
Agenda - ElasticON Tokyo
ElasticON Tokyo.
https://www.elasticon.com/event/d10b9524-5bd9-4355-aa2e-f01b63580506/websitePage:58bcc84d-205d-4730-bd98-422c693ce20e

こんにちは。検索基盤部 検索基盤ブロックの佐藤(@satto_sann)です。
11月30日にElasticOn Tokyo 2022が行われました。今回弊社からは検索システムに関わるメンバー10名で参加して、そのうち2名が登壇しました。本記事では弊社エンジニアによる登壇の様子や気になったセッションについて紹介していきます。
ElasticOn Tokyo 2022は2022年11月30日に開催されました。コロナ禍の影響で、オフラインでの開催は3年ぶりでした。開催場所は恵比寿駅から徒歩5分ほどに位置するウェスティンホテル東京です。
会場の詳しい様子は、記事の最後に紹介します。
本カンファレンスのプログラムは、午前は全体聴講、午後は分科会形式で行われました。
プログラムの詳細は下記を参照ください。
全体聴講
午前は、Elasticsearch株式会社の代表である山賀氏の挨拶に始まり、基調講演や落合陽一氏による特別講演が目玉になっていました。Elastic社のGeneral ManagerであるMatt Riley氏の基調講演では、Elastic社のこれまでの歴史や今後の展望についてなど話がありました。
今後の展望に関しては、特にセキュリティ・オブザーバビリティ・AIという3つの分野がキーワードになっており、ただデータを蓄積するだけでなくよりパワフルにデータ活用できる環境を目指しているようでした。また、Elastic社のアジアVPであるBarrie Sheers氏によるアジア市場での展望の話では、アジアの各国にElastic社の拠点を作るほどアジアを重要視していることが紹介されていました。
ユーザ分科会
午後の部は、「ユーザー分科会」と「テクニカル分科会」の2つのブースに分かれます。参加者は気になるセッションのブースへ参加して聴講するという形式でした。
ユーザー分科会では、各ユーザー企業がElastic Stackの活用事例を発表し、参加者に知見が共有されました。
Elastic Stackの活用方法は企業によって様々でした。いずれの企業においてもElastic Stackを利用することでシステムが抱えていた大きな課題が解消されており、ソリューションのひとつとして大きな役割を担っていることが分かりました。
また、今後Elastic Stackの活用の幅をより広げていこうとしている企業も見受けられました。
テクニカル分科会
テクニカル分科会では、Elastic Stackの最新機能や実践的な利用方法が紹介されていました。ユーザー分科会と比べ、より技術的な知識の共有が際立っていました。
共通するテーマとして、膨大で複雑なデータを集約していかにそれらを活用するかが掲げられていました。また、オブザーバビリティ(可観測性)を強調するセッションも多く見受けられました。こちらのセッションについては、後ほどエンジニアがいくつか紹介するので詳細はそちらをご確認ください。
カンファレンスの後には、ネットワーキングの時間もあり、Elastic Stackを利用する様々なユーザー企業とコミュニケーションを取ることもできました。
ZOZOも午後のユーザー分科会に「ZOZOTOWNの商品検索におけるElasticsearch活用事例」というタイトルで登壇しました。
2名で登壇し、前半パートは検索基盤部 検索基盤ブロックの池田より発表しました。Elasticsearchを用いた商品検索のシステム構成や、ElasticsearchLTRプラグインを用いた「おすすめ順」の仕組みなどについて話をしました。
後半パートは、SRE部ECプラットフォーム基盤SREブロックの立花より「検索APIが利用するElasticsearchの運用をプロダクションレディにするための取り組み」について説明しました。
登壇後には、Elastic CloudのTerraform管理や運用面の課題に興味を持ってくださったユーザー企業様とネットワークを形成でき、ユーザー分科会の目的を達成できました。
登壇資料は以下にアップしておりますので、詳細はこちらをご参照ください。
ここからは参加メンバーから、聴講したテクニカル分科会やユーザ分科会の内容を一部紹介していきます。
