
GMOメイクショップ コアグループ エンジニアの森です。
最近業務効率化のためにOpenAIのAPIを利用して大量の文章データを自動整理するツールを開発をしました。
この記事ではAIを使った文章要約と、過去データとの重複チェックを実装した過程について紹介したいと思います。
開発の背景
課題
makeshopをご利用いただいているショップ運営者から日々様々なご意見・ご要望をカスタマーサポート(CS)にいただいています。その中でmakeshopの機能改善に関する要望については、CSがスプレッドシートに直接記載し、それを確認するという方法で管理していました。しかし1万を超えるショップ様から寄せられる要望は数が多く、さらに以下のような問題が発生していました。
- 要望の重複:複数のショップ様から似た内容の要望が何度も寄せられ、同じ要望が複数回記録されてしまうことがありました。
- 記録のばらつき:CSが要望を記録する際、書き方にばらつきがあり、要望内容の確認や議論が困難になることがありました。
要望の内容確認・精査に工数が増えることで、エンジニアが開発に着手するまでの時間がかかり、対応が遅れる一因となっていました。
解決策
この課題を解決するために、以下の2つの機能を備えたツールを開発することになりました。
1. 要望の要約処理
- 要望をAIが自動的に共通フォーマットに要約・整形することで、素早く概要を把握できるようにする。
- 複数の要望が一つにまとめられた場合でも、それぞれを個別の要望に分解することで、正確な件数を把握できるようにする。
2. 重複した要望の検出
- 重複する要望を検出し、同じ趣旨の要望を繰り返し確認する手間を削減する。
- 複数のショップ様から寄せられた内容が同じ要望の数を把握することで需要の高い要望を見極め、意思決定の最適化を図る。
ツールの概要
ここからは前段の問題を解決するために今回開発したツールについての説明です。
使用した技術
■Chat Completions API
自然な会話やテキスト生成が可能なOpenAIのAPIです。基本的に返答はテキストベースの文章ですが、レスポンス形式を指定することでjson等データで受け取ることも可能です。
■Embeddings API
テキストデータを数値ベクトルに変換できるOpenAIのAPIです。テキストのベクトルデータは自然言語処理によって様々な解析に利用可能です。
■Qdrant
オープンソースのベクトル検索エンジンで、テキストや画像の埋め込みベクトルを扱います。
流れとしては以下です。
- CSがショップ様から要望を聞き取り
- CSがSlack Workflowの入力フォームから要望を入力
- 入力された要望をツールにかける(←本記事で紹介する部分)
