-Qiita記事Part.14-【Python】位置情報解析ライブラリscikit-mobilityについて④ ~データ解析編・人流データ全体解析~

こんにちは、ナイトレイインターン生の田中です。
Wantedlyをご覧の方に、ナイトレイのエンジニアがどのようなことをしているか知っていただきたく、Qiitaに公開している記事をストーリーに載せています。
少しでも私たちに興味を持ってくれた方は下に表示される募集記事もご覧ください↓↓
1. scikit-mobilityとは?
scikit-mobilityは位置情報データを使用して人の動きを解析したり、可視化することができるpythonライブラリです。
公式ドキュメント:https://scikit-mobility.github.io/scikit-mobility/index.html
GitHub:https://github.com/scikit-mobility/scikit-mobility
公式ドキュメントは英語しかありませんが結構充実していて、
GitHubにはチュートリアル等も載っているので試してみるのがおすすめです。
scikit-mobilityの主な機能と、チュートリアルについて解説しているQiitaもありますのでこちらも是非参考にしてください。
2. 今回紹介する関数
- カテゴリ:measures(データ解析用関数)
- 参考URL:https://scikit-mobility.github.io/scikit-mobility/reference/measures.html
- 概要:緯度・経度・日時・ユーザーid等のデータから様々な移動パターンの解析を行うことができる関数が用意されています。
また、データ解析用の関数には二種類のカテゴリがあります。
- Collective measures(集団解析) : データセット全体の動きを解析できる関数
- Individual measures (個別解析):データセット内のユーザーそれぞれの動きを解析できる関数
今回はこのうち
