/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)



株式会社ZOZO's job postings
- バックエンドエンジニア
- アナリスト
- 内部統制(J-SOX)
- Other occupations (8)
- Development
- Business
- Other
こんにちは。ML・データ部データサイエンス1ブロックの尾崎です。データサイエンス1ブロックでは機械学習モデルや、データ分析によって得られたルールベースのモデルの開発をしています。特に、ZOZOTOWNやWEARの画像データを扱っています。
本記事では、教師データがないPoC特有の「モデルの評価をどうするか」という課題への対策を商品画像の色抽出の事例とともに紹介します。教師データが無いという同じ境遇に置かれた方々の一助となれば幸いです。
アパレル商品の検索において、カラーは重要な要素の1つです。ZOZOTOWNでは15色のカラー(図1)を指定して検索できますが、より細かな粒度で商品を検索したいユースケースもあります。最近ではメイクやファッションにパーソナルカラーを取り入れることが流行しています。自分のパーソナルカラーに合う色で検索したいユーザもいることでしょう。ただ、現在のZOZOTOWNの検索だと「黄緑色」の商品に細かく絞り込みたくても、検索結果に「濃い緑色」の商品などが含まれてしまいます(図2)。
図1 ZOZOTOWNのカラー検索で使える色
図2 「緑色」の条件で絞り込んだ検索結果
