

Amazon Kinesis Data Firehose Data Delivery
Describes data delivery for Amazon Kinesis Data Firehose.
https://docs.aws.amazon.com/firehose/latest/dev/basic-deliver.html
こんにちは、那須です。
過去に何度かElasticsearchの運用関連の記事を書きましたが、今回はElasticsearchにデータを入れたいのにいろんな事情があって入れられず困っていたことと、それを解決するまでの流れを共有します。
私の所属するdotDではonedogという愛犬の健康管理ができるモバイルアプリを提供しています。このonedogから位置情報がAWS環境に送られてくるのですが、この位置情報を時々Elasticsearchに保存できないといった事象が発生していました。
具体的には、status code: 429でes_rejected_execution_exceptionというエラー(以降、429エラー)が発生していて、Writeキューがいっぱいになってこれ以上Elasticsearchで処理できない(書き込み拒否)という状況になっていました。最初はごく稀に発生していたのですが、2021年6月になると週に1回見るようになってきました。
このまま放っておくと大規模なデータ欠落が発生してしまうと思いました。そうなるとユーザの皆様にお届けできるサービスの価値が下がってしまいます。そうなる前にこれを解決しようと考えました。
429エラーの原因はWriteキューからリクエストが溢れることなので、単純にElasticsearchへのリクエストを減らすか、リクエスト数をうまく分散させて特定の時間に集中させないことが重要です。それが簡単にできれば良かったのですが、現実はそう甘くはありませんでした。
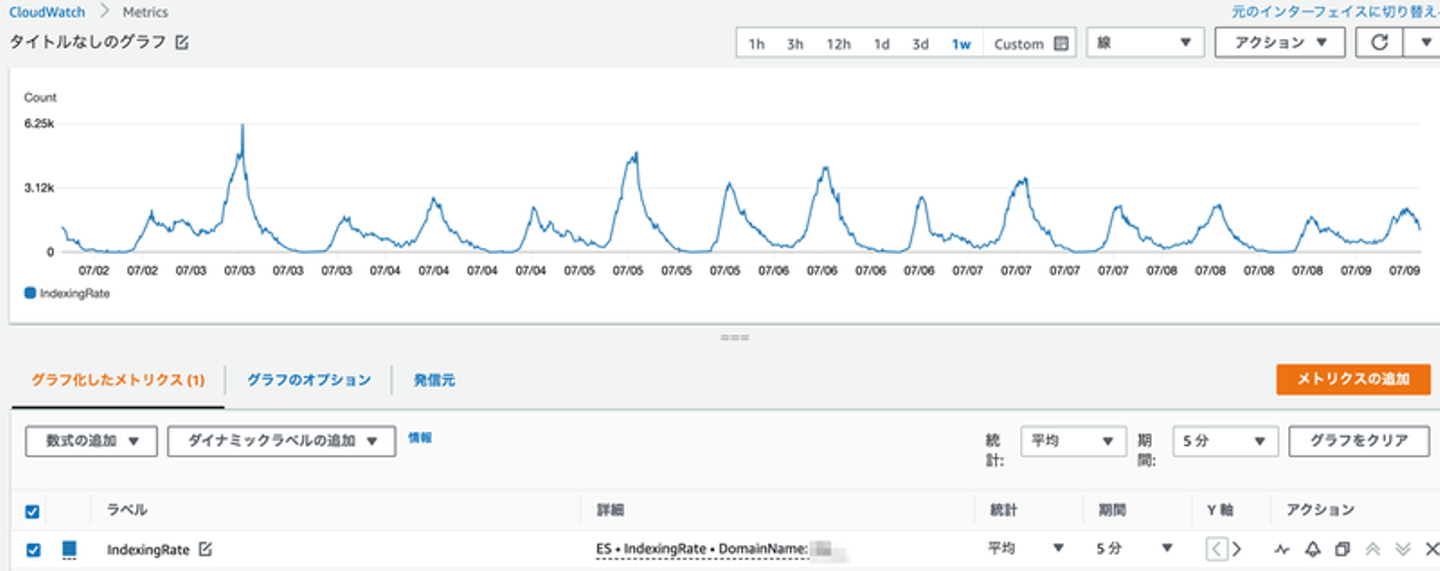
以下のCloudWatchの画面は1週間分のElasticsearchのIndexingRateのメトリクスです。ご覧の通り、1日に2回のピークがあります。必ずではないのですが、このピーク時間帯に429エラーが発生していました。
そしてElasticsearchへのデータ送信は、Lambda関数から_bulkリクエストを送る形で実装していました。ユーザからの位置情報保存のアクセスが発生するたびに_bulkリクエストがElasticsearchに送られている形です。ピーク時間帯にはこの_bulkリクエストが集中して発生してしまい、その結果429エラーが時々発生していたというわけです。
リクエストさえ集中しなければいいのですが、以下の要件があって単純に解決できない状況でした。
アプリのある機能を提供するために、位置情報はすぐに検索できる必要がありました。なので位置情報保存のAPIアクセスがあれば、すぐにLambda経由で都度_bulkリクエストを送信していたという背景があります。
またElasticsearchを運用されている方であればわかると思うのですが、データを保存してもrefreshと呼ばれる処理が実行されるまでは新たに保存されたデータは検索対象になりません。ただ、リクエストごとにrefreshするのはElasticsearchに負荷がかかります。負荷が上がると429エラーが発生する可能性が高くります。ですので、refresh動作についてはrefresh_intervalで設定した時間毎にしています。この時点で既にリアルタイムではなくなってますが、現状は仕方ありません。
一方、Elasticsearchへのデータ送信のベストプラクティスはいくつかあって、AWSのSAの方に相談するとKinesis Data Firehoseを使って送信するのがいいと伺いました。ただ、Kinesis Data Firehoseを使ってみようと思ってドキュメントを読み進めていくうちに、以下の文言にひっかかりました。
最短でバッファに1MB溜まるか60秒待ってからElasticsearchに送信されるので、残念ながら要件を満たすことができません。設定も簡単なので利用したいけど、ちょっと利用できないなぁという状態です。
AWSから以下のページが公開されているのは知っていました。
