こんにちは。データプラットフォームチームのボーノです。
GPT関連のアップデートが凄まじく、キャッチアップが大変ですよね。
今回は、特にホットな LangChain についてキャッチアップするべく、これを使ってAIに「Wikiすごろく」をさせて遊んでみました。
LangChainについて LangChainについては、今回キャッチアップできたのは全体のほんの一部なので、全体の解説は詳しい解説記事等をご参照ください。
一応、 公式DocのIntroduction の序文の訳を置いておきます。(Translated by GPT-4)
LangChainは、言語モデルによって動作するアプリケーションを開発するためのフレームワークです。これにより、以下のようなアプリケーションを可能にします:
データ認識:言語モデルを他のデータソースに接続する エージェンティック:言語モデルがその環境と対話することを可能にする LangChainの主な価値提案は以下の通りです:
コンポーネント:言語モデルを操作するための抽象化と、各抽象化の実装集合。コンポーネントはモジュラーで使いやすく、LangChainフレームワークの他の部分を使用しているかどうかに関係なく使用できます 既製のチェーン:特定の高度なタスクを達成するためのコンポーネントの構造化された組み立て 既製のチェーンは、始めるのが簡単です。より複雑なアプリケーションやニュアンスのあるユースケースの場合、コンポーネントは既存のチェーンをカスタマイズしたり、新しいものを作成したりするのが簡単です。
また、今回はこちらの記事をかなり参考にさせていただきました。
Wikiすごろくとは 「Wikiすごろく」または「Wikiしりとり」をご存知でしょうか?
スタートの記事とゴールの記事を決め、スタートの記事から Wikipedia 内のリンクを辿っていき、ゴールの記事までたどり着けるか?というゲームです。
こちらの記事 から説明を引用しますと、
ゲームの目的は、ランダムで出題される2つの言葉を、Wikipediaのページ内リンクを使って結びつけること。例えばスタートが「生命表」、ゴールが「大気汚染」だったら――「生命表 → 生態学 → オゾン層 → 国立環境研究所 → 地球環境問題 → 大気汚染」と、こんな感じでリンクをたどっていき、最終的に「大気汚染」までたどり着くことができればクリア。 というものです。
これを、Embeddingを使って「ゴールに近そうな単語でジャンプさせていく」ことで、AIにプレイさせられないか、試してみようと思います。
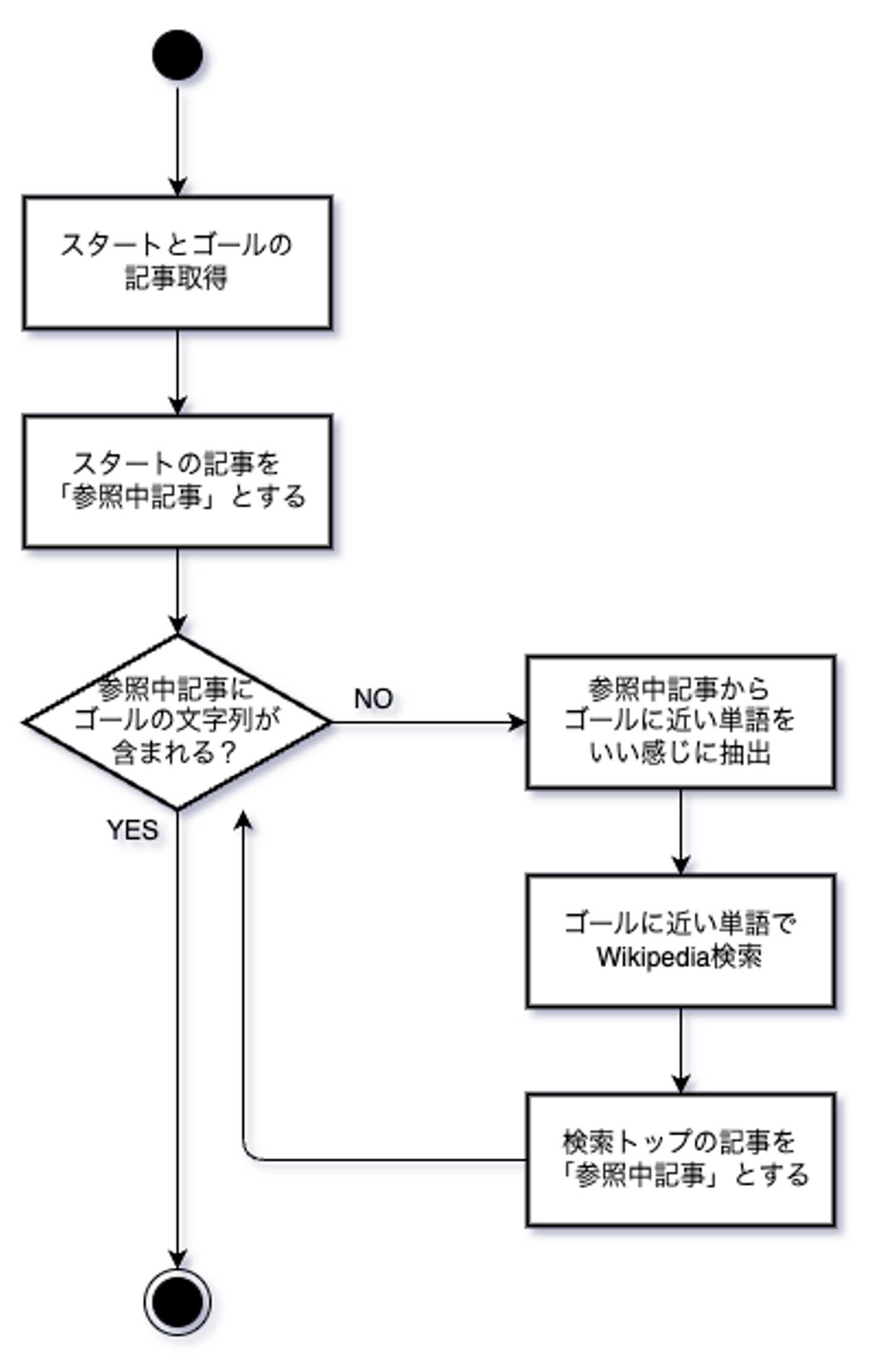
今回のスコープ 処理フロー 細かい終了条件等を除けば、だいたいこんな感じのイメージです。
頑張らないこと 今回はあくまでLangChainの練習なので、下記のような点は妥協しています。
実際に人間がプレイしても同じルートが辿れるか?という保証 探索のアルゴリズム:ゴールに必ず辿り着けるような工夫や、最短で辿り着けるような工夫 環境構築 ライブラリ群 LangChainの他に、 OpenAI のチャットモデルとEmbeddingを使用します。 openai[embeddings] LangChainからWikipediaへアクセスするために wikipedia パッケージが必要です。 tiktoken をトークナイザーの内部で利用しているようなので、入れます。 ログ出力用に loguru を使います。 私は poetry をよく使っているので、下記のコマンドでインストールしました。
poetry add langchain openai [ embeddings ] tiktoken wikipedia loguru
環境変数 OpenAIのAPI Keyが必要です。(取得方法は「OpenAI API key 取得」等でググればすぐに出てきます。)
環境変数にOpenAIのAPI Keyを OPENAI_API_KEY という名前で設定してください。
私はdirenvをよく使っているので、 direnv edit . で下記のように記載しました。
export OPENAI_API_KEY=sk-... 実装 全体のソースコードはこんな感じです。
