【Quipperブログ】Kubernetes 上のアプリケーションから Stackdriver Logging に構造化ログを送る


こんにちは!Quipper採用担当の鈴木です。今回の記事は、プロダクトマネージャーの@yuya-takeyama による「Kubernetes 上のアプリケーションから Stackdriver Logging に構造化ログを送る」です!
是非、ご覧ください!
SRE チームの @yuya-takeyama です。
Quipper の SRE チームでは AWS や Kubernetes を用いたインフラの構築、CI/CD パイプラインの構築・改善等様々な Developer Experience の向上、社内のあらゆるサービスのマイクロサービス化のサポート、そしてそれに伴う複雑化にも耐え得るよう、サービスの安定稼働を支えるためのルール・ツール群を整備しています。
今日はその中でも、簡単かつより精緻に Logs-Based Monitoring が行えるよう、GCP の Stackdrider Logging に構造化ログを送る方法について紹介します。
構造化ログとは
ここではとりあえず「Machine-Readable なログ」として定義します。通常のログはテキストベースの Human-Readable なもので、UNIX 哲学においては行指向のテキストファイルは grep
等の単純なツールとの組み合わせの容易性から善しとされていると思います。
ですが、行指向のテキストデータでは複雑な構造のデータを扱うのは難しいでしょう。正規表現等で parse するのはログの形式によっては困難です。
というわけで今回はその両方の良いところをとって行指向の JSON を使用します。私は以前からログを改行区切りの JSON で記録する手法を好んでいます。
Stackdriver Logging とは
Stackdriver は GCP のサービスで、Monitoring や Logging といった Observability を確保するための機能群を持っています。
Stackdriver は今でこそ Google に買収されていますが、AWS にも対応しており、AWS でのセットアップ手順についても公式のドキュメントが用意されています。
また、Kubernetes から Stackdriver Logging にログを送信する手順については Kubernetes の公式ドキュメントに記載されています。
今回はこれら手順を完了し、とりあえずログは Stackdrider Logging に送れている状態を前提としています。
JSON での Logs-Based Monitoring の何が嬉しいか
まず JSON に限らず Logs-Based Monitoring に関してですが、アドホックな分析にとても便利です。
後に紹介しますが、事前に想定していなかった事態に際して、ログをもとにとりあえずのメトリクスを作成・可視化することで Fact-Based な意思決定を低コストに行うことができます。
また、さらにそれを JSON で行うのは、複雑な構造のデータを取り扱う、というのももちろんそうですし、アプリケーションがログ収集基盤の知識を持たなくて済む というのも大きいと考えます。
例えば同じことは Fluent Logger を使って Fluentd にログを送りつけることもできますが、その場合アプリケーションは Fluentd について知らなくてはなりません。Fluentd であればその先のデータストアのことは隠蔽してくれますが、例えばログ収集のツールを LogStash に変更しよう、といった場合もアプリケーション側への改修が必要となってしまいます。
