私たちパクテラ・コンサルティング・ジャパン(以下:パクテラ)は世界基準のナレッジを有し、デジタル領域に強みを持つグローバルカンパニーです。
大規模のプロジェクトを進めていく上で、従業員のボトムアップが常に求められている現状から、社内研修制度の一環としてITのスペシャリストによるセッション「PETS」を開催しております。
本投稿ではその第3回目の内容をレポートさせていただきます。是非、ご一読ください。
PETSとは? PETSとはPactera Engineer Training Session のそれぞれの頭文字を取ったITのエキスパートを養成するためのパクテラ・ジャパン独自の社内研修です。毎回、外部講師を招待し、日本のDX化を促進させる上での専門性や思考力をセッションを通じて身に付けてまいります。 講師 川島 義隆
株式会社ウルフチーフ 代表取締役 大手SIerで20年間、多数のWebアプリケーション開発プロジェクトのアーキテクチャ設計を担当、また社員教育、技術者採用、研修講師などを努め、2018年10月アーキテクチャ設計専業の株式会社ウルフチーフを創業する。その他、技術コミュニティを中心に登壇多数。 テーマ:データモデリング データマネジメントやデータガバナンスを全体最適の形で行うために必須なデータモデリングですが、 その重要性を100%理解している方は少ないように思われます。今回は、データモデリングの必要性を理解し、効率的なシステム保守を実現するためのポイントやノウハウを講師の川島さんからレクチャーしていただきます。
