
こんにちは!Onplanetzです。
今日もArchigan#2に引き続き、ベースラインの改善を行っていきたいと思います!
という訳で、今回はArchigan#1で課題になっていた、画像の鮮明度を向上させていきます。
前回は以下の通り、部屋と部屋の境界が斜めになっていたり、境界がぼやけてしまったりといった問題がありました。(詳細については、過去記事をご覧ください。)

これには、以下のような原因が考えられていました。
・そもそもアノテーション[1]に失敗した枚数が多かったので、GAN[2]がきちんと学習出来てい なかった。(前記事で解決)
・境界など細かい部分が取れていないので、学習が足りず、精度が低かった。
この問題に対処するには、
・データ枚数を増加させる。
・学習時のepoch数を増やす。
・学習率を調整する。
・別モデルを使用する。
などありますが、今回はデータ枚数の増加と学習時のepoch数の増加を行いました。
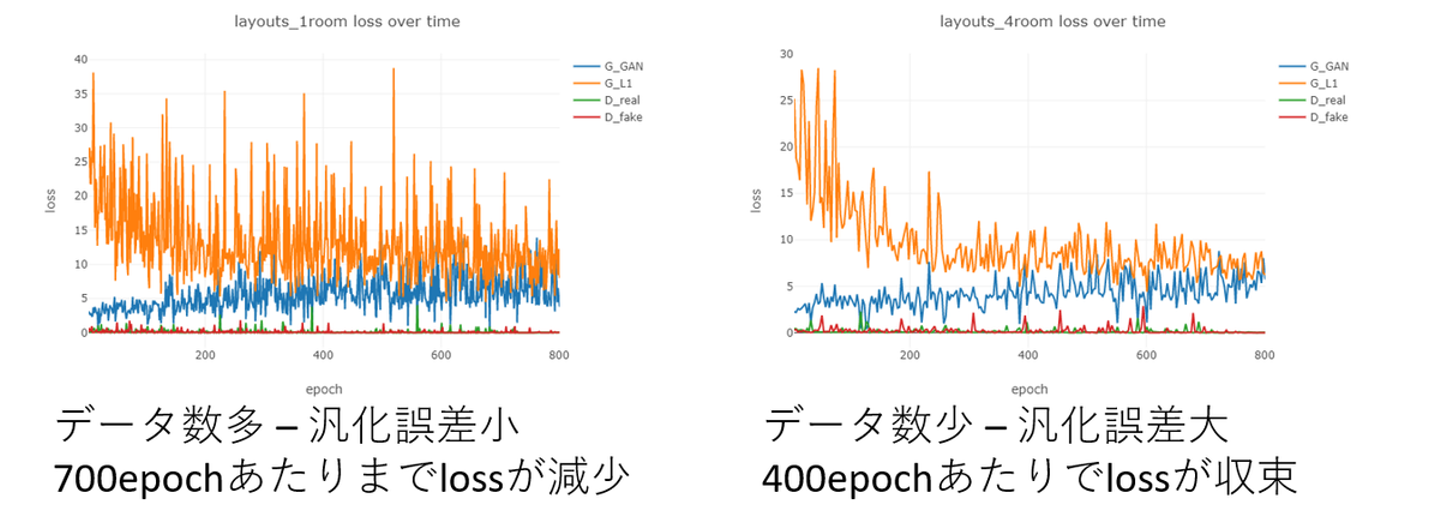
上に示した図は、学習用データの枚数が多いときと少ない時における学習の進行状況を可視化したもので、オレンジ色の線が、生成された画像と元のアノテーション画像との差(つまり、教師データとの差)を表しています。今までは200epoch, 学習データ30枚くらいでやっていましたが、図から、学習データを80枚くらいまで増やした場合に、700epochあたりまでオレンジ色の線の下降が見られることから、学習データを増やしてepoch数も増やすと、精度の向上が見込めることが分かります。
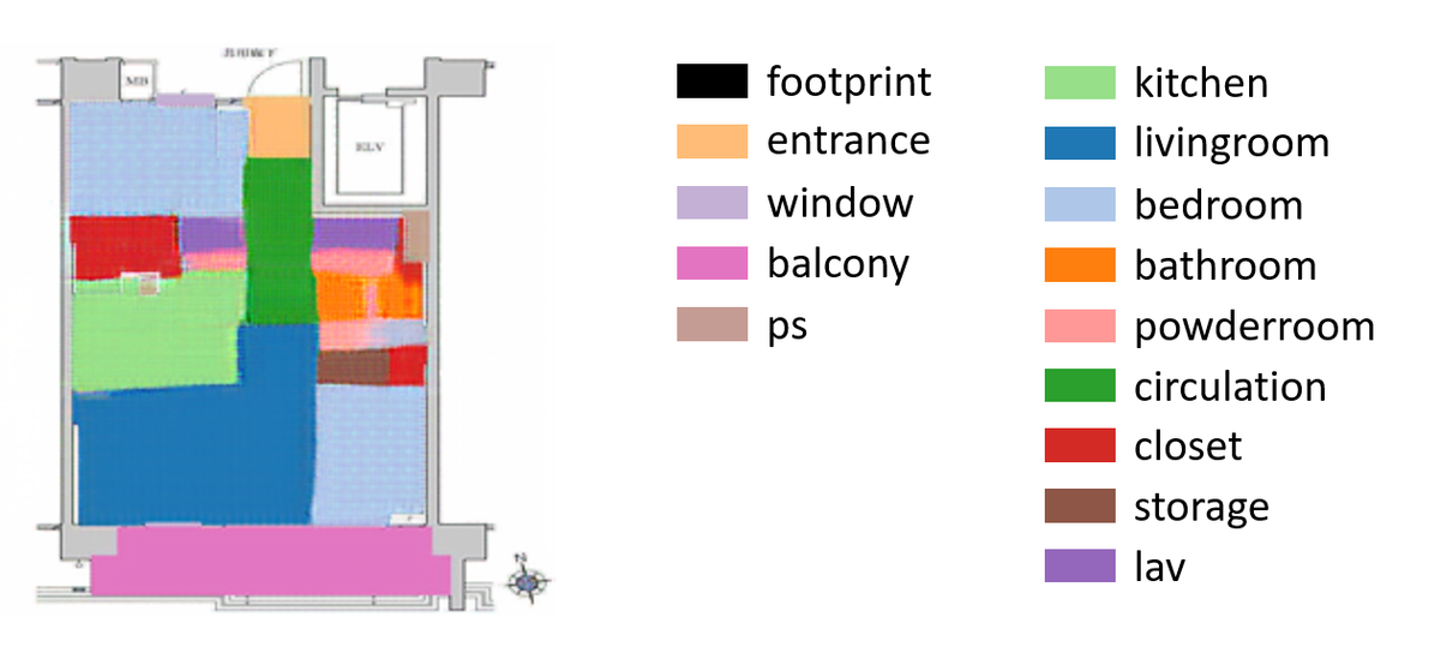
実際に作成した間取り図も以下のように、定性的に判断しても鮮明さがあがり、最初にお見せした画像と比べて精度が大幅に向上する結果となりました。また、まだ改善の余地はあるものの、洗面所の近くにお風呂が生成されるなど、ある程度尤もらしい部屋が生成できているのではないかと思います。
さて、ここまでで間取り図生成モデルが実用出来そうなレベルになってきたので、次はニーズを解決する方向に持っていきたいと思います!(#4へ続く)
参考文献
[1]アノテーションは、labelImgを使用しています。
GitHub:Tzutalin. LabelImg. Git code (2015), https://github.com/tzutalin/labelImg
[2]今回使用したGANのモデルは、pix2pixで、先行研究としてArchiGANを参考にしています。
pix2pix論文:Image-to-Image Translation with Conditional Adversarial Networks, Phillip Isola et.al., https://arxiv.org/abs/1611.07004
pix2pixコード:CycleGAN and pix2pix in Pytorch, junyanz github, https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
先行研究:ArchiGAN: a Generative Stack for Apartment Building Design, NVIDIA, https://devblogs.nvidia.com/archigan-generative-stack-apartment-building-design/
/assets/images/21853197/original/83661473-6dc7-4f92-a9f3-d0a6669a5ae8?1755593766)


/assets/images/21853197/original/83661473-6dc7-4f92-a9f3-d0a6669a5ae8?1755593766)

/assets/images/21853197/original/83661473-6dc7-4f92-a9f3-d0a6669a5ae8?1755593766)


