/assets/images/4298867/original/660614d5-392c-46fc-9884-7aab50ba6fcc?1574300883)
株式会社プラスアルファ・コンサルティング's job postings
- 人事(採用担当)
- 26新卒(コンサルタント職)
- 26新卒(開発職)
- Other occupations (7)
- Development
- Business
- Other

「そろそろアレ買わないとなぁ」
スマホチラッ
「絶妙なタイミングでアプリの通知が来てる……こわっ……でもポチッちゃう……」
ポチー
場面は変わって、その1ヶ月前、"アレ"を販売する企業のEC(通販)マーケティング部にて・・・
「"アレ"、売れ行きは好調なんだけど、今一歩ターゲットにしてるお客さんに刺さりきってない感じがあるんだよなぁ」
「原因はいろいろありそうだけど、通知のタイミングが悪いから埋もれちゃって、うちが"アレ"を売り出したことを知ってもらえていないとかあるかもしれない」
「同じ時間に一斉通知するのはやめて、気味悪がられるかもしれないけど、一人ひとりスマホを見そうなタイミングに通知を飛ばしたい!できれば通知飛ばすべき時間とかも自動分類したい!」
「よし。決定木に相談だ!」
カスタマーリングス事業部で開発をやっています。油山です。
というわけでこの記事は、マーケティングの分析・予測の手法として、決定木とその派生手法について4回に渡って紹介する記事のその2です。実際に決定木に相談してみる回です。
図1: マーケターが木を植えた結果、色々上手くいく様子を表した図
この一連の記事は決定木について、「どこでどう使うのか」「結果はどう解釈できるのか」「実践的にはどう使われているのか」を紹介するもので、次の内容から構成されます。
弊社のカスタマーリングスでも実際に、メールなどの配信の際に最も開封・既読されやすいタイミングを顧客1人1人に対して予測して、この記事のタイトルのような気味悪いけれどなんだかんだ嬉しいことをする機能などに、決定木の派生手法であるGBDTが応用されています。
そもそも決定木とはなんでしょうか。
前回の記事の後ろの方にちょろっと出てきましたが、何かを入力し、それに対して2択の質問を繰り返していくことで分類を行うような機械学習モデルです。
イマイチよくわからないですね。具体例を用意したので、それを見てみましょう。
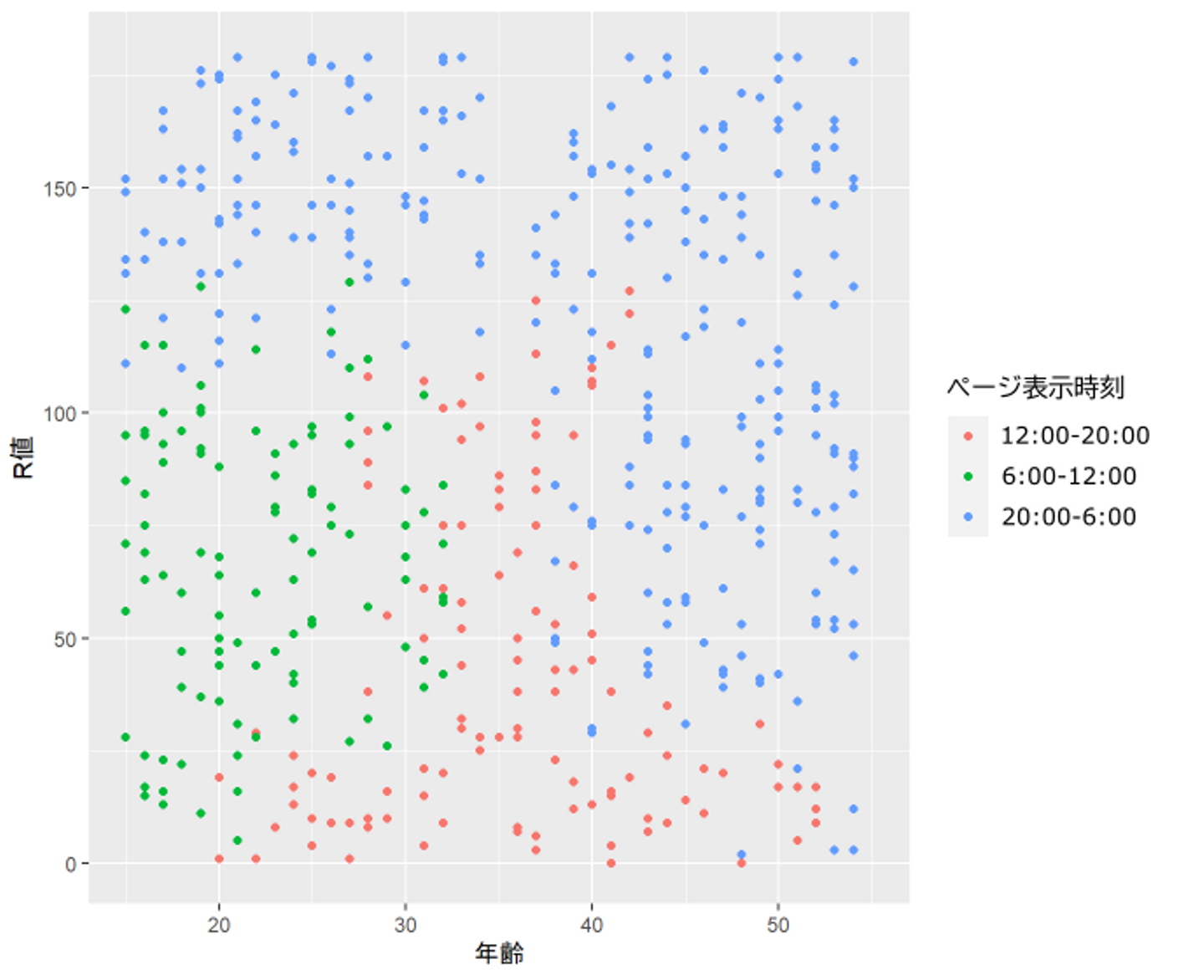
