

こんにちは。Quipper採用担当の鈴木です。今回の記事は、@chaspyによる「障害対応とポストモーテム」です!是非、ご覧ください!
こんにちは。SRE の @chaspy です。
ユーザに価値が提供できなくなってしまうシステム障害は起きてほしくはありませんが、絶対に発生しないとは言い切れません。
そんなシステム障害は、そもそも発生頻度が不定、かつ多くないので、どのように対応すべきかを体系化することは(起きる事象が毎回異なることも相まって)難しいと思います。
本記事では、Quipper において、どのように障害対応を行うのか、また、障害発生時の考え方を紹介します。
障害はどのように対処されていくのか
障害発生フロー
Quipper では 標準化された障害時連絡のフロー / 障害レベルがあります。
これによって、障害の内容、影響範囲によっては親会社のリクルートマーケティングパートナーズへのエスカレーションが必要であることと、その基準が言語化されました。また、エスカレーション時に送るメールのテンプレートも用意されており、「誰が」「何を」「いつ」送るかが明確化されたことにより、責任者、あるいは担当者は迷うことなく報告ができるようになっています。
ただし、ここでの障害発生フローは報告にフォーカスしたものであり、現場で行われる障害対応は実際には以下のフェーズにわけられると思います。
- 検知と影響範囲の特定
- 暫定対応
- 原因究明
- 再発防止
検知と影響範囲の特定
障害はどのように検知されるでしょうか。
Quipper では基本的には Web Developer が Sentry からの通知を受け取るか、SRE が DataDog の Alert を受け取るか、もしくはその両方によって検知されます。
検知のあと、最初の報告を行いますが、障害の初動報告で最も重要なのは「影響範囲の早期特定」です。
Application Error であれば該当サービスの開発者が特定のチャンネルで Sentry によって通知を受け取ります。これらは Production Readiness Check にも記載されており、基本的に全サービスにおいて受け取れているはずです。
一方、SRE の観点では、最前段にいる Reverse Proxy (Nginx) で受けるリクエストから、サブドメインごとに 50x Error rate / count に関する Alert を受け取ります。これによって影響範囲が特定できます。
通知を受け取ったあとは、ドメインごとに用意されている DataDog Dashboard を見て原因を特定します。(こちらも同じく Production Readiness Check に記載されています)
ざっくりとした50x count は DataDog で確認できますが、より詳細に絞り込むためには BigQuery に送られている Nginx のログを活用します。これによって影響範囲と影響ユーザ数の概算をここで出すことができます。原因の具体的な特定方法についてはここでは省略しますが、この時点で「どのサービスを使っているユーザがどれぐらい、どの機能が使えない」といった初動報告の文章を作成することができます。
暫定対応
起きてる障害が一時的なものではなく、継続して発生している場合、その被害を収束させることが最優先です。
Application が原因の場合で、かつコードの変更が原因であれば、迷わず Revert をすべきでしょう。
これは Infrastructure / Configuration の変更も同様です。Quipper では Infrastructure / Configuration がほぼすべてコード化されているので、Release したものを Revert することになります。
コード化されていないものが原因である場合、あるいは Revert が時間がかかってしまう場合は、実際に稼働しているものを直接 Manual Operation によって変更することもあるかもしれません。
もっとも恐ろしいことはこの Manual Operation によって被害がさらに拡大してしまったり、データが消失してしまったりすることです。
Manual Operation を行うときは Slack などでチームメンバーに連絡し、Double Check をしてから実施しましょう。ログインしている Server の Hostname なども実際に確認しながらやるのが望ましいです。
