
(この記事は2019年9月16日に弊社テックブログに掲載した内容となっております。)
こんにちは、AppBrewでアルバイトをしている@Leoです。 自然言語処理の研究室に最近入った大学生で、趣味はKaggleと競技プログラミングです。 AppBrewでは、LIPSの投稿を使ったデータ分析をしています。
今日の記事では、弊社のアプリLIPSにて投稿ジャンルを機械学習を使って自動推定した方法を紹介します。
自然言語処理・確率関係全然わからない!という人でも読みやすい内容になっていると思うので、最後まで読んでいただけると幸いです!
LIPSにおけるジャンル
最近、LIPSにジャンル機能が追加されました。 これは投稿されたクチコミにジャンルを設定できる機能です。 適切にジャンルを設定すると、投稿を検索するときにジャンルを使って絞り込めるなどの利点があります。
ジャンルは7種類(コスメ、スキンケア、ヘアケア・ヘアアレンジ、ネイル、ダイエット、恋愛、その他)のいずれかです。
(LIPSにおけるジャンル ※23年11月現在は仕様が異なっております)
ジャンル機能追加後の投稿にはユーザがジャンルを付与してくれるのですが、それ以前の投稿にはジャンルが付いていないという問題がありました。
LIPSには既存の投稿が100万件ほどあったので、古い投稿に手動でジャンルを付与するのは現実的ではありません。 そこで、ジャンルがついている最近の投稿を使って、古い投稿にも自動でジャンルを付与することにしました。
教師データの作成
機械学習用の教師データを作るために、直近2ヶ月間の投稿におけるジャンル比率を確認しました。
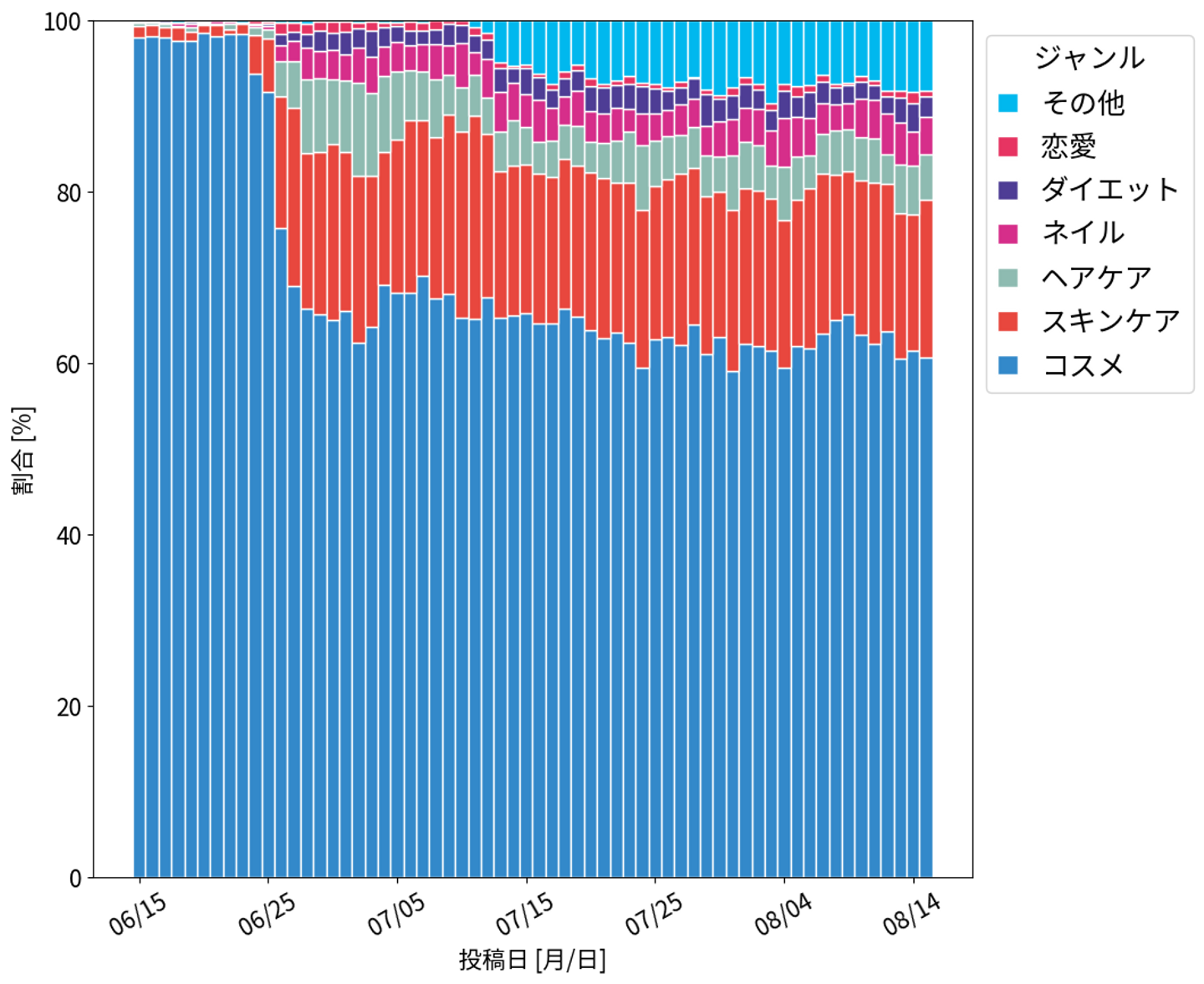
(投稿ジャンルの分布)
ジャンル機能実装前の投稿のジャンルはすべて「コスメ」になっています。