- 整形後の要望をスプレッドシートに書き込む
今回紹介するのは3番の部分、主に上記図の青いエリアでの処理です。
ツールを置いたAWSの環境構築やSlack Workflow、Google Spreadsheetとの連携の実装についても、いずれどこかで紹介できればと思っています。
ツールでの処理内容
APIを呼び出すメソッド
まずAPIの呼び出し部分の紹介です。OpenAIのAPIにリクエストするGoで書かれたメソッドです。
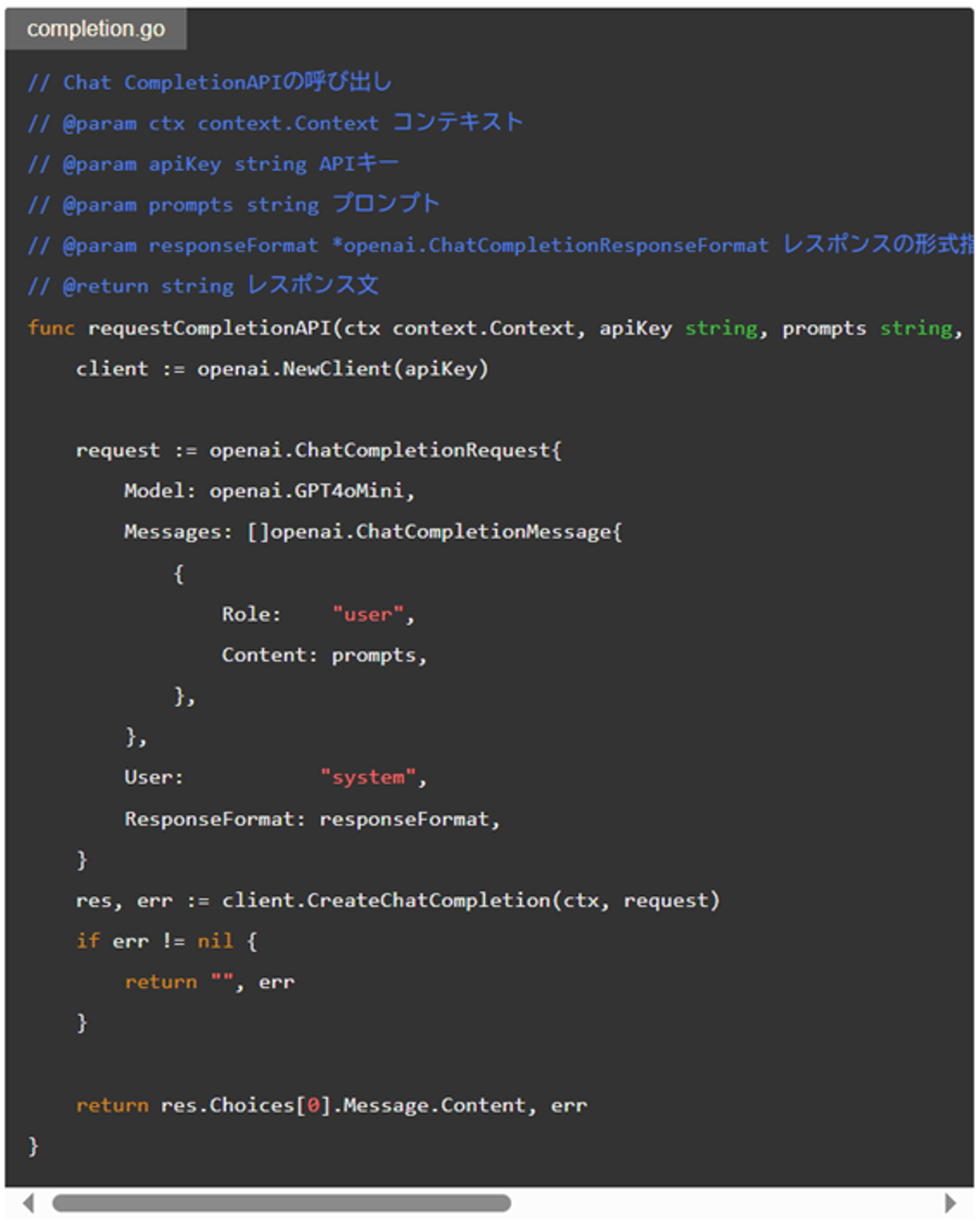
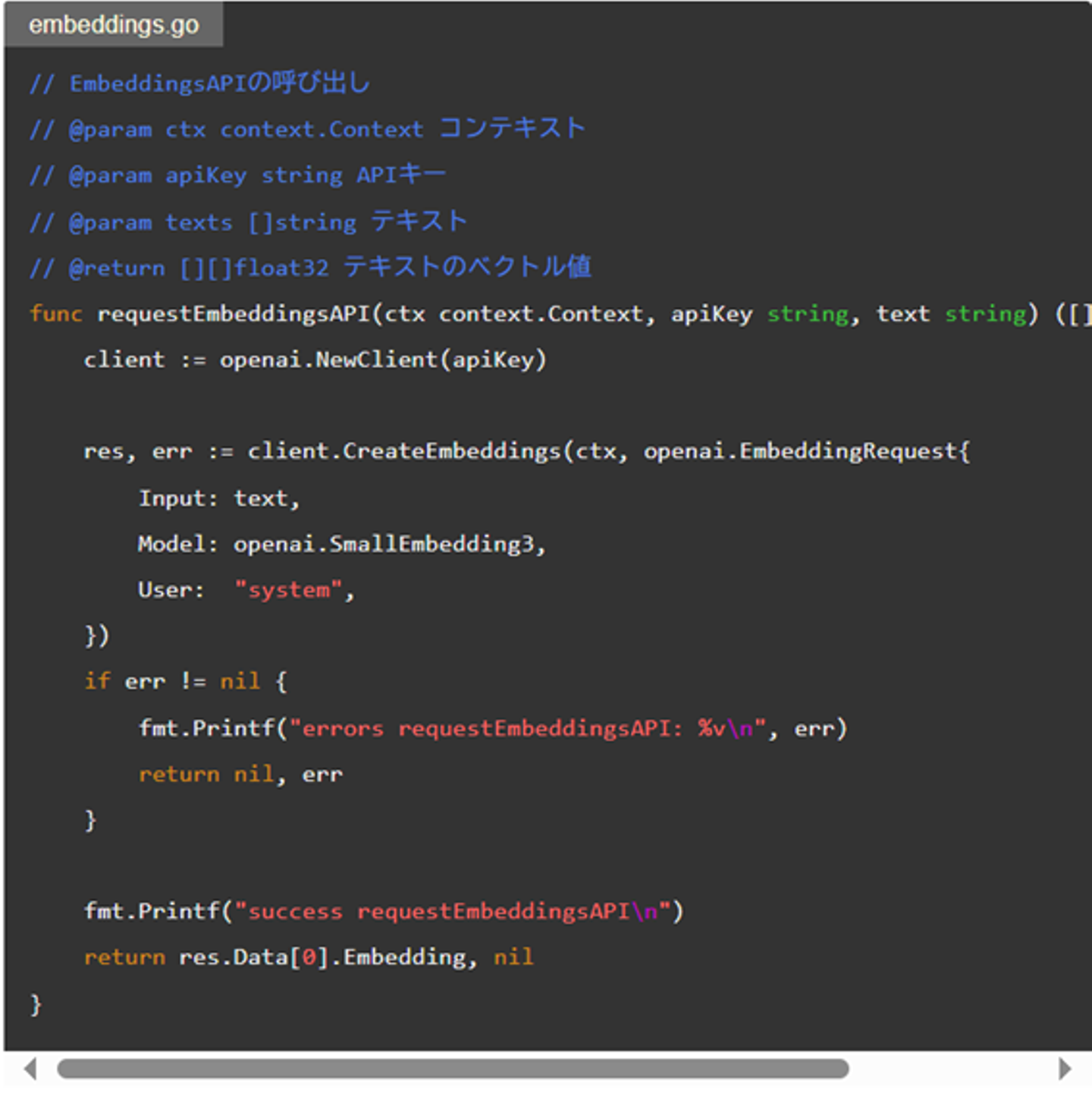
要約処理
処理内容要約はChat Completions APIに本文、該当する機能種別を組み込んだプロンプトを渡すことで実現しました。
大きく以下の3つを満たす出力を得られるようにプロンプトを作成しました。
- 要旨だけを抜き出し文量を減らし箇条書きにする
- 不適切な文章の置換・削除
- 異なる内容の分割
以下が実際のプロンプト(一部)です。
※ %sは本文、機能種別にあたる変数です。

固有名詞など、無くなると要望の根源になりうるものは削除しないようにし、逆に要望に直結しないものについては削除するよう調整しました。容易に概要を把握できるよう共通フォーマットで出力されるようにしています。