また、暫定対応の判断に時間がかかる場合は、「サービスを一時停止する」という判断も必要になるでしょう。Quipper ではサブドメイン単位で Maintenance Mode に切り替える Script が用意されており、緊急時はこれを使用して、一時的にサービスを停止させることもあります。
原因究明
暫定対応したあとは落ち着いて原因究明をしていきます。
こちらも内容はケースによって左右されるので割愛しますが、原因がわかったらそれを修正する HOT FIX をなるべくはやく出しましょう。
再発防止
再発防止策として、何をやるべきかを TODO として記載し、担当者をアサインしましょう。 これらがきちんと終了しなければ意味がありません。Priority をあげて行いましょう。SRE Team では (詳細は後述しますが)ポストモーテムによって障害の概要と再発防止のための TODO が管理されており、GitHub Issue によって作成されます。これらの TODO がちゃんと終わってクローズされているかどうかを、 Label をつけることで定期的にトラッキングしています。
障害対応への心構え
これまで、障害が発生したときの流れを説明しました。これらを実際にやるには知識だけではなく、経験が必要です。
(残念ながら)いくつか障害対応を経験してきた中で、大事だと思うことをいくつか紹介します。
落ち着く
これが一番大事です。
起きてしまったことは仕方がありません。上記で述べたようなやるべきことを確実にやるべきです。
障害対応はリアルタイムに影響が発生していることもあり、プレッシャーを感じてしまうひとも少なくないと思います。(もちろん私もそうでした。)しかし同時に、障害対応は複雑な状況から起きた原因を究明したり、失敗が許されない本番環境での Manual Operation が発生したりと、非常に難易度の高い仕事です。
そういった仕事を確実にこなすためにも、落ち着くことが何より大事です。(楽観視するという意味ではなく、冷静であるという意味です。)
役割分担する
最低限、以下は分けたほうが良いでしょう。
- 現場を指揮統率するひと
- 障害内容を報告するひと
- 復旧・原因究明をするひと
- ポストモーテム(後述)を書くひと
前述したように、障害発生時に(時間のプレッシャーもある中)難しい障害に対処するには集中することが何より大事です。

障害発生時に役割分担をする様子
ある日の障害対応では、上記のように役割分担を行うことで非常にスムーズに解決を行うことができました。役割を分担し、それぞれリードを行うひとを決めることで、それぞれの関心事項に関して周囲のひとが協力して解決を行うことができました。
現場を指揮統率するひとは主に判断と担当へのアサインを行います。システムを熟知していて、ステークホルダーをよく知っているひとが適当でしょう。
障害内容を報告するひとは、Developer に協力を仰ぎ影響範囲や障害内容をまとめながら、ステークホルダーにメールを送ったり Slack によって報告を行います。ビジネス・プロダクトの責任者が適当かもしれません。
復旧・原因究明をするひとはおそらく SRE や Developer となるでしょう。
ポストモーテムを書くひとは、現場を指揮統率するひとが兼ねてもいいでしょう。
こまめに状況報告する
役割分担して、スムーズに報告が行われたとしても、やはり周囲のひとはいつ根本解決するのかが気になってしまうでしょう。
暫定対応・原因究明フェーズいずれでも、私たちは Slack の Thread を用いてこまめに状況を書き込んでいます。
特に Manual Operation が発生する場合はダブルチェックの意味もかねて、Operation Trail を残すようにしています。
ひとではなく問題に向き合う
後述する ポストモーテムにおける Blameless Culture のことです。
原因究明や再発防止のプロセスでは絶対に特定個人の振る舞いに注視しないようにします。
「起きた問題」に対して、チーム全員で解決に向かって建設的に向き合いましょう。
障害から学ぶ取り組み / ポストモーテム
ここまで、障害発生時にどのように考え、動くべきかを述べてきました。次に、障害が収束したあと、その障害を2度と発生しないためのポストモーテムとその活用方法について紹介します。
ポストモーテムとは
ポストモーテムとは、障害発生の経緯をまとめ、「失敗から学ぶ」ための取り組みです。
