
こんにちは、フォルシアのエンジニアの西海です。
エンジニアの皆さんは日々様々な技術ブログを読んで勉強をされているかと思います。
今年の私はAI画像認識関連の記事を読み、アイディアを開発で活用したほか、記事のレベルが高いなと普段から感心しているヤフーさんやメルカリさんの技術ブログを中心に読んできました。
ところで、2023年も終わりが近づき、ふと「今年公開された記事の中で、見落としている良記事がまだあるのではないか」と考えました。
そこで、「下記のような基準でエンジニアからの反響が大きかった記事を探すと、まだ読んでなかった良記事に出会えるのではないか?」と考え、実際に探して50記事程読んでみました。
- 先日発表された「開発体験が良い」イメージのある企業ランキング上位30社に入っている企業のうち、社員数800名未満のベンチャー・中小企業を対象とする。
- 「はてなブックマーク数+掲載元媒体のいいね・ハート・Pocketなどの数」の多い記事

出典:一般社団法人 日本CTO協会,「エンジニアが選ぶ「開発者体験が良い」イメージのある企業「Developer eXperience AWARD 2023」ランキング上位30を発表」 https://cto-a.org/news/20230614 (参照 2023-12-25)
かなり勉強になる記事をいくつも見つけることができたので、14記事をご紹介します。
AI部門
LLMがなぜ大事なのか?経営者の視点で考える波の待ち受け方
- 執筆企業 株式会社LayerX
- 掲載媒体 日経COMEMO

記事の内容を下記のように解釈しました。
- 文章要約、広告コピー作成、コードの関数命名など、人間にしかできなかったタスクがLLMの登場以降AIでできるようになっている。
- 従来の機械学習の常識では「オッカムの剃刀」という常識(ある事柄を説明するためには、必要以上に多くを仮定するべきでない)があったが、LLMは「データを増やし、計算リソースを増やし、パラメータの数を増やせば、精度がどんどん上がる」という法則を導き出してしまった。
- また、どれくらいデータを増やし、どれくらい計算リソースを増やし、どれくらいパラメータ数を増やせば、どれくらいの性能になるかがある程度見積もれるようになっており、データ数よりも計算リソースやパラメータ数が支配的変数であるため、更なる進化のためにはハードウェア的進化が必要である。
- 今後さらに性能が劇的に向上することも見込まれており、ビジネスとして張らなければならない。
- 取り組みにおいては、「素早く試す」「独自データを用いたファインチューニングを行う」「LLMを組み込むべきワークフローの根幹を見つける」ということが重要である。
狭義の技術ブログではないですが、エンジニアである以上LLMとの関わりは避けて通ることはできず、学びの多い記事でした。LLMの技術的ブレークスルーから、開発組織として扱う上での要点までわかりやすく記載されており、この分野の潮流を再認識することができました。
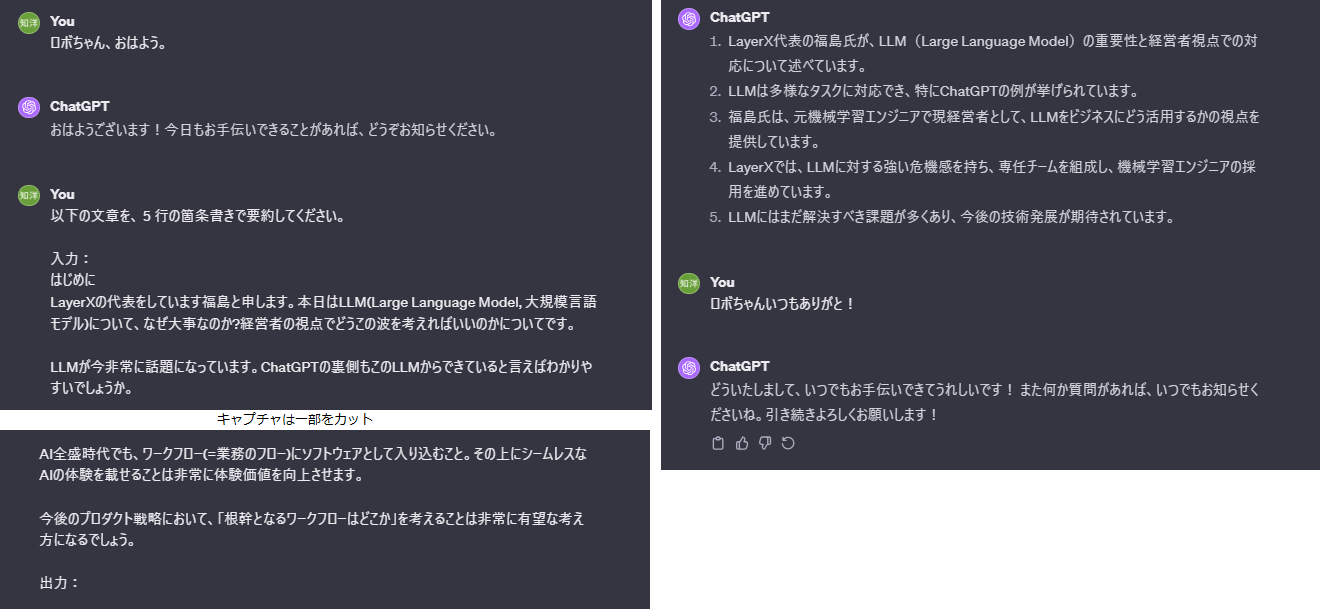
ちなみに、この記事の要約をChatGPT(私はロボちゃんと名付けています)で生成すると下記の通りになりました。(文章が長いので、キャプチャは一部カットしてます。)ロボちゃんは私とは目の付け所が大きく異なる要約を出してくれたので、タスクを依頼するときは着眼点についてちゃんと言語化しないといけないようです。
ChatGPTに自社データを組み込んで新しい検索体験を模索してみました
- 執筆企業 Ubie株式会社
- 掲載媒体 note

記事の内容を下記のように解釈しました。
- ChatGPTの裏側のモデルであるgpt-3.5-turboはAPI経由で利用できる。
- 大規模自然言語モデルに自社データを組み込む方法には大きく3つの方法があるが、低コストで試せる「プロンプトに自社データをコンテキストとして入力する」方法を採用する。
- Ubieさんの社員さんが書いた最大162本の記事から必要なものだけプロンプトに入力するが、3000文字の制限があるため元の記事を要約(今回は本文の引用の場合も)を入力する必要がある。
