![]()
はじめに
こんにちは、豆蔵IT戦略支援事業部の時と申します。私の部署では、データ分析やAI・機械学習を活用した案件を扱っています。
データ分析ではデータから有用な知識を得ることにより、様々なビジネスの問題を解決できます。例えば購買履歴を分析することで、お客様がどの商品をどのように好んでいるかについての知識が得られ、商品をより有効に販売する施策が立てられます。
データから知識を得る手法として統計学と機械学習がよく挙げられています。今回はデータ分析の事始めとして、統計学と機械学習の違いについて簡単に紹介したいと思います。
統計学と機械学習の違い
統計学は「データの説明」に、機械学習は「データの予測」に重きを置いていると言えます。この違いはデータ分析を行う側にとって大きな違いであり、使い方を間違ってしまうと、データから有用な知識を得られない可能性があります。
そのため、どんな目的で、どんなことをしたくて、どのようにデータを集めるのかなどを考えてから、手法を決めることが必要となります。
両者がどんなイメージで使用されているのか、統計学による「データの説明」と機械学習による「データの予測」について概要と使用例をご紹介します。
統計学について
従来のデータ分析では統計学(Statistics)が使用されてきました。統計学は大きく分けて、記述統計と推測統計の2種類があります。
記述統計では、平均や分散、度数分布などから、集めたデータの特徴や傾向を把握します。
例えば各地域の店舗売り上げの平均を計算することで、地域による商品販売の特徴が分かります。
推測統計では、推定や仮説検定によって、標本データ(集めたデータ)から母集団(本来存在するすべてのデータ)の特徴を推測します。すべてのデータ(例えば全日本人のデータ)を集めるのが難しい場合に使われます。仮説検定では、標本データで観測された特徴が偶然ではなく、母集団でもその特徴があるといえるかどうかを調べることができます。
例えばマーケティングにおいて、アンケート調査で商品Aの方が商品Bよりも好まれるというデータが得られた場合には、1回の調査でたまたま差が見られたのではなく、母集団でも(例えば全日本人にアンケート調査しても)商品Aが商品Bよりも好まれることを仮説検定で検証することが可能です。
![]()
複数の変数間の関連性を明らかにしたい場合は相関分析や回帰分析を使います。相関分析によって、2つのデータの間に何らかの関係があるかどうかが分かります。また回帰分析によって、複数の変数の間に因果関係があるかどうかが分かります。
例えば、室内の気温がアイスの売上の増減に対して影響しているかどうかを回帰分析で調べることが可能です。さらに回帰分析では変数間の因果関係を表した式(モデル)が求められるので、例えば室内の気温からアイスの売上を予測するように、モデルを使って未来の新しいデータを予測することも可能です。
他にも、教育分野では偏差値の算出、マーケティング分野ではA/Bテストの分析、医療分野では新薬の有効性の判断などで統計学が利用されています。