{makeshopの前提知識}には、管理画面にある各ページとその機能について説明した文章を定義しています。(文量が多いため割愛)
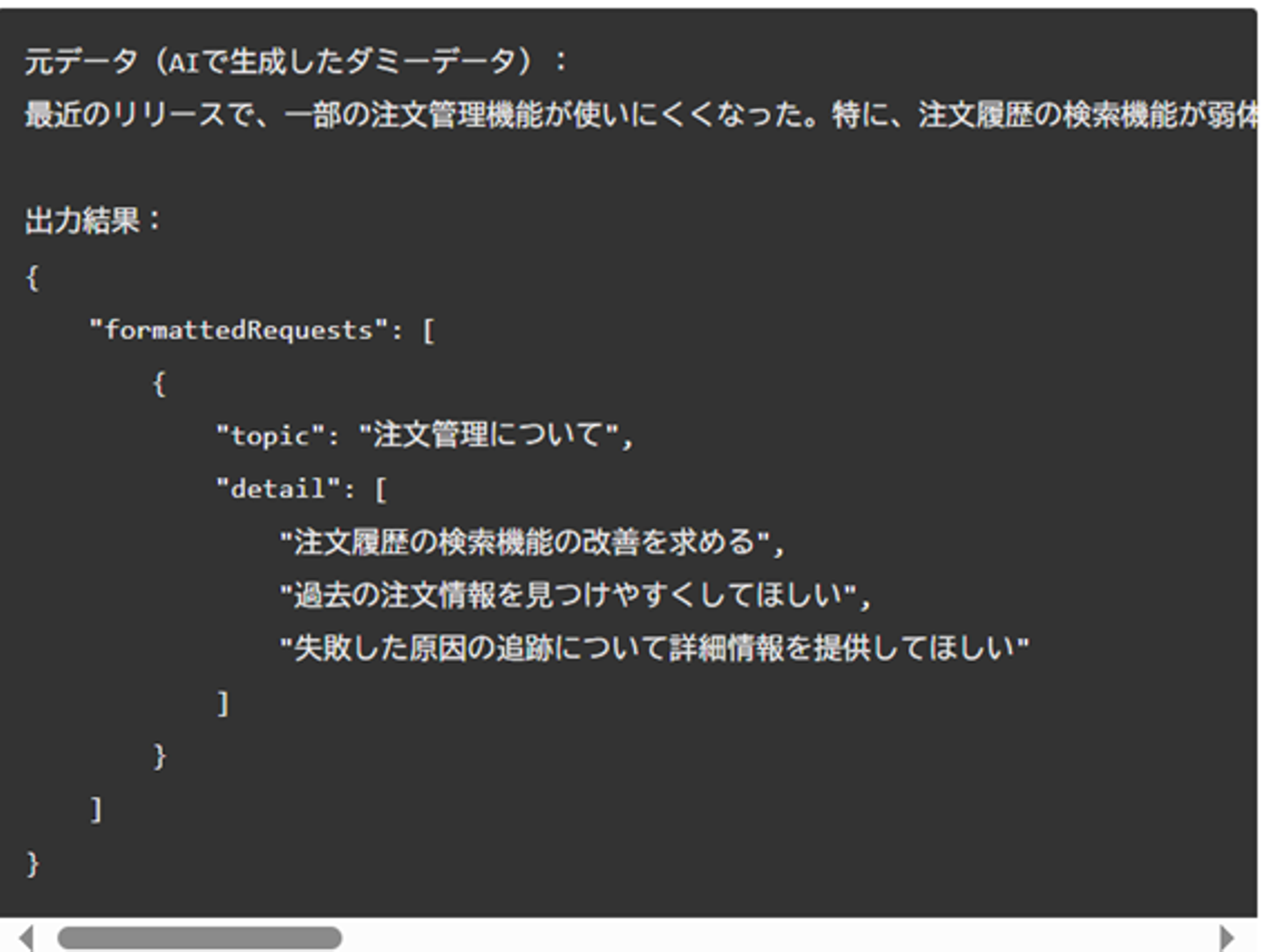
出力結果
出力結果は jsonオブジェクトの形式で取得するようにしました。レスポンスの形式はAPIリクエストにResponseFormatを含めることで指定可能です。 以下出力結果と使用したResponseFormatです。

重複チェック
処理内容
重複チェックによって過去に同様の要望があった場合に、それを検知できるようにします。処理は以下の5ステップで行われます。
- 新しい要望をEmbeddings APIにリクエストして、ベクトル化した値を取得
- 先に紹介した
requestEmbeddingsAPI()の引数に要望の本文を使うことで、ベクトルを取得します。
- 先に紹介した
- Qdrantの類似検索によって、過去の類似した要望を取得
- Qdrantの検索結果を用いてChat Completions APIで重複チェック
- 重複していた場合、重複IDを付与
- 重複していたと判断した場合は、対象となる過去要望に紐づくUIDを重複IDとして登録します。重複IDを持つかどうかで、過去にあった要望かを判別できます。