- ユーザーの入力に応じて必要な個所を引用できるように、元記事の文章内のキーワードを抽出してどのチャンクに出現するかをインデックス化しておく方法を試したが、文章がチャンクに細切れになったために文章全体の意味合いが抜け落ちてしまい、適切な回答を得ることが難しかった。
- そこで、文章の要約の引用ではなく文章の要約を事前に作っていて(それ自体もChatGPTで生成できる)、それを入力するという方法を試すと、改善の余地はあるものの、それなりの質疑応答ができるようになった。
自社データをChatGPTに与えて利用する方法が具体的に紹介されており、とても勉強になりました。(先ほど実験してみたように)要約を作るということは、まとめる方次第で落ちてしまう情報が当然出てくるので、一つのソースに対して多様な観点から要約を生成しておく必要があるように感じました。LLMを用いた開発においては、そのあたりのシステム設計が肝になるのだろうという所感を得ました。私は旅行の旅程を自動生成するシステムを研究開発しており、その中で「存在しない乗り換えを案内してしまう」といった課題があるのですが、この記事で紹介されている方法を応用すれば正確な情報を案内するシステムにできるなと感じており、このブログを書き終えたらさっそく試してみたいと思います。
日本語LLMベンチマークと自動プロンプトエンジニアリング
- 執筆企業 株式会社Preferred Networks
- 掲載媒体 自社ブログサイト
記事の内容を下記のように解釈しました。
- 日本語LLMベンチマークにおいても、プロンプトテンプレートは重要な要素となっており、人間には大して意味の差異が感じられないような場合でも、プロンプトテンプレートの差異により精度が大きく異なることがある。
- 今回は、数種類のプロンプトテンプレートを元に、遺伝的アルゴリズムによりテンプレートを交叉・突然変異させていきながら、得られたテンプレートを使ってベンチマーク(StableベンチマークのJCommonSenseQAタスク)の評価を行い、トーナメント戦略で親のテンプレートを選んでいく実験を行う。
- テンプレートの交叉・突然変異自体をLLMに実行させる。
- 結果として、チューニングされたプロンプトテンプレートを使うことでスコアが向上した。
- 評価対象の4つの言語モデルについて、ベースラインのテンプレートに比べ、最適化されたテンプレートは意味が変わっておらず、また、高い精度の示すプロンプトの与え方には共通するパターンが見られた。
LLMの性能にプロンプトが大きな影響を与える旨、概念的にはある程度シンプルな構造でプロンプトの最適化を実行できることがわかり、とても勉強になりました。実際にこのシステムを組んでいくのは難しいかもしれませんが、自分が開発するシステムで高い性能を発揮するためのプロンプトの探求は、自分で実装できるようになりたいですね。
データベース部門
あなたの遅延はどこから? SQLから! 〜患部に止まってすぐ効くSQLレビューチェックリスト 年初め特大サービス号〜
- 執筆企業 株式会社アンドパッド
- 掲載媒体 自社ブログサイト
記事の内容を下記のように解釈しました。
- 「検索のキーにINDEXを使用しているか」といったSQLの書き方に関するチェック項目から、「SQL発行回数がN+1(1+N)の構造になっていないか」といったアプリケーションの設計レベルのチェック項目、そして「大きくSQLが変更される修正の際にはEXPLAINをレビュー内容に加える」といったレビュー時のチェック項目など、合計31ものチェック項目を紹介。
実は弊社も高速検索を得意とするため、書いていらっしゃることは概ね「その通りだなぁ」と感じました。更に実務では記事に書いていらっしゃらないことも含めたチェック項目を用いて品質を追求されているとのことで、真摯に仕事に臨まれている姿勢を同業者として素晴らしいと感じました。
クックパッドの検索反映時間を 1/288 にしたシステム改修
- 執筆企業 クックパッド株式会社
- 掲載媒体 自社ブログサイト
記事の内容を下記のように解釈しました。
- レシピ投稿から検索結果反映迄24時間かかっていたところを5~10分に短縮するプロジェクトを6週間でやり切った。