詳しいカラーで検索できる機能があるとUX向上にも寄与します。そのためには、これまでのカラーデータよりも詳細なカラーデータを得る必要があります。そこで、データサイエンス1ブロックでは教師データがない状況から、商品画像のカラーを抽出するモデルを開発しました。
図3が、作ったモデルによる抽出・検索結果です。カラーコードの色で検索した結果を列ごとに表示しています。教師データがない状況でここまでの精度を出すことができました。
図3 モデルによる出力結果
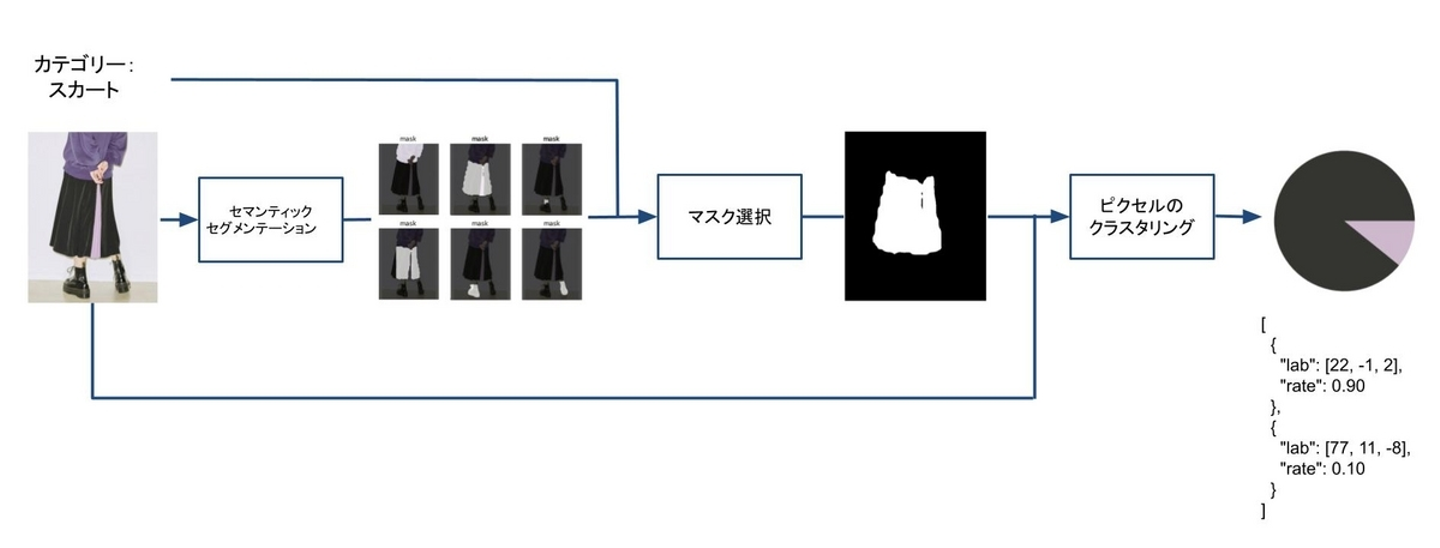
モデルの概要図は図4です。商品画像からカラーと比率を抽出するモデルです。
図4 カラー抽出モデル概要図
以下のステップでカラー抽出を実現しました。
カラーはL*a*b*(以下、簡単のためLabと表記する)色空間上の3次元のベクトルで表現しています。Lab色空間は人間の視覚に近くなるよう設計されており、人間が知覚する色差をユークリッド距離で表せます。
教師データがないので、工夫して定量評価できるようにしました。定量評価をわざわざ行えるようにした理由は実験サイクルを早く、正確に回すためです。定性評価では実験のたびに関係者へ評価をお願いするので時間がかかりますし、評価に主観が入り込んでしまいます。
次の節からその工夫を解説します。主に正解ラベル、アノテーションを外注/内製するか、評価指標の決め方を紹介します。
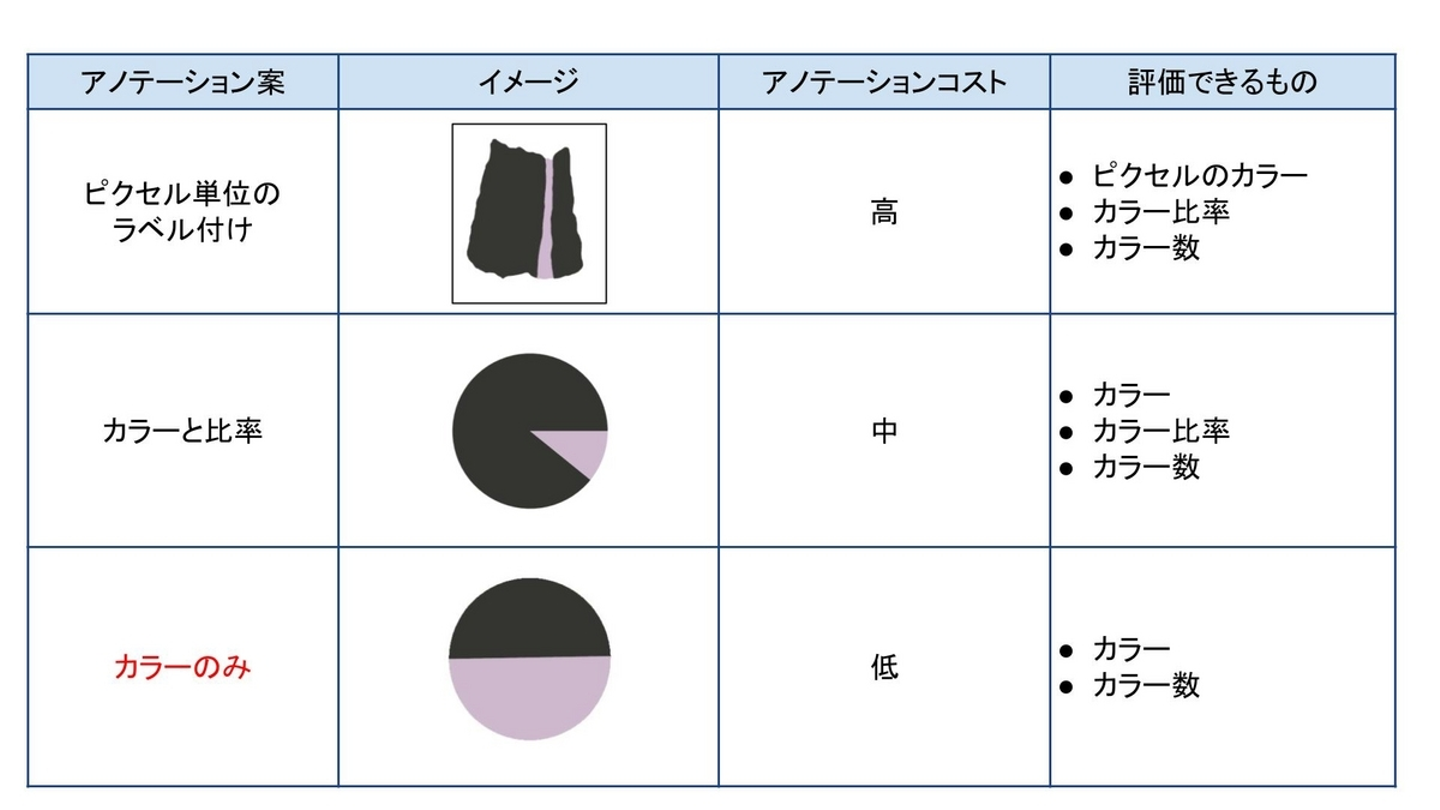
教師データがなくても、定量評価には正解ラベルが必要です。正解ラベルは、商品画像に含まれる「カラーのみ」としました。他にも以下の表1の案がありました。
「カラーのみ」を選んだ理由はアノテーションコストが最も低く、かつ検索というユースケースにおいては「カラー」と「カラー数」が評価できれば十分だったからです。
