

Lookerのカレンダー | Advent Calendar 2022 - Qiita
Lookerのカレンダーページです。
https://qiita.com/advent-calendar/2022/looker
この記事は Looker Advent Calendar 2022 の 12/15の記事です。
クラシコムデータ分析チームの高尾です。
今回は、Lookerが得意としているデータガバナンスについて、複雑化するスプレッドシートの運用とどう向き合うか、というテーマで最近取り組んだことについてご紹介します。
データ分析が、事業に貢献する、と言ったときに、大きく、以下の2つの方向性があると考えています。
・インサイトを提供して売上をあげることで利益に貢献する
・業務を効率化することでコストを削減して利益に貢献する
僕が「データ分析」という言葉から受ける印象としては、前者のイメージが強かったのですが、ここ最近の実感として、後者も大事だし、データチームが貢献できるポイントの一つだな、と感じています。今回は、どちらかというと、後者に着目した内容です。
後者については、ガートナー社が提唱した「DataOps」という考え方に近いものと言えます。
(ガートナー社のサイト上の文言をGoogle翻訳で日本語にしました)DataOps は、組織全体のデータ マネージャーとデータコンシューマーの間のデータフローの通信、統合、および自動化を改善することに重点を置いた共同データ管理プラクティスです。
また、鹿島アントラーズ社の金子さんが「コーポレートソリューション」というキーワードが、DataOpsを包含しつつ、事業への貢献を端的に表している単語だなと感じ、参考にさせていただいています。
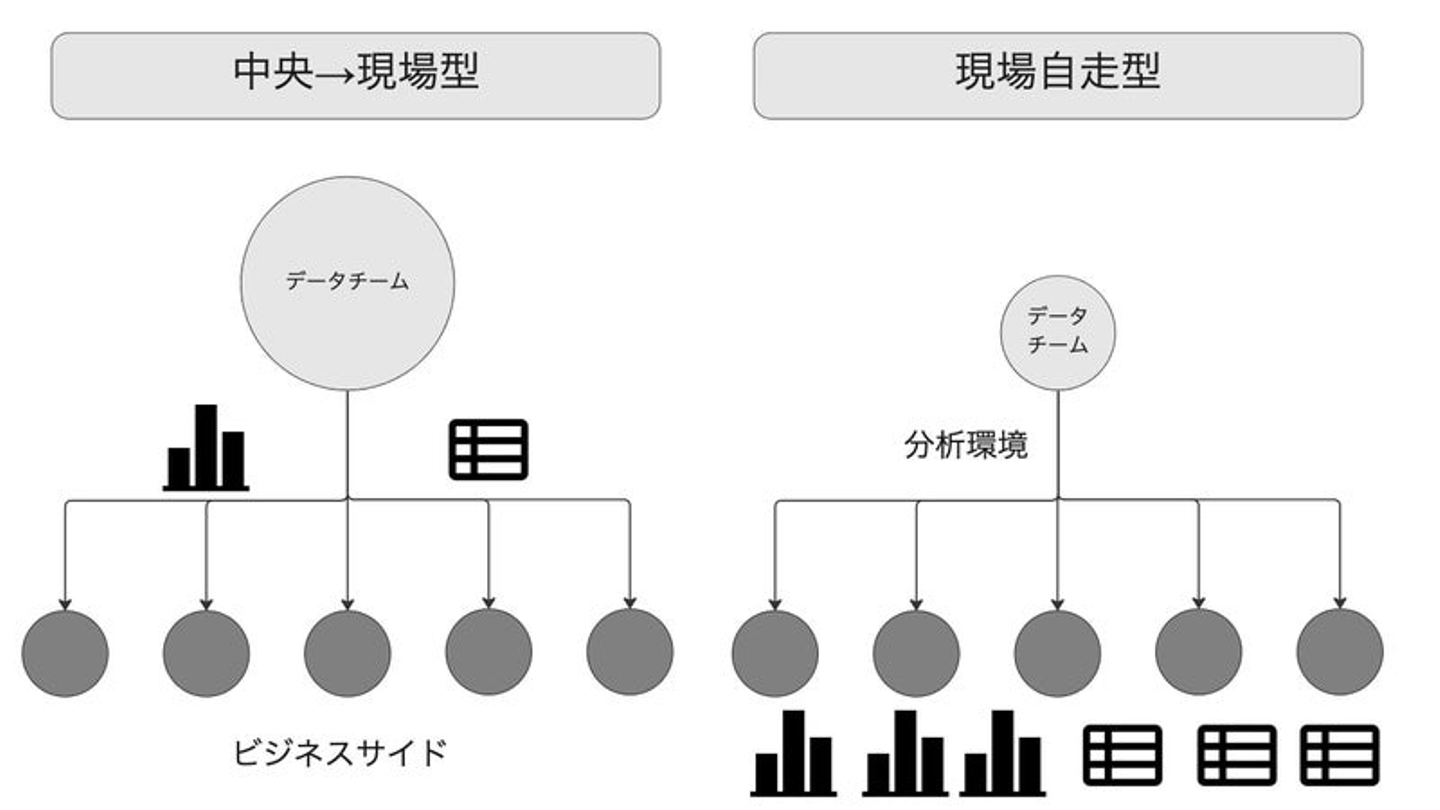
これは、「データ民主化」という文脈の中で語り尽くされたことかもしれませんが、Lookerを使ってexploreやdashbordを整備することによって、データのユーザー部門において分析や集計が盛んに行われるようになります。
最初は、こちらが意図したデータをみてもらっている、という状況だったのが、いつのまにか、「あ、そんなデータみていたんだ」というケースが、発生します。
クラシコムのように、元々業務がデータ基盤なしに成立していて、後から基盤を構築した、という場合には、むしろ、「現場ではずっと見ていた数字を、Lookerを使って更に便利にみることができるようになった」というのが実態なので、「いつの間にかデータを見ている」というより、段々と、データチーム側(僕)が、現場の業務の解像度が上がってきて、よくわかるようになってきた、というのが正確な表現かもしれません。
データ分析の貢献の2方向、という観点でいうと、現場が、効率的にデータをみれるようになって、分析の所要時間が短縮され、利益に貢献できている、という状態です。
ただ、ここでちょっと不安な点が出てきました。