リトライ処理自体が最初はなかったので、まずは数秒待ってからリトライするよう実装しました。そうすると、リトライすることで位置情報のデータは問題なくElasticsearchに送信されたのですが、Lambda関数の実行時間がその分長くなってしまいました。またリトライの数に比例してElasticsearchへの負荷も上がったように見えました。これは悪手だなと思いました。
AWSからはエクスポネンシャルバックオフアルゴリズムでリトライすることが推奨されていますが、この方法でもLambda関数の実行時間が長くなってしまいます。実際に1回目のリトライでも429エラーが返ってきたことがありますので、その場合はさらに実行時間が伸びます。
ピーク時間帯以外はすぐにデータ送信して、ピーク時間帯は429エラーが発生しても何度もリトライするけどLambda関数の実行時間は可能な限り短くしたい。そういうやり方がないか考えた結果、以下のようになりました。
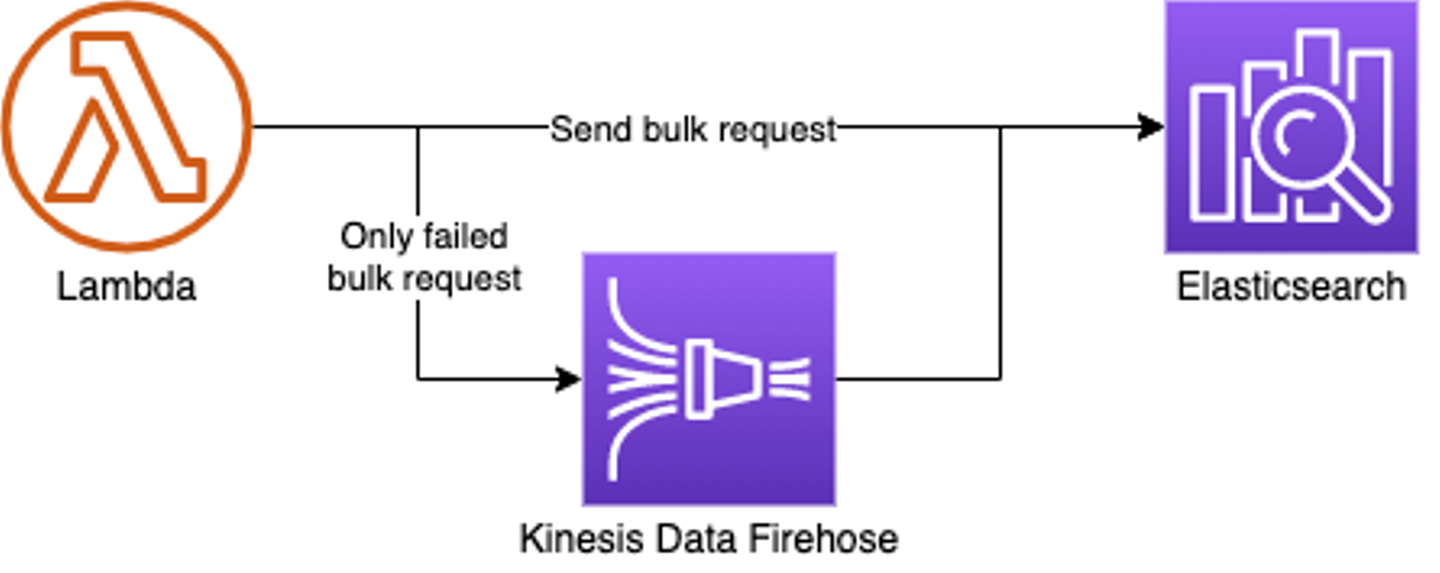
なぜすぐに思いつかなかったのか不思議なんですが、このようにエラー発生時のみ非同期処理にすればいいことに気がつきました。正常時はLambda関数から直接_bulkリクエストを送り、429エラー発生時のみKinesis Data Firehose経由でデータを送ることにしました。
こうすることで、ピーク時間帯に429エラーが発生するとリアルタイムで保存と検索ができない(60秒以内だが待たないといけない)データが出てくるのですが、ほとんどのデータはほぼリアルタイムで利用することができます。また、何度もしつこく_bulkリクエストを送ることがなくなるのでElasticsearchへの負荷も下がります。そして負荷が下がるので429エラーの発生頻度も減少する、といった好循環が生まれました。
そしてKinesis Data Firehoseは最大2時間の間、リトライを試してくれます。Lambdaだと最長の15分までしかリトライすることができませんので、これでほぼ確実にデータを欠落することなく保存することができるようになりました。
Python3で実際に実装したLambda関数の内容を一部抜粋してご紹介します。Kinesis Data Firehoseにデータ送信する関数を作成して、それにデータのリストを渡しているだけの単純なものです。Kinesis Data Firehoseを作成するCloudFormationやCDKのテンプレートも作って紹介したかったのですが、思いのほかテンプレート作成に時間がかかりそうだったので、残念ですが今回は手作業で対応しました。
from elasticsearch import helpers
import boto3
import json
try:
helpers.bulk(connection, data)
except helpers.BulkIndexError as bulk_index_error:
retry_list = []
error_list = []
for error in bulk_index_error.errors:
if error.get('index').get('status') == 429:
retry_list.append(error.get('index').get('data'))
else:
error_list.append(error)
if retry_list:
data_retry = (
r for r in retry_list
)
logger.info('Retry send request using Kinesis Data Firehose.')
try:
response = send_to_firehose(data_retry)
except:
logger.error('Failed to send data to Kinesis Data Firehose.')
if error_list:
logger.error(f'Error occurred other than status 429: {error_list}')
def send_to_firehose(data_list):
records = []
client = boto3.client('firehose')
for data in data_list:
data_dict = {
'Data': json.dumps(data) + '\n'