import argparse from langchain import PromptTemplate , OpenAI from langchain . document_loaders import WikipediaLoader from langchain . embeddings import OpenAIEmbeddings from langchain . output_parsers import CommaSeparatedListOutputParser from loguru import logger from openai . embeddings_utils import cosine_similarity WIKIPEDIA_CONTENT_CHARS_MAX = 10000 WORD_EXTRACT_SENTENCE_LENGTH = 1000 MAX_LOOP = 10 class WikipediaArticleNotFoundException ( Exception ) : pass def get_document ( q : str ) - > str : logger . info ( f"getting { q } Wikipedia article..." ) loader = WikipediaLoader ( query = q , lang = "ja" , load_max_docs = 1 , doc_content_chars_max = WIKIPEDIA_CONTENT_CHARS_MAX ) loaded = loader . load ( ) if loaded is None : raise WikipediaArticleNotFoundException ( q ) if len ( loaded ) == 0 : raise WikipediaArticleNotFoundException ( q ) content = loaded [ 0 ] . page_content if len ( content ) == 0 : raise WikipediaArticleNotFoundException ( q ) logger . info ( f"loaded { q } Wikipedia article" ) return content def embed_text ( content : str ) : embeddings = OpenAIEmbeddings ( ) embedded = embeddings . embed_query ( content ) return embedded def extract_closest_text ( from_text : str , to_text : str ) - > str : to_vector = embed_text ( to_text ) from_text_first_half = from_text [ : len ( from_text ) // 2 ] from_text_latter_half = from_text [ len ( from_text ) // 2 : ] first_half_vector = embed_text ( from_text_first_half ) latter_half_vector = embed_text ( from_text_latter_half ) first_half_similarity = cosine_similarity ( first_half_vector , to_vector ) latter_half_similarity = cosine_similarity ( latter_half_vector , to_vector ) if first_half_similarity > latter_half_similarity : if len ( from_text_first_half ) < WORD_EXTRACT_SENTENCE_LENGTH : return from_text_first_half return extract_closest_text ( from_text_first_half , to_text ) if len ( from_text_latter_half ) < WORD_EXTRACT_SENTENCE_LENGTH : return from_text_latter_half return extract_closest_text ( from_text_latter_half , to_text ) def extract_closest_words ( from_words : list [ str ] , to_text : str ) - > list [ str ] : logger . info ( f"Extracting closest word from { from_words } " ) to_vector = embed_text ( to_text ) max_similarity = - 1 max_similarity_word = None for word in from_words : logger . info ( f"embedding 「 { word } 」 ..." ) word_vector = embed_text ( word ) similarity = cosine_similarity ( word_vector , to_vector ) if max_similarity < similarity or max_similarity_word is None : try : get_document ( word ) max_similarity = similarity max_similarity_word = word except WikipediaArticleNotFoundException : logger . info ( f"no Wikipedia article found: word= { word } " ) if max_similarity_word is None : raise Exception ( f"no Wikipedia article found: word list= { from_words } " ) logger . info ( f"Closest word: { max_similarity_word } " ) return max_similarity_word def extract_words_from_text ( text : str , before_word : str ) - > list [ str ] : logger . info ( f"extracting words from 「 { text } 」" ) output_parser = CommaSeparatedListOutputParser ( ) format_instructions = output_parser . get_format_instructions ( ) template = """
以下の文章から、「{before_word}」以外の日本語の名詞(固有名詞含む)を半角カンマ区切りで30個抽出してください。
{text}
{format_instructions}
""" prompt = PromptTemplate ( template = template , input_variables = [ "before_word" , "text" ] , partial_variables = { "format_instructions" : format_instructions } ) model = OpenAI ( temperature = 0 ) output = model ( prompt . format ( text = text , before_word = before_word ) ) extracted_words = output_parser . parse ( output ) if len ( extracted_words ) == 1 : extracted_words = extracted_words [ 0 ] . split ( "," ) if len ( extracted_words ) == 1 : extracted_words = extracted_words [ 0 ] . split ( "、" ) if before_word in extracted_words : extracted_words . remove ( before_word ) return [ word for word in extracted_words if len ( word ) > 0 ] def main ( ) : parser = argparse . ArgumentParser ( ) parser . add_argument ( "start" ) parser . add_argument ( "goal" ) args = parser . parse_args ( ) start = args . start goal = args . goal goal_content = get_document ( goal ) loop_count = 0 link_list = [ start ] now_word = start while loop_count < MAX_LOOP : now_content = get_document ( now_word ) if goal in now_content : break closest_text = extract_closest_text ( now_content , goal_content ) logger . info ( f"closest