/assets/images/17478267/original/811c7fd1-005f-481d-abba-454cd7a7ed9e?1711958341)

株式会社グロービス's job postings
こんにちは!
グロービスでデータサイエンスチームのプロダクトマネージャーをしている宮島です。
こちらの記事でも紹介したように、現在グロービスでは自社で保持する学習データを活用した機械学習PJTをガンガン進めています。
そして実際にリリース(=サービス導入)まで完了したPJTもいくつかあります。
そこで今回はリリースしたPJTの中で、約1.5ヶ月という短期間でサービス導入となったPJTをピックアップして紹介出来ればと思います。
機械学習PJTの概要
どんなPJTか?
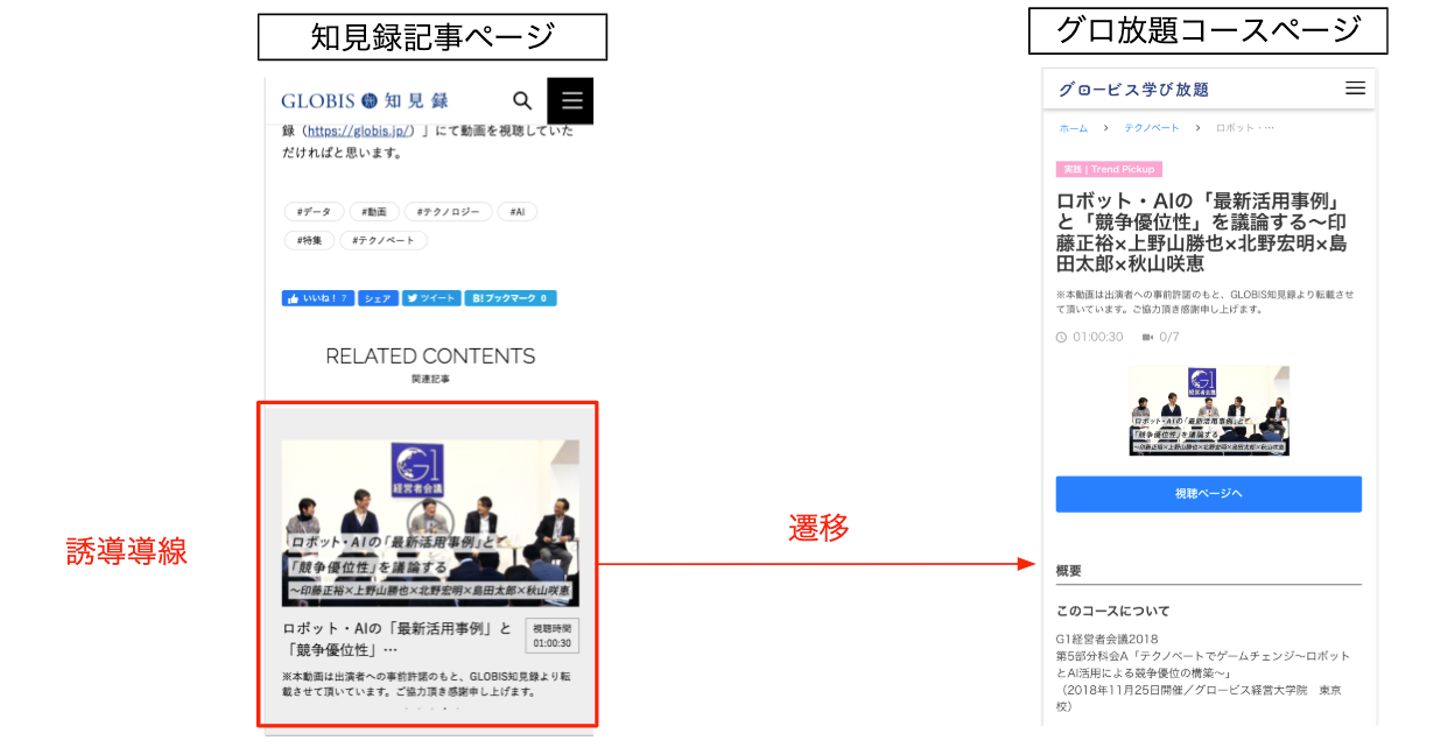
一言でいうと、オウンドメディアであるGLOBIS知見録(以下知見録)からオンライン学習サービスであるグロービス学び放題(以下グロ放題)への誘導を最適化するというPJTになります。
知見録からグロ放題に遷移するユーザーを増やす事で、グロ放題利用ユーザーを増やすという事を目的にしたPJTになります。
どんなアルゴリズムにしたか?
