
JMDC開発本部データ基盤開発部の杉山です。
医療ビッグデータ事業を展開するJMDCでは、様々な医療データを取り扱い、価値創出へとつなげています。医療データと言っても、その種類や役割は実に幅広く、多岐にわたっています。
私たちは、どんな医療データを扱っているのか。今回は、その中でもJMDCのデータ事業の代名詞とも言える保険者データ(レセプトデータ等)に焦点を当てて、分かりやすく解説していきたいと思います。

プロフィール
杉山 岳史(すぎやま たけふみ)
株式会社JMDC 開発本部 データ基盤開発部 保険者基盤グループ マネージャー
新卒で入社した情報システム会社でSI事業を一通り経験。2018年8月、JMDCに転職しデータ基盤開発部に配属後、レセプト取り込みシステムを担当。現在は保険者基盤グループのマネージャーとして、保険者データ基盤の構築・管理を担当。
事業の原点は、紙レセプトを集めてデータ化すること
まずは、JMDCが取り扱っている医療データにはどんな種類があるのか、全体像を見ていきます。受領元でカテゴライズすると、以下の4つに大別されます。
1.健康保険組合から受領するデータ(保険者データ)
1-①:レセプトデータ
1-②:健康診断データ
1-③:適用台帳
2.医療機関から受領するデータ
2-①:DPCデータ
2-②:検査値データ
3.自治体から受領するデータ
国民健康保険、協会けんぽのレセプトデータ
4.PHRデータ(個人の健康データ)
今回は、上記のうちJMDCが保有するデータ量として最大の規模である健康保険組合から受領するデータ(保険者データ)にフォーカスして解説します。
健康保険組合との取引が年々発展
保険者には、国民健康保険、健康保険組合、協会けんぽ、共済組合といった種類があり、皆さんいずれかの保険に加入されているかと思います。こうした保険者の中でもJMDCは、健康保険組合との取引をメインに展開しています。
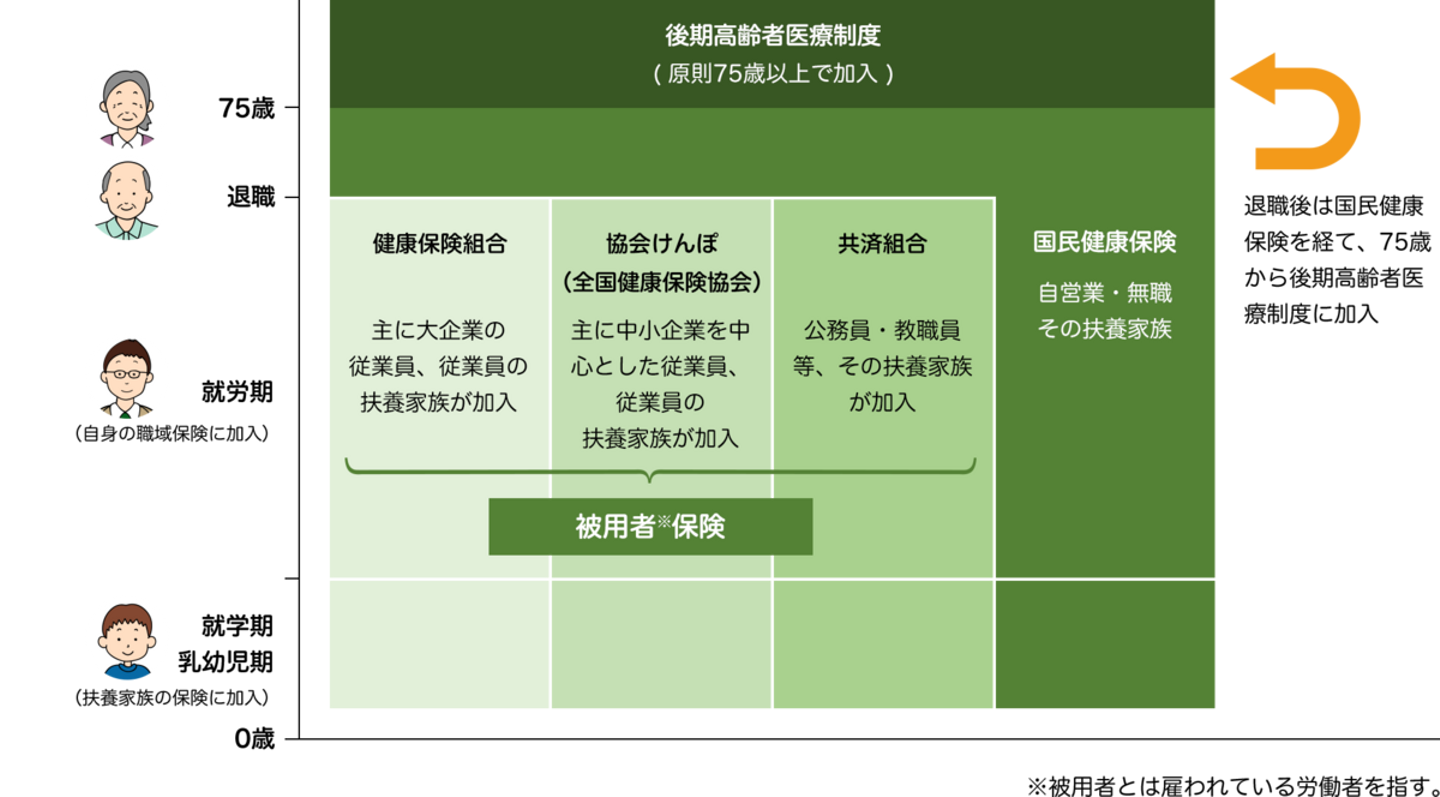
