


開発部のbonです。
弊社では2022年の今でありながら、バックエンドのサーバーをHeroku上で運用しています。なぜ未だにHerokuなのかというと色々と理由があるとは思いますが、個人的には以下のような理由を挙げます。後半はほぼ組織体制や技術スキル的な問題ですが、概ねこんな感じだと思います。
・コンテナベースのシステムよりは現行メンバーでメンテナンスしやすい
・現状のトランザクションをさばくのに十分なキャパシティをHerokuで確保できている
・バッチ処理系やpubsubとの依存関係が強くリプレースしづらい
・移行にかかわる非機能要件やデータマイグレーション全体の流れを整理できてない
国内に置けるHerokuの運用記事や構成については2022年ではほぼ見かけなくなってしまったので、そろそろリプレースしないと技術的負債がどんどん増えていく一方で、安定稼働しているサービスを敢えてコストを掛けてリプレースするという部分でのリスクヘッジをどうするかという点が現在の課題です。
その課題を整理する目的もあわせて、今回弊社でのHerokuの構成要素を包み隠さずお伝えしようと思います。
目次
- サーバー構成
- アドオン構成
- 今後の展開
- アンケートのお願い
- メンバー募集中です
サーバー構成
まず弊社のHerokuを取り巻くサーバー構成について、Dyno(1つのサーバーの単位みたいなもの)の内訳は以下のとおりです。
APIサーバー: 1dyno(Performance-L dynos)
Jobサーバー: 1dyno(Standard-2X dynos)
pubsubサーバー: 10dyno(Standard-1X dynos)
これらのdynoを、弊社ではProcfileで管理しています。Staging環境については常時起動しているサーバーが1台のみ存在し、マニュアルデプロイを利用してそれぞれのメンバーが使いたいときにブランチを変更してデプロイする感じで対応しています。
次に各サーバーについて説明します。
APIサーバーはその名の通りフロントエンドからのAPI通信を処理するバックエンドサーバーで、Performance-Lプランを契約しています。詳しくは後述しますが、HerokuのアドオンでLibratoを利用してメトリクス監視をしており、メモリの利用量が2GBを消費することもよくあるためこのプランにしています。
JobサーバーはSidekiqを用いたバックグラウンドジョブを処理するためのサーバーです。扱うデータ量が多くなるにつれStandard-1Xでは難しくなってきたため、2Xで稼働させています。
pubsubサーバーはGoogle Cloud Pub/Subに溜まったLINEからのイベントをSubscribeするためのものです。大きなデータというよりは小さなデータを大量に処理する必要があるため、ここだけは10dyno * 8 Threds という環境で動いています。内部処理ではActiveRecordのトランザクションが実行されるため、スレッド別にコネクションが残ったままにならないよう↓のような処理を書いて対応しています。