この図を見ると以下のことがわかります。
- 6月25日から「コスメ」以外のジャンルの投稿が増えている
- この頃、ジャンル機能を実装した
- 7月10日からジャンル「その他」の投稿が増えている
- この頃、ジャンル「その他」を追加した
今回は、ジャンル機能を導入し終え、アプリのアップデートが十分浸透した、7月13日以降のデータを使ってモデルを学習することにしました。
ナイーブベイズ
ジャンル推定のためのモデルとしては、ナイーブベイズという古典的な機械学習モデルを使うことにしました。
ナイーブベイズとは、ベイズの定理
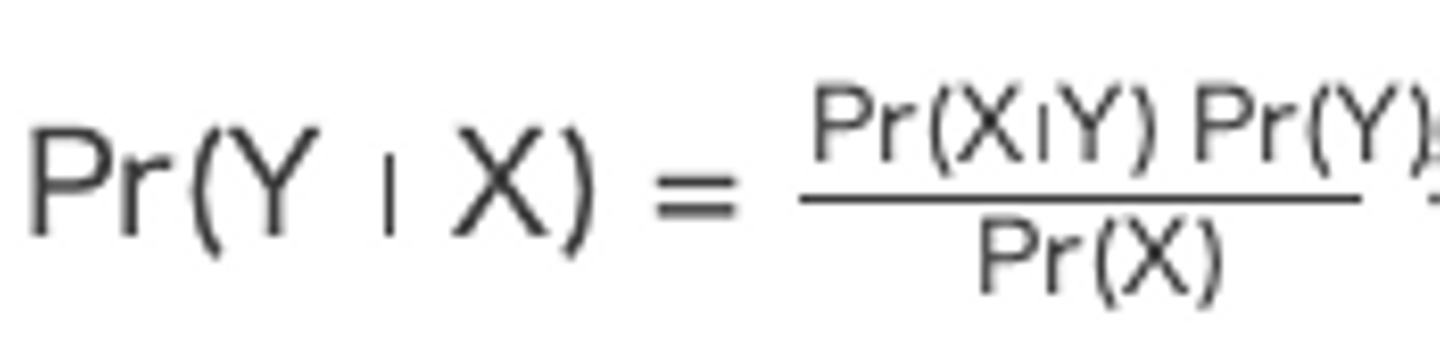
を利用した分類手法です。 仕組みがシンプルで実装が簡単で計算も軽いので、教師データを使ってテキストを分類するときにはベースラインとなるアルゴリズムです。
この節は数式多めなので、ニガテな人は次の節まで読み飛ばしちゃってください。
sklearn のアルゴリズム選択フローチャート(https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html より)
今は投稿の本文からそのジャンルを推定しようとしているので、ベイズの定理において、X を投稿の本文 content に、Y を投稿のジャンル genre に置き換えます。
この等式に現れる各項を見てみましょう。
- Pr(genre|content):ある投稿の本文が content であるとき、そのジャンルが genre である確率
- Pr(content|genre):ある投稿のジャンルが genreであるとき、その投稿本文が contentである確率
- Pr(genre):ある投稿のジャンルが genre である確率
- Pr(content):ある投稿の本文が contentである確率