JMDCの事業のひとつに、保険者支援サービスがあります。健康保険組合は、被保険者の健康を増進する保健事業というものを推進しており、我々はその保健事業を支えるための分析ツールやコンサルティングなどを提供しています。
こうしたサービスの大元となっているのが、保険組合が保有する各データ(医療機関からのレセプト等)で、私たちはそのデータをお預かりしデータベース化してサービス価値を生み出しています。

健康保険組合との取引は、年々増加。それに応じて、取り扱うデータ量も増えています。
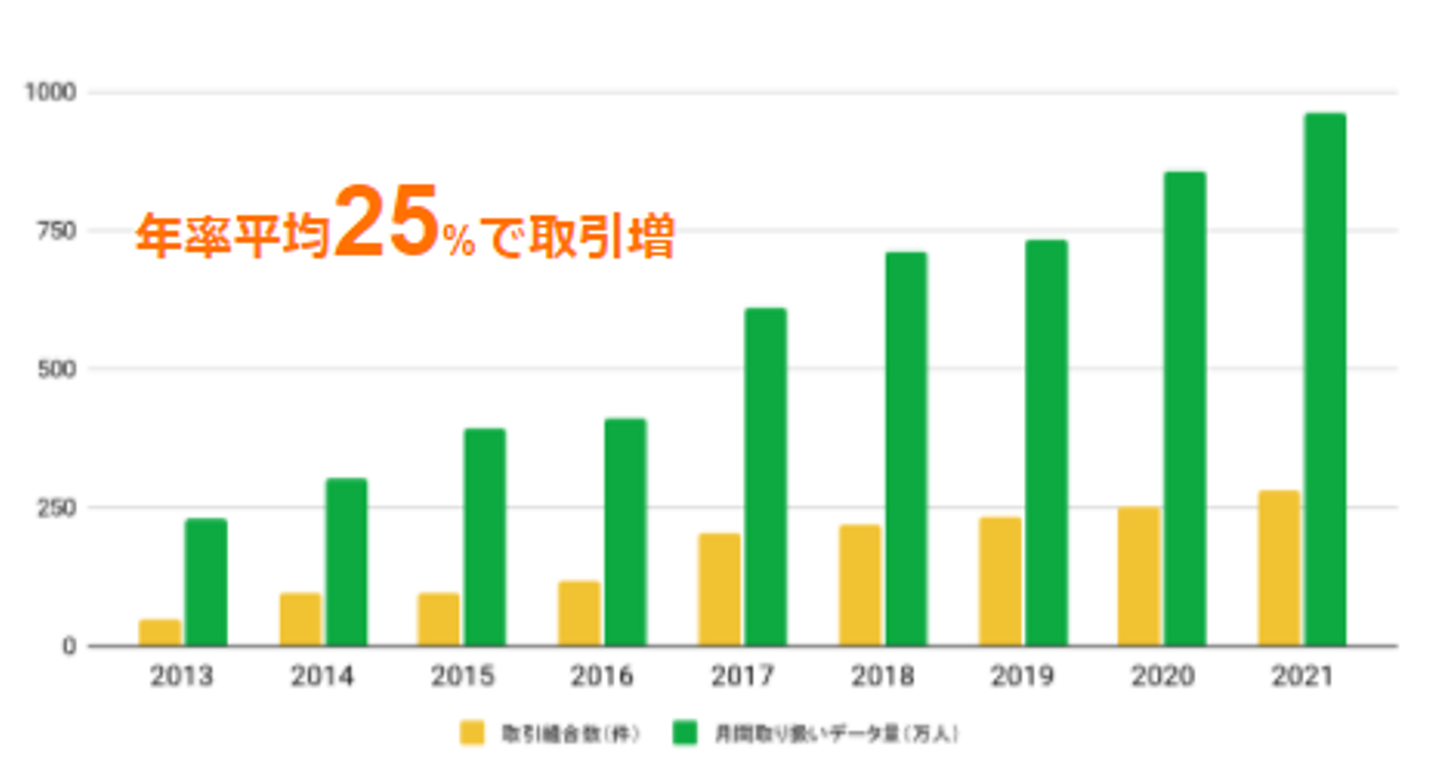
そもそも、なぜJMDCが保険者データを扱うようになったのか。 これは2002年の創業まで遡ります。当時、製薬会社に勤務していた創業者の木村は、実際の医療現場で患者にどんな薬がどのように使われているのかがデータで把握できれば、社会的なバリューにつながると考えました。
そこで可能性を見出したのが、診療報酬請求で使うレセプト(当時はデータではなく紙)でした。木村は健康保険組合に飛び込み、データベースの価値を伝え、紙レセプトを提供してくれる組合を少しずつ増やしていったのです。当時からの地道な蓄積が、現在の巨大データベースへとつながっています。
国内最大規模の累計1300万人のレセプトデータ
次にJMDCが保有する保険者データの種類について詳しく見ていきましょう。保険者データは、次の3つに大別されます。
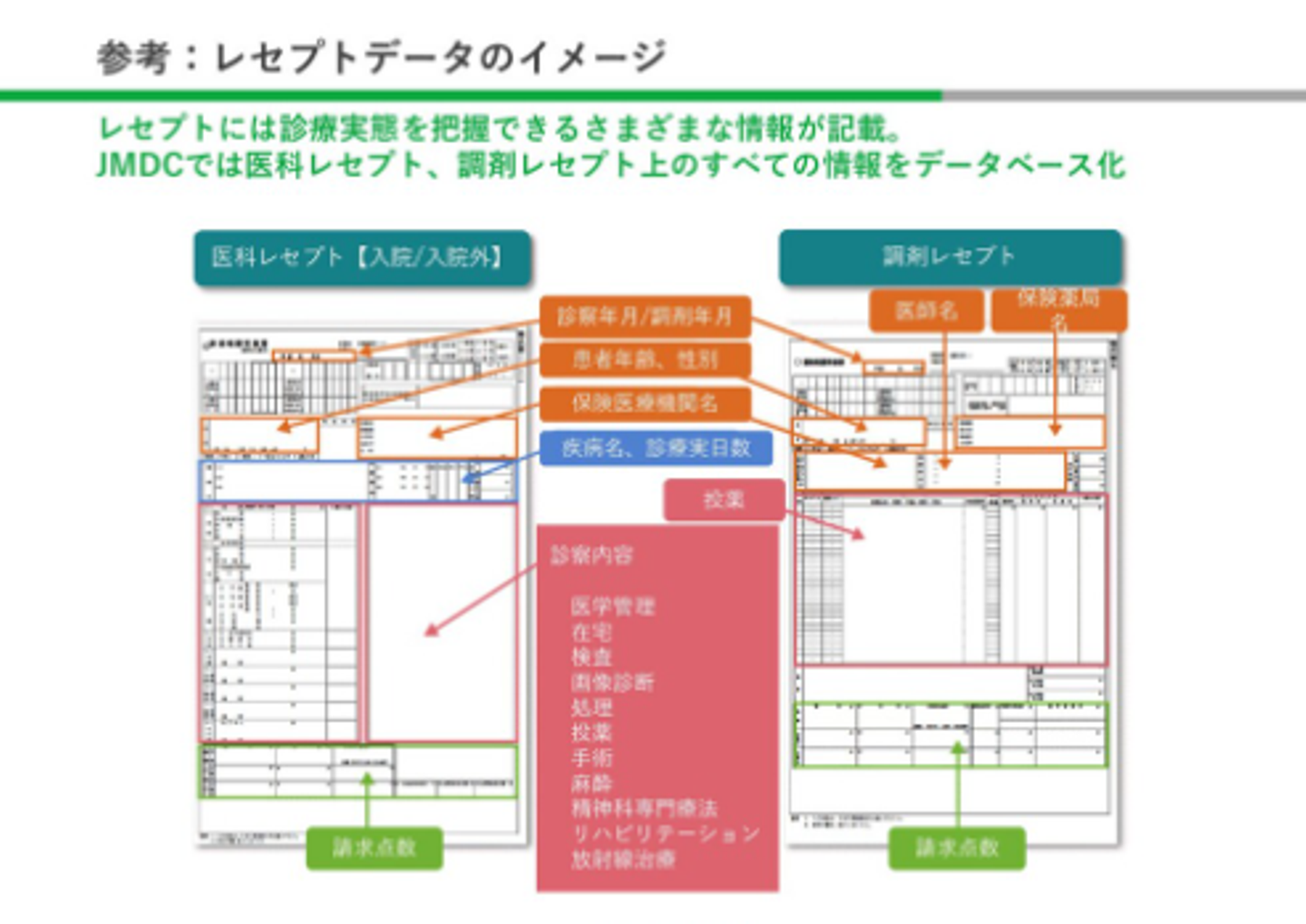
【1】レセプトデータ
レセプトデータとは、医療機関(病院、歯科、調剤薬局等)が保険者負担分の診療報酬を請求する際に送るデータを指します。診療報酬明細書とも呼ばれ、JMDCでは主に病院からの「医科レセプト」と保険薬局からの「調剤レセプト」の2種類を扱っています。
レセプトには、傷病名や医療行為が項目ごとに記載されていて、各項目の診療報酬点数が入力されています。病院に行ったときにもらう領収書や明細書を見たことがある方は多いと思いますが、このうち明細書の内容が所定のルールをもとにレセプトデータとしてまとめられています。