検索基盤部 検索基盤ブロックの今井です。
このセッションでは、ベクトル検索入門の話やElasticsearchでのベクトル検索の実現方法について紹介がありました。
ある単語を検索したとき、全文検索ではインデックス内に存在する文章の中から、その単語が含まれる文書を見つけます。言い換えると、文章内に単語が含まれていないと検索できないことを意味します。
一方、ベクトル検索を利用することで文章内に検索対象の単語が含まれていなくとも、単語の意図や意味を考慮して検索出来るようになります。そのほか、入力としてテキストだけでなく音声や画像も扱うことが出来たり、ドメインの特異性(ECのドメイン知識など)を学習して活用出来たりと、今まで出来ていなかった検索をすることが出来るようになります。
ベクトル入門、類似性について
クエリと検索対象の文書をそれぞれベクトル化することで、ベクトルの距離が近いほど類似しているというように数学的な比較が出来るようになります。
また、ベクトルの次元数が多ければ多いほど、要素をより多く表現/比較することが出来るため精度は高くなります。ただ、その分計算量が増えてしまい処理時間がかかるようになってしまいます。次元数はElasticsearchでは最大2048次元まで対応しており、現実的なところでは300次元ほどではという話がありました。次元の上限に関しては、以下公式リファレンスにdimsパラメータの記載がありますので参照ください。
ベクトルを用いた検索のために、ElasticsearchではANN(近似最近傍探索)がサポートされています。ANNではHNSWという複数レイヤーを使って近似値を出すアプローチをとっています。これにより、多少の精度とは引き換えに速度優先で検索することが出来て、大規模インデックスにおいても優れた処理速度で処理することが出来るとのことでした。
Elasticsearchでのベクトル検索について
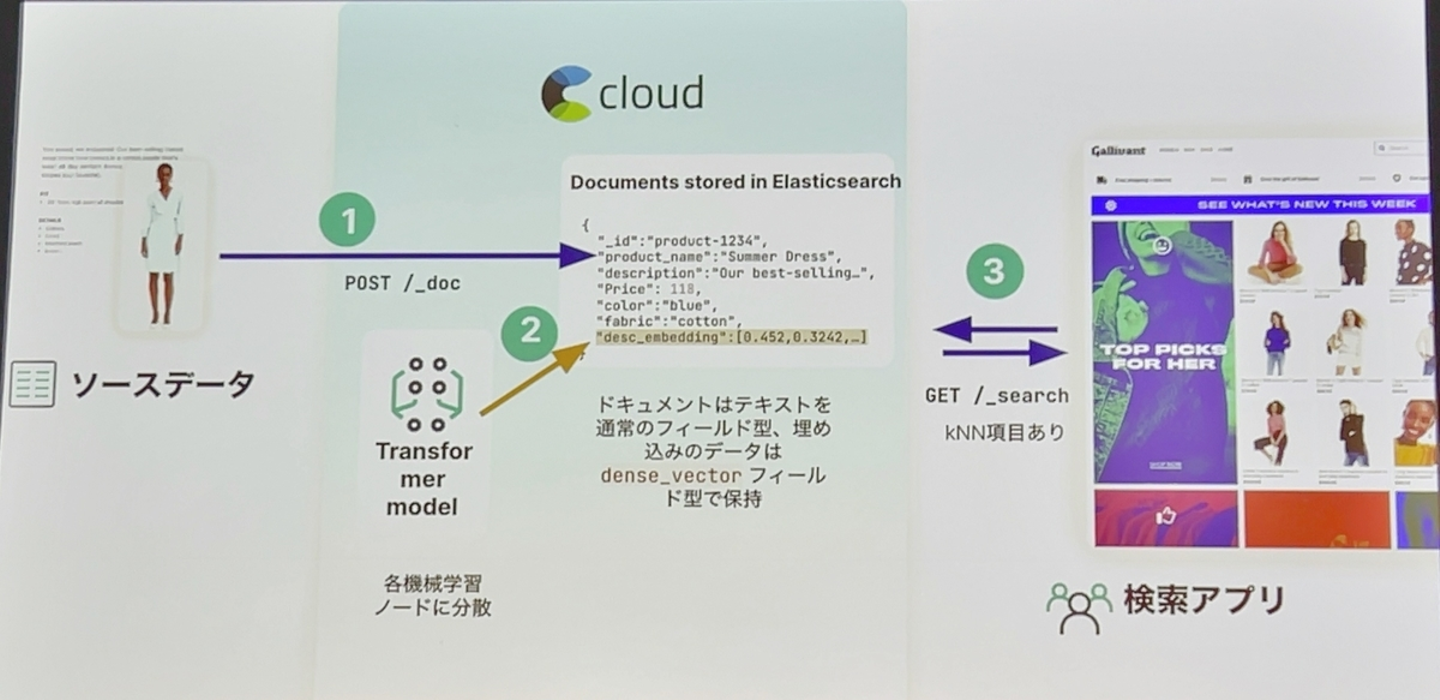
実際にどう実装するかの話ですが、セッションでは以下の手順の紹介がありました。
1.学習モデルの準備
・PyTorch(目的に沿ったモデル選び)→ クラスターへのモデルアップロード(eland_import_hub_model)→ KibanaのTrained Modelでアップロードモデル確認可能
・※モデルアップロードにはML機能を利用可能なライセンスが必要
2.データの取り込みと埋め込み(embedding)生成
・ML inference Processorを用いて埋め込み
3.ベクトルクエリ発行
・クエリの埋め込みを生成(/ml/trained_models//infer)→ 生成された埋め込みをESLのknn項目に指定して_searchエンドポイントにリクエストを発行
・knn項目で指定する内容は以下公式リファレンスを参照ください
手順の紹介の最後には、全文検索でのスコアとベクトル近似スコアを組み合わせて利用することも可能という説明もありました。
このセッションを聴講して、テキストマッチングと組み合わせて利用することでテキストと画像を一緒に検索してスコアリングするなど検索の幅が広がり、可能性を感じました。知見はまだまだ貯まっていないと思いますので、実際に導入を検討する場合はベクトルの次元や要素の選定やベクトル検索の処理速度など実用レベルで利用するためによく検証する必要はあると思いました。
SRE部 ECプラットフォーム基盤SREブロックの大澤です。
このセッションではElasticsearchが現在アーキテクチャに至る経緯と課題から、今後予定されているアーキテクチャについて紹介されました。その中でもSREチームとして気になった内容についてピックアップして紹介します。
Elasticsearchは拡張性・耐障害性のためのShard分割、効率的なデータ管理のためのデータ階層化を経て現在のアーキテクチャに至りました。しかしながら様々な課題を抱えており、それら課題を解決するための新しいアーキテクチャが「ステートレス」です。
続きはこちら
/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)


/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)

![]()



/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)