今知りたいのは、ある投稿本文 content が与えられたとき、最も Pr(genre|content)が大きくなるような(= 最もそのジャンルっぽい)ジャンル genreです。
先述したように、Pr(content)は固定値なので判断に影響せず、無視しても結果はかわりません。また、Pr(genre)は学習データにおけるそのジャンルの投稿数割合で推定できます。
あとは、Pr(content|genre)さえ計算できれば、最も Pr(genre|content)が大きくなるジャンル genre を計算できます。
この値を計算するために、投稿を単語に分割します*1。 投稿本文を構成する単語をw₁,w₂,⋯,wₙ とします。 ここで、投稿本文とその本文に現れる全単語の集合を同一視します。つまり、本文にどの単語が現れたかだけを考慮し、単語の並び順や位置等を無視することにします。 すると、
Pr(content|genre)=Pr(w₁,w₂,⋯,wₙ∣genre) となります。
さらに、各単語の出現確率の独立性を仮定します(つまり、実際には一緒に使われやすい・使われにくい単語等がありますが、それを無視します)。 すると、
Pr(w₁,w₁,⋯,wₙ∣genre)=Pr(w₁,∣genre) × Pr(w₂,∣genre) ×⋯×Pr(wₙ,∣genre) となります。
Pr(wᵢ|genre)は、学習データにおけるジャンルが genre である投稿のうち、wᵢが現れるものの割合として推定できます。
こうして、学習データを使って各ジャンルの Pr(content|genre) を計算できました。
以上のように、投稿の本文からその投稿のジャンルを推定する手法がナイーブベイズです。
単語分割