1. Collective measures(集団解析)
に分類される関数たちを6つ、コードを交えて紹介していきます。
※ 今回この記事で使用しているデータは社内検証用のデータになります。
3. 前提処理
ライブラリのインストール
$ pip install scikit-mobility
詳しい環境構築はこちらを参考にしてください
TrajDataFrameデータの作成
- 以下の項目を含むデータを用意します。
latitude(type: float); 緯度(必須)
longitude (type: float); 経度(必須)
datetime (type: date-time); 日時(必須)
uid (type: string);(オプション)
tid (type: string); (オプション)
特に使いたいデータがない場合はscikit-mobilityのチュートリアルを参考にこちらのデータをダウンロードするといいと思います。
※自動でデータがダウンロードされるので気をつけてください
# ファイルのダウンロード(google colab等で実行する場合はこうすると楽です。)
import urllib.request
url='https://raw.githubusercontent.com/scikit-mobility/scikit-mobility/master/examples/geolife_sample.txt.gz'
save_name='geolife_sample.txt.gz'
urllib.request.urlretrieve(url, save_name)
- 用意したデータをTrajDataFrameに変換します。
import skmob
# リストをTrajDataFrameに変換する場合
tdf = skmob.TrajDataFrame(data_list, latitude=1, longitude=2, datetime=3)