part: 「 { closest_text } 」" ) extracted_words = extract_words_from_text ( closest_text , now_word ) now_word = extract_closest_words ( extracted_words , goal_content ) if now_word in link_list : logger . info ( f" { now_word } already in list. ループに入っちゃったので終了" ) break link_list . append ( now_word ) logger . info ( f" { ' -> ' . join ( link_list ) } " ) loop_count += 1 if __name__ == "__main__" : main ( )
Wikipedia記事の取得 記事の取得は下記の部分で、LangChainの WikipediaLoader を使っています。簡単ですね。
loader = WikipediaLoader ( query = q , lang = "ja" , load_max_docs = 1 , doc_content_chars_max = WIKIPEDIA_CONTENT_CHARS_MAX )
文章の埋め込み(Embedding) Embeddingについても、 OpenAIEmbeddings として利用できるようになっています。
embeddings = OpenAIEmbeddings ( ) embedded = embeddings . embed_query ( content )
文章から次に参照する単語の抽出 ここをどう実装するか迷いましたが、下記の3ステップになっています。
文章全体からゴールに近そうな箇所をざっくりと切り出し 切り出した文章から単語リストを抽出 リストの中で最もゴールに近い単語を抽出 1. 文章全体からゴールに近そうな箇所をざっくりと切り出し 文章全体からいきなり単語を抽出すると関係のない単語を拾ってきそうな気がしたので、このステップで単語を抽出する範囲を絞っています。
うまいアプローチはたくさんありそうなのですが、今回は extract_closest_text 関数内で簡単に再帰的な二分探索を行うことにしました。
from_text_first_half = from_text [ : len ( from_text ) // 2 ] from_text_latter_half = from_text [ len ( from_text ) // 2 : ]
この部分で文章全体を2つに分割して、後のコードで埋め込みベクトルのコサイン類似度がゴールに近い方を採用し、 WORD_EXTRACT_SENTENCE_LENGTH より短くなるまで再帰させています。
これにより、「ゴールに近づくような単語が含まれそうな場所」を抽出したい狙いです。
2. 切り出した文章から単語を抽出 extract_words_from_text で実行しています。
日本語の形態素解析といえば Mecab や Janome あたりが有名ですが、今回はあくまでLangChainの練習なので、単語の抽出はGPTにお任せしています。
下記の箇所で、 PromptTemplate を使ってプロンプトをテンプレート化、 CommaSeparatedListOutputParser を使って出力をリストに展開しています。
output_parser = CommaSeparatedListOutputParser ( ) format_instructions = output_parser . get_format_instructions ( ) template = """
以下の文章から、「{before_word}」以外の日本語の名詞(固有名詞含む)を半角カンマ区切りで30個抽出してください。
{text}
{format_instructions}
""" prompt = PromptTemplate ( template = template , input_variables = [ "before_word" , "text" ] , partial_variables = { "format_instructions" : format_instructions } ) model = OpenAI ( temperature = 0 ) output = model ( prompt . format ( text = text , before_word = before_word ) ) extracted_words = output_parser . parse ( output )