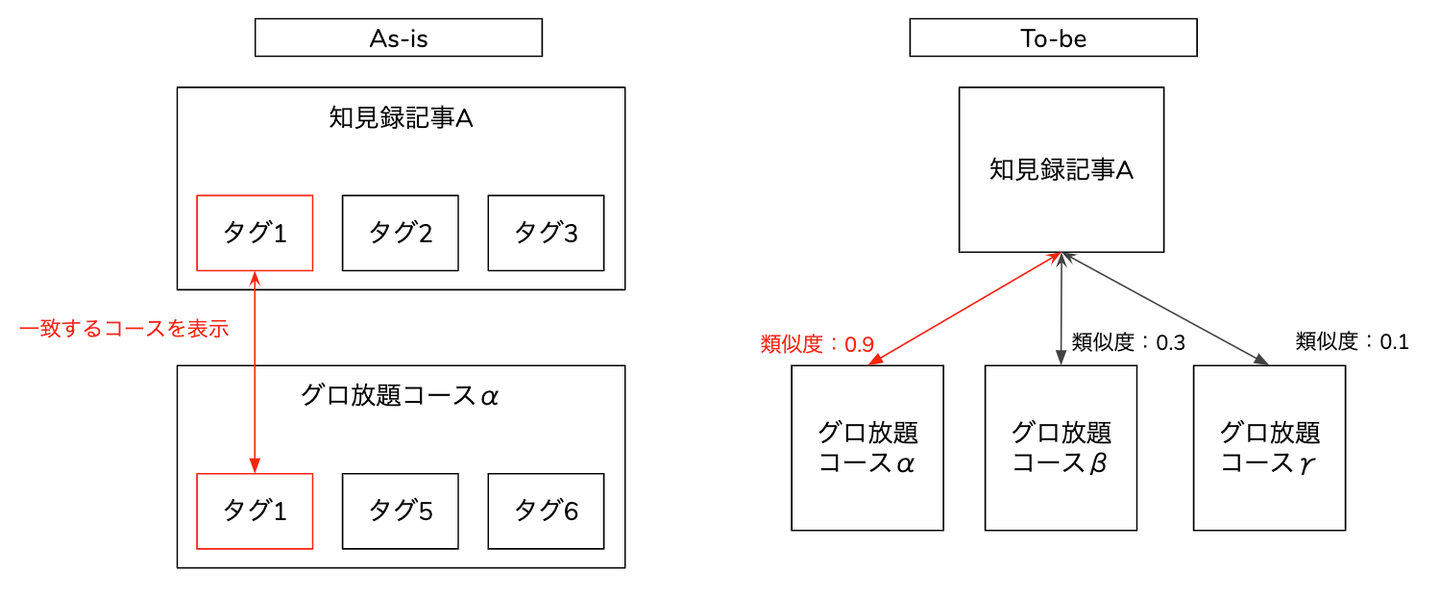
改良前のアルゴリズムは、下記のように知見録記事に付与されたタグと合致するグロ放題のコースをランダムで5個表示するというルールベースのアルゴリズムになっていました。
このアルゴリズムの改良として、コンテンツベースのレコメンドを採用しました。
知見録記事とグロ放題コース情報のそれぞれの文章をTF-IDF表現でベクトル化し、コサイン類似度を使って類似度計算をする事で類似度が高いコースを5個表示するという非常にシンプルなアルゴリズムにしました。
本当はImpressionやClickログを用いたアルゴリズムも試したかったのですが、これらのログが取得出来ていなかった事から、初期リリースではログベースは一旦諦めました。
アルゴリズム改良で期待していた点は何か?
