
【記事移行のおしらせ】
こちらの記事はバンダイナムコネクサスのTechBlogへ移行しました。
下記Linkよりご覧ください。
https://zenn.dev/bnx_techblog/articles/945f4c7ba61d6b
こんにちは。バンダイナムコネクサス 上田です。 前回に引き続き、広告出稿のKPI最大化のためのデータ基盤開発について紹介します。
※ この記事は、記事執筆者の代理として藤井によってアップロードされています。内容に関する質問やコメントは藤井経由にてご連絡ください。
第1章のプロジェクト発足ではプロジェクト発足に至った背景やプロジェクト運営上の工夫についてご紹介しました。
第2章の今回は出稿している広告のデータを毎日収集し、利用しやすく整えるために行なったデータパイプライン開発を紹介していきます。
対象読者はデータ基盤新規開発プロジェクト立ち上げに将来携わるエンジニア、PM、ビジネスサイドのメンバー全員を想定し、これから広告関連のデータを触る予定のエンジニアやPMはもちろん、広告関連のデータに関わりのない方、非エンジニアの方にとっても有益な情報となることを願います。
記事に書いてあること
前回の記事
弊社の広告運用者が各広告施作の振り返りを行うために次のような課題があることを紹介しました。
- 単調な作業をできる限り効率化したい
- 各媒体が提供している管理画面をそれぞれ見に行くのに時間がかかる
- 管理画面で見れる以上の視点での振り返りに課題がある
今回の記事
課題に対して
- 出稿している広告のデータを毎日収集し、利用しやすく整える
- 出稿している広告の実績レポートを自動で作成し、広告運用者がいつでも参照できる状態にする(データの民主化推進)
を実施したので、その詳細を次の流れで紹介していきます。
-開発したデータパイプラインの概要
-データパイプライン作成作業の流れ
-開発のポイント
データパイプライン概要
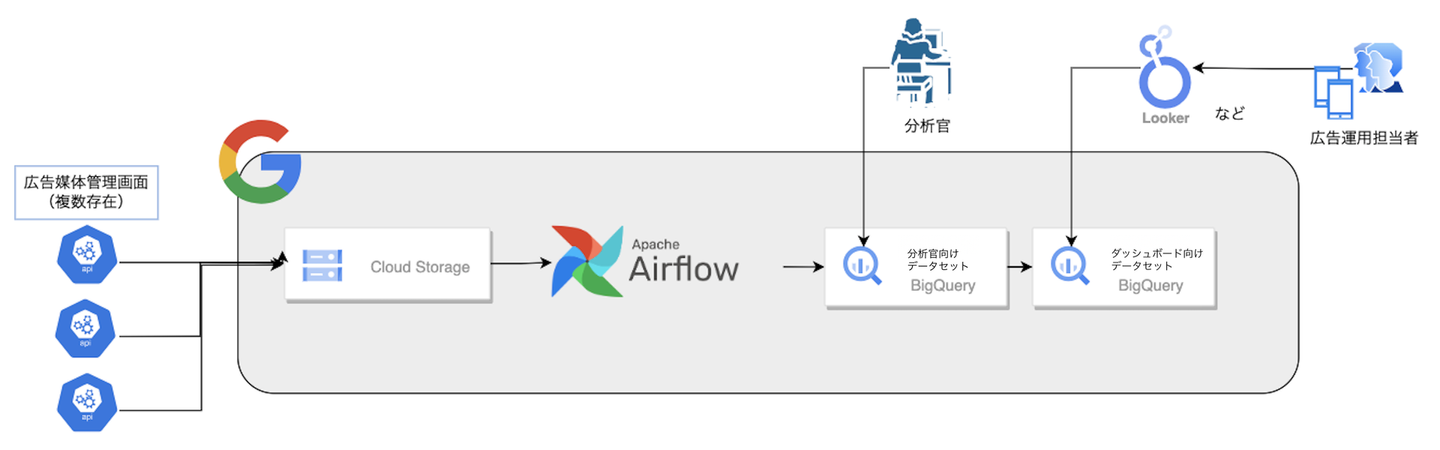
図に示したようなデータの流れで、収集したデータをそのままCloud Storageに保存し、AirflowでBigQueryに格納します。
BigQueryに格納したデータを参照するLookerダッシュボードを作成することで、非エンジニアである広告運用担当者もデータを確認することができます。
BigQueryでは利用用途ごとにデータセットを切り分けています。
- 分析官向けデータセット(仮)
-必要なデータをjsonやlistから取り出し、型変換、カラム名を各媒体統一するなどの加工をしたデータを格納 - ダッシュボード向けデータセット
-分析官向けデータセットのテーブルから必要なデータをまとめたデータを格納
データパイプライン作成作業の流れ
広告媒体×レポートの種類 それぞれに対して、以下の流れで開発を行います。
- 媒体のレポートデータの理解、収集する対象の決定
- 各広告媒体のレポートデータを収集し、Cloud Storageに保存
- レポートデータを加工しBigQueryに保存
-GCSに格納されたjsonやcsvデータから使用したいデータを取り出し加工し、BigQueryへ格納
-週末や年末年始などの連休時もデータが見れるように安定稼働できる設計をする - データマート化
-BigQueryに保存した各媒体のデータを統合、集計しデータマートを作成 - ダッシュボード化
-非技術者でも簡単に参照できるようにLookerでBigQueryのviewを参照し可視化(データの民主化推進
開発のポイント
それぞれの工程のポイントを説明します。
1 媒体のレポートデータの理解、収集する対象の決定
どんなデータが欲しいか?欲しいデータがあるか?などを確認します。
Point
- 最終的に他の媒体との結合がうまくできるようなkeyとなる項目を取得する
- jsonの場合、意外と深いところに欲しいデータがある場合があるので処理をよく検討する
- 日毎や時間ごとに集計済みのデータを取得する際にはタイムゾーンに要注意
- 管理画面のタイムゾーン設定に依存したり、希望のタイムゾーンに設定できない場合がある
- 希望のタイムゾーンに設定できない例)Twitterで日本時間で1/1のデータが欲しい場合
・12/31 15:00~1/1 15:00のデータを取るようにする
- (当然だが・・・)媒体によっては、特定の指標が取得できたり出来なかったりする
- 例えばAppleとGoogleなど複数の媒体に出稿したゲームAの実績を比較したい場合に、両方の媒体にどんな指標がどんな定義であるかの調査が必要になる
- ClickやImpressionなど基本的な指標はどの媒体にもある
2 各広告媒体のレポートデータを収集し、Cloud Storageに保存
広告媒体のレポートデータをrawデータ(加工しないデータ)でGCSに格納します。
3 レポートデータを加工しBigQueryに保存
GCSの格納されたjsonやcsvデータを分析や可視化で使いやすいように整形 弊社ではAirflow(正しくはCloud Composer。Cloud ComposerはApache Airflowで構築されています。)を使用しており、15個以上の広告媒体に関するdagが現在稼働中です。 また、BigQueryに格納した段階で一旦値のテストを行います。