ActiveRecord::Base.connection_pool.with_connection do
pubsub_handler.receive(received_message)
end
アドオン構成
Herokuには便利なアドオンがあり、大抵のことはそれを利用することでなんとかなります。以下は弊社で利用しているアドオンの一覧です。
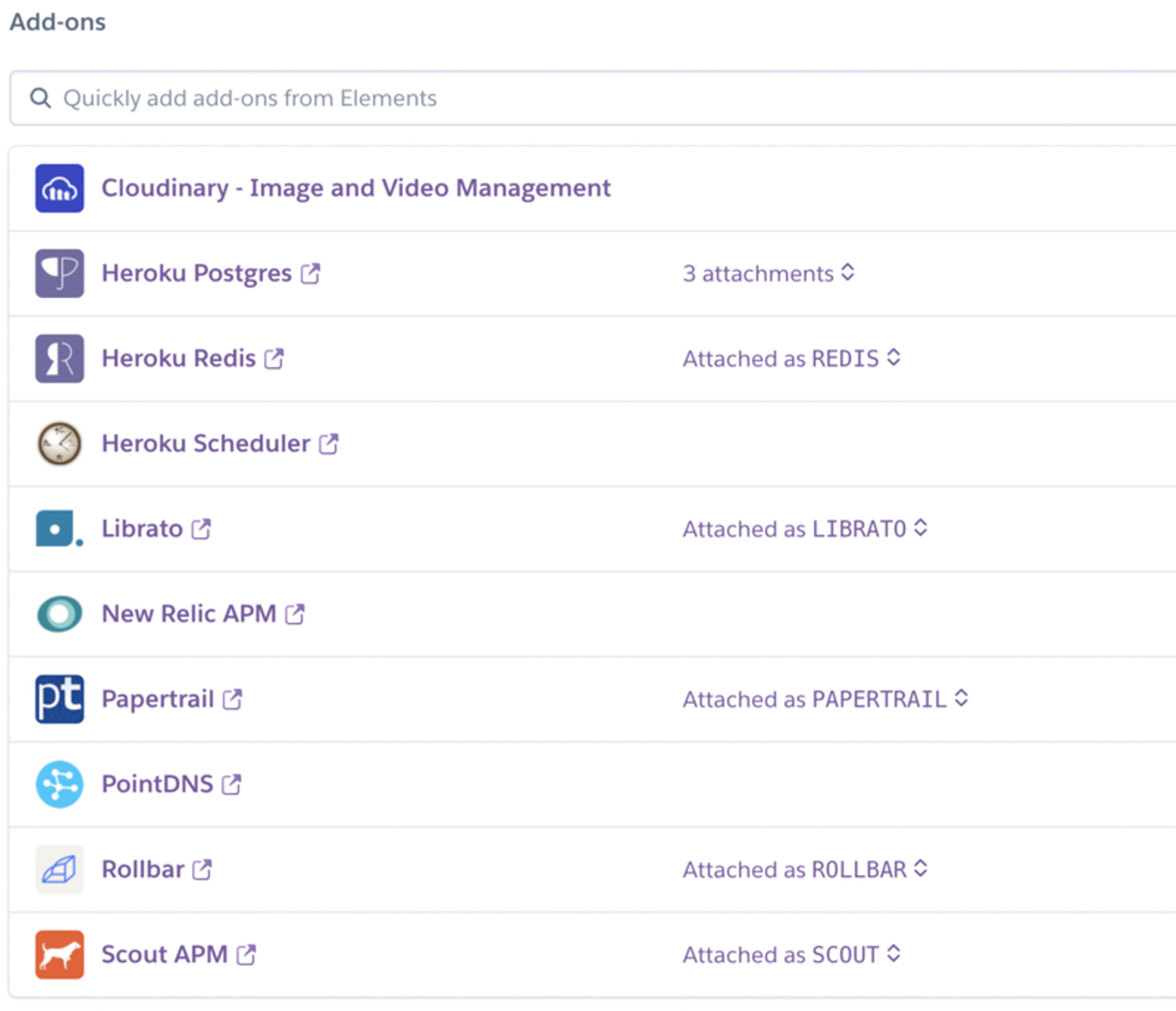
なぜかNew Relic APM、Scout APMのように重複しているパターンもあります。こちらは過去の経緯として色々と比較検証したうえでの名残です。
ということで現在利用しているものについて、どのように利用しているか説明していきます。
Cloudinary
有名な画像・動画管理ツールです。CDNにAkamaiを利用していたり画像サイズを良い感じにリサイズ・圧縮してくれたりします。メチャクチャ便利なのですが、使い方を間違えるとBandwidth(データ転送量)が意外と多くかかります。コンテンツの配信がシステム側が多い場合キャッシュが効かないことが多いので、画像そのもののファイルサイズを小さくするなり工夫が必要になります。
例えば弊社の場合、LINEのイメージマップやイメージメッセージのAPIを使用して各利用者へ画像配信することが多数を占めており、以下のように `n/a`のドメインからの参照が圧倒的に多いです。
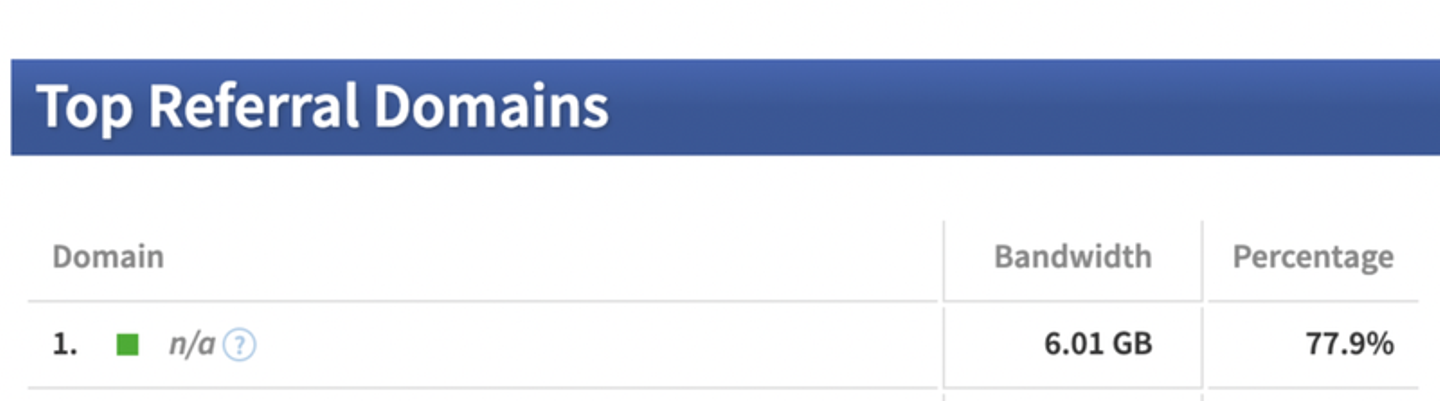
静的Webサイトのようにユーザーがシステム側へアクセスして来るパターンが多いときはCloudinaryの画像はCDNによるキャシュが有効になるため、それなりに有益です。しかしながらこのパターンではCDNキャッシュは無意味ですので、割と大きめのBandwidthを消費します。このあたりはS3やGCS側に画像を移行したほうがよさそうだと最近考えています。
Heroku Postgres
様々なHeroku上のサービスからアクセスされるRDBです。それゆえトランザクション数もデータ量もそれなりに多く、弊社ではpubsubの同時トランザクション数を考慮し、接続制限(Connection Limit)が500のPremium 3プランを利用しています。このプランはHAも有効になっており、システムメンテナンスやサービス不具合時でも基本的にはDBが落ちて問題になることはありません。そしてこのPremiumプランを選択するためにHerokuも同様にPremiumプランを選択している、という感じです。
また、ドキュメントをちゃんと読むとわかるのですが、HerokuのEnterpriseプラン以外ではこのPostgreSQLはパブリック公開されています。そのためデフォルトのユーザー名であるpostgresを使ってシステム構築&本番運用してしまうと勢いよくDDoSとブルートフォース攻撃に合うので注意してください。