これを、アプリケーションはただ「改行区切りの JSON を標準出力に書き込めば良い」とすれば、例えログ収集ツールやコンテナ基盤が変わったとしても高い再利用性が期待できるでしょう。
Fluentd でログ中の JSON を parse する
上記の Kubernetes のドキュメントでは Fluentd を使って、Kubernetes 内の Docker が出力したログを吸い出しています。
この時のログはこのような改行区切りの JSON データです。
{"log":"[info:2016-02-16T16:04:05.930-08:00] Some log text here\n","stream":"stdout","time":"2016-02-17T00:04:05.931087621Z"}この中の log
部分がアプリケーションが標準出力または標準エラー出力に出力したデータです。常に 1 行ずつ出力されます。これを Kubernetes ドキュメント中の Fluentd のデフォルトの設定では以下のようにして取り出しています。
<source>
type tail
format json
time_key time
path /var/log/containers/*.log
pos_file /var/log/gcp-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%N%Z
tag reform.*
read_from_head true
</source>
<filter reform.**>
type parser
format /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<log>.*)/
reserve_data true
suppress_parse_error_log true
key_name log
</filter>ですが、今回はそのログデータにさらに JSON が含まれていることを想定します。実際にはこのようなログとなるでしょう。
{"log":"{\"foo\":\"FOO\"}\n","stream":"stdout","time":"2016-02-17T00:04:05.931087621Z"}このように、JSON 中にさらに JSON エンコードされた文字列を含みます。なので、上記の設定の後に以下のような設定を追加します。
<filter reform.**>
@type parser
format json
key_name log
reserve_data true
hash_value_field _data
</filter>これで、もし log
中の文字列が JSON としてパース可能であれば、Stackdriver Logging 中は jsonPayload
というフィールドの中にさらに _data
というフィールドを作って構造化されたログが埋め込まれます。
Rails から構造化ログを出力してみる
あとは標準出力か標準エラー出力に JSON を出力するだけです。ただし、改行はせずに 1 データあたり 1 行に収める必要があることには注意が必要です。
今回は、Web アプリケーションのバックグラウンドで動作するとある Resque worker のパフォーマンス問題を調査するために以下のようなログを追加してみました。