# pandas.DataFrameをTrajDataFrameに変換する場合
tdf = skmob.TrajDataFrame(data_df, latitude='latitude', datetime='hour', user_id='user')
- TrajDataFrameはPandasDataFrameを拡張したものなので、Pandasでできるような基本的な処理を行うことができます。
4. Collective measures(集団解析)
参考URL:https://scikit-mobility.github.io/scikit-mobility/reference/collective_measures.html
概要
入力したuidにかかわらず、入力したデータ内のユーザー全体の位置データの傾向を解析する関数が用意されています。
random_location_entropy
概要
特定の場所を訪れたユーザーの推測可能性(ロケーションエントロピー)が算出されます。
(ロケーションエントロピーについては難しかったので、勉強中です。。)
inputに必要なデータとパラメータ、outputされるデータについて
- inputデータ
- tdf(TrajDataFrame): 緯度経度データ
- パラメータ
- show_progress: Trueの場合、プログレスバーを表示
- inputするデータ例
- データ型がTrajDataFlameのデータを使うことができます。
- 中身はこんな感じです。
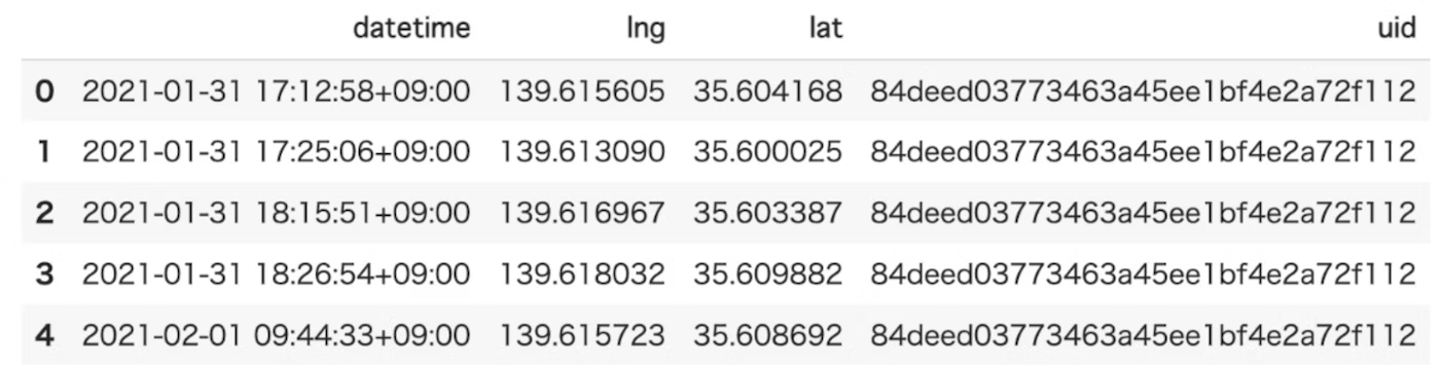
- outputデータ
- 各場所のランダムなロケーションエントロピーが出力されます。
- outputされるデータ例は以下のようになります。
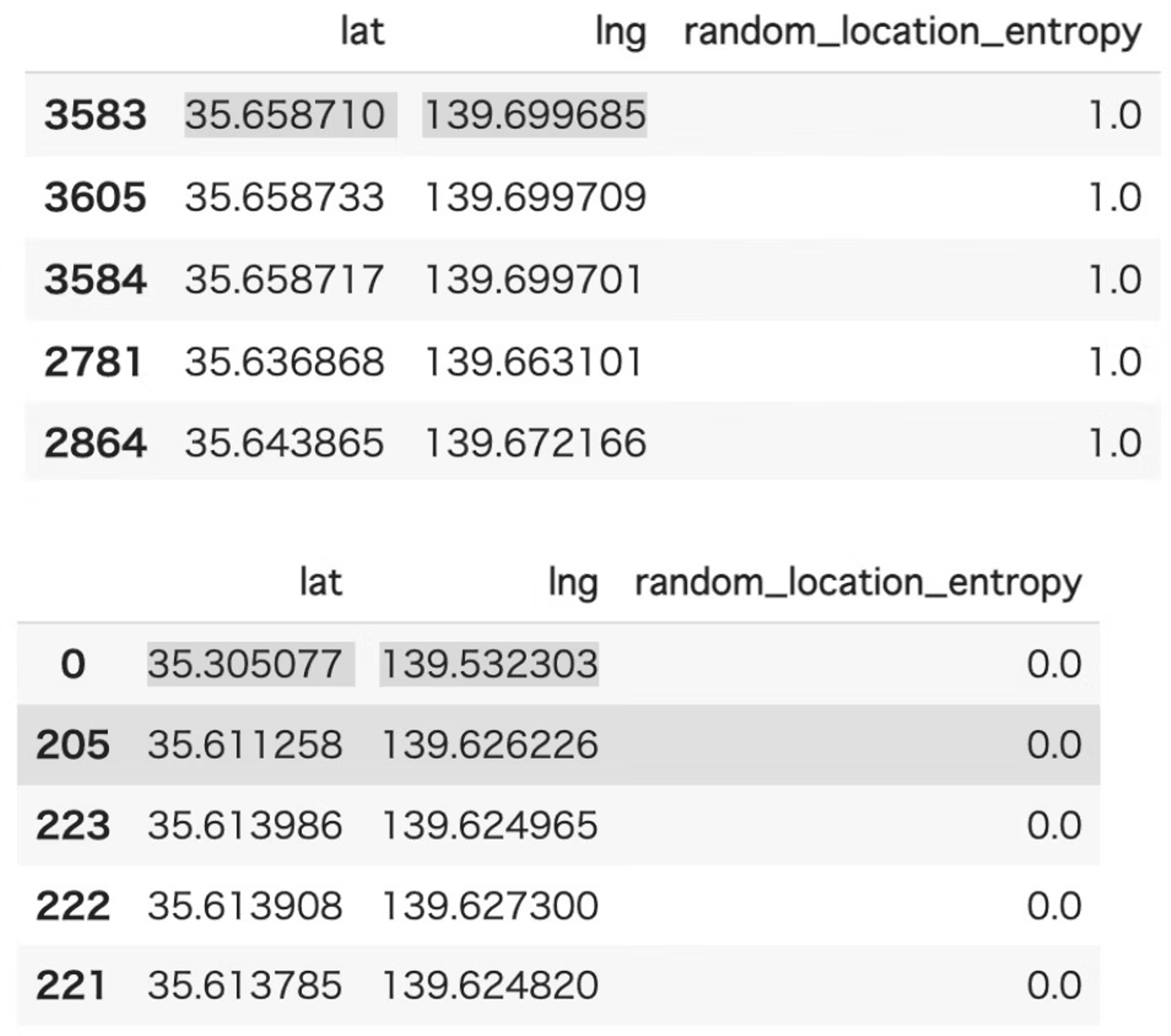
- id, lng, lat, random_location_entropyのカラムが出力されます。
- random_location_entropyの値は0.0~1.0の間の値になります。
- random_location_entropyが1に近いほどユーザーが全体的に行く確率が高い場所になっています。