なぜデータモデリングが重要なのか? データを構造的に整理し、効率的に扱えるようにするデータモデリングには主に2つの意義があります。
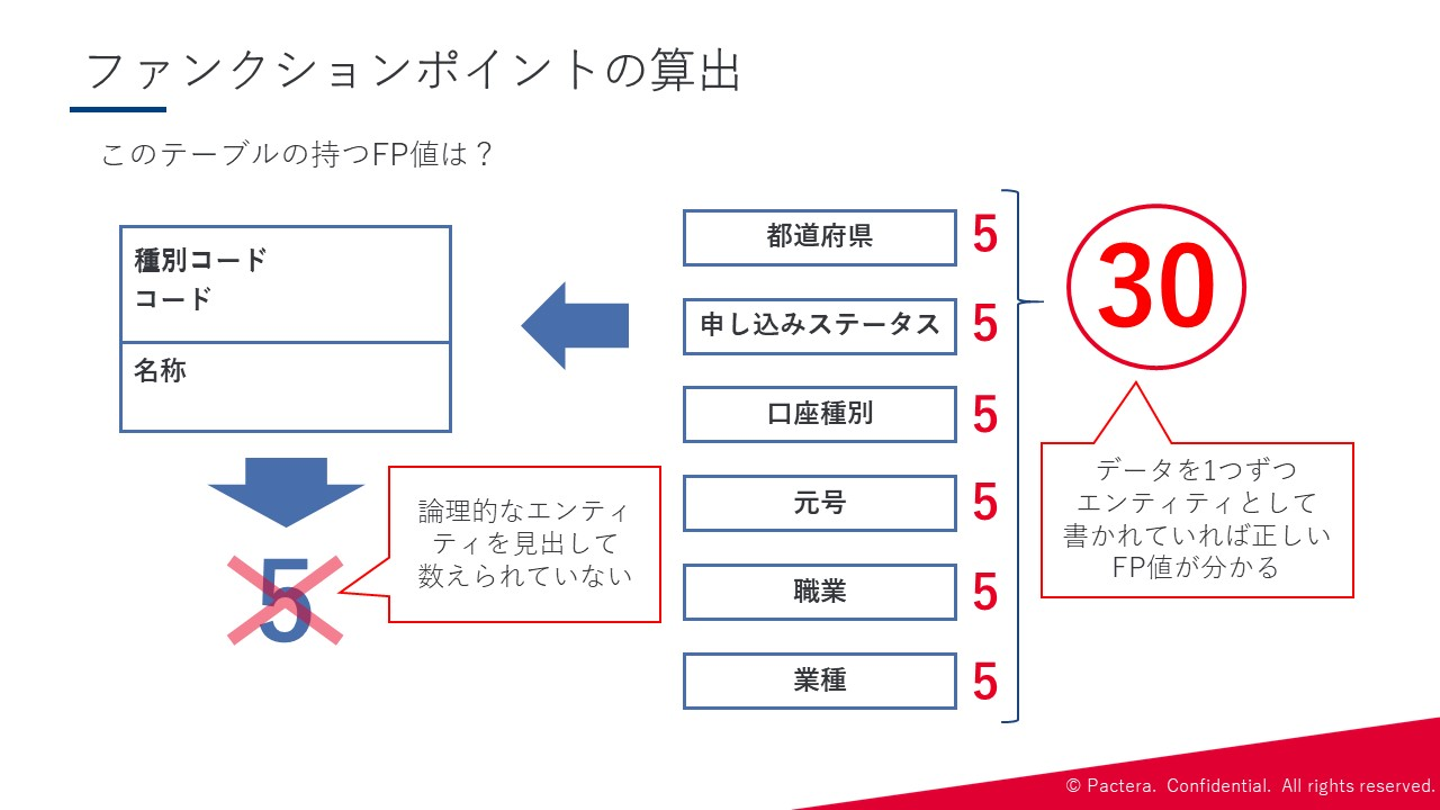
①システム規模を正しく見通すため ②余裕のある開発をするため ①の開発を正しく見通すことにおいては、ソフトウェアの機能を基本にファンクションポイント(以下:FP)を付けていき、ポイントを合計して規模を導き出します。ここで、注意するのは テーブルの数を基にシステムの規模を算出しない ことです。
上記のように、ER図に種別コードと名称だけ書かれているテーブルだけを見て、FPを算出してしまうと論理的なエンティティを数えることができないため、正しく規模を見通すことができません。しかし、データ項目を1つずつエンティティとして洗い出しておけば、正しいFP値を求めることができます。FP値を人月換算すると1人月当たり10~15FPと言われているので、先の例では データモデリングを怠ると2~3人月を損する ことになるのです。
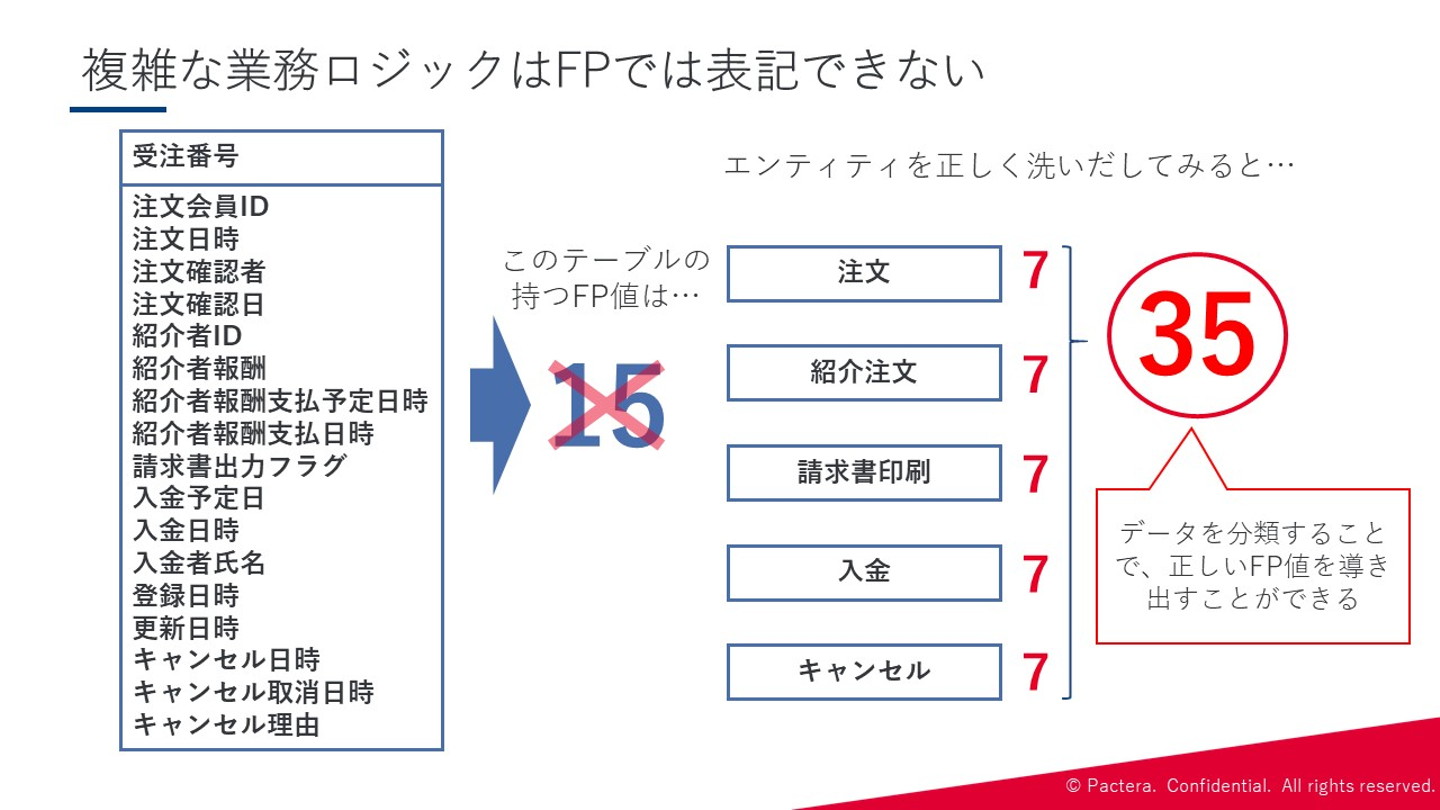
また、②の余裕のある開発をするにあたっては、FPでは複雑なロジックが表現できないことを理解する必要があります。複雑な業務ロジックが生まれる原因として、1つのテーブルを複数の業務で更新することにより、更新時のルールが生まれてしまうことが挙げられます。