【2】健康診断データ
健康診断データ(以下、健診データ)は、被保険者が健診機関で受けた健康診断のデータです。身長・体重はもちろんのこと、血液検査、X線検査の数値、医師の所見などが含まれます。JMDCでは、主に40歳以上が受ける人間ドックや1日健診のデータを保有しています。そこには特定健康診査、いわゆるメタボ健診も含まれています。
【3】適用台帳データ
適用台帳データは、保険組合で管理する被保険者証記号・番号に紐づく個人情報のデータです。皆さんが持っている保険証に記載されている情報となります。
これらの保険者データを膨大に蓄積・運用しているのが、JMDCの優位性となっています。例えば、レセプトデータは国内最大級規模の累計母集団1,300万人を保有。これは全国の約10%に当たる数字で、件数だと6億5,000万件を超えています。
また、大規模レセプトデータに紐づく各情報も膨大な量を管理しています。
代表的なデータ項目(カラム)に「傷病」「医薬品」(「傷病」は風邪や喘息といった疾病・怪我の名前のことです)がありますが、それぞれの累積テーブル数を測定してみたところ「傷病」が15億5,000万件以上、「医薬品」が4億6,000件以上ありました。(傷病名の種類がこの数あるというわけではなく、全レセプトデータから傷病に分類される累計のテーブル数です)
他にも、カラムには以下のようなものがあります。
「患者情報」被保険者記号・番号、氏名、生年月日など
「傷病」患者が診断された疾病名 例:風邪、高血圧症
「診療行為」診療行為名 例:検査、X線、注射
「医薬品」医薬品名
「材料」診療行為で使われた材料 例:注射針、ブドウ糖

データの数に加えて、データの精度の高さもJMDCならではの特徴です。適用台帳にある個人情報とレセプトデータを独自の論理回路で紐づけることで、「誰がどこでどんな治療を受けて、どんな薬を処方されたのか」が追跡可能になっています。
一例を出すと、レセプトデータの中でも医科レセプトと調剤レセプトは出所が別ですので、全く別のものとして存在しています。そのため両方のレセプトデータがあったとしても同一人物のものだとみなされなかったり、薬がどんな病気で処方されたのかをつかむことはできません。