改良前のアルゴリズムには大きく2つの問題点がありました。
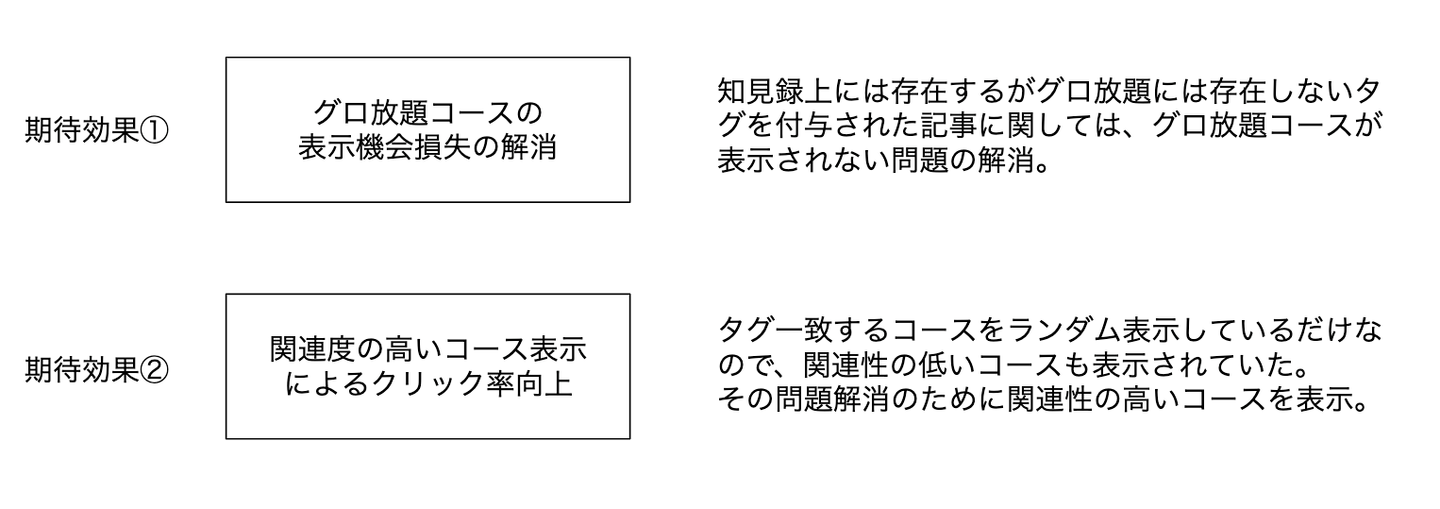
1つ目の問題点は、グロ放題への誘導導線が表示されないという機会損失です。
知見録上には存在するがグロ放題には存在しないタグを付与された記事に関しては、グロ放題コースが表示されなくなりimpression観点で機会損失が発生していました。
2つ目の問題点は、関連性の低いコースも表示されてしまう点です。
タグ一致でかつランダム表示であるため、記事の内容と本当に関連度の高いグロ放題コースが表示されないケースも発生していました。
これらの問題点を解決すればグロ放題ユーザーの増加が見込めそうだったので、シンプルなコンテンツベースレコメンドでクイックにリリースする事を目指しました。
どのようなデータパイプラインにしたか?