Heroku Redis
Sidekiqを利用するためにジョブをキャッシュする目的で利用してます。このアドオンについてもPostgresと同じようにHeroku側のメンテナンス対応を考慮してHAのついてるプランを選択する必要があります。pubsubのコネクション数もそれなりになるため、それに合わせてPremium 2プランを現状では利用しています。
Heroku Scheduler
rakeタスクで実行している様々なcronジョブを登録しています。ジョブの成否やログの収集が若干分かりづらいですが、それらは後述するPapertrailでアラート監視しています。
また、ジョブはそれぞれdynosのプラン設定をすることができるため、比較的データ量が多かったりメモリを消費したりする処理のジョブはプランを上げています。現在では後述するPapertrailでエラー検知するようにしておき、メモリエラーが起きた際に手動でサイズを変更しています。オートスケールできるようにしたいですね。
Librato
Herokuでの log-runtime-metrics を有効にした上で、CPUやメモリ、ロードアベレージなどのログを収集してメトリクス監視しています。Herokuの他のアドオンとの相性もよく、PostgreSQL、Redisのメトリクスも特に何も工夫することなく取得することができます。
参考: https://devcenter.heroku.com/ja/articles/log-runtime-metrics
Herokuのメトリクスはある程度自動で作られるので、Redisやアラートを別途作ったくらいです。
Papertrail
herokuで出力されるログを収集しています。これがなかなか厄介で、割とすぐにログの転送量上限に達しますし、なによりログからエラーを追いづらくあまり弊社ではログ調査の目的では活用されていません。(現在他のアドオン含めて改善を検討中)
ただし、アラートの設定は正規表現で簡単にできるので、こちらはSlack連携することでかなり有意義にエラー検知ができるようになっています。
PointDNS
独自ドメインを利用するために使用しています。
Scout APM
Railsのアプリケーションパフォーマンスを監視しています。よく起きるN+1もこのアドオンによってすぐに検知することができます。また、タイムアウトエラーなどの検知時にはこちらを参考にすることもあります。特にエラー時のコンテキスト(変数に格納された値)が残っている場合があるため、エラー発生状況を確認するのもとても楽になります。
現行のScoutにはエラーモニタリングの仕組みも整っており、SentryやRollbarを使わずともAPMもエラーもまとめてモニタリングすることができるようになっています。が、HerokuのScout APMのバージョンでは対応できないとサポートから回答を得ています。残念。