しかし、当社では一気通貫で紐づいているため、AさんがB病院でCという診断を受けてD調剤薬局でEという薬を処方されたことが分かります。この「すべての情報が紐づいている」ことが、ビッグデータ事業において何事にも代えがたい競争優位性になっています。他社にはないJMDC独自の稀有なデータといえるでしょう。
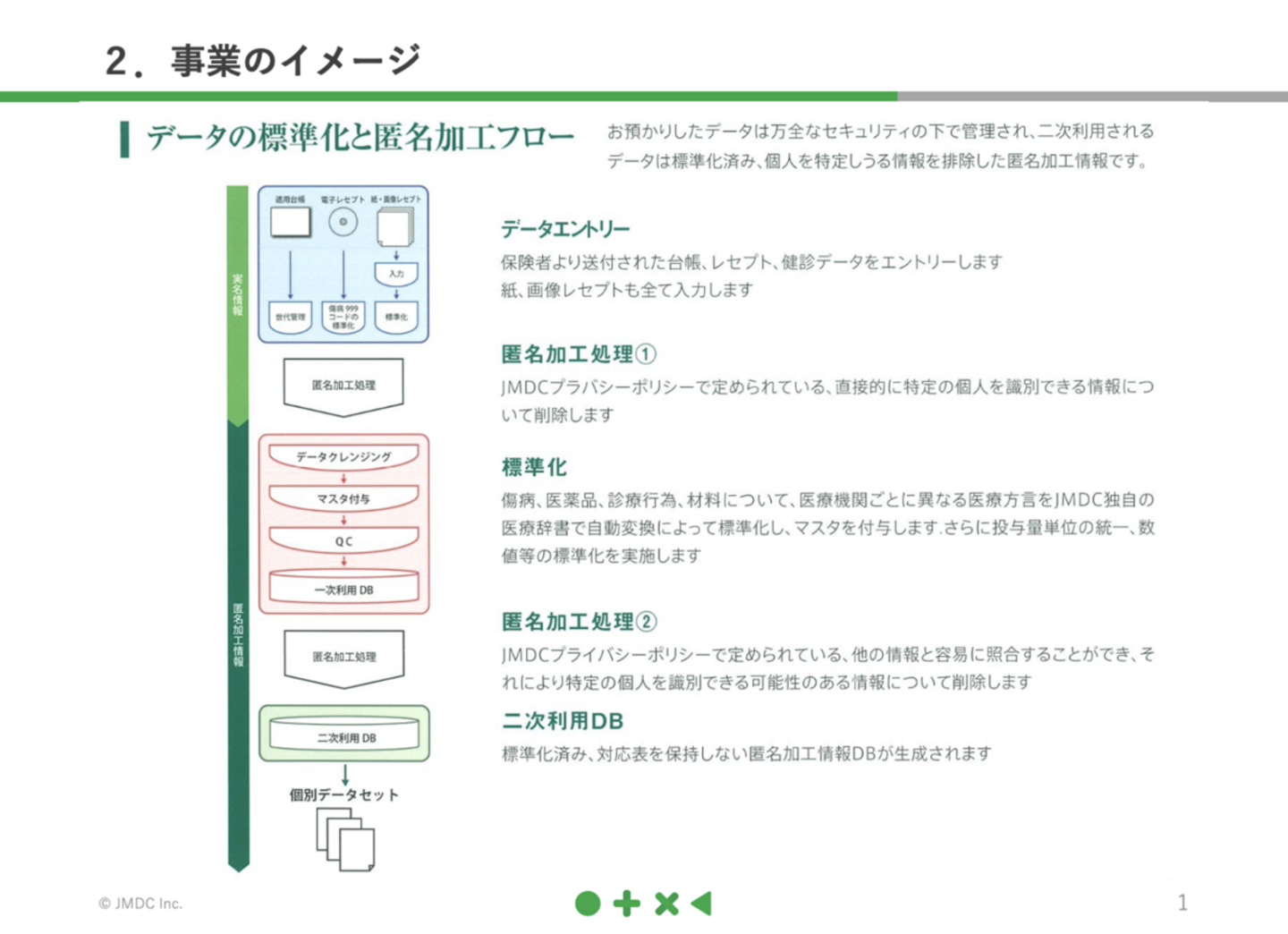
データ取込からデータベース化までの流れ
では、保険者データを取り込んでからデータベース化するまで、どんな工程を経ているのか一連の流れをご説明しましょう。
(1)レセプト取込システムで、診療報酬請求に紐づくデータとそれ以外の履歴データを見分けて、前者のデータを取り込む
(2)カラム単位でクレンジングを行う
(3)個人情報の匿名化処理
(4)名寄せ
(5)データベースへ集積
(2)のカラム単位のクレンジングでは、表記の揺れを防止しています。1と1.0のような同じ意味でも集計すると別々のレコードに分かれてしまう表記をルールに沿って統一しています。
(4)の名寄せは、表現のブレを1つに統一する処理を指します。例えば風邪ひとつとってもレセプトによってはカゼ、感冒など同じ傷病でも別の名前で記載されていることがあります。こうした場合、1つの表現に統一します。
名寄せは、複数表記のある文字パターンを蓄積した辞書データを使って、自動処理しているのですが、中にはそのパターンからはじかれてしまう情報が日々出てきます。それらをどの表記で判断するのかは、社内の医療事務経験者の専門チームがチェックし対応しています。
レセプトデータは、国内各所の医療機関から集まっているデータですので、さまざまなパターンが存在します。中には、システムが想定していない異例のパターンが出て、異常が発生する場合もまれにあります。
その場合、対象のレセプトが1件だとしてもしっかり調査をする必要があります。レセプトから読み取れる情報で仮説を立て、社内の有識者(JMDCには医師、薬剤師など専門知識を持つ方々が在籍)から知見を集め、異例なパターンを網羅したシステムへ改修します。