ナイーブベイズを使うためには、投稿本文を単語に分割する必要があります。 英語の場合は単に単語間のスペースで区切れば済むのですが、日本語の場合は文を解析して単語の区切りを見つけなければいけません。
今回はMeCabを使って単語の区切り調べました。試しにMeCabを使ってみましょう。

しっかり「すもも」や「もも」を区切れていますね。
MeCabで使える辞書*2はいくつかありますが、LIPSを解析するには、Web上のデータを新語として日々追加してくれるNEologdが良いでしょう。
最近のNEologdを使うとYouTuberの名前も認識できるらしいです。 例えばYouTuberの「ゆきりぬ」さんに関する「今日のゆきりぬの動画で〜」という文を考えてみましょう。
「今日のゆきりぬの動画」を他の辞書(IPAdic)を使って分割すると、「ゆきりぬ」が「ゆき、り、ぬ」に分けられてしまいます。

一方NEologdを使うと「ゆきりぬ」を人名として認識してくれます。

LIPSにはコスメを紹介するYouTuberに関する投稿もあります。 そのような投稿を正しく単語に分割するためにも、今回はNEologdを使いました。
モデルの実装
実装にはscikit-learnを使いました。
CountVectorizerを使って投稿をベクトル化し、Complement Naive Bayesを使ってモデルを学習しました。
ここで使ったComplement Naive Bayes*3はナイーブベイズの亜種です。 これは今回のように、ジャンルが3つ以上ありジャンルごとのデータ量の偏りが大きいときに有効なモデルです。 実際に、素朴なナイーブベイズを使った場合と比べて予測精度が大きく改善すること*4を確認できたため、今回はこのモデルを使いました。
分類結果
LIPSに投稿された全投稿のジャンルを予測する前に、分類結果を検証しました。
今回は過去の投稿のジャンルを予想したいので、7月14日以降のデータを訓練用、7月13日のデータを検証用としました。*5