- データ内のユーザーがよく訪問する傾向にある場所を知りたい時などに役立ちそうです。
コード例
from skmob.measures.collective import random_location_entropy
# 'sort_values'でrandom_location_entropyの高い順にソート
rle_df = random_location_entropy(tdf,
show_progress=True).sort_values(by='random_location_entropy', ascending=False)
rle_df.head()
- データ内のユーザーがいる確率が最も高いとされるrandom_location_entropy=1.0の場所を可視化してみました。
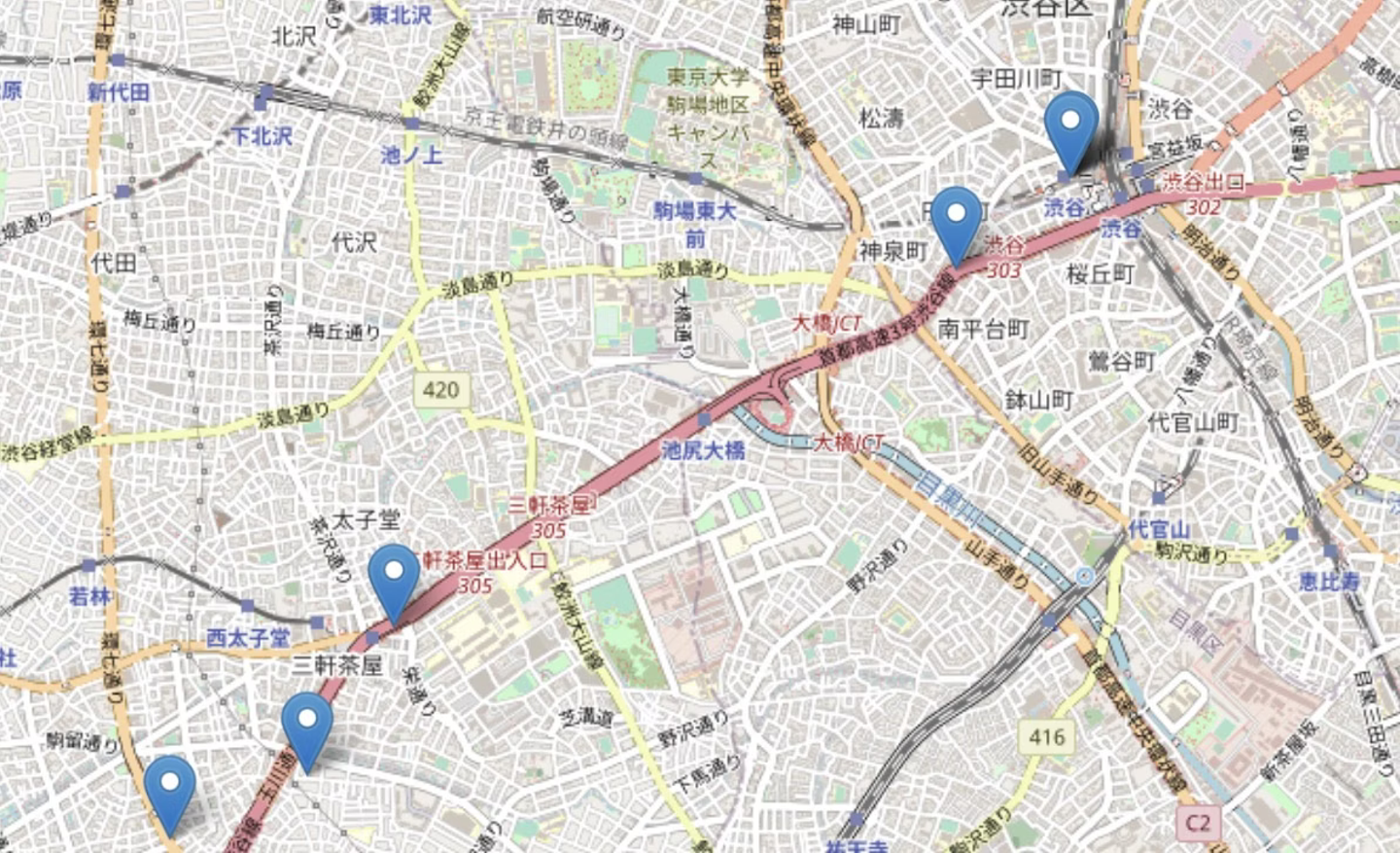
→ 渋谷周辺が最もデータ内のユーザーが訪問する確率が高いとされているようです。
→ ナイトレイ社内のデータなので、ナイトレイがある渋谷の確率が高いのは矛盾がないですね。
uncorrelated_location_entropy
概要
時間的な相関のない特定の場所に訪問したことがあるユーザー数の推測可能性を算出する関数です。
inputに必要なデータとパラメータ、outputされるデータについて
- inputデータ
- tdf(TrajDataFrame): 緯度経度データ
- パラメータ
- normalize: Trueの場合、位置エントロピーを正規化する。
- show_progerss: Trueの場合、プログレスバーを表示する。
- inputするデータ例
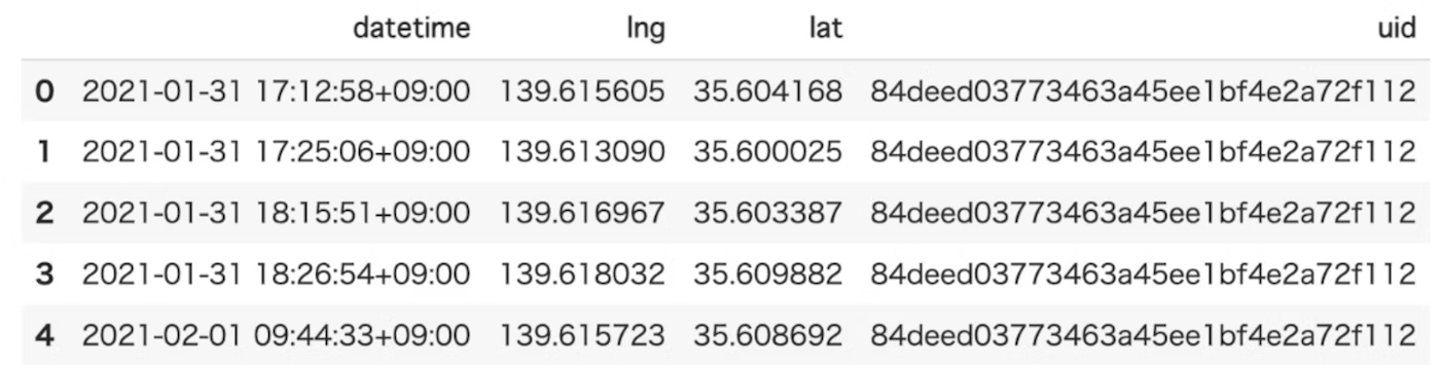
- データ型がTrajDataFlameのデータを使うことができます。
- 中身はこんな感じです。
- outputデータ
- 各場所の時間的に相関のないロケーションエントロピーを算出します。
