はじめに
今回、Google の Gemini 2.5 Flash Preview TTS モデルを使って、感情豊かなボイスチャットアプリを作ってみました。
このモデルの面白いところは、**プロンプトで音声の読み方(トーン・感情)を指定できる**という点。従来の TTS は「テキストを読み上げる」だけでしたが、Gemini TTS では「笑いながら読んで」「怒って読んで」といった演技指導ができます。
めちゃめちゃ怒られました。ほんとすみませんでした。
本記事では、実際にボイスチャットアプリを構築しながら、この「演技指導」機能を検証した結果をお伝えします。
gemini-2.5-flash-preview-tts とは
gemini-2.5-flash-preview-tts は、Google が提供する Text-to-Speech モデルです。
従来の TTS との違い
- 感情表現
- OpenAI TTS(gpt-4o-mini-tts):プロンプトで指定可能だが限定的
- Gemini 2.5 Flash Preview TTS:プロンプトで指定可能
- カスタマイズ
- OpenAI TTS(gpt-4o-mini-tts):instructions パラメータで指示
- Gemini 2.5 Flash Preview TTS:テキスト冒頭に演技指示を記述
- 音声プリセット
- OpenAI TTS(gpt-4o-mini-tts):13 種類
- Gemini 2.5 Flash Preview TTS:30 種類(男性 16 種 / 女性 14 種)
- 出力形式
- OpenAI TTS(gpt-4o-mini-tts):mp3, opus, aac, flac, wav, pcm
- Gemini 2.5 Flash Preview TTS:PCM(24kHz / 16bit / mono)
- 最大入力長
- OpenAI TTS(gpt-4o-mini-tts):4,096 文字
- Gemini 2.5 Flash Preview TTS:制限なし(実用上 500 文字推奨)
利用可能なボイス
男性・女性それぞれ多様なキャラクターの声が用意されています。
- 男性ボイス(16 種類): Puck, Charon, Fenrir, Achird, Zubenelgenubi, Algieba, Alnilam, Orus, Enceladus, Iapetus, Umbriel, Algenib, Rasalgethi, Schedar, Sadachbia, Sadaltager