対象ユーザの ID や、処理したデータ量等を記録します。
log_data = {
worker: self.to_s,
data:{
user_id: user.id,
duration: duration,
organization_count: organizations.count,
student_group_count: student_groups.count,
student_count: students.count,
}
}
Rails.logger.info(log_data.to_json)worker には Resque worker のクラス名、durationには処理時間のミリ秒数を持っています。
これを元に検索するには以下のようなクエリを書けば良いことになります。例えば FooWorker の実行時間が 10 秒 (10000 ミリ秒) 以上時間がかかっているものを抽出する場合。
jsonPayload._data.worker="FooWorker"
jsonPayload._data.data.duration > 10000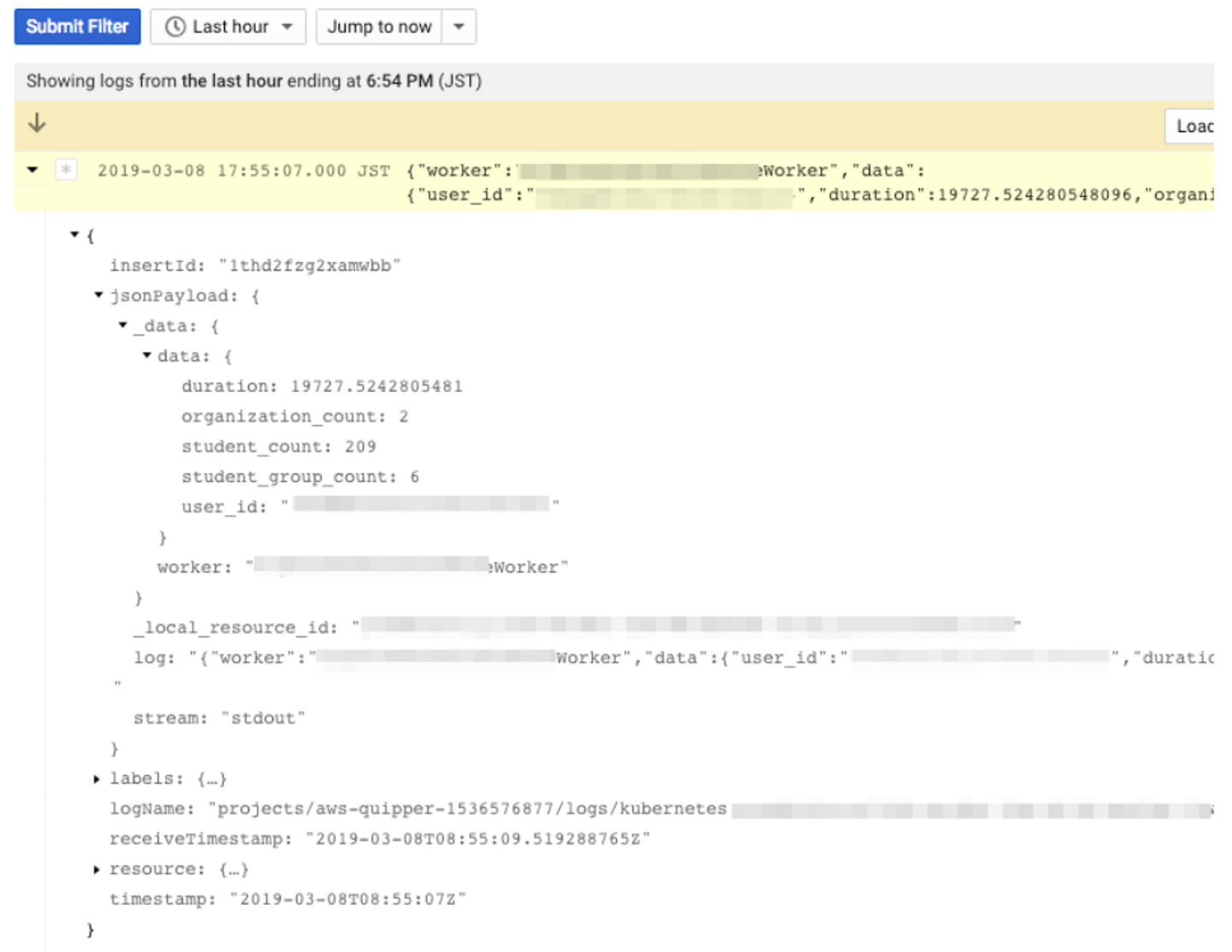
Stackdriver Logging クエリ画面
(スクショ中、一部 Quipper 独自の設定による条件が含まれる点に注意)
このように、必要なデータがピンポイントで取り出せました。
ちなみに実際にこのデータを活用してパフォーマンス上問題になりがちなユーザの傾向を特定し、パフォーマンス向上のための改善が行われようとしているところです。
さらなる活用
Stackdriver では Logs-Based metrics としてログからメトリクスを作成することもできますし、それをもとにアラートを飛ばすこともできます。
メトリクスの作成は、例えば正規表現にマッチする行数、といったものでも可能なので、必ずしも構造化ログである必要はありません。が、構造化ログであれば例えばログ中のある数値の分散を可視化したりもできるので、やはり構造化しておいた方が色々活用しやすくなるでしょう。
こちらは先日リニューアルしたとある Single Page Application について、「リニューアル前のバージョンのアプリケーションからのアクセスが来ているらしい」ということが発覚し、急遽どれぐらい来ているのかというのを可視化するために作ったグラフです。 (JSON 関係ない例)
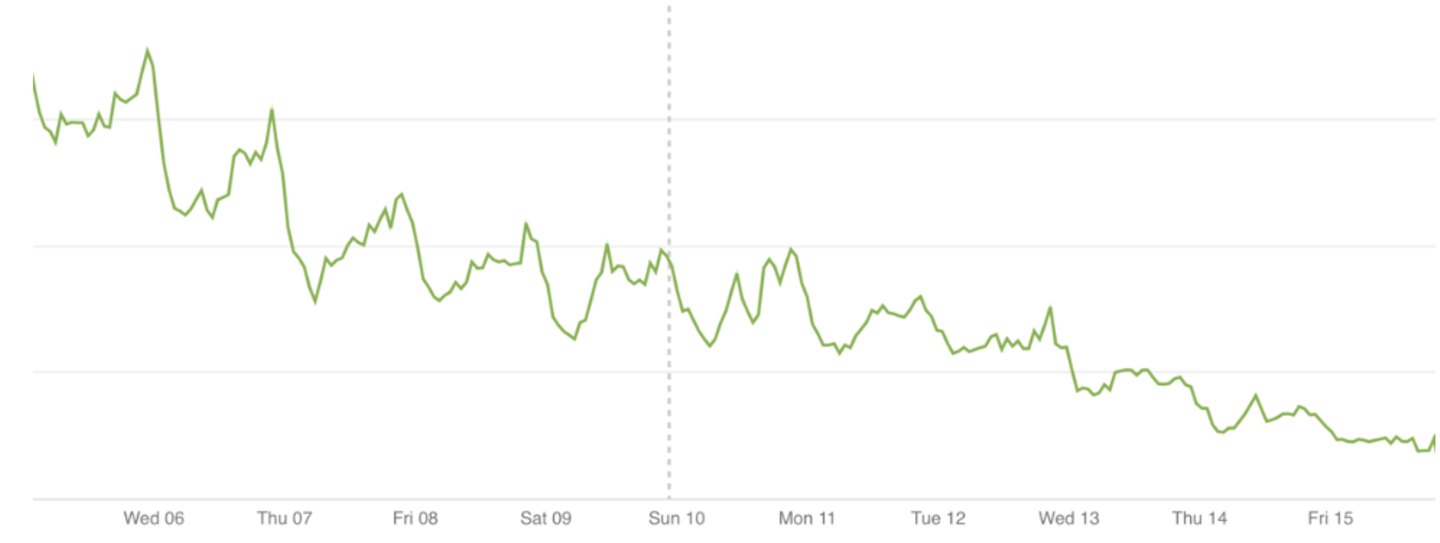
Logs-Based metrics のグラフ
そこそこアクセスは来ているものの、日を追うごとに順調に減っているのでとりあえずは静観、という判断を下すことができました。めでたしめでたし。
その他にも、例えば削除予定の実装を消す前にスタックトレース付きでログの出力し、メトリクスの作成等を行っておけば、意図せず呼ばれてしまってないか検知するための仕組みが非常に安価に用意できた入りと、様々な活用ができそうです。
というわけで Logs-Based Monitoring はとても便利なので、是非活用してみましょう。

/assets/images/8020079/original/f5632a6b-81e7-484b-87e8-9a2dd6aeeee7?1635733533)




/assets/images/8499187/original/1944cc29-7cbf-49e3-a0e7-345d3a36e4b1?1642059254)