以上のように複雑な業務ロジックはテーブルを基にFPは算出できないため、 各データをエンティティとして洗い出してみると、正しいFP値を求める ことができます。ちなみに月人時換算をしてみると、このケースで データモデリングを怠ると1~2人月分を損してしまう ことになります。
このように正しいデータモデル設計は、データを分類し、エンティティとして洗い出すことで、システム規模を正確に見通し、開発業務に余裕を与えるのです。
データモデリングにおける5つのステップ データモデリングの重要性を理解したところで、モデリングの5つのステップを通じてマスターしましょう。以下が5つのステップになります。
Step1:エンティティの抽出 Step2:エンティティの分類 Step3:イベントエンティティの処理 Step4:リソースに隠されたイベント抽出 Step5:非依存リレーションシップから交差エンティティへの転換 それでは早速、Step1から進めていきましょう。
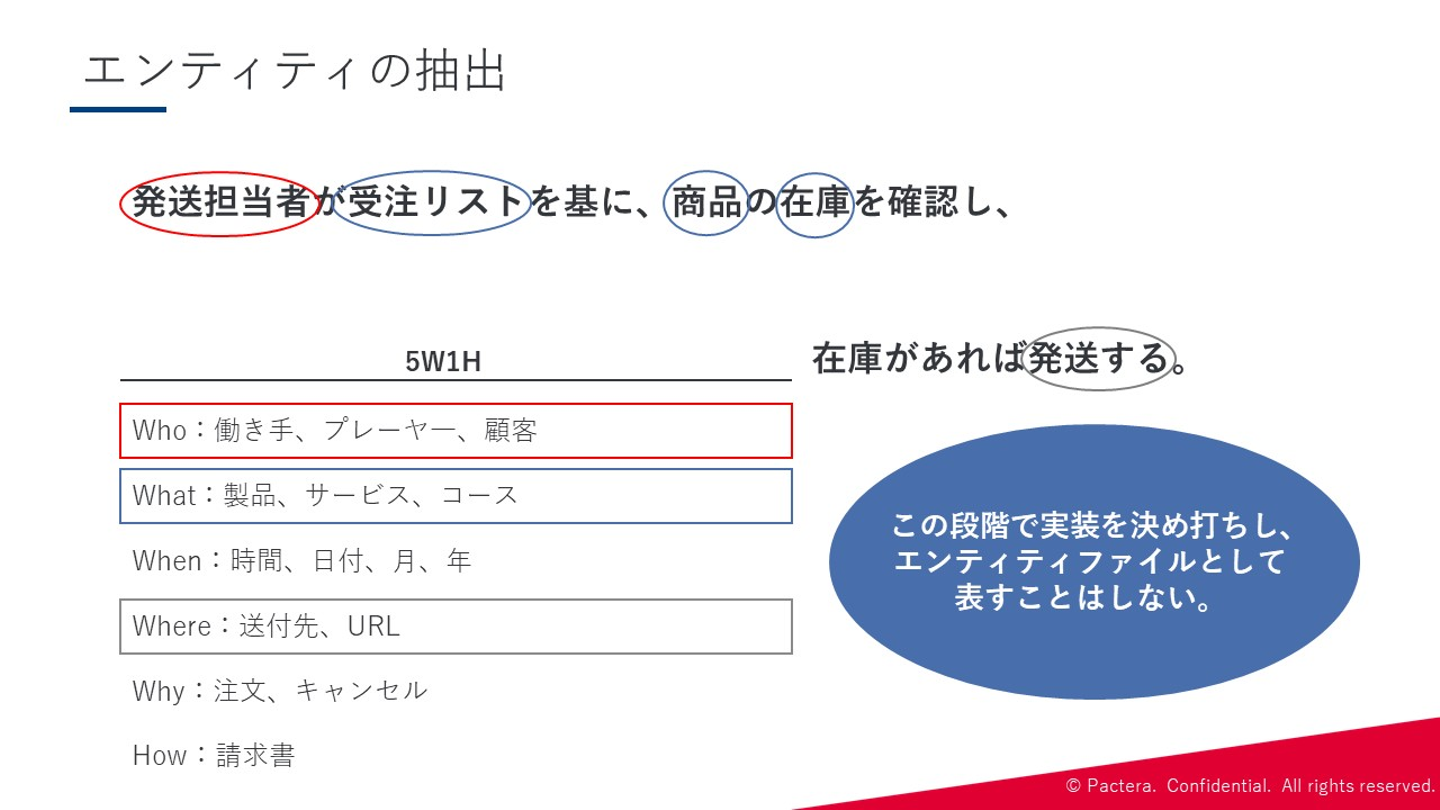
Step1: エンティティの抽出 始めにエンティティを抽出します。その際には、以下のルールを基に実行します。
①:要求仕様の「動詞」を抜き出しエンティティとする。 ②:①に関わる「名詞」を抜き出しエンティティとする。 ③:エンティティ間の関連に線を引く。 ④:属性や候補キーも分かる範囲で明確にする。