Site Reliability Engineering の ポストモーテムテンプレートが非常によくできており、Quipper でもこれを Issue Template として採用しています。まだやっていない方は今すぐできるプラクティスとしてオススメします。
また、Quipper では、以前 1st SRE Book を読書会したこともあり、多くの Web Developer はポストモーテムを理解しています。
いつ書くのがベストか
いつでもいいのですが、私は「暫定対応」フェーズのあと、がベストだと考えています。なぜなら(よくできたテンプレートであれど)ひと段落したあとから作成するのは面倒だからです。
さらに、これは直接の原因究明を行うエンジニアより、別のひとが作成したほうが良いと感じています。暫定対応後のタイミングであれば、原因究明と同時並行で Timeline や Impact 等は書けるからです。
役割分担として最低3つあげましたが、ポストモーテムを書くひとを分けてもいいですし、個人的には指揮統率を取るひとが書いてもいいと思っています。
実際に障害対応が行われてる流れで随時 Timeline や Supported Information を更新すると非常に楽です。
原因究明が終わった後、TODO を記載して、担当者をアサインしましょう。
Close まで見送る
ポストモーテムを作成すると TODO を決め、担当をアサインします。
これが行われなければ何も意味がありません。Label を用いて定期的に確認し、TODO が行われているかを確認しましょう。長期的には必要だが今すぐやらなくてもいい類のものは、別の Issue として独立に扱った方がいいかもしれません。
失敗から学ぶ
私はポストモーテムにおいて Lesson we learn の項目が非常に大切だと感じています。この項目があることがまさに Blameless Culture を体現していると思います。障害を悪いことと捉えず、学びとして前向きに捉えて、チームを成長させることができる重要な観点です。
読書会をする
Quipper SRE Team では New Joiner が入ったタイミングで過去のポストモーテムの読書会をはじめてみました。とても有益な取り組みですのでオススメします。

ポストモーテム読書会初回を終えての所感
ポストモーテム読書会を行うことによって、以下のような有益な点があります。
- 障害の影響範囲や原因から、現行のシステムアーキテクチャを学ぶことができる
- TODO や根本原因から、技術的な仕組みを学ぶことができる
- Slack Thread を参照することによって、障害発生時の流れを疑似体験することができる
障害と判断する基準 / SLO
さて、障害発生フロー
によると障害の判断基準が記載されていると述べました。実際の現場では起きた事象に対して個別に緊急性を判断して対応を行うと思います。
しかし、それとは別に、より精密に、システマチックに判断できる基準があるとより便利でしょう。
これは、先日、非常に短時間の Service Down が起きた際に、ポストモーテムを書くか、と思った時に、ふと「どういう基準でポストモーテムを書くのだろう」と考えたのがきっかけでした。
理想的には、SLO であるべきだと思います。(SLO に関しての詳細の説明は省きます)
しかしそのためには、以下のようなことを考慮する必要があります。
- SLO を SRE と Web Developer, Business Developer と合意する必要がある
- SLO が本当に(ユーザにとって)重要な目標として適切である必要がある
- SLO を下回った(エラーバジェットを使い果たした)ときに通知を受けとる必要がある
SLO の策定と運用についてはまた別途記事を書きたいと思いますが、障害を判断する基準としては有益かもしれません。
より発展的な障害予防
最後に、障害を予防する仕組みについて簡単に紹介します。
Resiliency / なんもしてないのに治った
人間はスケールしません。
オンコールを 24/365 で行ってない限り、障害対応をいつでも行うことは不可能です。
障害の多くは Release (Application Code, Configuration, Infrastructure の変更)によって起きますが、一方でそれ以外の予期せぬ原因によっても発生します。