- outputされるデータはこんな感じになっています。
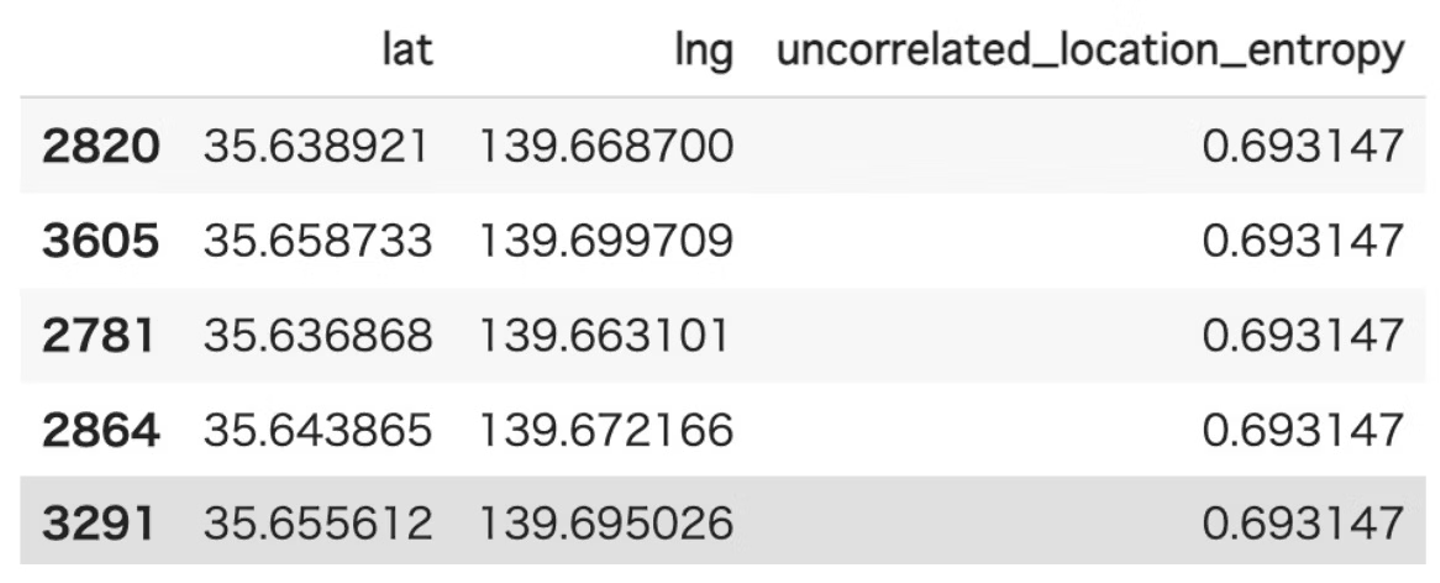
- id, lng, lat, random_location_entropyのカラムが出力されます。
- uncorrelated_location_entropの値は0.0~1.0の間の値になります。
コード例
from skmob.measures.collective import uncorrelated_location_entropy
# 'sort_values'でuncorrelated_location_entropyの高い順にソート
ule_df = uncorrelated_location_entropy(tdf, show_progress=True).sort_values(by='uncorrelated_location_entropy', ascending=False)
ule_df.head()
mean_square_displacement
概要
全体の平均二乗ゆらぎを計算します。
平均二乗ゆらぎ:時間の経過に伴う基準位置に対するオジェクトの位置の偏差の尺度
知識が足りず理解できていないです。勉強中です。。
inputに必要なデータとパラメータ、outputされるデータについて
- inputデータ
- tdf(TrajDataFrame): 緯度経度データ
- パラメータ
- days: 開始時刻からの日数
- hours: 開始時刻からの日数からの時間
- minutes: 開始時刻からの日数からの時間からの分数
- show_progress: Trueの場合、プログレスバーを表示
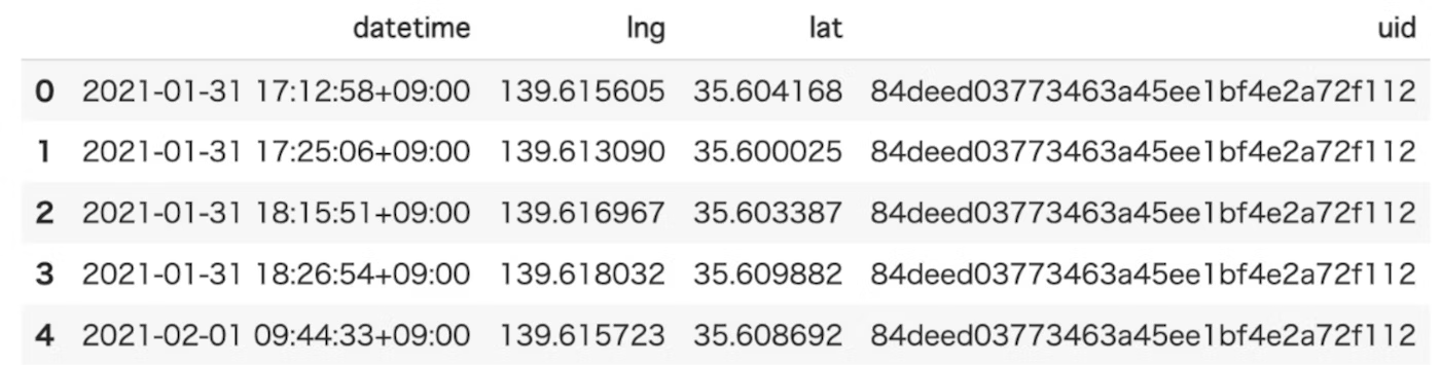
- inputするデータ例
- データ型がTrajDataFlameのデータを使うことができます。
- 中身はこんな感じです。
- outputデータ
- 平均二乗ゆらぎを算出します。
- outputされるデータはこんな感じです。