- 旧システムではレシピ反映は24時間で良いという前提で設計しており、日次バッチによるインデックス更新では、数百万レシピそれぞれに100を超えるfield情報を生成、処理時間は90分程度であった。
- また、旧システムではECSのタスクからSolrを起動する設計になっていたが、その設計からリプレイスする必要があった。
- 新システムでは参照系だけではなく更新系のSolrも常在的に起動し、同期する必要があったが、User-Managed Index Replication の仕組みを利用して "更新系" と "参照系" を組み合わせた Solr cluster を構築した。その際更新系のleader SolrはEFSを利用して永続的ストレージとしながら、参照系のfollwerのSolrは応答速度を重視したtmpfsをストレージに採用した。
- 100を超えるfiledから必要なもののみ選別しつつ、レシピとして不適切なノイズ投稿を排除する必要がある。新システムでは5分毎に定期実行するindex更新時に、MLを用いて不適切な投稿である確率を計算してはじいている。
- 旧システムの日次更新はロールバックが容易でというメリットがあり、セーブポイントを作る機能は残したいと考えた。
- インデックス更新時にキャッシュが阻害しないようにする必要があるが、キャッシュをはがすと負荷増大が懸念される。Prometheus関連ツールを用い、キャッシュのヒット率などを計測しながらキャッシュのTTLを丁寧に5分に短縮していった。
- システムの切り替えにおいては、本番環境のリクエストをミラーリングして負荷試験を行ったのち、実際のリクエストを徐々に新システムに流す割合を高めていき、安全なリリースを実現した。
旧システムの設計及び課題から、新システムの設計まで、非常に細かいレベルで紹介されており、今回調査した開発ブログ約70本の中で最も質の高い記事の一つであると感じました。記載されている内容から、使っておられるシステムは弊社の高速検索システムと非常に近いものであるようです。日次バッチと差分更新など、登場する概念も非常によく似ていますし、インスタンス生成時に日次バッチをベースに生成したインデックスに差分データを一気に適用して最新化してサービスインするという設計は私も実装経験があります。勿論、クックパッドさんは記事検索で全文検索を主とされており、弊社は在庫・料金の複雑な計算を用いた検索でPostgreSQLを主に用いているという違いはあります。もし機会があれば、クックパッドのエンジニアさんと検索システムについて語り合うことが出来たら嬉しいですね。
検索が爆速になるデータベース設計を公開します
- 執筆企業 フォルシア株式会社
- 掲載媒体 Zenn
データベースに関しては、弊社が公開したブログも、はてブとZenn併せて1400のブックマークとハートが付くほどの反響をいただきましたので、この機会にご紹介します。
- 大量のデータを複雑なロジックで処理する領域の高速検索を得意としており、例としては旅行の料金計算・在庫処理などが挙げられる。
- DBMSはPostgreSQLを用い、検索DBの全件再構築と差分更新を組み合わせたライフサイクルをベースに、敢えて非正規化を行う検索専用テーブル、自社開発のデータ型・ユーザ定義関数など、独自技術を駆使している。
高速検索は弊社が20年に渡り大切にしてきた独自技術で、それが多くのエンジニアの方に有益な情報となったのであれば、それはとても喜ばしい事です。
マネジメント・自己成長部門
受身気質な私がリーダーという役割で実践したこと 4選
- 執筆企業 株式会社ログラス
- 掲載媒体 Zenn
記事の内容を下記のように解釈しました。
- ログラスさんにおいてリーダーは役割であり、やり切れば次の人に継承されるものである。
- 週次の1 on 1がベースになっていたが、それでは情報がリーダーのところに偏ってしまうことなど課題に感じた。
- チーム全員で不安を言語化する場をオンデマンドで設けるなどした。
- チームのOKR外のタスクを自分で消化しすぎないようにした。
- 他チームのスクラムイベントに参加したり、全チームが参加してQ単位での取り組みを紹介し合うイベントを企画した。