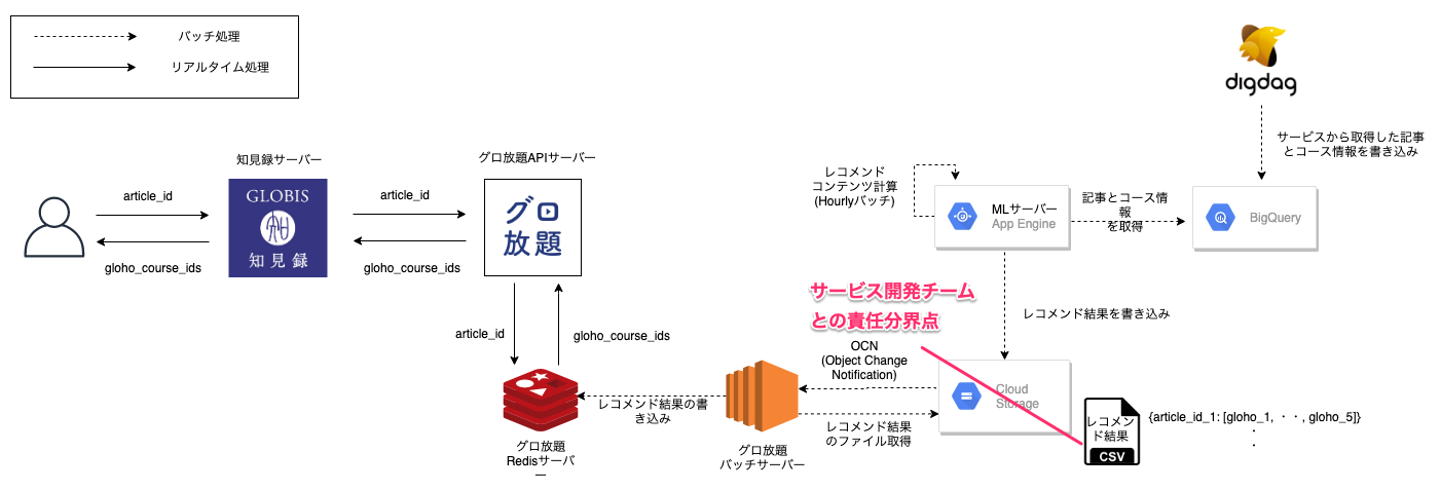
こちらの記事でも紹介したように、機械学習のサービス導入においては「自チームのみの対応でアルゴリズム改良可能なデータパイプラインにする」事が重要になります。
(継続的にアルゴリズム改良をしていきたいので)
なので、今回は下記のようなファイル連携の形にしました。
プロダクト開発チームとの責任分界点をファイルを書き込むCloud Storageにしているので、書き込むファイルの内容を変更すれば、レコメンド結果を変更出来るようになっています。
リリース結果
A/Bテストから始めて、新アルゴリズムの方が良い事を確認してからサービスインする事が一般的かと思いますが、このPJTでは最初からサービスインという形にしました。
前述の既存アルゴリズムの課題を踏まえると、良くなる事が自明だったためです。
そこで、効果検証はリリース前後1ヶ月での比較になりました。
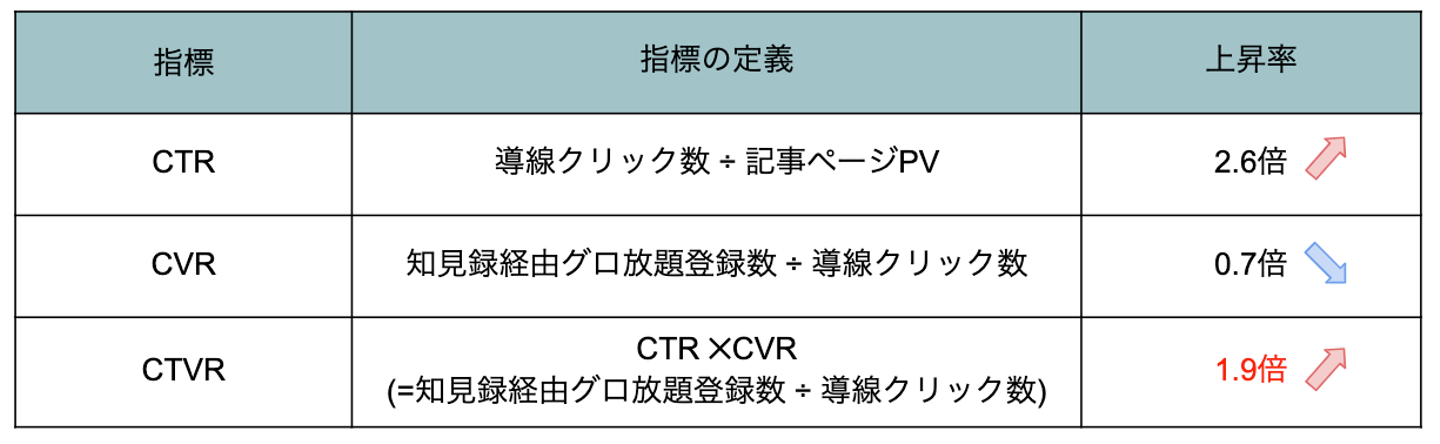
また効果を測る指標としては、以下3つの指標を使いました。
・CTR:導線クリック数 ÷ 記事ページPV
・CVR:知見録経由のグロ放題登録数 ÷ 導線クリック数
・CTVR:CTR ✕ CVR (知見録経由のグロ放題登録数 ÷ 記事ページPVと同義)
その結果は以下のようになり、CV(=知見録経由のグロ放題登録数)を約1.9倍に増やす事に成功しました!