予測精度指標としては、Accuracy、Precision、Recall、F値を使いました(各指標の説明は例えばここにあります)。
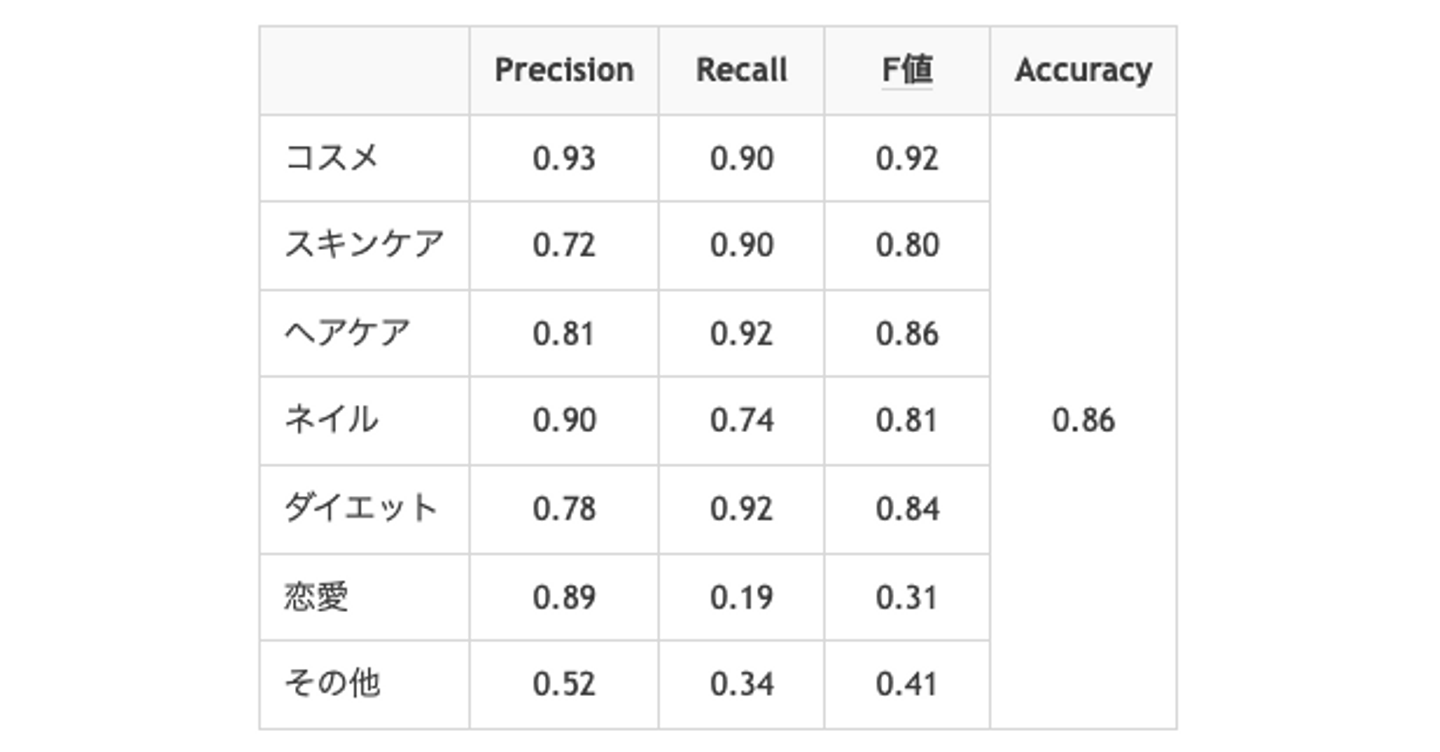
「コスメ」〜「ダイエット」ではF値が0.8を超えていて良さそうです。
結果を掘り下げるため、どのクラスをどのクラスと混同しているのかを確認してみました。
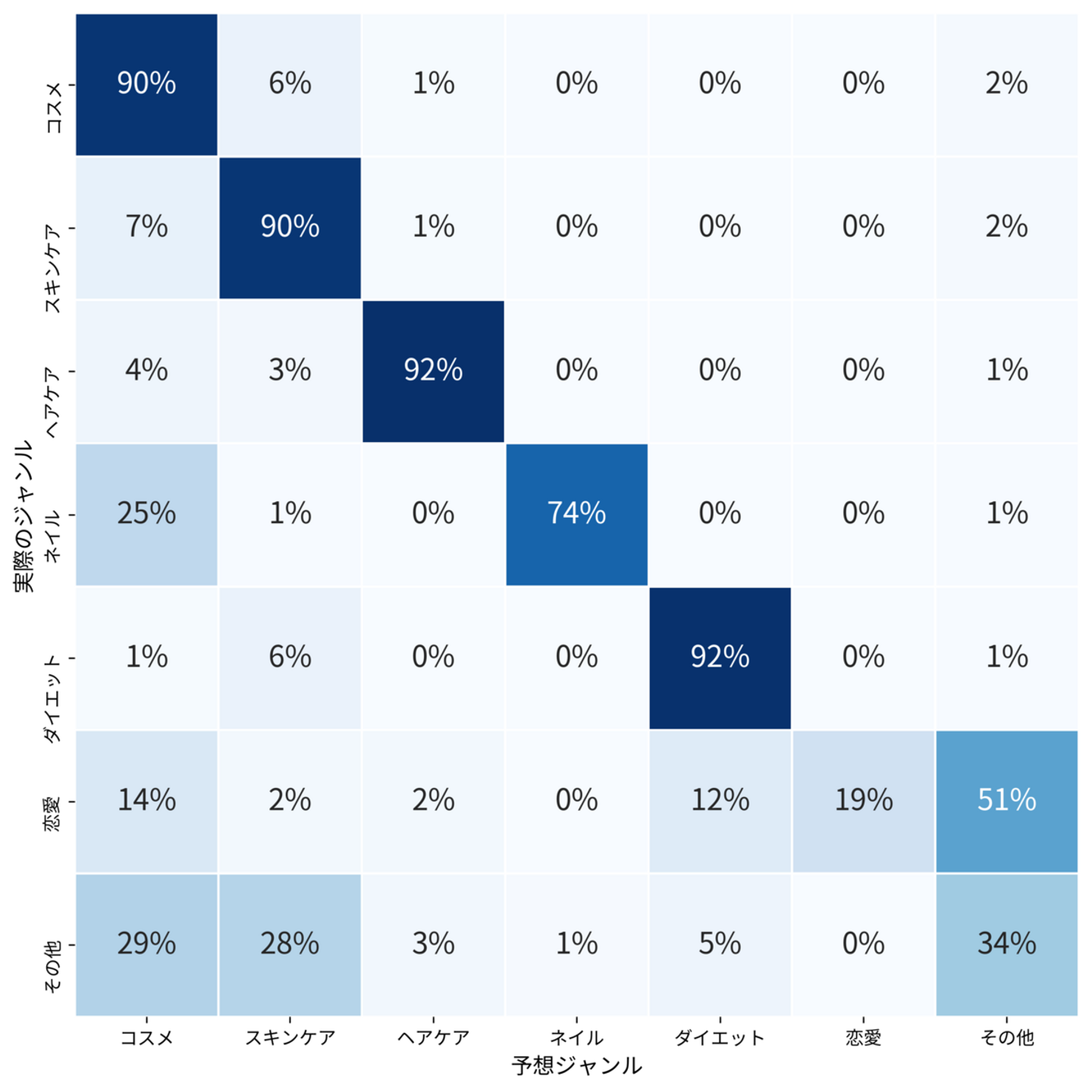
(実際のジャンルと予想したジャンル)
- 「恋愛」の投稿は1%未満しかなく、データ不足が原因で上手く分類が出来なかったようです。データが増えたら学習し直すと良いかもしれません
- 「その他」の投稿が「コスメ」や「スキンケア」に分類されることが多いようです。間違って分類された投稿を見てみると、これは「その他」の定義がフワッとしていることに起因するようでした
最後に、実際に目視で結果を確認しましたが、「コスメ」~「ダイエット」の投稿は十分な精度が出ていると言えそうでした*6。
おわりに
投稿のジャンルを推定するにあたり、Complement Naive Bayesを使うと上手くいったという話でした。ナイーブベイズは実装が簡単で計算も軽く、今回の作業は一日程度で終えられました。
最近の自然言語処理・機械学習界隈では、強くて重いモデルで殴ることが多いのですが、タスクに合った手法を選べば少ないリソースでも十分なパフォーマンスを出せることがあります。
弊社AppBrewでは現在、350万DL突破のコスメ口コミアプリ「LIPS」をはじめとした「ユーザーが熱狂するプロダクト」を、「再現性をもって開発すること」に携わるエンジニアを積極採用中です。
下記募集ページにぜひ一度、目を通してみてください!