こうしたデータ調査をもとに処理を改善することで、以前より質の高いデータを後続のサービスへ届けられるようになるのです。基幹システムのエンジニアとしては、自分たちの責任を果たせたとやりがいを感じる部分でもありますね。
保険者データベースの後続サービスとしては、主なものに保険者支援向けのWebツール「らくらく健助」や、健康増進のための各種通知メニューがあります。そのほか、健保加入者が使う健康管理サービス「Pep Up」上のお薬手帳にデータが反映されています。
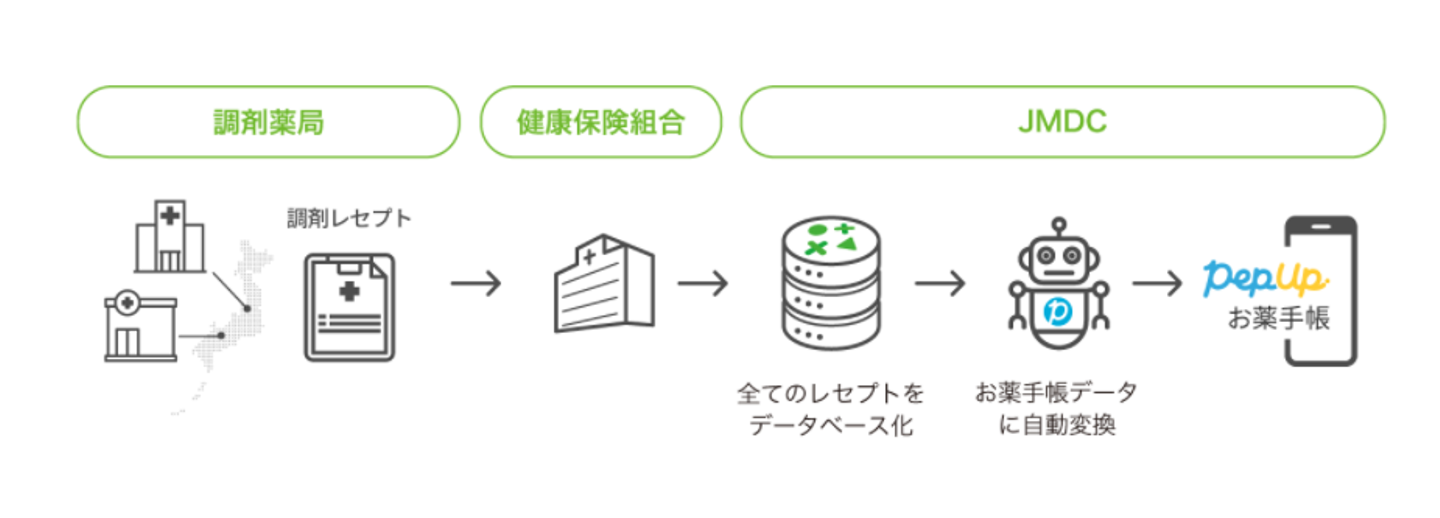
「疑わしきは表に出さない」個人情報の徹底管理
保険者データを取り扱ううえで、どんな意識や知見が必要になるのか。また、データ処理に関して、どんな技術を使っているのか。ここでは、データの扱い方についてお伝えしていきます。
「医療データというと、医療の専門知識が必要になるのでは?」と聞かれることがあります。それに対して私は「実は、それほど特別な知識は必要ないですよ」とお答えしています。皆さん、病気やケガで病院に行って治療を受けたことがありますよね。保険証を使ったことがない人もほとんどいないと思います。
レセプトデータに関しては、身近な情報がベースになるため、イメージがわきやすいものが多いです。もし理解が難しかったり、判断に迷う場合は、社内に在籍する医師、薬剤師、医療事務、検査技師など専門家の力を借りて、解決に導いています。
私たちが心掛けているのは、あるべき姿をデータベース化するために、医療の現場・現実に則した処理を作ることです。システム開発では、上記の専門家たちと連携しながら、現場の意見と現場を表すデータの双方を確認できるので、業務を通して少しずつ医療データへの知見を広げることができます。
どんな個人情報も見逃さない
私たちがデータを取り扱う中で最も注意しているのは、個人情報の取り扱いです。「疑わしきは絶対に表に出さない」をモットーに徹底管理しています。