また、エンティティを抽出する際には、5W1Hをベースにそれぞれの概要に沿って行うともれなく抽出することができます。
また、エンティティへ名を付ける時は、エンティティ名が短くその意味を的確に表現するものでなくてはなりません。なくても意味が通じてしまうワード(情報、データ、処理、~物、マスタなど)は使わないようにしましょう。
Step2: エンティティの分類 エンティティを抽出した後は、分類の作業です。洗い出したエンティティを リソースとイベントに分類 します。分類の基準は属性に 日時 を持つかどうかです。 動詞から抜き出したエンティティはイベント に、 名詞から抜き出したエンティティはリソース になります。
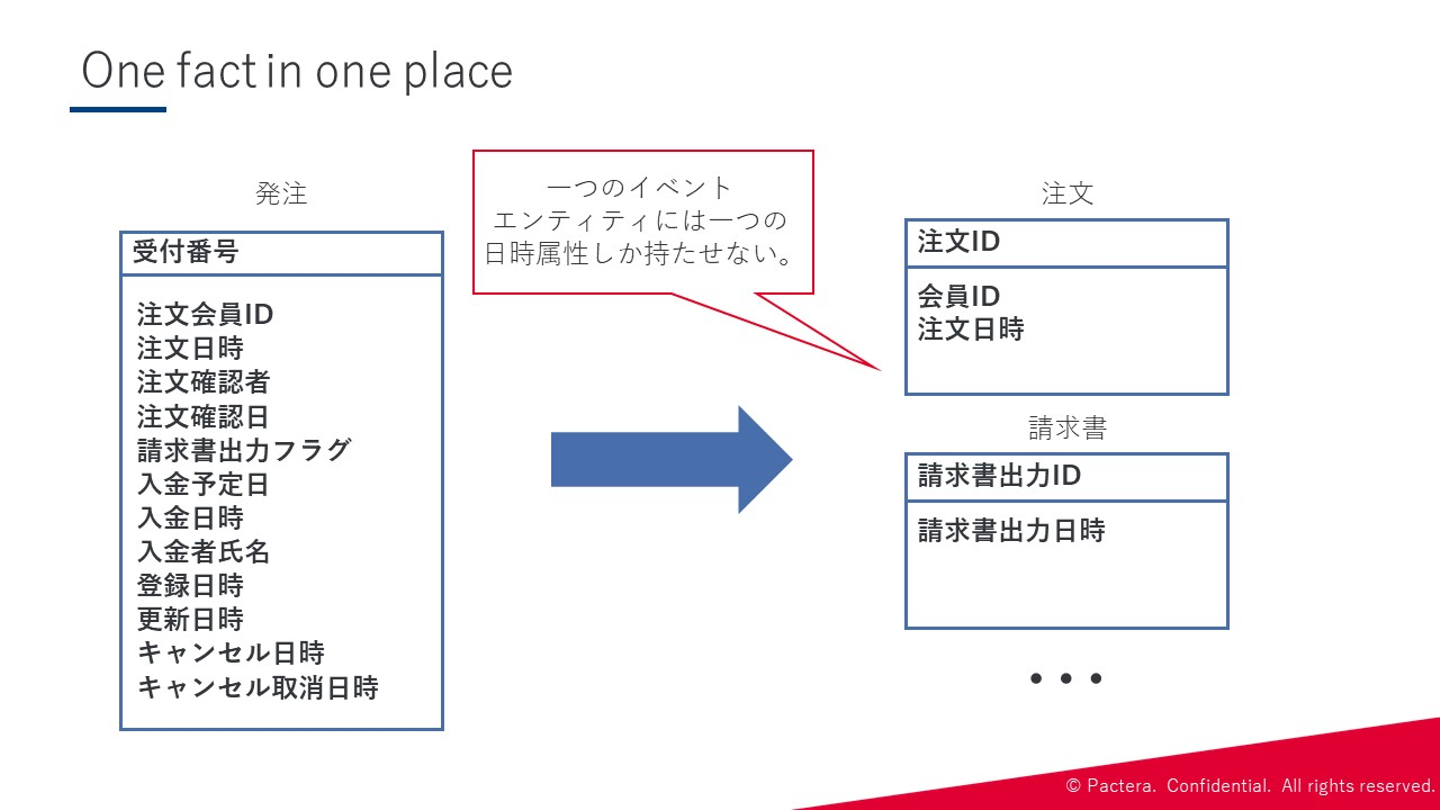
Step3:イベントエンティティの処理 エンティティの分類を行った次は、イベントエンティティの処理です。具体的には、 イベントエンティティは1つの日時属性しか持たせないようにする ことです。( One fact in one place ) イベント系エンティティは業務の記録であるため、その更新は記録の更新、言い方を変えれば記録の改ざんになります。そのため、イベントエンティティは更新が入らないデータを格納するため、属性は1つだけしか持たせることができないのです。
また、イベントエンティティは、システム上ではコアな部分であり、業務上最も重要なエンティティなので、 ER図を書く際には、図上の中心に添える ことを心がけましょう。