今回は内製にしました。理由は「1件あたりのアノテーション時間」を計測し、最終的にかかる時間を見積もったところ、コア業務に支障がでない時間で終わりそうだったからです。この判断により、外注費用の節約ができましたし、アノテーションがまったく終わらないという事態も回避できました。
IoU (Intersection over Union) など、セマンティック・セグメンテーションの指標ではなく、評価指標を独自に定義する必要がありました。なぜなら、正解ラベルとして「ピクセル単位のラベル」ではなく、商品に含まれる「カラーのみ」を採用したからです。
まず、評価したい観点として以下の2つを洗い出しました。
カラー数も評価する理由は今回のユースケースである検索において、どんなに色が近くても色数が異なればユーザ体験が損なわれると判断したからです。
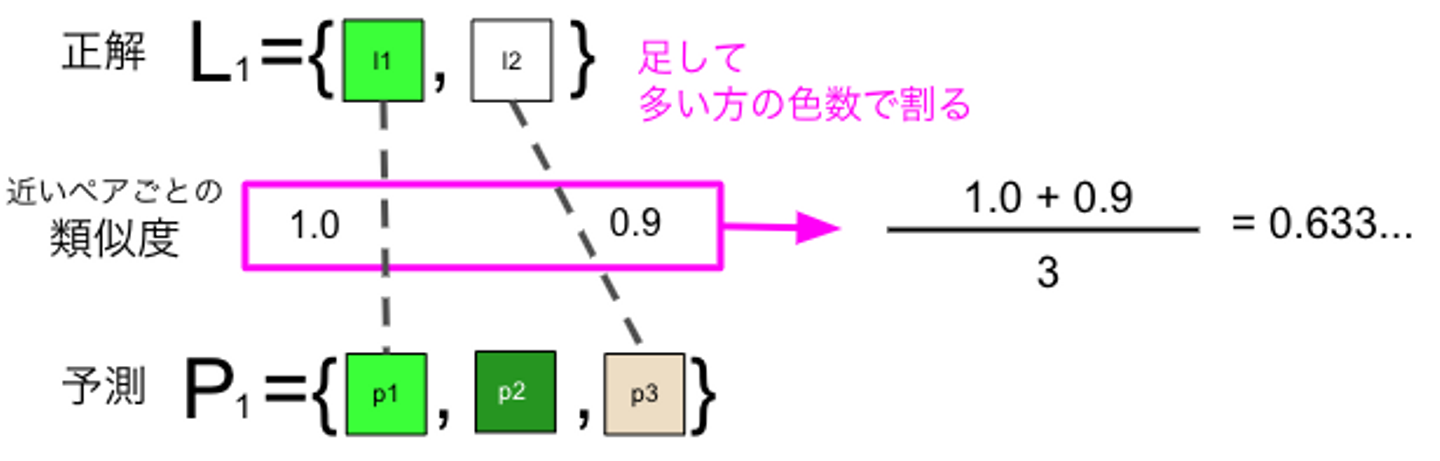
この2つの観点を測るため、以下の図5のように色の近いペアごとに類似度を計算し、その和を正解と予測のうち多い方の色数で割った値を評価指標としました。
図5 独自に定義した評価指標の概要
これを数式で表現すると以下になります。
続きはこちら
/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)


/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)

![]()
/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)