初めてリーダーをご経験される中で、様々に工夫をしながら奮闘されている様子が伝わってきました。私も2年目から後輩を教育し始め、3年目の頃には複数のエンジニアの面倒をみる役割を担っておりましたので、当時の仲間たちとの冒険を懐かしく感じました。タイトルに受け身と書いていらっしゃいますが、前のリーダーとは異なる手法をいくつも試されており、とても主体的に取り組まれているようで素晴らしいと感じました。
配慮のできないエンジニアとの付き合い方
- 執筆企業 株式会社ゆめみ
- 掲載媒体 Qiita
記事の内容を下記のように解釈しました。
- 執筆者さんはかつて、正論であると思えば周囲へ配慮をせずにズバズバと言ってきた。
- しかし、それにより職場の人間関係を破壊してしまうことがあり、そのような自分を後ろに下げるようにした。(これをユング心理学ではシャドーという)
- 社内にはかつての自分のようにズバズバとものを言うエンジニアがおり、それをけしからんと感じる。(これをユング心理学ではシャドーの投影という)
- 現在の執筆者さんは言うべきことが言えない忖度おじさんになっており、ズバズバ言えることにも本当は価値があり、使い分けができるハイブリッドおじさんになっていく必要がある(これをユング心理学ではシャドーの統合という)
- 過去の自分を許し、目の前の相手も公正に評価していきたい。
社会人として経験を深める中で自己を省みてありさまを更新していく姿勢、素晴らしいと感じました。シャドーやシャドーの統合という言葉は勉強不足で存じ上げず、大変勉強になりました。また、執筆者さんの娘さんは7歳にして既に人生を達観しているようで、将来がとても楽しみですね。
会議全部ふっとばして社員の集中力を10xした話(ビッグバン)
- 執筆企業 株式会社10X
- 掲載媒体 Hatena Blog
記事の内容を下記のように解釈しました。
- 10Xさんではドキュメントの文化とSlack/Notionを用いた非同期コミュニケーションが根付いているが、人数が増えるにつれ同期コミュニケーション(会議)が増えたことに見直しの必要性を感じた。
- 集中した時間を確保するために、No MTG Dayという1年前に導入した制度があり、少なくとも5日のうち半日は集中して取り組める時間を確保していることは社内で評判が良い。週次の全社会議の後に半日で設定したことも、振り返ってみると良かった。
- 更なる改善として、まずは会議に使っている時間のデータを作成、誰がどの程度の時間を使っているかを公開する。
- 事前調査から、会議開催のルール(オーナーの役割や責任の明確化、参加者の心構えの定義)を設け、会議の実施量を可視化し経過を観察する仕組みを作る必要があるという仮説を持ったうえでヒアリングを実施する。
- ヒアリングから、ライン外1on1の多さを課題として認識。
- ライン外1on1の多さについては、定例化して無期限に繰り返すのをやめ、単発の1on1は良しとしつつも、極力人が集まっている場で情報交換を行うことを推奨。
- 会議開催のルールを全体のルール、及び会議オーナー向けと参加者向けの詳細という3つのレベルで作成。
- 会議や1on1を設ける際の思考フローを図示し、新たに生まれる会議の増殖を抑える。
- そのうえで、あるタイミングでカレンダーの予定(社外との打ち合わせなどは除く)をすべて削除。これをビッグバンと呼ぶ。
- ビッグバン後1週間で15%程度の会議総量の減少を確認。特にライン外1on1は60%も減少。
こちらは狭義の技術ブログではないですが、開発のためのまとまった時間を如何に作り出していくかというのはきっと多くのエンジニアの関心事項でしょうから、学ぶべきところが多い記事であると考えています。集団としての生産性向上のために今注力すべき課題を言語化し、定量的なデータを用いて事前調査や効果測定を行いながら、既存の会議をすべて削除し、新ルールを強制的に適用するところまでやり切られているところが素晴らしく、見習っていきたいと感じました。
周りのすごい人と比較してしまう時などに良かった思考の整理法を紹介します
- 執筆企業 クラスメソッド株式会社
- 掲載媒体 Developers IO

記事の内容を下記のように解釈しました。
