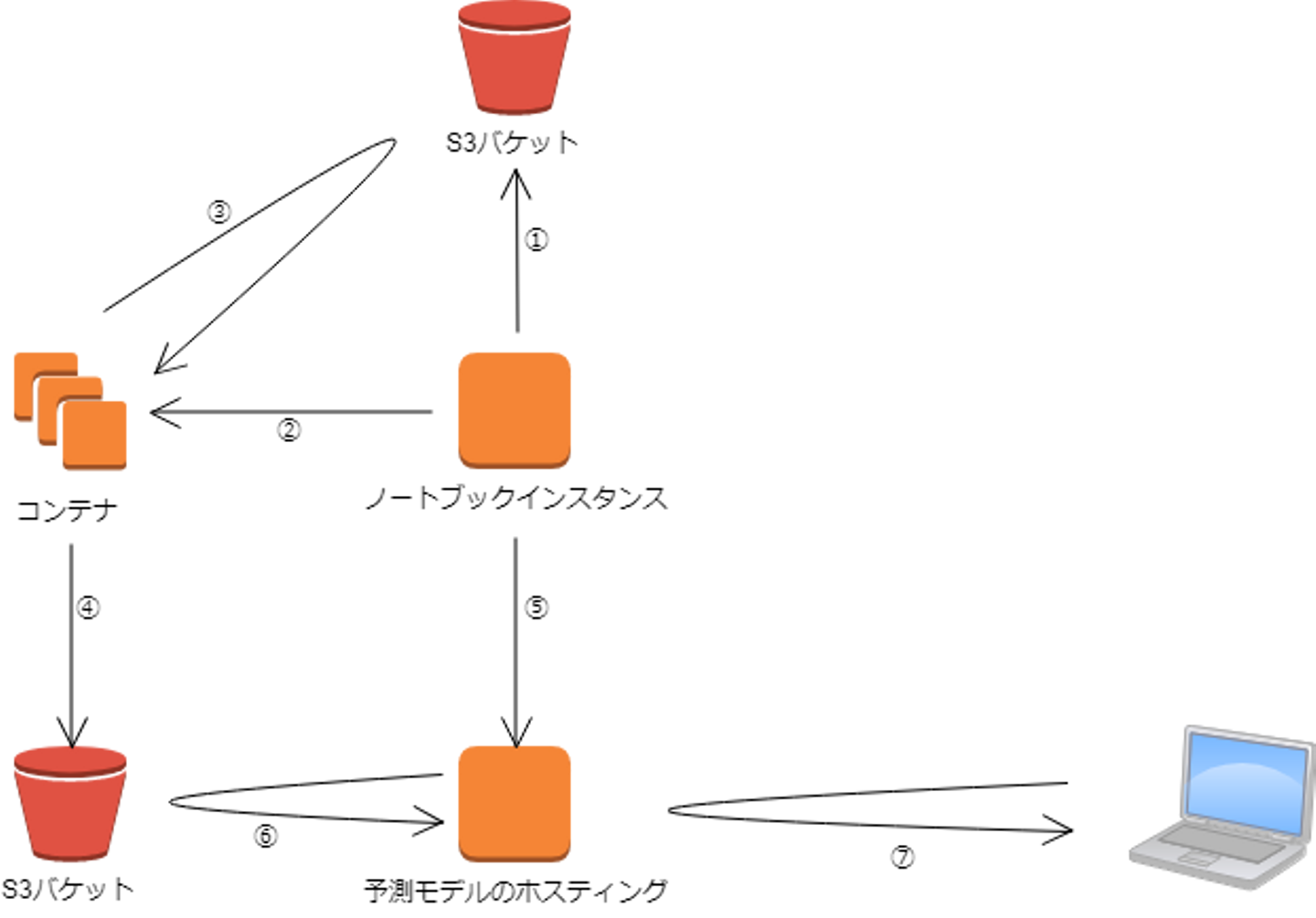
①JupyterNotebookからS3バケットにトレーニング用のデータをアップロードします
②JupyterNotebookからコンテナを起動します
③コンテナがトレーニング用のデータを取得してモデルをトレーニングします
④トレーニングしたモデルをS3バケットにアップロードします
④JupyterNotebookから予測モデルをホスティングするためのインスタンスを起動させます
⑥S3バケットにアップロードされているモデルをホスティングします
⑦エンドポイントにAPIを投げることで、予測を得られます
・データの生成
話を簡単にするために、乱数で以下のデータを生成します。
Y = 4 + 2 * X1 – 3 * X2 + 誤差
また、データを二つに分割してトレーニング用のものとテスト用のものに分けておきます。
import numpy as np
data_size = 250
train_size = 200
test_size = 50
dimension = 2
X_rand = 2*np.random.rand(data_size,dimension).astype(np.float32)
y_rand = (4+2*X_rand[:,0]-3*X_rand[:,1]+np.random.randn(data_size)).astype(np.float32)
X_train = X_rand[0:train_size,:]
X_test = X_rand[train_size:data_size,:]
y_train = y_rand[0:train_size]
labels = y_train.reshape(-1)
y_test = y_rand[train_size:data_size]・ライブラリのインポート
import boto3
import os
import re
from sagemaker import get_execution_role
import io
import numpy as np
import sagemaker.amazon.common as smac
import sagemaker
from sagemaker.predictor import csv_serializer, json_deserializer・S3バケットにトレーニング用のデータをアップロード
bucket = 'xxxxxxxxxxxxxxxx'
prefix = 'sagemakerlgtest'
key = 'traing_data'
buf = io.BytesIO()
smac.write_numpy_to_dense_tensor(buf, X_train, labels)
buf.seek(0)
boto3.resource('s3').Bucket(bucket).Object(os.path.join(prefix, 'train', key)).upload_fileobj(buf)bucketにはバケット名が入ります。・コンテナを指定
containers = {'us-west-2': '174872318107.dkr.ecr.us-west-2.amazonaws.com/linear-learner:latest',
'us-east-1': '382416733822.dkr.ecr.us-east-1.amazonaws.com/linear-learner:latest',
'us-east-2': '404615174143.dkr.ecr.us-east-2.amazonaws.com/linear-learner:latest',
'eu-west-1': '438346466558.dkr.ecr.eu-west-1.amazonaws.com/linear-learner:latest',
'ap-northeast-1': '351501993468.dkr.ecr.ap-northeast-1.amazonaws.com/linear-learner:latest'}・モデルをトレーニングして、結果をS3バケットに出力します
role = get_execution_role()