個人情報は、氏名や生年月日以外だけにとどまりません。レセプトには薬剤師の免許証番号や、コメント欄に「〇〇先生(医師の名前)の指示のもと処方」と記載されているケースもあります。このような情報は除去する、もしくは暗号化処理を施す必要があります。各項目を神経を尖らせてチェックするのは、骨が折れる作業ですが見落としがあってはなりません。責任感を持ちながら向き合っています。
また、データ管理に関して、以下のような厳重に取り扱うための体制を構築しています。
■個人情報を扱う専用ルームの設置・・・普段のワークスペースとは別に、個人情報を扱う作業の専用ルームを設置しています。本番環境のデータベースにはこの部屋からしか接続できません。
■物理的な遮断環境・・・データを外に一切持ち出せないように、外部媒体が刺さらなかったり、本番環境以外のネットワークへ繋がらないようにしています。
ただし、調査結果を外部に報告する際に基盤となる集計データ(個人情報に当たらない部分)が必要になる場合があります。システムのパラメーターなど本番環境上のものを持ち出すときは、必ず管理者の承認を得るというフローを設けています。
独自の匿名化技術による暗号化処理
次に、データ処理技術にはどんな特色があるのかをお伝えします。JMDCの独自技術といえば、2008年頃に開発した不可逆的匿名化技術による高度暗号化処理(MediC-4)が筆頭に挙げられます。
MediC-4は、以下のように患者の個人情報を数字とアルファベットを含む記号に変換する処理です。
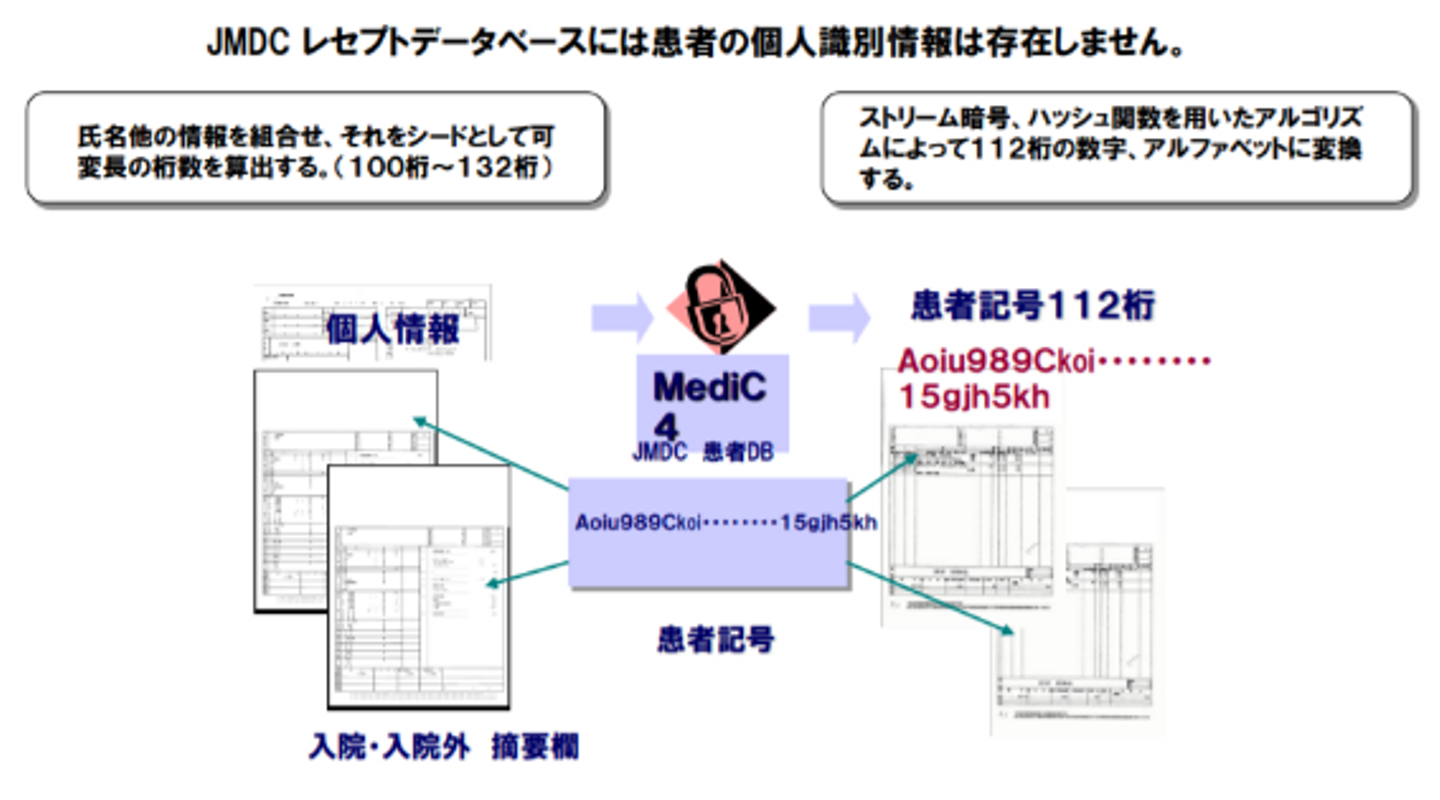
この処理は、個人情報が識別できないようにするだけではありません。同じ患者さんには同じ記号を振り分けています。そうすることで、もしある患者さんが病院を移ったとしても患者記号を軸にデータを連結すれば、どんな医療変遷をたどっているのか時系列で追跡することができます。
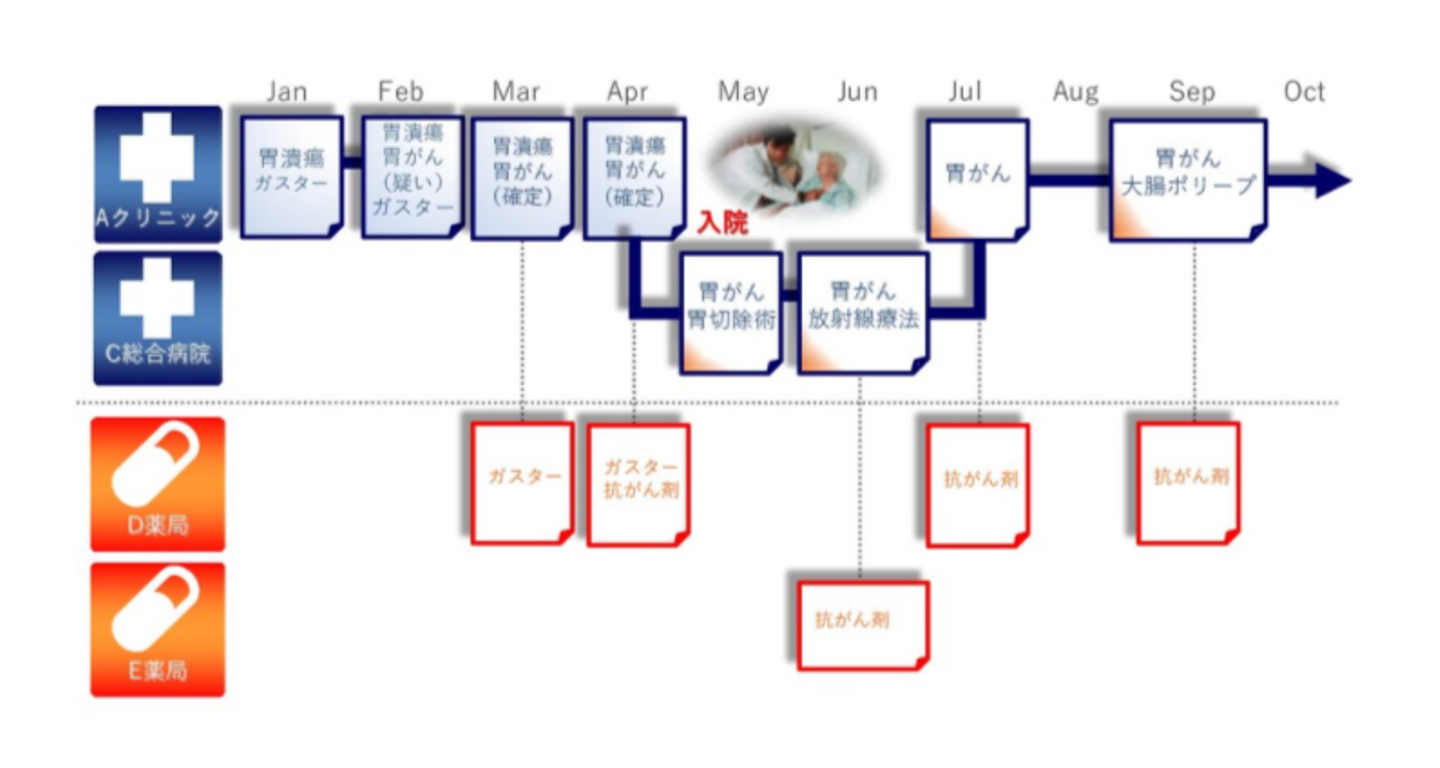
基幹システムエンジニアの成長ポイント