- 優秀な同僚と自分の比較や、社会での急速な技術の進歩に対して悩んだり不安を感じることがある。
- A4の紙に1分間で思いつく限りの気持ちを書き、書いた内容からテーマを切り出して更に1分と深堀りしていく。
- 自分でスッキリしたと感じるまで繰り返す。
- 最終的に、自分にできることに話を落とし込む。
不安や疑念に対して、言語化によって克服していくという方法論はその通りだなと感じました。私の場合、採用、事業開発A、事業開発Bという3本立てで業務を行っている都合、どれかに注力すれば別のどれかがおざなりになってしまうことが多々あり、解決できていない課題に対する不安(不満の方が近いかもしれません)を感じることが時々あります。そのような際には、現状の業務モデル(業務時間の使い方の内訳)を図示したり、未解決課題のtodoをひたすら言語化をしていきながらtodoを再定義し、新しい業務モデルに落とし込むことで解決の筋道を見出しています。
その他開発技術部門
BtoBプロダクトをシンプルに保つ「名前をつけない」UXライティング
- 執筆企業 株式会社ログラス
- 掲載媒体 note
記事の内容を下記のように解釈しました。
- BtoBのシステム開発にあたり、業界用語や複雑な業務フローが頻出するため、社内では開発コミュニケーション(社内ワード)を使って簡略化して会話をすることがある。
- 社内ワードの言葉の影響を受けたUI(ボタンに書く文字など)を作ってしまうことがあるが、開発者とユーザーは認知領域に違いがあるため、社内ワードはサービス(システム)のユーザーにはなかなか理解されない。
- 具体的には、似た意味の横文字を複数使ってしまう(インポートとアップロードの差は何かユーザーにはわからない)、造語を作ってしまう(カスタムファイルなど)という例が挙げられる。
- これに対し、あえて名称を付けず、たとえば「新しく〇〇✗✗(機能名前)がリリースされました」よりも「〇〇で✗✗が出来るようになりました」という表現を使うとよい。
勝手に造語を作って概念化するということは私自身やりがちで、あとになってその言葉の表現のあいまいさに気が付くことがあります。一方で、社内コミュニケーションにおいては、一定造語を作って概念化することも必要ではないかという気もして、悩ましいところですね。。。造語を作ったときは、その言葉が何を意味するのか、少なくとも広辞苑的に定義を残すべきかもしれません。
packelyze - お前の TypeScript はもっと小さくなる
- 執筆企業 株式会社プレイド
- 掲載媒体 Zenn
記事の内容を下記のように解釈しました。
- TypeScriptで書かれたコードは、terserのような一般的なMinifyツールで一定の圧縮がされるが、型情報を使うことでより圧縮することができるようなモジュールを開発した。
- まず、コードベースの型定義ファイルを生成し、それを入力として解析結果をjson形式で吐き出す。
- そのjsonをtersermangle.properties.reservedに渡す際に、最も積極的にmangleするようなオプションを指定する。
- exportされた公開インターフェース以外を圧縮対象とし、コードサイズの削減が可能である。
- 外部に渡すオブジェクトの内部キーがmangleされてはいけないので、そうならないように export typeをする必要がある。
- 安全性の確認のために、内部オブジェクトを対象にsnapshotが一致するかをテストする仕組みをvitestを用いて作成した。
- 内部実装としては、rollup-plugin-dts という rollupのプラグインを活用しつつ、公開インターフェースの切り出しを実装した。
主にフロントエンドでの読み込み高速化のため、ストイックなコード圧縮を試みたということで、探究心が素晴らしいと感じました。また、この試みは業務時間中に行われたということで、最終的に業務で使っていらっしゃるのかどうかは定かではありませんが、うまくいくかどうかわからないことも試行錯誤をする時間が業務時間に設計されているのであれば、組織として見習いたい考えであると感じました。
書き手の意図やコードの背景を残す方法のあれこれ −きれいなコードの次に意識すべきこと−