上記以外のアドオン
登録はしていますが利用していません。NewRelicは現状では運用検討をしているものの、他のアドオンの組み合わせで問題ないという判断で保留となってます。Rollbarは現在Sentryを利用しているため使っていません。
Sentry(外部)
Herokuのアドオンではなく外部サービスとして利用しています。基本的にはRailsのコードにおいて、エラー発生時の処理にSentryの呼び出しを書いたり、initializerで読み込んでException発生時に自動的にSentryへエラーが送られるという一般的な対応をやっています。
運用としてはエラー発生時にSlackにも連携されるようにしており、対応内容やエラー発生時の作業フローをSentry側のエラーのActivityへ記載することで、同様のエラーが起きたときの対応を様々なメンバーがすぐに取り組めるようにしています。
とはいえまだまだエラー監視や保守運用としては見直す部分が多いと思っているので、他のアドオンや監視ツールと併せてより一層のObservabilityの確保と仕組み化を検討しているところです。
今後の展開
冒頭にて述べたとおり、 Heroku + 何か で検索すると2016年とかだいぶ古い記事が検索候補として表示されます。これは俗にいう技術的負債として捉えることもできます。
Herokuそのものに運用上の問題はないのですが、例えばObservabilityを観点に置くと、フロントエンドやBFF層を持っている弊社のアーキテクチャ構成においては、どうしてもアプリケーションログを時系列で捉えリクエストが生まれてからレスポンスが返っていくまでの状況をキレイに追うことができません。まとめると以下のような課題がまだまだ残っています。
・ コスト削減
・ 適切な性能要件の設計と実装
・ Observabilityの確保
・ セキュリティの確保
・ 昨今の技術動向に鑑みたHerokuからの脱却
具体的な施策としては、例えば今様々なアドオンの連携で成り立っている部分をDatadogやSnowflakeを入れることで一元管理できたりログ集約できたりすることもできるでしょう。弊社で使っているGCPを利用してStackdriverや一部ジョブをCloudRunへ切り出す、GKSを利用してコンテナベースオーケストレーションをやってみるなどやること・やれること・考えることはたくさんあります。
0ベースでの提案や新技術の導入などは柔軟に対応できる環境ですので、バックエンド・インフラ・SREエンジニアの方、是非一緒に技術刷新にチャレンジしてみませんか?

/assets/images/10326886/original/7a007e8c-7e65-4896-90ad-848b341d8a51?1662986894)




/assets/images/10326886/original/7a007e8c-7e65-4896-90ad-848b341d8a51?1662986894)