ここまでは主にデータに焦点を当てて解説しました。ここでは、医療データを扱う基幹システムエンジニアがどのような仕事をしているのか、また開発業務を通してどのような成長が見込めるのか、私がマネージャーを務める保険者基盤グループを例にお話したいと思います。
結論から申し上げると、私は「フルスタックエンジニアが育つ環境」として、とても理想的な環境だと思っています。
理由の一つは、担当範囲が非常に幅広いということ。当グループのエンジニアは、下記の流れで1チームでプロジェクトを進めています。
・データと技術目線で目標に向かってスキームをイメージする。
・プロジェクトに関わるデータの専門的視点を得る。
・プロダクトエンジニアとE/Uに有効なデータ構成を確認しながら、自分のイメージが正しいのか・間違っているのか確認と補正を繰り返す。
・巨大な基幹システムの一部として製品を具体化する。
・リリース後の運用・保守をする。
自社サービスを扱っているというのもあり、かなり幅広い範囲をカバーし対応しています。SIerのシステム開発業務ではなかなか経験できないシーンも多いかと思います。

また、JMDCは著しい成長フェーズにあり、取り扱うデータの種類や量も増え続けています。こうした急激な成長に合わせてシステムの維持と拡張するため、社内では新規システム導入や既存システムのリプレイス案件が常時複数進行しています。
このような大きなプロジェクトを経験すると、必然的にフルスタックな技術者として成長できる可能性が高くなります。(※大型リプレイス事例については、こちらの記事をご参照ください→「 医療機関データのオンプレ → クラウド移行にかけた1年と、6倍の効率化について」)
社内には上記のような環境で育ってきた経験豊富な先輩方がたくさんいます。彼らと一緒にさまざまなプロジェクトを経験することで、フルスタックエンジニアの動き方の基礎を学べるでしょう。
また、データ処理技術を高めていく中でも技術的な成長が加速すると思っています。私たちは膨大なデータを集めて分析結果を集計している関係上、どうしても重い処理が発生します。そこを効率的に動作するよう調整するパフォーマンスチューニングもエンジニアの重要な仕事です。