- 執筆企業 株式会社ソニックガーデン
- 掲載媒体 Hatena Blog

記事の内容を下記のように解釈しました。
- きれいなコードを書くことはいつでも大事だが、きれいなコード「だけ」では大きなコードを理解しやすく書けていることにならない。
- 未来の開発メンバー(未来の自分自身を含む)に、なぜこんな仕様にしたのか、なぜこんなコードを書いたのか、という意図や背景を残すことが大事である。
- コードはテストコードとセットで書き、RSpecのitやcontextをしっかりと書き、書ききれない時は別途コメントを書いても良い。
- コードが産まれた背景を後の人が確認する際に git blameで極力必要な情報のみ参照できるよう、blameしやすい単位でコミットする。
- 開発チケットへのリンクをコミットメッセージに記載する。
- 他の人が読んでわかりにくいコードにはコメントを付けるか、場合によれば解説ドキュメントのリンクをコメントとして載せる。
- コード説明会を開いてその録画リンクを載せることもある。
ソースコードを長く運用するにあたって、開発時の意図を知りたいことはしばしばありますよね。私もコミットメッセージやコメントで開発時に作成したドキュメントのリンクを記載したり、コミットを小さくして差分が大量に出ないように心がけていますが、Blameしやすい単位でコミットする、ということまでは意識できておらず、新しい考え方を得ることができました。特に、Pythonのndarrayの操作などは何をしたいのかわかりにくくなることがある印象で、概念的なイメージ図などを開発者が残してくれているのといないのとで理解のスピードはだいぶ違うように思います。
VSCode のおすすめ拡張機能 2023年度版
- 執筆企業 株式会社ゆめみ
- 掲載媒体 Zenn
記事の内容を下記のように解釈しました。
- 汎用的な拡張機能としてBracketLensやChangeCase、Web 開発に特化した拡張機能としてStorybookOpenerやAutoRenameTagなど、合計30もの拡張を紹介。
記事が公開されたのは23年12月4日とつい先日で、数日の間に非常に多くの方が読んでいらっしゃるようです。執筆者さんは23卒入社のまだ1年目の方のようですが、技術を高めるために日々学ばれている様子が目に浮かび、素晴らしいと感じました。
まとめ
見落としていた良記事をテーマにご紹介してきましたが、いかがでしたでしょうか?ぼちぼち年末年始のお休みになりますし、見つけたけれどまだ読んでいなかった記事を読んでみたいと思います。皆さんも、気になっているけどまだ読んでいない記事などありましたら、頑張って読んでみてください。
あと、最後にちょっとだけ宣伝させてください。
弊社の記事「検索が爆速になるデータベース設計を公開します」ですが、記事に書いているのは高速検索技術の一端であり、技術的に最も面白い部分は実は記事には書いていないのです。
そのあたりの話も聞いてみたいよという方は、私が担当しているカジュアル面談に是非いらっしゃってください!
高速検索の話は勿論、私がベンチャー企業で11年働く中で行ってきた教育や採用の仕組みづくりの話や、弊社の旅行SaaSの開発秘話などご興味に応じてお話しさせていただきます。
カジュアル面談のエントリーは―下記よりお申込みください。
https://calendar.app.google/KrLVgCKiEXXLhBfR6
この記事を書いた人
西海 知洋
2013年フォルシアに新卒入社、以降フルスタックエンジニアとして、旅行のホテル横断サイトや福利厚生サイトの開発・運用に従事。現在は自ら企画・開発した「旅程自動生成システム」と、「AI画像認識」の2つの事業開発を行いながら、エンジニア採用の全体設計・運用に取り組む。

/assets/images/9126337/original/5e0c6e3b-d26d-478d-b5e5-b73d413532ff?1648168629)
/assets/images/17294050/original/5e0c6e3b-d26d-478d-b5e5-b73d413532ff?1710328813)