Infrastructure の Layer では Load Balancer とHealth Check による死活監視が、 Application Platform の Layer では Kubernetes による Self-Healing が有効です。
予期せぬ原因は大きく "Traffic の急増による Resource の枯渇" と "Hardware / Cloud の障害" に二分されると考えており、前者は AutoScaling および 事前の Scheduled Scaling、後者は、いつ単一の Instance / AZ が Down しても可用性に影響しないような設計をし、復旧時には自動的に復旧することが望ましいです。
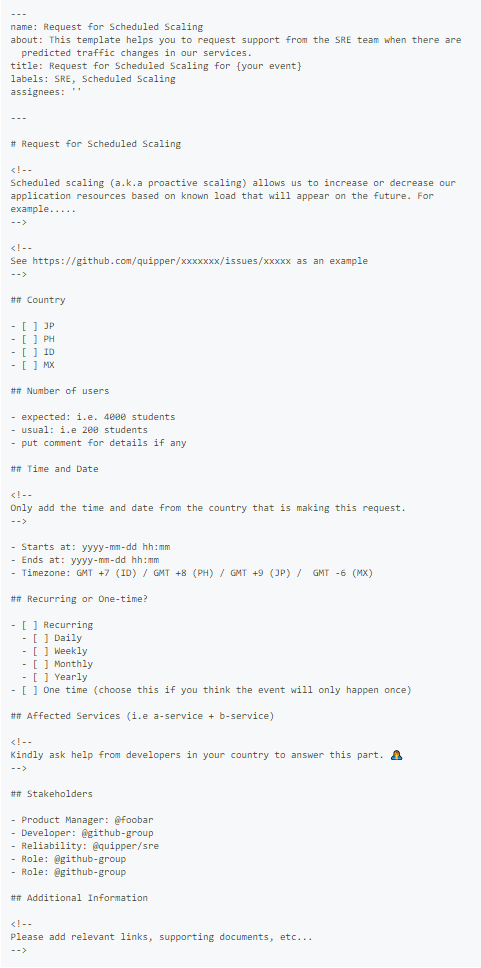
Push 通知や コマーシャル、キャンペーンによる突発的な負荷は Auto Scaling だけで対応することは難しく、Scheduled Scaling を行うことになると思います。Quipper では事前にそれらを円滑に行うための Issue Template が用意されており、Product Manager, Business Developer, Marketing Team と協力してシステムの信頼性を保っています。
以下が最近 SRE Team の rbmrclo と協力して用意した Issue Templates で、早速いろいろなチームからリクエストが届いています。各国の各 Product Team が独立して集客・成長施策を行うために、安心して SRE と連携できるとても良い仕組みだと感じています。
Feature Toggles / ヤバかったらすぐ戻す
Quipper では Dark Launch と呼ばれる独自の仕組みを@ujihisaが導入しました。(詳細はRailsDM 2019 での発表 "雑" / Almost Microservices をご覧ください。動画 / Slide )また、それとは別に@ravelll 採用の Launch Darkly という外部サービスを利用した仕組みも存在します。
これらによって、アプリケーション単位ではなく、機能のレベルでリリース(公開・非公開)をコントロールすることができています。
前者に関しては Product の責任者である Product Manager が実際にオン・オフを実施しており、実験的な機能、新機能をこっそりデプロイしておいて、任意のタイミングで実行・解除を行っています。
Canary Release / ちょっとずつ試す
Service Mesh の Layer ではなく、Kubernetes Cluster 内部の Nginx と monorepo の活用によって Canary Release を実現しています。(詳細は@mtsmfm の発表 Canary release in StudySapuri をご覧ください。)
これによって環境変数で割合を設定し、ユーザ単位で少しずつ新サービス・新バージョンへリクエストを流す仕組みを実践しています。
実際に Rails Upgrade と、MognoDB Upgrade の際に大活躍しています。
Circuit Breaker / 山火事を防ぐ
こちらは現在 Quipper では実現できていませんが、ある特定の Service が継続的にエラーを返し続けた場合、その Service へのリクエストを行わず、ただちにエラーを返すというものです。
おわりに
Quipper では障害発生を未然に防ぎ、ユーザに価値を届け続けたい仲間を募集しています。
現状これは前述した Feature Toggles によって Application Layer で実装されています。(もし特定の Service がエラーになった場合、該当機能を隠したり、ロジックを伴わないデフォルトの結果を返す、など)しかし、より広い範囲で行うには Service Mesh によって解決されるべき課題です。

/assets/images/8020079/original/f5632a6b-81e7-484b-87e8-9a2dd6aeeee7?1635733533)


/assets/images/8499187/original/1944cc29-7cbf-49e3-a0e7-345d3a36e4b1?1642059254)


