/assets/images/11093741/original/fe173ed1-fa6a-4440-9317-41359d6a5bd3?1667814355)
株式会社 LINKI’N FELLOWS's job postings
#2【社内ワーキンググループ】GoogleAppScript検証:webスクレイピング


on 2023-11-30
こんにちは、入社二年目の米本です。
11月にしては温かい日が続いていましたが、最近は一転すっかり冬の雰囲気に・・・
皆様いかがお過ごしでしょうか?
前回開始したGoogleAppScript検証について、今回は実際にwebスクレイピングを行ってみたいと思います。
◯利用に際しての注意事項
と、その前に注意事項になります。
Googleはポリシーにて、「Google 検索結果ページやその他の Google のプロパティをスクレイピングすることはできません。また、スクレイピングされた Google のデータをサードパーティから間接的に入手することも、禁止されています。」
と明記しており、使い方によっては規約に違反する可能性があります。
利用に際しては十分にご注意ください。
今回は弊社HPを使って動作検証してみることにします。
◯ライブラリインストール
では実際の作業を開始します。
まずはライブラリをインストールします。
ライブラリとはよく使うプログラムをひとまとめにしたファイルのことですね。
GASには多数のライブラリが用意されています。
今回はParserライブラリをインストールします。
このParserライブラリはスクレイピング処理に特化したライブラリでHTML形式の記述に対して平易な命令ができるようにパッケージ化されているため、取得したWebページのデータを簡単に処理することが可能になる、とのこと。
①ライブラリの+を押下
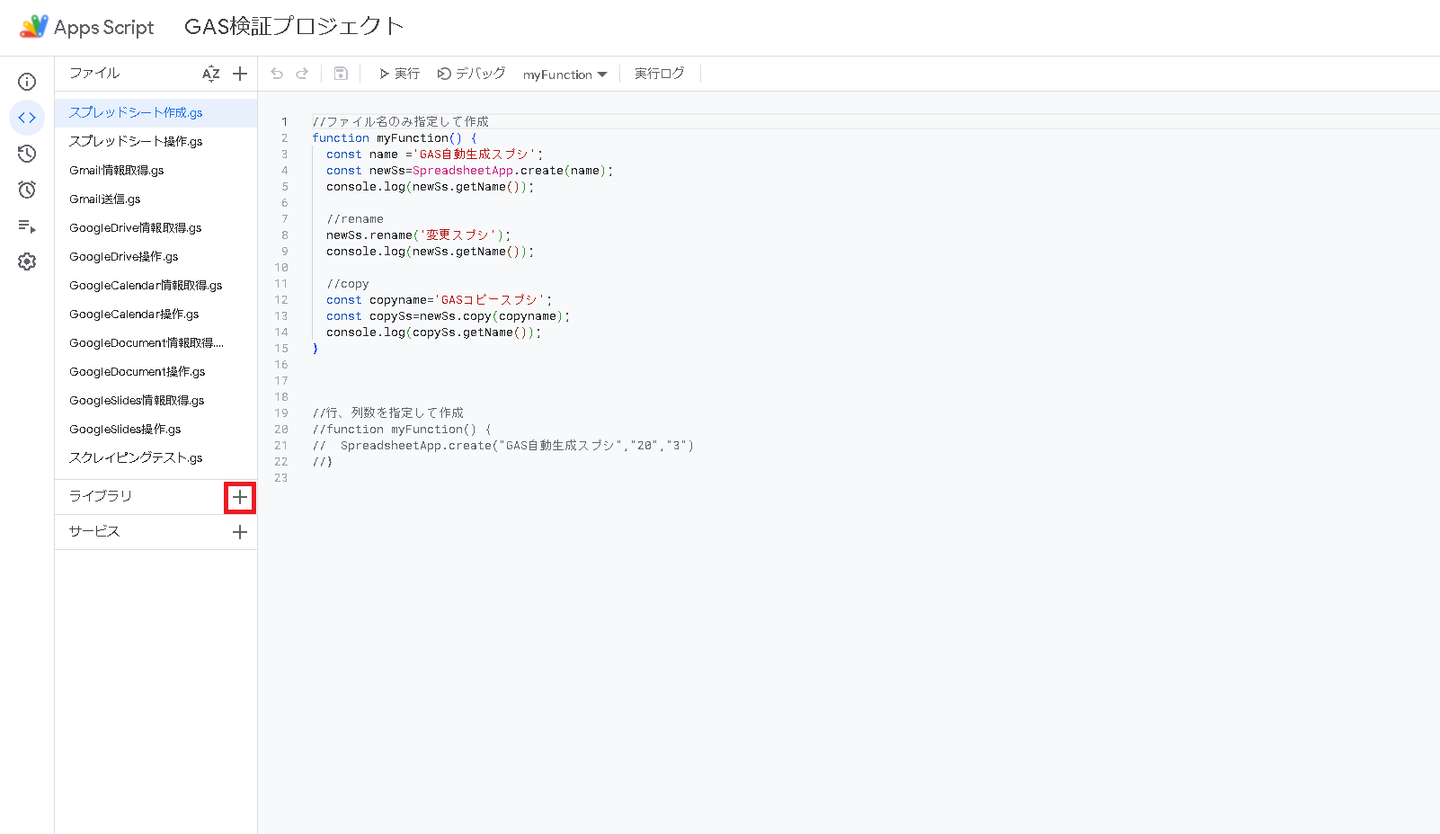
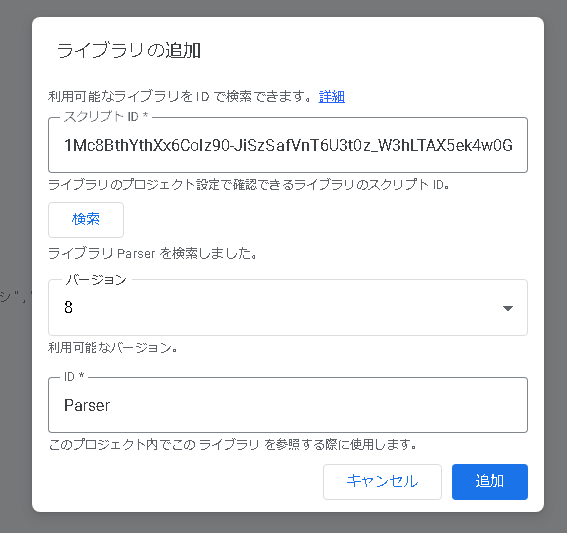
②スクリプトIDに以下を入力し追加
1Mc8BthYthXx6CoIz90-JiSzSafVnT6U3t0z_W3hLTAX5ek4w0G_EIrNw
③ライブラリにParserが追加される
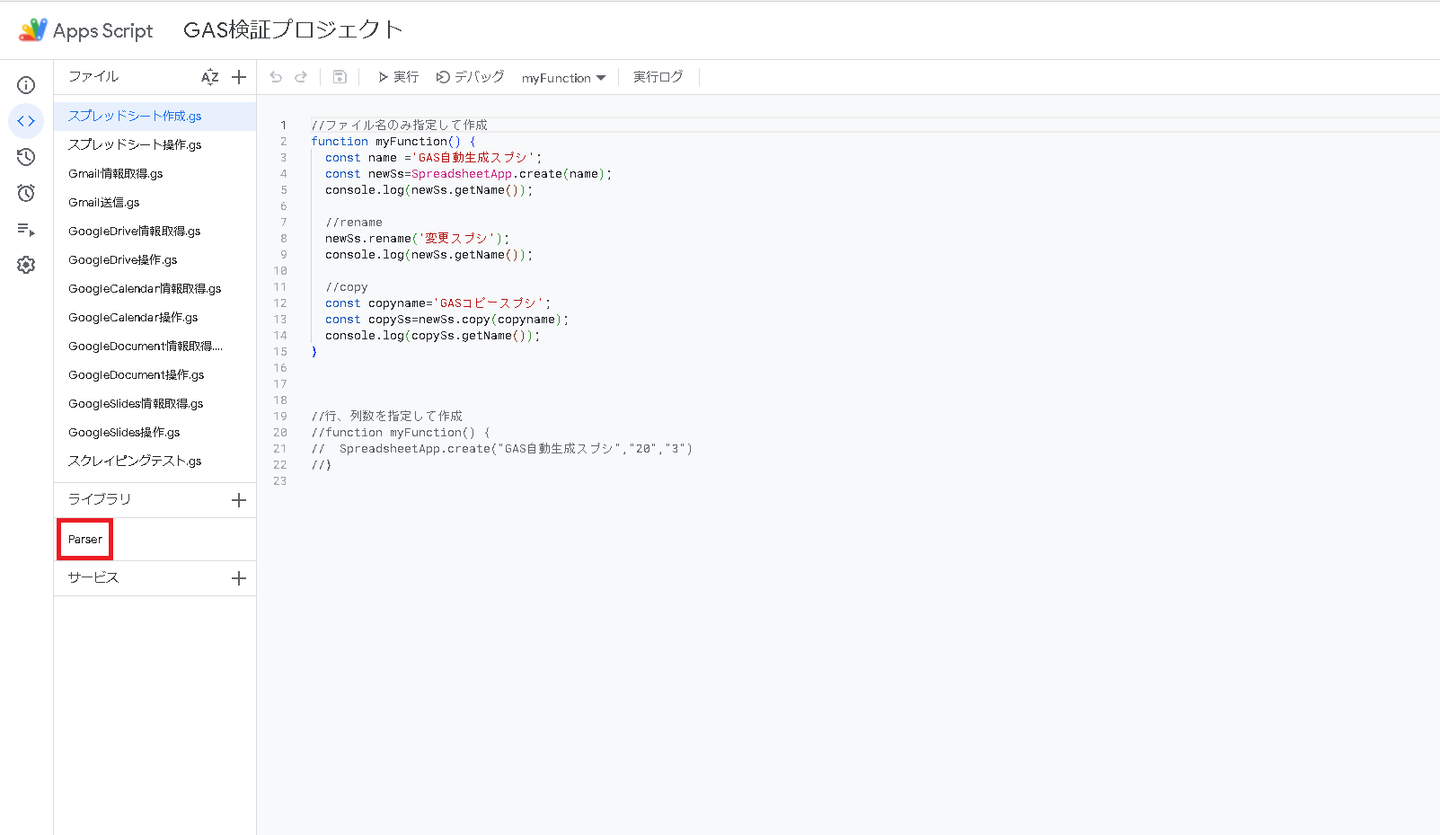
簡単ですね。
◯コード作成
ライブラリインストールが完了したら、以下のコードを入力、実行します。
function data_scraping() {
let response = UrlFetchApp.fetch("https://www.linkin.co.jp/");
let content = response.getContentText("Shift_JIS");
var text = Parser.data(content).from('<div align="left" class="lineheight20">').to('</div>').iterate();
for(var i = 0 ; i < text.length ; i++){
text[i] = text[i].replace(/\<[^\>]+\>|\n| */g,"");
}
console.log(text);
}今回は弊社HPのTOPICSに記載の文字列を抽出します。

上記コードを実行すると・・・

抽出することが出来ました。
抽出が出来たらあとは煮るなり焼くなり。
スプレッドシートへの出力や更に追加での加工等、必要に応じて取り扱うことが可能になります。
と、今回はここまで。
次回は外部ツールとの連携を予定しています!ご期待ください!
#3→12月更新予定
/assets/images/11093741/original/fe173ed1-fa6a-4440-9317-41359d6a5bd3?1667814355)

Invitation from 株式会社 LINKI’N FELLOWS
If this story triggered your interest, have a chat with the team?
#2【社内ワーキンググループ】GoogleAppScript検証:webスクレイピング

/assets/images/11093741/original/fe173ed1-fa6a-4440-9317-41359d6a5bd3?1667814355)
/assets/images/15588036/original/fe173ed1-fa6a-4440-9317-41359d6a5bd3?1698663012)