}
records.append(data_dict)
logger.debug(f'Data sent to Kinesis Data Firehose : {records}')
response = client.put_record_batch(
DeliveryStreamName=stream_name,
Records=records
)
logger.debug(f'Data received from Kinesis Data Firehose : {response}')
return responsefrom elasticsearch import helpers
import boto3
import json
try:
helpers.bulk(connection, data)
except helpers.BulkIndexError as bulk_index_error:
retry_list = []
error_list = []
for error in bulk_index_error.errors:
if error.get('index').get('status') == 429:
retry_list.append(error.get('index').get('data'))
else:
error_list.append(error)
if retry_list:
data_retry = (
r for r in retry_list
)
logger.info('Retry send request using Kinesis Data Firehose.')
try:
response = send_to_firehose(data_retry)
except:
logger.error('Failed to send data to Kinesis Data Firehose.')
if error_list:
logger.error(f'Error occurred other than status 429: {error_list}')
def send_to_firehose(data_list):
records = []
client = boto3.client('firehose')
for data in data_list:
data_dict = {
'Data': json.dumps(data) + '\n'
}
records.append(data_dict)
logger.debug(f'Data sent to Kinesis Data Firehose : {records}')
response = client.put_record_batch(
DeliveryStreamName=stream_name,
Records=records
)
logger.debug(f'Data received from Kinesis Data Firehose : {response}')
return responseElasticsearchへのデータ送信でエラー発生時に非同期でリトライする処理を思いつくまでの流れをご紹介しました。もっとスマートなやり方があるような気がしていますが、問題は解決できたのでひとまずこれで運用しています。もし「こうすればいいんじゃない?」といったツッコミがあればぜひお願いします!
…というような流れで様々な改善活動を少人数で行っていますが、正直エンジニアが少なすぎて思うように進んでいません。副業で関わる形でも大丈夫ですので、少しでも興味がある方は連絡いただけるとめちゃくちゃ嬉しいです!Wantedlyのリンクはインフラエンジニアですが、他の職種も大募集していますので気軽に連絡ください!
/assets/images/4296662/original/b80b4f68-ec9e-4cdc-9859-c9bcb75aa27f?1574232535)


/assets/images/4296662/original/b80b4f68-ec9e-4cdc-9859-c9bcb75aa27f?1574232535)

![]()

/assets/images/8864511/original/b80b4f68-ec9e-4cdc-9859-c9bcb75aa27f?1644990968)