- 女性ボイス(14 種類): Zephyr, Kore, Leda, Aoede, Callirrhoe, Autonoe, Despina, Erinome, Gacrux, Laomedeia, Achernar, Pulcherrima, Vindemiatrix, Sulafat
30 種類もあるのはありがたいですね。今回は男性ボイスの `Zubenelgenubi`(カジュアル、リラックス)を使用しました。
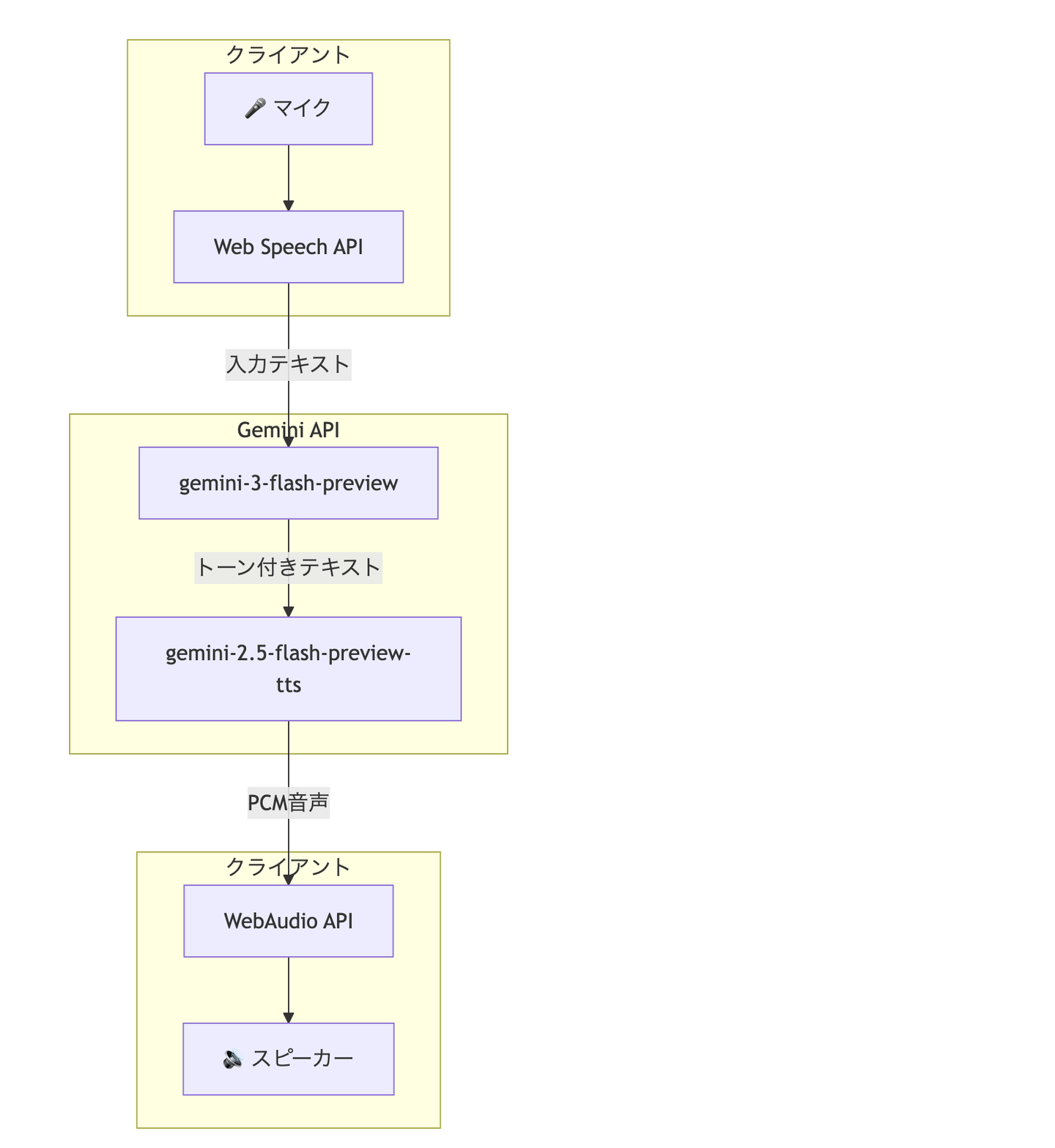
アーキテクチャ全体像
今回構築したボイスチャットアプリのアーキテクチャは以下の通りです。
![]()
処理フロー
- 音声入力: ユーザーの発話を Web Speech API で認識・テキスト化
- テキスト生成: gemini-3-flash-preview でトーンを加味した応答文を生成
- 音声合成: gemini-2.5-flash-preview-tts でトーンを加味した音声を生成
- 音声再生: WebAudio API で PCM データを再生
シンプルな構成ですが、ポイントは「テキスト生成」と「音声合成」の両方でトーンを制御しているところです。
実装のポイント
TTS API の呼び出し方
Gemini TTS API を呼び出す際のポイントは以下の 2 点です。
- responseModalities: ['AUDIO'] を指定してオーディオ出力を要求
- speechConfig でボイスを指定
const response = await ai.models.generateContent({
model: "gemini-2.5-flash-preview-tts",
contents: [{ parts: [{ text: "読み上げてほしいテキスト" }] }],
config: {
responseModalities: ["AUDIO"],
speechConfig: {
voiceConfig: {
prebuiltVoiceConfig: { voiceName: "Zubenelgenubi" },
},
},
},
});
レスポンスは Base64 エンコードされた 24kHz/16bit mono の PCM データで返ってきます。
トーン(感情)制御の二段構え
今回のアプリでは、テキスト生成時 と 音声生成時 の両方でトーンを制御しています。
◼︎なぜ二段構えなのか?