*1 単語以外の特徴量を使うこともできます。特徴量の独立性を仮定し、ベイズの定理を使って最尤推定をする手法がナイーブベイズです
*2 形態素解析に使える辞書についてはhttps://www.wantedly.com/companies/appbrew/post_articles/874156 でアルバイトの星野さんが記事を書いてくれました
*3 Complement Naive Bayes を提案した論文:https://people.csail.mit.edu/jrennie/papers/icml03-nb.pdf
*4 sklearnの他のナイーブベイズ亜種と比べて、特にデータ量が少ないジャンルでComplement Naive Bayesは有効でした
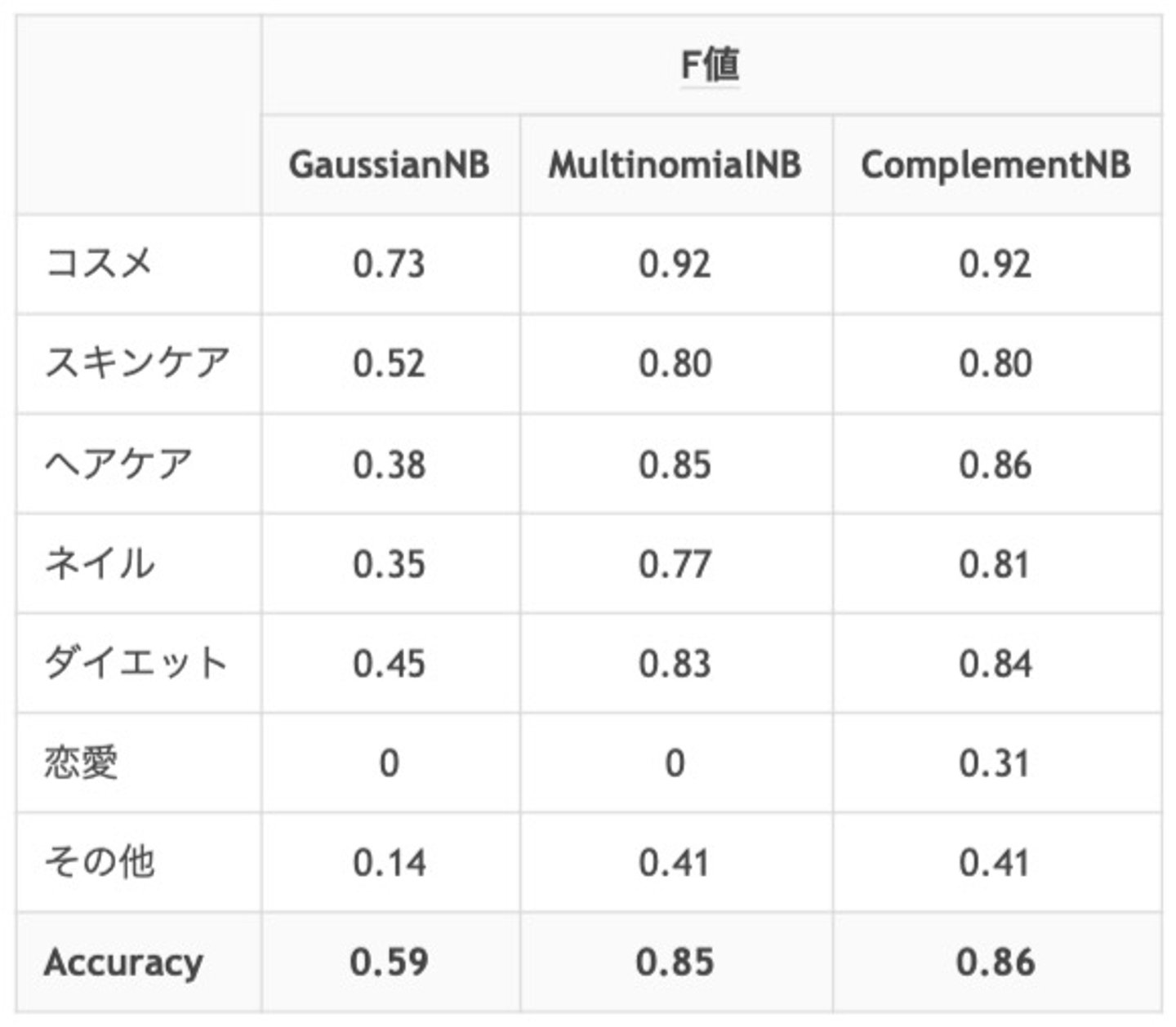
*5 学習データ: 約32000、検証データ: 約8000
*6ユーザがジャンルを付け間違えたものを、モデルが正しいジャンルに分類しているケースも散見されました
/assets/images/4901651/original/9de972b3-d882-4d9c-b24b-93fff9219963?1586959280)


/assets/images/4901651/original/9de972b3-d882-4d9c-b24b-93fff9219963?1586959280)
/assets/images/4901651/original/9de972b3-d882-4d9c-b24b-93fff9219963?1586959280)