データチームとビジネスサイドの2つの関係
Lookerのエクスポート機能や、troccoの転送機能を利用することで、ビジネスサイドがデータをスプレッドシート上に集約できます。
そして、関数やGASに詳しい人がいた場合、スプレッドシートが幾重にも折り重なって集計が行われる、という状況が発生し得ます。
クラシコムの場合、予算管理を担当しているバイヤーが、関数を使うのがすごく得意なので、パッと見ただけでは何が行われているかわからない・・・というくらい、スプレッドシートがフル活用されている環境が発生していました。
業務は効率的に行われています。
しかし、Lookerの導入時に利点の一つとして考えていた、「LookMLで集計のロジックを定義できるからデータガバナンスを効かせられる」という環境が、やや崩れているように感じられてしまいました。
何か、具体的に問題が発生したわけではないのに、実は、望ましくない状態になっているのではないか・・・?という漠然とした不安が湧いてきました。
ここに至って、「コーポレートソリューションに貢献するデータガバナンスとして最低限担保しないといけないラインはどこか?」を検討する必要性に迫られたのでした。
データガバナンスとは・・・?と考えるみちのり
そこで、現場に時間をもらって、業務フローや、スプレッドシートがどのように活用されているのかをヒアリングさせてもらいました。
実は、同タイミングで、現場側からも「スプレッドシートを用いた運用で問題ないのか気になっており、特に、データ集計の安定性を確保できるようにしたい」という相談をもらっていたこともあり、「業務を効率化できるかもしれない」という仮説のもと、ヒアリングを実施しました。
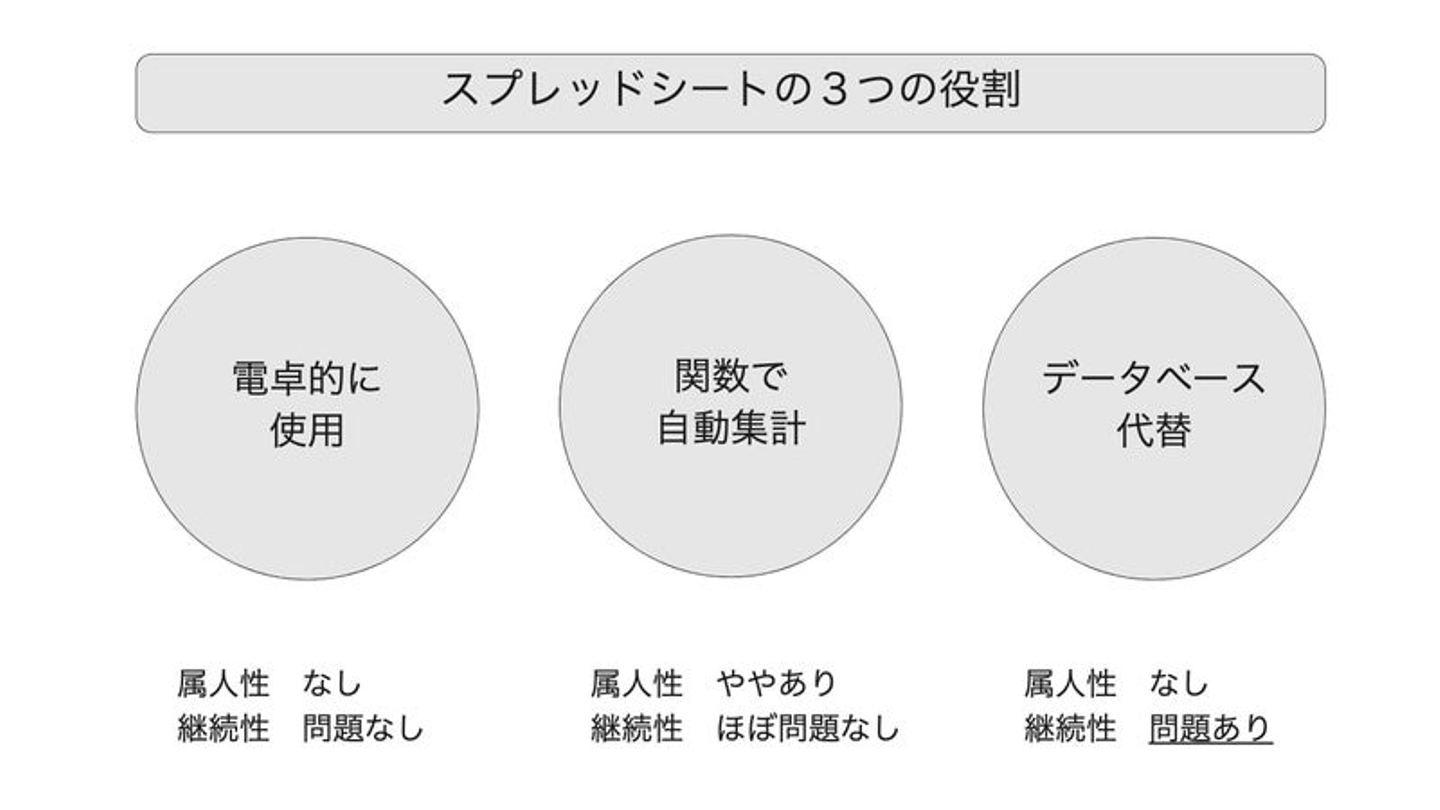
ヒアリングの結果、普段、何気なく便利に、万能ツールとして使っているスプレッドシートには以下の3つの役割がある、ということがみえてきました。
①電卓の代わりに使う
②関数で自動計算する
③データベースとして利用
それぞれ、簡単に補足します。
あるデータに対して、例えば、来月の発注量を1割増やすと、在庫金額はどう変動する?などを計算しながら、発注量を決めていく、という使い方です。
Looker上では決められた数字を定常的にウォッチするのには向いていますが、細々とした計算はスプレッドシートを使うのが便利です。
importrangeを使って別シートのデータを取り込んだり、sumifやvlookupを駆使して集計を行ったりと、関数を予めシートに記載しておいて、データが取り込まれたら(この取り込みもtroccoで自動化されている)、自動的に計算結果を参照できるようになっている、という使い方です。
例えば、取り扱っている商品を分析する上で、タグを付与したり、ちょっとしたメモを記載する場として、スプレッドシートを利用するケースです。