airflow_taskの流れ
Point
- 広告媒体×レポートの種類 でDAGが増えていく想定だったので、Airflowコードをできる限り型化しました。
- 新規開発の際に既存のコードを流用できるので、軌道に乗ったら開発スピードが爆上がりしました
- このAirflowコードの詳細に関しては、エンジニア向けの記事を後ほど作成します。
4 データマート化: 各媒体のデータを統合、集計
このデータマートはLookerで参照しやすいように作成しました。 3でもテストしていますが、他媒体との突合がうまくいっているか確認するために再度値のテストを行います。
Point
- 現在はBigQueryのviewがデータマートの代わりとなっています
- まだJOINするテーブルが増えるため
- 安定稼働後table化予定
viewのSQLはGitで管理しています
- 変更の際は、他の開発フロート同様にレビューを行う
- もし問題が発生したとしても変更のログが参考になる
- テストで気づいたこと
- 想定外の広告運用設定があり、意図した集計が行えないことがありました
- 例: アカウントよりキャンペーンの粒度の方が小さいと考えて集計したが、1つのキャンペーンが複数のアカウントに設定されているケース
5 ダッシュボード化: 非技術者でも簡単に参照できるように
BigQueryのデータマートのデータを参照してLookerでダッシュボードを作成しました。
Point
- キャッシュの利用
- クエリ量の削減、ダッシュボード表示速度の向上のため
- 詳細
・実行クエリと同様のクエリの結果がキャッシュに存在する場合、キャッシュから結果を返す
・定期的にデータマートのレコード数を確認し、レコード数に変更がない場合は結果を保持し続ける(max保持期間:24h)
- テスト
- 3, 4でもテストしていますが、1ヶ月間データ利用者にテストを兼ねてデータを確認していただく期間を設け、データ利用者が普段作成しているレポートの値とダッシュボードの値に相違がないかを確認しました。
おわりに
今回の記事の中で登場した「Airflowコードをできる限り型化した」については、次回以降の記事で触れたいと思います。
最後まで読んでいただきありがとうございました!
もっとバンダイナムコネクサスについて詳しく知りたい方はこちら

/assets/images/21398270/original/3d6bad77-a316-4188-9b42-9cc30fa12eb8?1750395813)




/assets/images/11911367/original/QD3Kxba?1674532040)