- テキスト生成時: 文章の語尾や表現をトーンに合わせて調整(日本語)
- 音声生成時: 実際の読み方・声色をトーンに合わせて調整(英語プロンプト)
この二段構えにより、テキストの内容と音声の表現が一貫した感情表現になります。TTS への指示だけだと「文章は普通なのに声だけ怒ってる」みたいな違和感が出てしまいます。
◼︎使用しているプロンプト
テキスト生成用プロンプト(日本語)
default:
# 話し方のスタイル
- 温かみのある親しみやすい口調で話してください
happy:
# 話し方のスタイル
- 明るく楽しそうな口調で話してください
- 文末に「!」を使って元気さを出してください
sad:
# 話し方のスタイル
- 悲しそうな口調で話してください
- 文末に「...」を使って余韻を出してください
angry:
# 話し方のスタイル
- 怒りを込めた強い口調で話してください
- 文末に「!」を使って語気の強さを出してください
sarcastic:
# 話し方のスタイル
- 皮肉っぽく嫌味な口調で話してください
- 見下すようなニュアンスを語尾に込めてください
音声生成用プロンプト(英語)
default:
Read aloud in a warm and friendly tone:
happy:
Read aloud in a very cheerful, laughing, and joyful voice as if you are extremely happy and cannot contain your laughter:
sad:
Read aloud in a very sad, tearful, and sobbing voice as if you are crying deeply:
angry:
Read aloud in a very angry, frustrated, and aggressive voice as if you are furious and shouting:
sarcastic:
Read aloud in a condescending, sarcastic, and snide voice with a mocking tone as if you think you are better than everyone else:
こんな感じで、テキスト生成では日本語で口調を指示し、TTS では英語で読み方を詳細に指示しています。
工夫した点・ハマった点
工夫した点
1. 原稿作成からトーンを加味
前述の通り、TTS への演技指導だけでなく、テキスト生成の段階からトーンを反映させました。
例えば「悲しんでいる」トーンを選択すると:
- テキスト生成時: 文末に「...」を使った余韻のある文章を生成
- 音声生成時: 泣きそうな声で読み上げ
これにより、文章の内容と声のトーンが一致し、より自然な感情表現が実現できました。
2. プッシュ・トゥ・トーク方式の採用
常時マイクをオンにする方式ではなく、**スペースキー長押しで発話する**プッシュ・トゥ・トーク方式を採用しました。
理由は以下の通りです:
- ノイズの誤検知防止: 環境音や独り言を拾ってしまう問題を回避
- 意図しない会話の防止: ユーザーが明示的に話しかけたい時だけ認識
- レイテンシの体感改善: 発話終了のタイミングが明確になり、待ち時間が気になりにくい
常時リスニングだと、環境音や自身の発生を拾って勝手に応答し始めてしまいました、、。それを防ぐためにプッシュ・トゥ・トークにしました。
3. テキスト長の制限
TTS API の安定性向上のため、テキストを 500 文字に制限しています。長すぎるテキストは途中で切り、「...」を付加して自然に聞こえるようにしました。
ハマった点
日本語プロンプトでの精度問題
当初、TTS API への演技指導も日本語で行っていました。
❌ 「笑いながら楽しそうに読んでください」
しかし、日本語プロンプトでは思ったようなトーン制御ができませんでした。感情の変化が薄かったり、指示が無視されることがあって、なかなか安定しませんでした。
解決策: 英語プロンプトに切り替え
✅ "Read aloud in a very cheerful, laughing, and joyful voice as if you are extremely happy and cannot contain your laughter:"
英語で詳細に指示することで、期待通りの感情表現が得られるようになりました。特に `as if you are...` のように具体的なシチュエーションを描写すると効果的でした。
まとめ
Gemini 2.5 Flash Preview TTS を使って、感情表現が可能なボイスチャットアプリを構築しました。
検証結果
- 演技指導は有効: 英語プロンプトで詳細に指示すれば、笑い声や怒り声など、様々なトーンで読み上げてくれる
- 二段構えが効果的: テキスト生成と音声生成の両方でトーンを制御することで、一貫した感情表現が可能
- 日本語プロンプトは課題あり: 現時点では英語プロンプトの方が精度が高い
今後の可能性
- キャラクター AI との組み合わせ(喜怒哀楽のある対話)
- ナレーション・朗読アプリ(場面に応じた感情表現)
- 教育コンテンツ(感情を込めた説明)
Gemini TTS の「演技指導」機能は、従来の TTS にはない表現力を持っています。まだ Preview 版ですが、今後の進化が楽しみです 🙏
参考

/assets/images/22662369/original/1fbbc184-09b1-4b92-9925-e0c80625cba1?1765255298)

/assets/images/23434746/original/dd41a3f5-61d3-4b06-930d-ca47f7ecb419?1775036408)


/assets/images/23434746/original/dd41a3f5-61d3-4b06-930d-ca47f7ecb419?1775036408)