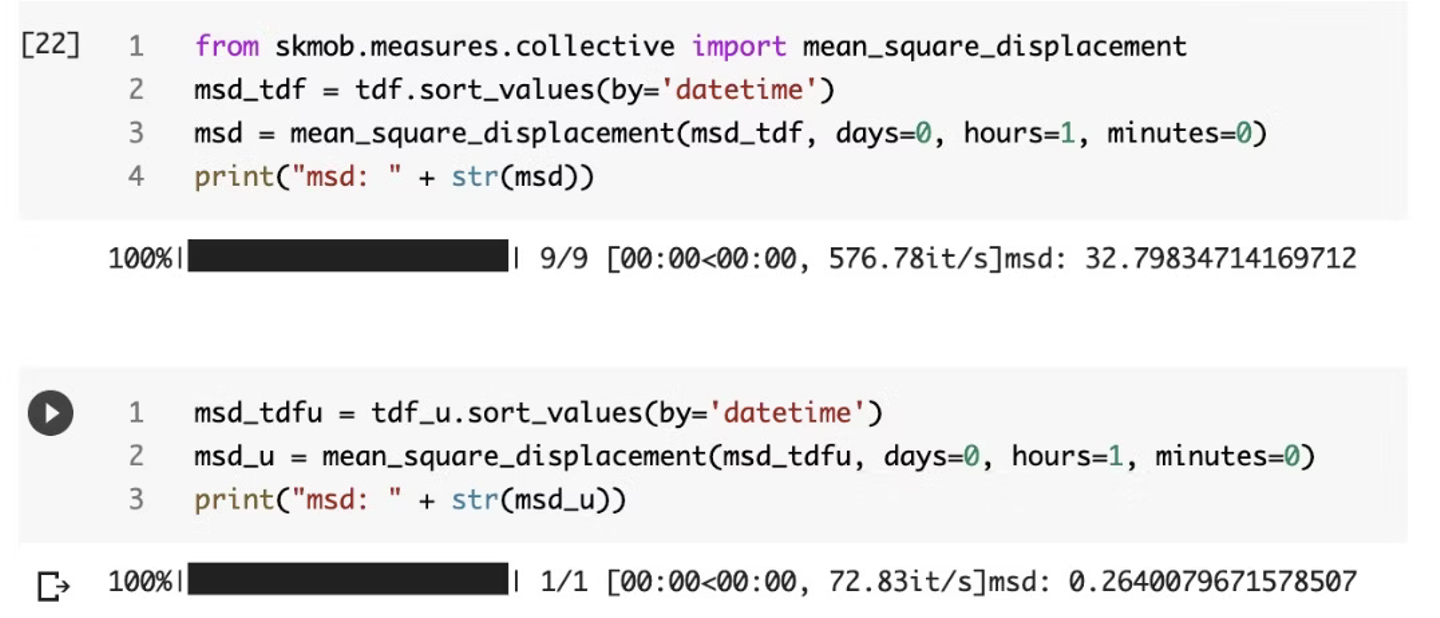
コード例
from skmob.measures.collective import mean_square_displacement
msd_tdf = tdf.sort_values(by='datetime')
msd = mean_square_displacement(msd_tdf, days=0, hours=1, minutes=0)
visits_per_location
概要
各ロケーション(場所)への全ユーザーの総訪問数を算出します。
inputに必要なデータとパラメータ、outputされるデータについて
- inputデータ、パラメータ
- tdf(TrajDataFrame): 緯度経度データ
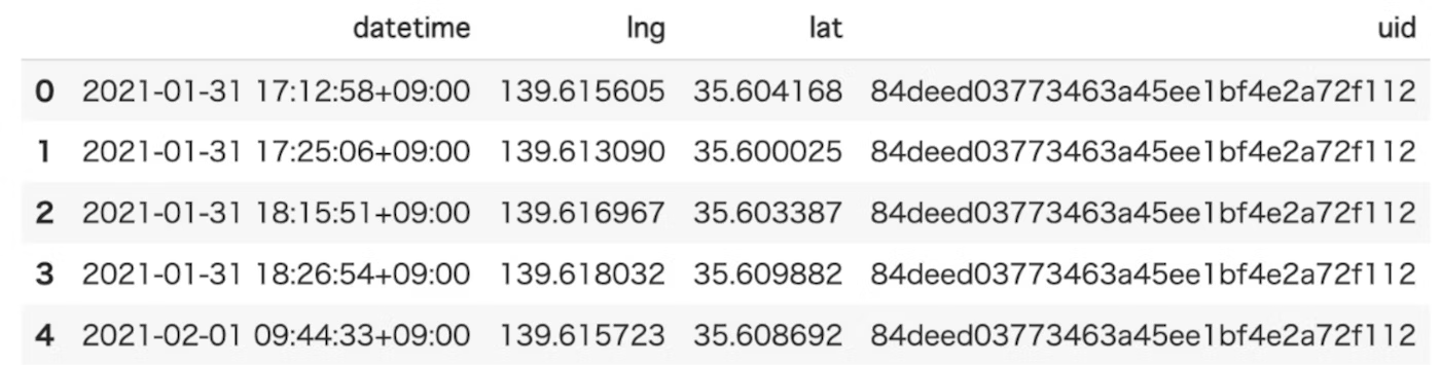
- inputするデータ例
- 中身はこんな感じです。
- outputデータ
- 各ロケーションごとの訪問数が算出されます。
- 訪問数(n_visits)の値で多くのユーザーが訪れた場所がわかります。
- outputされるデータ例
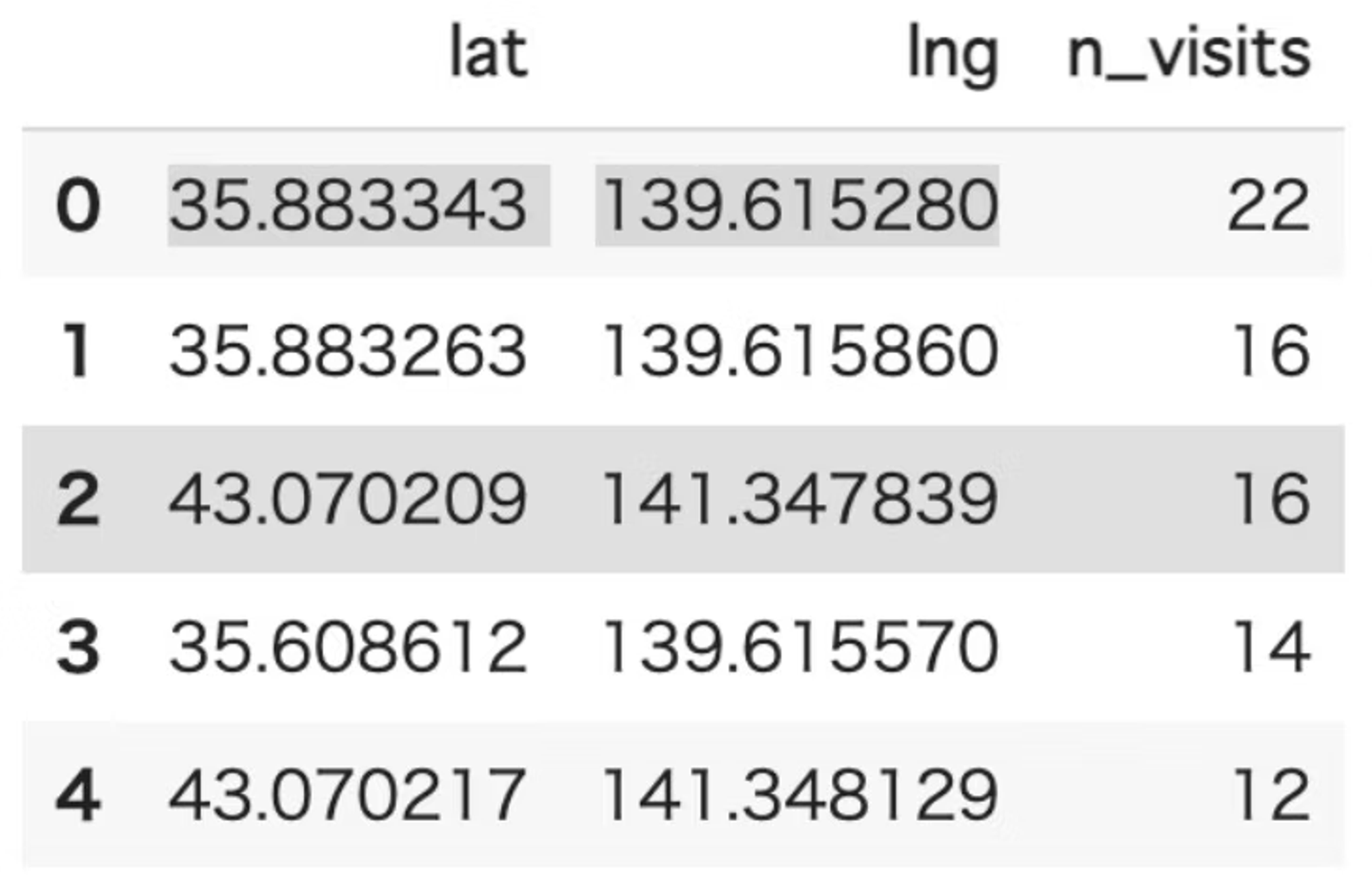
- データ内のユーザーが多く訪問した場所を調べることができます。ユーザーの訪問傾向を調べるのに役に立ちそうです。
コード例
from skmob.measures.collective import visits_per_location
vl_df = visits_per_location(tdf)
vl_df.head()
homes_per_location
概要
特定の場所にある自宅の数が算出されます。
夜の時間帯に最も多くユーザーがいた緯度経度を"家"と定義しているようです。
inputに必要なデータとパラメータ、outputされるデータについて
- inputデータ、パラメータ
- tdf(TrajDataFrame): 緯度経度データ
- パラメータ
- start_night: 夜判定の開始時刻(形式:HH:MM)