JMDCでは、パフォーマンスの優れた高額データベースを導入していますが、それでも1プロジェクトあたり、1個はうんともすんとも進まない処理が出てくることもあります。パフォーマンスチューニングを続けることで、身につく技術的な知見やスキルは計り知れません。
最後になりますが、私自身、もともと医療分野に詳しくなく、特別に興味を抱いていたわけではありませんでした。しかし、JMDCが掲げるビジョンや、これからやっていきたいことを聞いて、とてもワクワクして入社を決めたのを覚えています
実際に入社して思うのは、JMDCはエンジニアとして自らが挑戦していきたい技術に対して、惜しみなく後押ししてくれる会社だということ。その技術が事業の方向性と一致していて、よリパフォーマンス向上につながるのであれば、プロジェクトでの役割やアーキテクチャの既成概念にとらわれず、チャンスを作ってくれる度量の広さがあります。
技術的な挑戦へ向けて、最初の一歩を踏み出しやすい環境だからこそ、意思があればできることはたくさんあると日々感じています。
最後までご覧いただきありがとうございました。
もし少しでも弊社にご興味をお持ちいただけましたら、こちらの採用ピッチ資料に詳しいことが記載してありますので、ぜひ一度ご覧ください。
https://drive.google.com/file/d/1nU_SwoUiGUvb7ZhPASNsjen1Xpp9GocP/view
/assets/images/3485660/original/7e9d9ae4-8a1b-47b2-997c-a55b56537adc?1550113603)


/assets/images/3485660/original/7e9d9ae4-8a1b-47b2-997c-a55b56537adc?1550113603)
/assets/images/3485660/original/7e9d9ae4-8a1b-47b2-997c-a55b56537adc?1550113603)