Step4:リソースに隠されたイベント抽出 リソースエンティティに更新日時を持たせたくなるのは、リソースにまつわるイベントが洗い出せていないことが原因です。その際はもう一度、抽出結果を見直してリソースに隠されたイベントを選定しましょう。
また、リソースに対する変更の記録としてのイベントエンティティは、 履歴テーブル とも言えます。履歴テーブルの実装には正解というものが存在せず、業務要件などに照らし合わせながら設計することになります。もし、リソースに対する変更日時を記録したいと思ったら、イベントとして切り出すと良いでしょう。
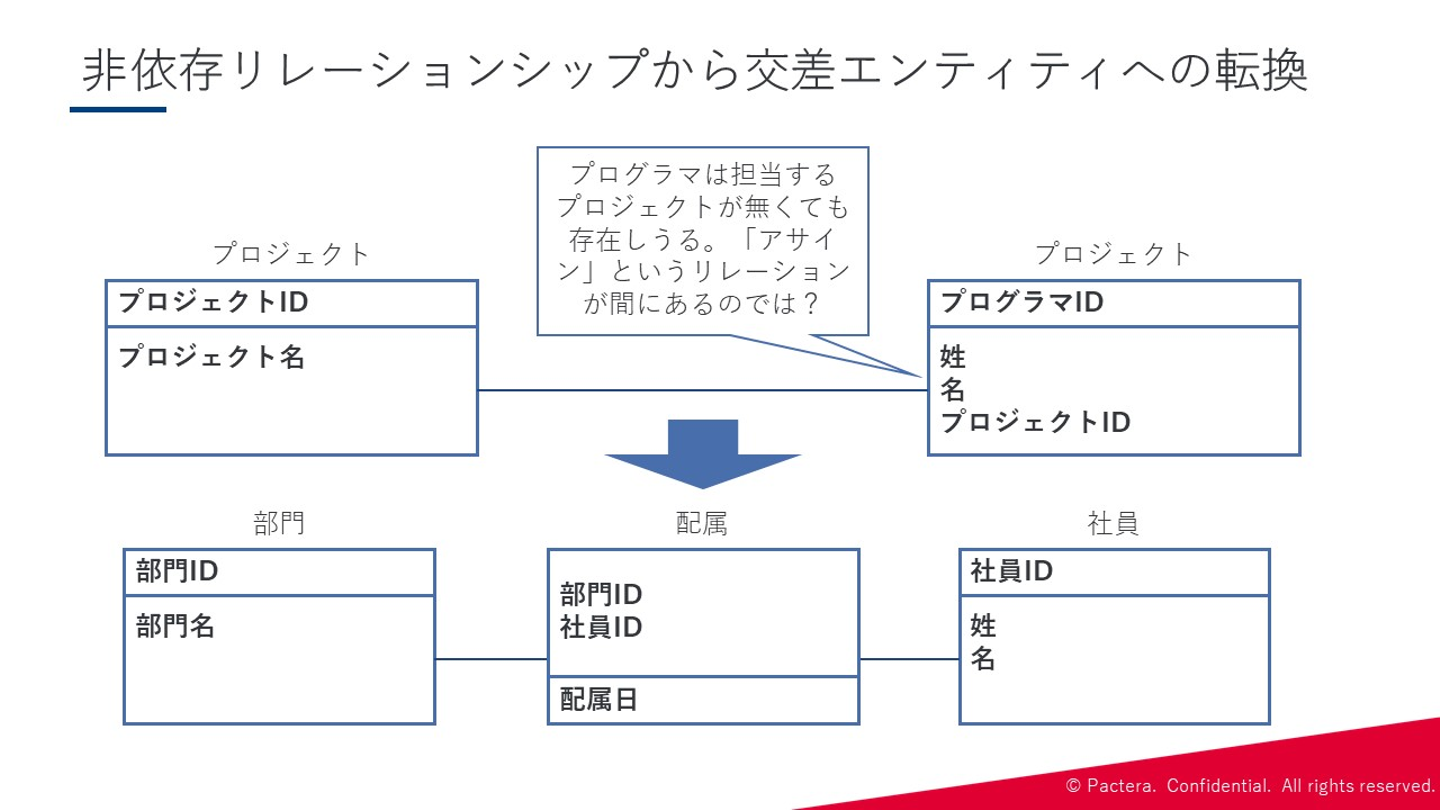
Step5:非依存リレーションシップから交差エンティティへの転換 最後のStepになります。リレーションが非依存である場合、外部キーにNULLを許し、後でアップデートすることが可能になってしまいます。つまり、一方のエンティティのキーを、もう一方に外部キーとして持たしてしまい、強い関係を生み出してしまうのです。このような要求の裏には別のイベントが隠れていることがあります。
ここで重要なのは、 非依存リレーションシップが互いに独立して存在する中で、どのイベントが関係性を構築しているのか洗い出す ことです。 これを行わずにカーディナリティだけでリレーションシップを考えると、業務上必須だったイベントエンティティを見落すことに繋がります。
演習 以上を踏まえて、実際にデータモデルの設計をしてみましょう。演習の詳細はこちらです。
演習の答え合わせは、次回のレポートで致します。それまでに是非、取り組んでみましょう。
終わりに 以上が今回のPETSのレポートでした。いかがでしたか? こちらをご覧になられた方の力に少しでもなれたら幸いです。
効率的なシステム保守のために不可欠な、データモデリングですが、更新日時に着目し、それらをエンティティとして抽出することで、堅牢なデータモデルを設計できることが分かりました。
パクテラでは引き続き、日本のDX化を促進させる活動の一環として社内研修の内容をご報告させていただきます。是非、今後ともよろしくお願いいたします。
最後になりますが、ご一読いただきありがとうございました。
今までのPETSに関する投稿はこちらになります。ご興味のある方は、是非ご覧ください。
パクテラ・コンサルティング・ジャパン株式会社's job postings
/assets/images/17001890/original/ae2a8c44-802f-4add-9fcc-b216f78a5c6e?1707888304)




/assets/images/17001890/original/ae2a8c44-802f-4add-9fcc-b216f78a5c6e?1707888304)

/assets/images/3245283/original/a4cb1fe8-d106-49d9-a00a-e0de8b0257fa.png?1542765005)