s3_train_data = 's3://{}/{}/train/{}'.format(bucket,prefix,key)
output_location = 's3://{}/{}/output'.format(bucket,prefix)
sess = sagemaker.Session()
linear = sagemaker.estimator.Estimator(containers[boto3.Session().region_name],
role,
train_instance_count=1,
train_instance_type='ml.c4.xlarge',
output_path=output_location,
sagemaker_session=sess)
linear.set_hyperparameters(feature_dim=dimension,
predictor_type='regressor',
mini_batch_size=20)
linear.fit({'train':s3_train_data}・モデルのデプロイ
linear_predictor = linear.deploy(initial_instance_count=1,
instance_type='ml.m4.xlarge')・予測
linear_predictor.content_type = 'text/csv'
linear_predictor.serializer = csv_serializer
linear_predictor.deserializer = json_deserializer
X_new2 = np.array([[0,1],[2,3]])
result = linear_predictor.predict(X_new2)
#出力:{'predictions': [{'score': 1.0461604595184326},{'score': -1.2051000595092773}]}とりあえず2データ分予測APIを実行してみました。
乱数発生させたときの形から、一つ目のスコアは1前後で二つ目のスコアは-1前後になる予定でしたので、ひとまずOKです。
・モデル評価
def fitting(X,y):
u = np.mean(y)
regvar = 0
for i in range(X.shape[0]):
regvar += (linear_predictor.predict(X)['predictions'][i]['score'] - u)**2
totvar = sum((y-u)**2)
determ = regvar/totvar
return determ
fitting(X_train,y_train), fitting(X_test,y_test)
#出力:(0.8128463118821895, 0.7119436635304706)それぞれ、トレーニング用のデータに対する回帰の決定係数と、テスト用に確保しておいたデータに対する回帰の決定係数です
それぞれ、トレーニング用のデータに対する回帰の決定係数と、テスト用に確保しておいたデータに対する回帰の決定係数です
・エンドポイントの削除
sagemaker.Session().delete_endpoint(linear_predictor.endpoint)同じデータに対して、scikit-learnでやってみるとこんな感じです。
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X_train,y_train)
lin_reg.intercept_, lin_reg.coef_
#出力:(4.1654177, array([ 1.7707555, -2.8340867], dtype=float32))
lin_reg.predict(X_new2)
#出力:array([ 1.33133101, -0.79533124])/assets/images/2686729/original/8eb834ec-052c-45cc-9c45-0f6436562322?1523253116)
/assets/images/1665806/original/e808559b-a750-42e4-b5be-3a629ab84bf2.jpeg?1496907715)