統計学は集めたデータおよびその背後にある母集団に対して、その特徴や性質を明らかにしたい場合に有効な手法です。言い換えると、業務などで発生したデータから特徴や性質を読み取って、方針や課題解決の裏付けの説明に使うことができます(例:アンケートで商品Aが好まれているから、商品Aを売ろう)。
回帰分析などを使ってデータを予測することも可能ですが、説明の根拠を求める場合により役立つ手法となります。
「データの説明に使う」ということをイメージしていただけたでしょうか。
機械学習について
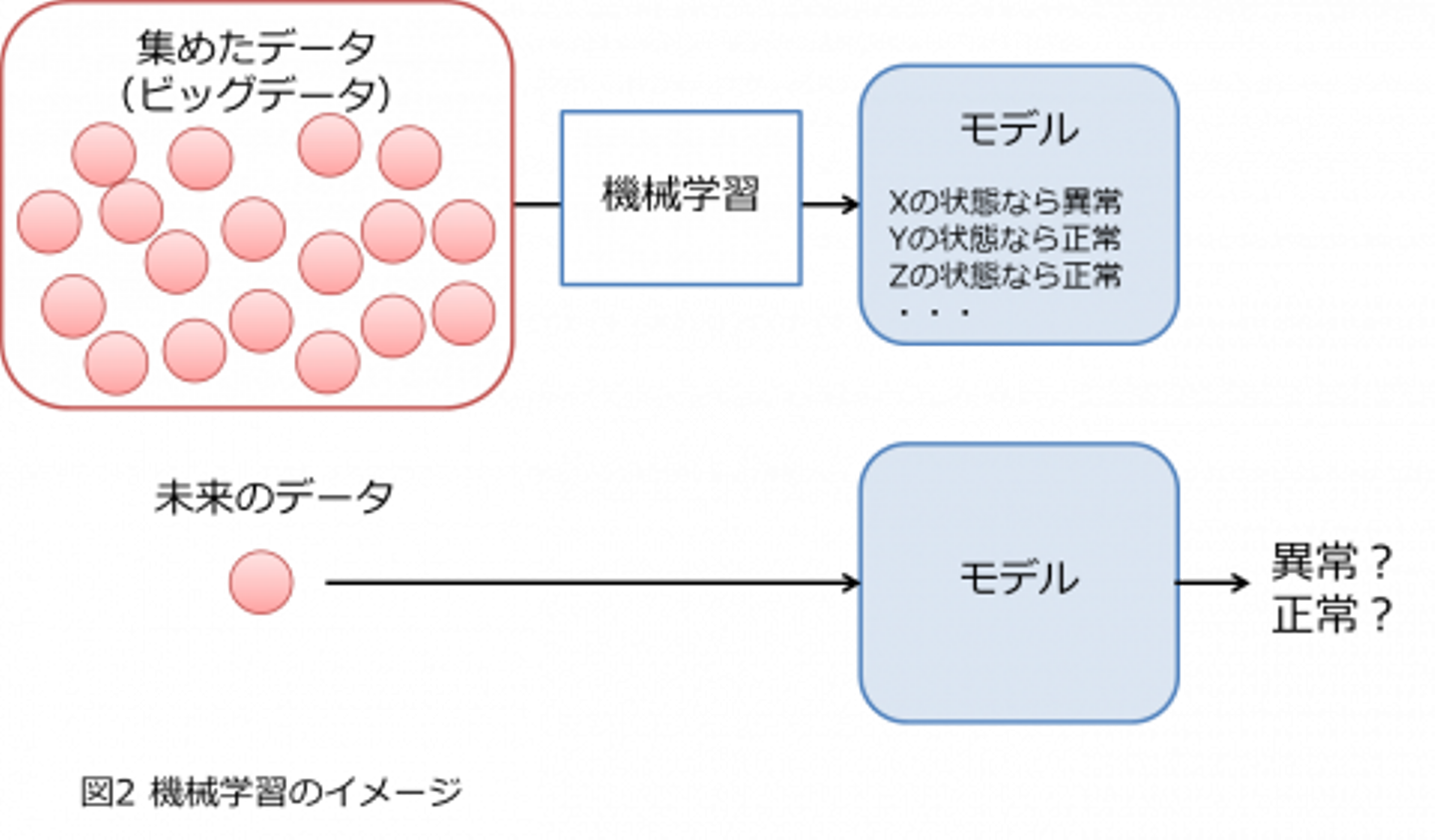
データ分析の手法として、機械学習(Machine Learning)を耳にすることも多いと思います。機械学習は、すでに集めたデータからデータの特徴を学習してモデル化し、そのモデルを使って未来の新しいデータを予測したり、分類したりすることが可能です。
例えば迷惑メールの振り分け結果を学習させることで、新たなメールが来た場合にそのメールが迷惑メールかどうかを分類することができます。
近年はデータの蓄積・加工技術が向上したことで、ビッグデータの分析が可能となりました。
ビッグデータは量が多く、様々な種類のデータ(テキスト、画像、音声など)を持ち、かつリアルタイムで生成されていくデータです。大量のデータかつ目的に合ったデータが必要な機械学習にとって、ビッグデータの登場で活用できる場面が増えています。
例えば、工場で稼働する製造機器の異常を検知したい場合に、機械学習を使って今までの製造機器の状態を学習し、リアルタイムで流れてくる製造機器の状態(例えば温度や振動数など)が異常であるかどうかを識別します。
他にも、レコメンドや購買行動の予測、画像認識、音声認識など様々なところで機械学習が利用されています。
![]()
機械学習は集めたデータを学習することで、未来のデータに対して何らかの判断(予測や識別)をしたい場合に有用な手法です。言い換えると、業務などで発生した様々なデータからパターンを見つけてモデル化し、新しいデータに対して自動で判断することができます。(例:モデルによると今の製造機器の状態に、異常が起きている。)
「データの予測に使う」というイメージを持っていただけたでしょうか。
おわりに
以上のように手法の違いはありますが、どんなことをしたくて、どんな目的でデータを使うのかについて考えを持っていただければ、それに合う手法が見つかると思います。
※転載元の情報は上記執筆時点の情報です。
上記執筆後に転載元の情報が修正されることがあります。




/assets/images/6899879/original/2fcf17aa-4638-4b0f-bc0f-f2f8122b147d?1622699171)
/assets/images/6756250/original/4bfb75e2-33cb-4789-8c8d-2648546016b4?1621923439)