- end_night: 夜判定の終了時刻(形式:HH:MM)
- inputするデータ例
- データ型がTrajDataFlameのデータを使うことができます。
- 中身はこんな感じです。
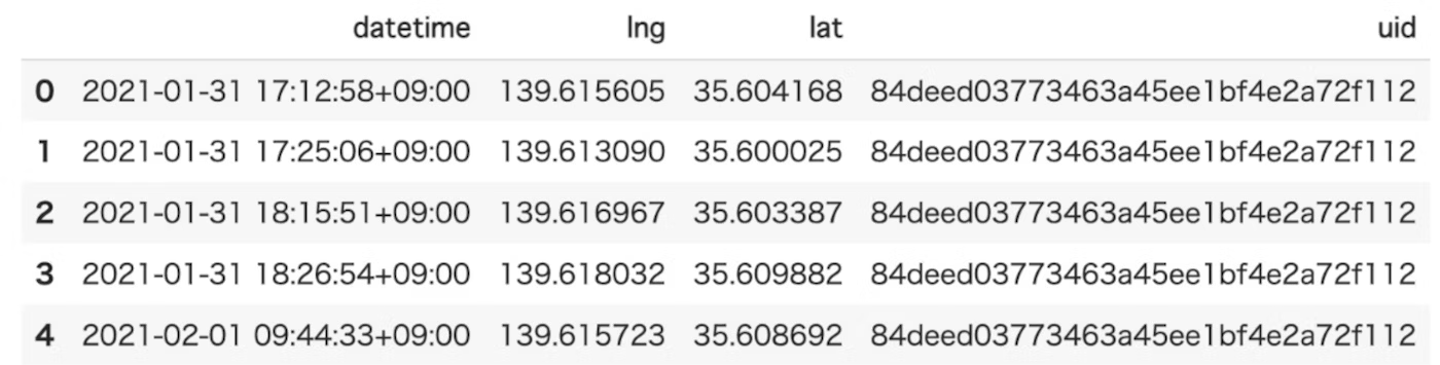
- outputデータ
- ロケーションごとの自宅の数が出力されます。
- outputされるデータ例
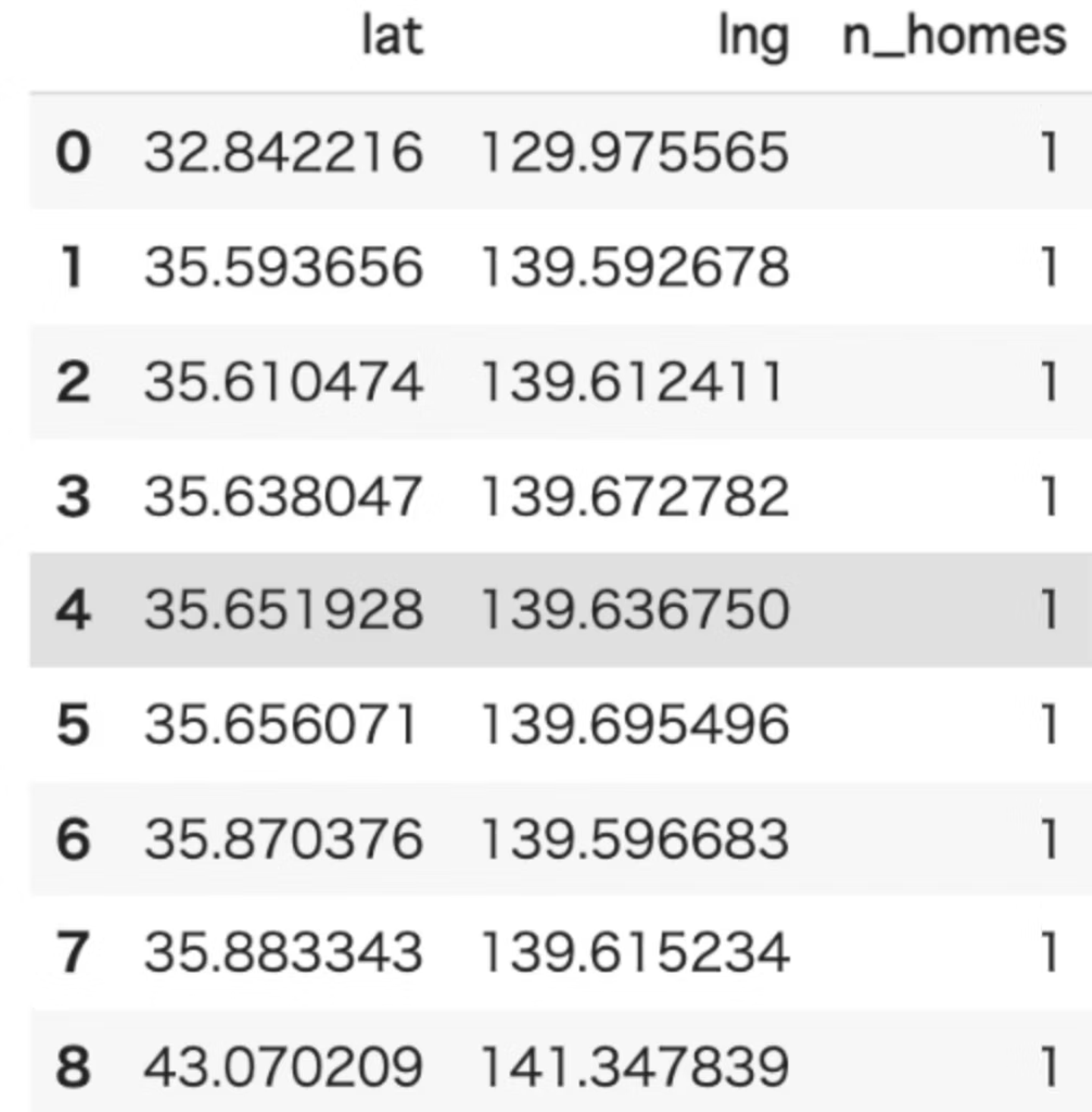
- データ内のユーザーが住んでいる傾向が高い駅や場所を割り出すのに役立ちそうです。
- また、時間帯で「家」と判断しているようなので、時間帯を平日の昼時などにして「職場」の場所の傾向を掴んだりするのにも使えるのではないかと思っています。
コード例
from skmob.measures.collective import homes_per_location
hl_df = homes_per_location(tdf).sort_values(by='n_homes', ascending=False)
hl_df.head()
visits_per_time_unit
概要
単位時間あたりの訪問数を算出します。
inputに必要なデータとパラメータ、outputされるデータについて
- inputデータ
- tdf(TrajDataFrame): 緯度経度データ
- パラメータ
- time_unit: 単位時間の指定
- inputするデータ例
- データ型がTrajDataFlameのデータを使うことができます。
- 中身はこんな感じです。
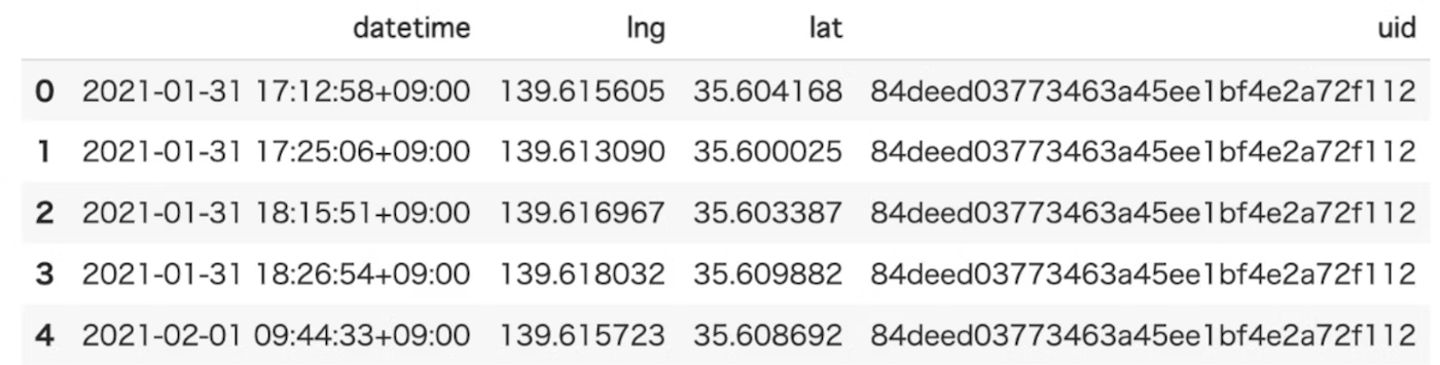
- outputデータ
- 単位時間あたりの訪問数を算出することができます。
- outputされるデータ例
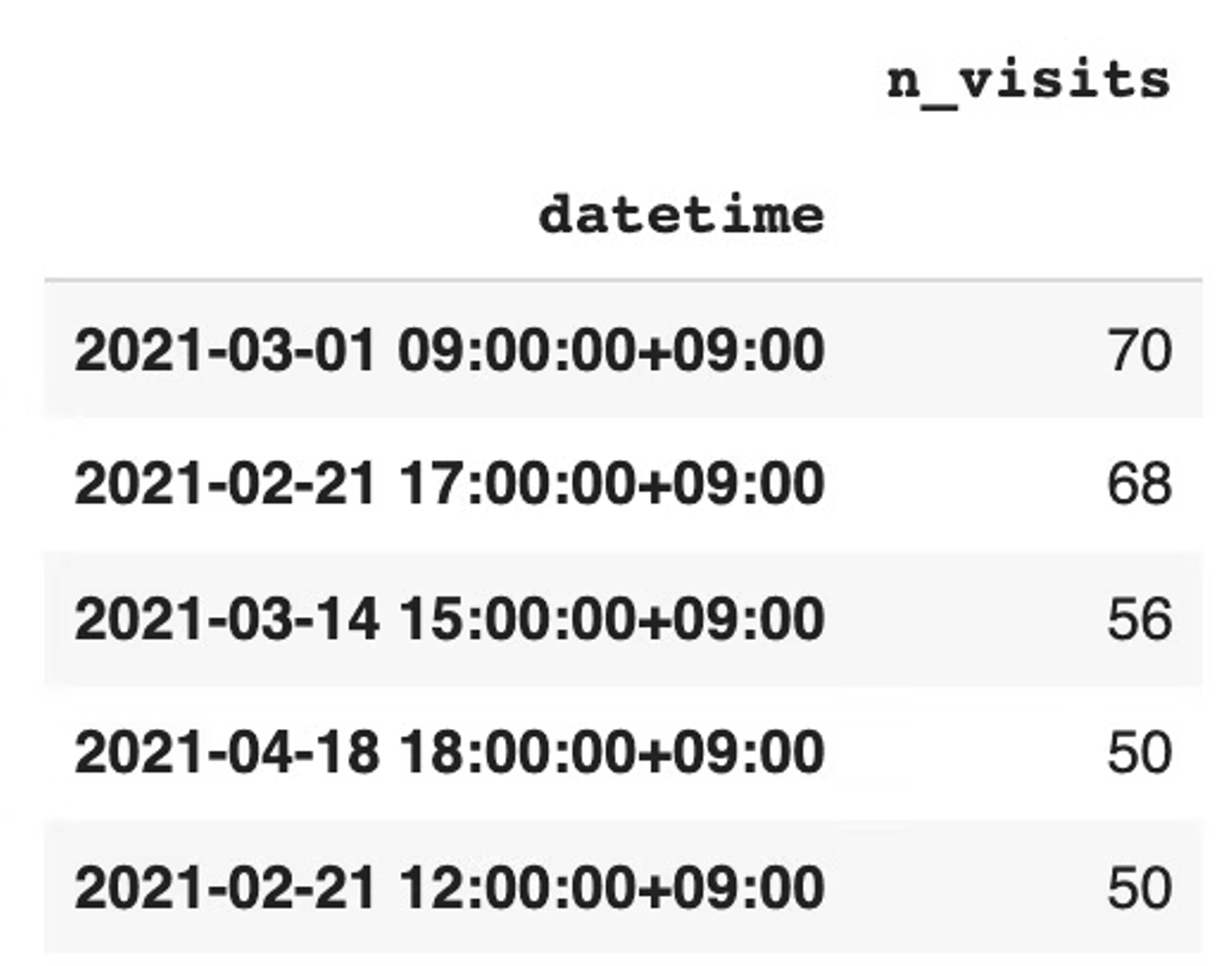
- どのような時間帯にデータ内のユーザーの動きが多いかが知りたい時に役立ちそうです。