- 重複した要望数をカウント
- 重複IDをカウントすることで、重複が多い要望 = 需要の高い要望として扱うことで、改善対応の優先度決定に反映することができます。
プロンプト
以下はChat Completions APIに重複チェックをリクエストする際のプロンプトの一部です。

{出力結果}には、前述した通り内容の一致度をスコアリングして最もスコアが高い要望を出力するよう指示をしました。スコアの他に識別できるようUID、またAIの判断基準が適切かを検証できるよう類似している根拠も出力するようにしました。
{類似条件}は精度を上げるために検証しながら少しずつ追加していきました。 検証段階で、これらの類似条件が書かれていない状態だと、
「これはECサイトに対する要望という点が共通しているため類似しています。」
「使いにくいという意見が一致しているため類似しています。」
といった大雑把な根拠に基づいて高いスコアが設定されるようになっていました。 そのため、そういった汎用的な表現等は類似している根拠としないよう、プロンプトに追加しました。
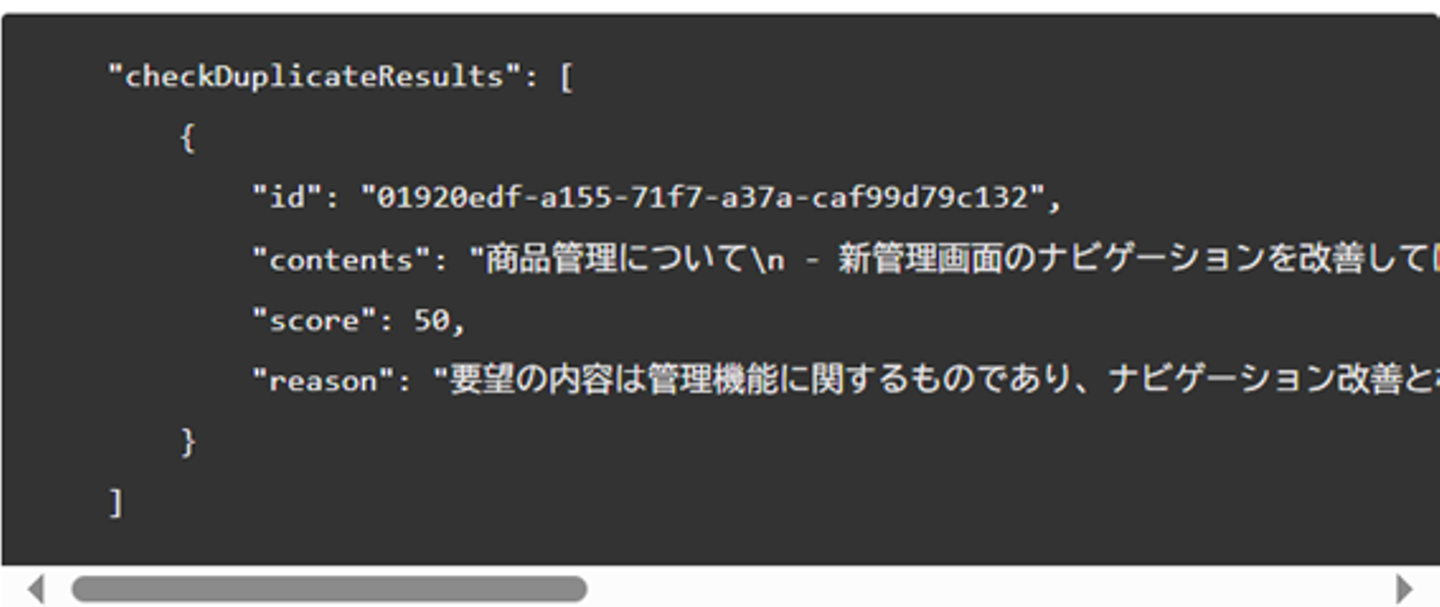
出力結果
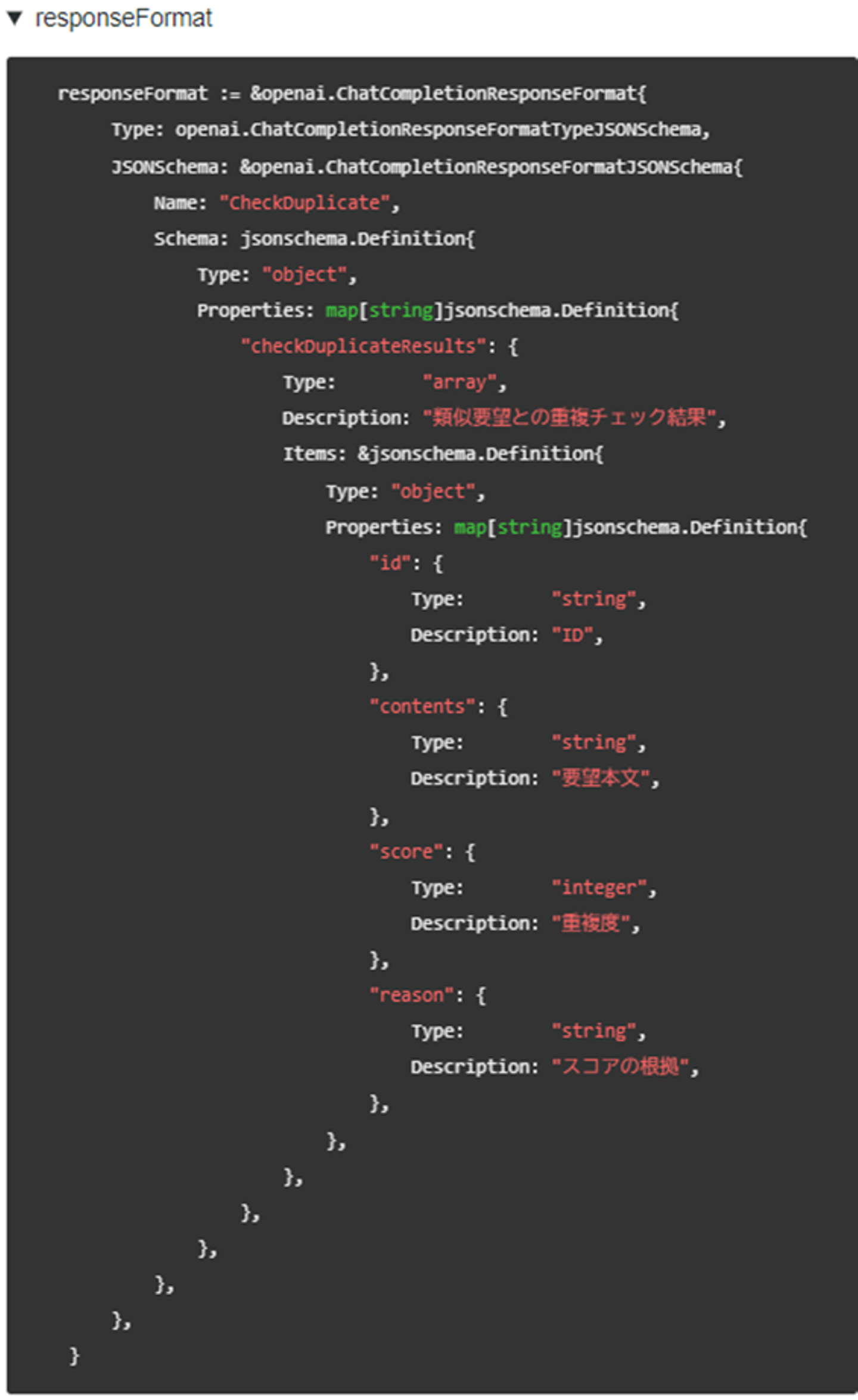
こちらの出力結果も要約処理と同様にjson形式で取得できるようResponseFormatを指定しました。
以下出力結果と使用したResponseFormatです。この例の場合はスコアが50のため重複とは判定しません。
まとめ
今回は文章データを自動整理するツールについて紹介しました。 まだ実験段階のため今後の運用を通してまだまだ改善できるものだと思いますが、引き続き開発と検証を重ねてより高い精度で要望の整理ができるようなれば、その過程についてまた取り上げたいと思います。 このツールではサービスのユーザから要望の文章を対象にしましたが、OpenAIのAPIやQdrantの利用など今回の実践した手法は様々なものに応用できると思います。是非みなさんの抱えた課題の解決に役立ててもらえれると嬉しいです。
◆ 他のBlogはこちらから⇒ https://tech.makeshop.co.jp/◆
最後までお読みいただきましてありがとうございました。ご応募お待ちしています!

/assets/images/32062/original/9178d6ef-9569-4fc7-8f84-ecd75cfcc597?1596514385)
/assets/images/32062/original/9178d6ef-9569-4fc7-8f84-ecd75cfcc597?1596514385)