・CTR:約2.6倍に上昇!
・CVR:約0.7倍に下降
・CTVR:約1.9倍に上昇!
このPJTが特徴的だったと思う3つのポイント
ここまでPJTの内容と結果を紹介してきましたが、実は進める中でグロービスらしさを表すような特徴的なポイントが3つありましたので、紹介出来ればと思います。
PJT実施がすぐに承認された
このPJTは2つのサービスが関係しているので、PJT関係者(=ステークホルダー)は以下のように多岐に渡りました。
・グロ放題開発チーム
・知見録チーム
・開発ベンダー (知見録を開発して下さってるベンダー)
プロジェクトマネジメントの一般論として、ステークホルダーが増えれば承認プロセスが複雑になり、承認を得るのに時間がかかるようになります。なので、私も最初は時間がかかる事を想定していました。
しかし実際は全関係者を集めた1回目のMTGでPJT実施の承認を得る事が出来ました!
加えて、A/Bテストをskipして最初からサービス導入しようという意思決定もなされました。
定量(=効果試算)と定性(=既存アルゴリズムの問題点指摘)の2つの観点でPJT実施の意義を説明した事で納得感を得られた部分もありますが、「良いと思ったらすぐに意思決定する」というグロービスのカルチャーの影響も大きかったと思っています。
プロダクト開発チームの開発が爆速
サービス導入は、データ連携要件の確定→実装→テストと開発が進んでいくので、リリースまで1ヶ月以上はかかる事を想定していました。
しかし実際は約2週間でリリースが完了しました。
(当初の予定より約1週間前倒してのリリースでした)
PJT実施の意義を納得してもらえていてモチベーションが高まっていた事もあると思いますが、「スピードを常に意識する」というグロービスのカルチャーの影響も大きかったと思っています。
約1.5ヶ月という短期間でサービス導入が実現
私自身これまでいくつかの企業で機械学習PJTのPMを経験していたので、PJT開始からサービス導入まで3ヶ月位はかかるだろうと想定していました。
しかし実際は、PJT開始からサービス導入までが約1ヶ月半で完了しました。
前述の「PJT実施の意思決定の早さ」、「プロダクト開発チームの開発が爆速」という2つの要因が重なった事による結果ですが、これまでに経験した中で最速でのサービス導入だったので、グロービスのスピード感にとても驚きました。
今後の展開
今後の展開としては、Factorization Machines(以下FM)を用いたアルゴリズムへの改良を予定しています。
アルゴリズム開発のためにはimpressionやclickログの取得が必要になるのですが、そちらの開発も爆速で進んでおり、近々利用可能になる予定です。
前述のように、自チームで生成するファイルの内容を変えればアルゴリズム切り替えが出来るようなデータパイプラインになっているので、FMが完成したらすぐに新アルゴリズムの効果検証が開始出来る形になっています。
さいごに
今回は1.5ヶ月でリリースした機械学習PJTの事例を紹介させて頂きました。
今回紹介した内容以外でもいくつか進めたい機械学習PJTがあるのですが、やりたい事に対してデータ人材が不足しています。
なので、下記のように様々な職種を積極採用しています!
・データエンジニア
・データサイエンティスト
・データサイエンスPdM
今回の事例紹介からもわかるように、グロービスではスピード感を持った機械学習モデルの開発やPJT進行が可能です!
少しでも興味を持って頂けたら気軽に話を聞きに来て下さい!
グロービスで機械学習のサービス導入を1.5ヶ月で実現した話

/assets/images/17478267/original/811c7fd1-005f-481d-abba-454cd7a7ed9e?1711958341)




/assets/images/17478267/original/811c7fd1-005f-481d-abba-454cd7a7ed9e?1711958341)