このとき、記載は、主に手入力で実施されることになります。そして、この入力内容を②の要領で、さらに別シートで参照して集計する、ということも発生します。
「何にでも使える便利なツール」の役割を整理
そして、それぞれに対して、解決すべき課題なのかどうかを改めて考えました。
そのときに考えた観点としては「属人性があるのか」「現在の運用が事業の継続性に影響を与えるのか」の2つの観点です。
そうすると、①の電卓的な使用は特に問題がなさそうです。②が、一見するとすごく気になるのですが、現実的に、LookML化してLooker上でみれるようにする工数がかけられないことと、見ている指標がなにか、ということは、現場の担当者だけではなく、マネージャーも把握しているため、ある日突然、スプレッドシートがクラッシュする、とか、間違って消してしまう、ということが発生しても、現実的な工数の範囲で、リカバリー可能なのではないか、と考えました。
しかし、③について、「スプレッドシート上にしか存在しないデータ」=「マスタデータとしてのスプレッドシート」が発生してしまっており、この場合は、シートの情報が失われたときに、リカバリーが困難です。
履歴を保持できる、というgoogle driveの機能があるため、本来的には、スプレッドシート上にしか存在しないデータが、シートごと失われる、という事態は発生しにくいはずなのですが、現場で運用されている「マスタデータ的スプレッドシート」が、発生の経緯の都合で、「いくつかの集計をしているシートの一つのタブ」の中に埋没して存在しているという状況でした。
この場合、編集権限を細かく設定することもできないため、マスタが意図せず編集される可能性もあります。
こういった状況を解消するため、今回は、いくつかの選択肢を検討し、「権限を適切に設定した、独立のスプレッドシートに切り出す」ということを対策としました。
長いお話しとなってしまいましたが、やったこととしては、とてもシンプルです。
しかし、これによって、現場は安心してデータを更新できるようになり、データチームや経営も、データの継続性に安心感をもつことができ、クラシコムらしいデータガバナンスのあり方を考える良い機会となりました。
また、データチームのリソースの関係で優先度を下げた自動集計部分についても、ゆくゆくは、Lookerへの乗せ換えを検討していきたい部分として認識できました。
今回は、コーポレートソリューションに貢献するデータ分析として、スプレッドシートの管理を中心にお話しました。
派手な成果が出るポイントではありませんが、着実に現場に貢献できているのでは、と考えています。

/assets/images/8987032/original/ddeeb212-469f-4efc-9ee4-c5b04a64e96d?1646380372)

![]()


/assets/images/8962265/original/c7866d47-17e7-4032-8d3d-04275630324d?1646121547)