- 曜日などをカラムとして追加したりするとさらに傾向がわかりやすくなりそうです。
コード例
from skmob.measures.collective import visits_per_time_unit
vtu_df = visits_per_time_unit(tdf)
vtu_df.sort_values("n_visits", ascending=False).head()
5. シリーズ記事
今回はここまでになります。
ここまで読んでいただき、ありがとうございました。
scikit-mobilityについて、シリーズで記事を投稿しています。
シリーズの記事もぜひ読んでいただけると嬉しいです。
前回の記事はこちらです。
最後に
私たちの会社、ナイトレイでは一緒に事業を盛り上げてくれるGISチームメンバーを募集しています!
現在活躍中のメンバーは開発部に所属しながらセールス部門と密に動いており、
慣れてくれば顧客とのフロントに立ち進行を任されるなど、顧客に近い分やりがいを感じやすい
ポジションです。
このような方は是非Wantedlyからお気軽にご連絡ください(もしくは recruit@nightley.jp まで)
✔︎ GISの使用経験があり、観光・まちづくり・交通系などの分野でスキルを活かしてみたい
✔︎ ビッグデータの処理が好き!(達成感を感じられる)
✔︎ 社内メンバーだけではなく顧客とのやり取りも実はけっこう好き
✔︎ 地理や地図が好きで仕事中も眺めていたい
/assets/images/17514/original/558f701b-5611-44f3-bc41-0c96b473917a.png?1427288547)


/assets/images/17514/original/558f701b-5611-44f3-bc41-0c96b473917a.png?1427288547)

/assets/images/8300070/original/558f701b-5611-44f3-bc41-0c96b473917a.png?1639042247)