ただ、なぜかoutputのリストが、がカンマ(,)や読点(、)区切りの1つの文字列のみが含まれたものとして返ってくることがあったので、自分で split もかけるように微調整しています。(OutputParserの出力を安定させる方法をご存知の方は教えてほしいです🙇)
3. リストの中で最もゴールに近い単語を抽出 extract_closest_words 内で、コサイン類似度でゴールに最も近い単語を抽出しています。
(単語もテキストも関係なくEmbeddingに放り込めるのがすごく楽なのでこうしていますが、もっといいやり方があるかもしれないですね…)
やってみた 実際に遊んでみました。
ポケモン→内閣総理大臣 果たしてAIは、「ポケモン」から「内閣総理大臣」まで飛べるのか? まずは「 ポケモン 」の記事から…
closest part: 「ポケットモンスター(Pocket Monsters)は、株式会社ポケモン(発売当初は任天堂)から発売されているゲームソフトシリーズの名称。また、同作品に登場する架空の生物の総称、それらを題材にしたアニメを始めとするメディアミックス作品群を指す。略称及び欧米で展開する際の正式名称は「ポケモン(Pokémon)」。 == 概説 == ポケットモンスターの原点は、1996年2月27日に発売されたゲームボーイ用ソフト『ポケットモンスター 赤・緑』である。開発元はゲームフリーク。コンセプトメーカーにしてディレクターを務めたのは、同社代表取締役でもある田尻智。この作品が小学生を中心に、口コミから火が点き大ヒットとなり、以降も多くの続編が発売されている(詳しくは「ポケットモンスター(ゲーム)」を参照)。ゲーム本編作品だけでなく、派生作品や関連作品が数多く発売されている(詳しくはポケットモンスターの関連ゲームを参照)。 ポケモンはゲームのみならず、アニメ化、キャラクター商品化、カードゲーム、アーケードゲームと様々なメディアミックス展開がなされ、日本国外でも人気を獲得している。 ポケモン関連ゲームソフトの累計出荷数は、全世界で2017年11月時点で3億本以上、2022年3月時点で4億4000万本以上に達している。その中で、メインシリーズの累計販売本数は2016年2月時点での最新作、ニンテンドー3DS『オメガルビー・アルファサファイア』までの25」
この辺が近いらしいです。
Closest word: 田尻智
「 田尻智 」さんが抽出されました。
からの
closest part: 「に手紙を送り、今に至る二人の友情が生まれ、2号以降のイラスト担当となった。その後も仲間は次第に増えていき、それに伴って『ゲームフリーク』の内容は充実していった。また、うる星あんず(大堀康祐)と中金直彦によるミニコミ界のベストセラー『ゼビウス 1000万点への解法』の再版依頼を受け『ゲームフリーク』別冊として発行し、当時のミニコミ誌としては記録的な部数を達成している。 ゲーム雑誌を作る傍ら、様々なゲームのアイディアを考案し、セガへ企画書を持ち込んだが、実際にゲーム制作を検討してくれる人物もいたものの、持ち込んだ企画がゲームとして発売されることはなかった。そのことで田尻は「自分の手でゲームを作らなければ」と決心した。 === ライター活動 === 高専卒業後は、『ゲームフリーク』における実績や、種々のゲームコンテストで培った人脈を活かし、『ファミコン通信』(現・『ファミ通』)・『ファミリーコンピュータMagazine』・『ファミコン必勝本』などでテレビゲーム情報関連のライターとなる。 ライターとして執筆していた主な雑誌およびコーナー、コラム ファミコン通信(現・ファミ通) ビデヲゲーム通信、指鍛錬道場、ソフトウェアレビューのコラム担当。 ファミリーコンピュータMagazine アーケードゲーム紹介コーナー「ぼくたちゲーセン野郎」を担当。 ファミマガVideo(VHSソフト) 徳間書店より発売されていたゲームビデオマガジン。アーケードゲームの紹介コーナー「ぼくたちゲーセン野郎」に田尻本人がナビゲーターとして顔出しで出演していた。 GTV ナムコ究極マニュアル(VHSソフト) GTVの企画でCBSソニーより発売されていたゲームビデオマガジン。クインティの発売時にはナムコ特集号が制作発売され、田尻本人も出演してクインティのゲーム内容や制作の経緯を詳細に解説していた。GTV関連ビデオソフトでは、後に『スーパーファミコンパーフェクトビデオ '92~'93』にも出演している。 ファミコン必勝本(パックランドでつかまえて) 自身の少年時代の」
この部分を抽出。そして
Closest word: 検討
ウソでしょ。
狙ったかのように「検討」が抽出されました。
「検討」の部分はWikipediaページになっておらず、「検討」をWikipedia内で検索したときにトップにくる「 ヨロシクご検討ください 」という番組が抽出されました。(本来辿れないルートになってしまうのは今後の課題ですね。)
…
その後も辿って行って、最終的には
ポケモン -> 田尻智 -> 検討 -> 伊藤康一 -> 日本国 -> 大日本帝国憲法
というルートで「内閣総理大臣」ゴール! Wikipediaリンクで辿れないものを使うというズルはありましたが、無事たどり着けましたね。
芥川龍之介→サザンオールスターズ 2ndチャレンジ。
流れは同様なので、ズバッと省略しまして
芥川龍之介 -> 夏目漱石 -> 東京帝国大学 -> 丹下健三 -> 丹下郁太郎 -> 日本官界情報社 -> 東京府 -> 神奈川県
ここまでたどり着きました。神奈川県なのでかなり近づいている感じがします。
…が、次の単語が
Closest word: 松田断層帯
絶対違うなー。
このあと、案の定上限の10回目までにたどり着けず、
芥川龍之介 -> 夏目漱石 -> 東京帝国大学 -> 丹下健三 -> 丹下郁太郎 -> 日本官界情報社 -> 東京府 -> 神奈川県 -> 松田断層帯 -> ソマリア -> ソマリランド
となってしまいました。 クリアーならず…
(ちなみに私が「神奈川県」からやってみたところ、「神奈川県→湘南海岸→サザンオールスターズ」で、2ステップでたどり着けました。惜しい…)
全体から文章の一部を切り出すタイミングで、「湘南海岸」を含む部分を切り出せていなかったようです。
チューリップ→コウテイペンギン 3rdチャレンジ。
こちらも省略しまして…結果
チューリップ -> イスタンブールチューリップ -> ペルシャ語 -> 新ペルシア語 -> タジキスタン -> パミール高山砂漠・ツンドラ地域 -> フェドチェンコ氷河 -> 細く長く続いている氷河 -> 北緯38度46分01秒 -> 太平洋沿岸 -> ニューギニア島
ということで、10回目までにたどり着けませんでした。
(変な単語が抽出されていますが…笑)
ただ、これはまだ行ける気がしたので、延長線で「ニューギニア島→コウテイペンギン」もやってみました。
結果がこちら。
ニューギニア島 -> パプアニューギニア -> ココポ (中略) Closest word: パプアニューギニア パプアニューギニア already in list. ループに入っちゃったので終了
パプアニューギニア→ココポ→パプアニューギニア…の無限ループに入ってしまいました。
頑張って南半球にたどり着けば「南極」等から行けたかもしれませんね。
課題など 課題は主に下記あたりです。
必ずしもWikipediaの記事にある単語を拾えるとは限らないコードになっている 貪欲的な探索しか行っていないので、簡単にループに陥る 人間がこのゲームをするときに強い、「1989年」「◯◯出身の有名人一覧」等のページを使えていない より強いWikiすごろくAIを作りたい方は参考にしてみてください。
その他、
前回の単語ベクトルから次の単語ベクトルへ移動するとき、埋め込み空間上の勾配を気にする…みたいなことができると良かったかも 人間が探すときは「意味全体」というよりは「ピンポイントの共通点」で飛ぶことが多い気がするので、類似度の定義も工夫できるかもしれない などなど…色々考えられそうで、面白かったです。
まとめ 今回は LangChain についてキャッチアップするべく、LangChainを使ってAIにWikiすごろくをさせて遊んでみました。
Document LoaderやPrompt Template、Output Parserなど色々使えて良い練習になりましたし、Embeddingの使い方もなんとなく分かってよかったです。(本来は こちらの記事 のように、埋め込んだ知識をベクトルDBに取り込むことで、カスタムのQ&Aを作成する、といったことに利用する使い方が多いようです。)
遊びながら色々な知識が得られることもあるので、新しい技術は積極的に触って遊んでいきたいですね。
さいごに KiZUKAIでは、絶賛メンバー採用中です! また、お決まりですがKiZUKAIでは絶賛エンジニアメンバーも採用中です! カジュアル面談も大歓迎です。お気軽にエントリーしてください。

/assets/images/4934437/original/620a5add-6f94-4f12-a97c-34d1c83e6d2d?1587689225)


/assets/images/4934437/original/620a5add-6f94-4f12-a97c-34d1c83e6d2d?1587689225)



/assets/images/13534329/original/620a5add-6f94-4f12-a97c-34d1c83e6d2d?1686292776)