冒頭に登場した、"アレ"を販売する企業が、ユーザがいつ"アレ"の商品ページを表示したかというデータを、次の図2のような形で持っているとします。これは500人のユーザのデータからなるものです。
※ これは説明用に、2軸だけでキレイに分離されるように作った、ありえないデータです。もちろんこの結果から現実に応用できる知見はありません。
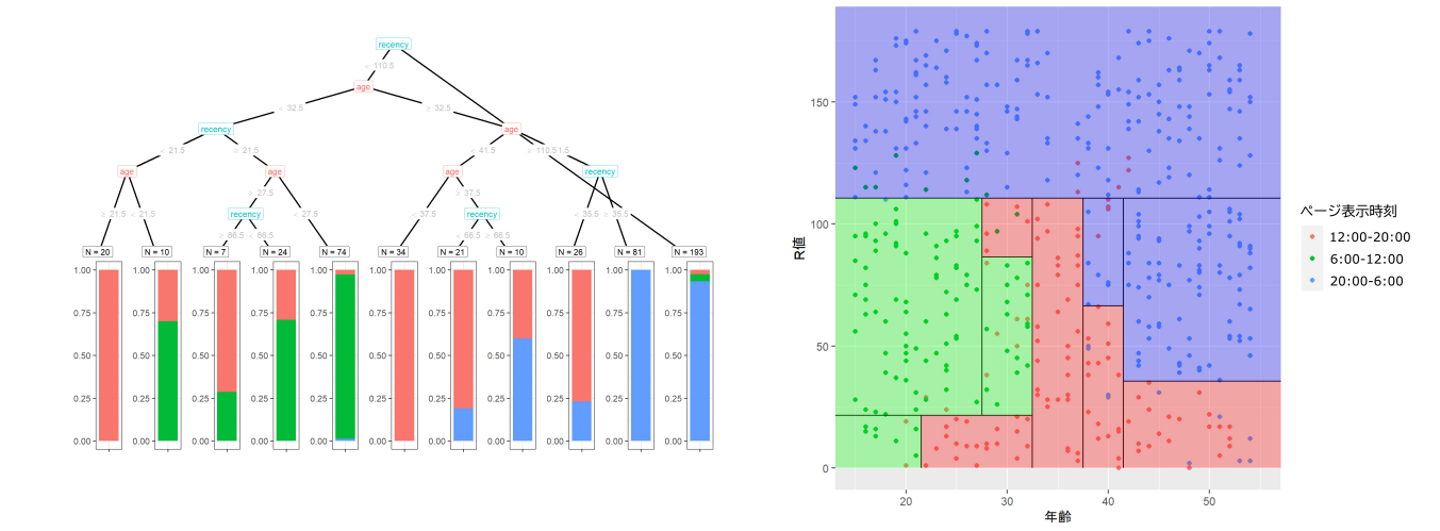
図2: ユーザが、いつ"アレ"という商品のページを表示したかを、年齢とR値という軸でプロットした散布図
※ 現実の結果が、この軸でこんなにキレイに分かれる形になることはまずありえません。赤青緑の点はもっと混ざり合っていることでしょう。しつこいようですが、このデータは決定木がどういうもので、その結果をどう解釈するかの説明のために作られた大嘘データです。
1つ1つの点はユーザを表しています。赤い点が、12:00-20:00の昼からゴールデンタイムにかけての午後にページを表示したユーザ、緑の点が6:00-12:00の午前中にページを表示したユーザ、青い点が、20:00-6:00の深夜から早朝にかけてページを表示したユーザを表します。
横軸は年齢、縦軸はR値(前回の購入からの日数のこと。英語で言うとRecencyで、RFM分析という、なぜかマーケティング界で主要な地位にある分析の構成要素)です。
ちなみにここで軸と呼んでいるものは特徴量と同義です。説明変数と言ってもいいです。
※ どうせありえない大嘘データなので、軸には、実際の分析によく使われるようなものを用いています。かなり不自然なデータに見えると思いますが、それはご愛嬌ということで。。。
このデータをもとに、"アレ"の商品ページを、午前中 / 午後 / 深夜帯にそれぞれ閲覧しやすいユーザの特徴を見つけ、それに基づいて各ユーザに通知を飛ばす時間帯を決めることを考えます。
ではその特徴をどうやって見つけるのか。そこで出てくるのが決定木です。
モデルとして決定木を用意し、教師データとしてこのデータを食わせて、モデルをチューニングした結果、ユーザの特徴がモデルに反映されるという寸法です。(前回の記事の後ろの方でこのあたりの言葉を紹介しています。あるいはググった方が早いかもです)
この節の冒頭にも書きましたが、決定木は入力に対して2択の質問を繰り返すことで分類を行います。
図2では、赤緑青の点は比較的キレイに分かれているので、パッと見でこんな2択を組み合わせるとうまく分類できそうだというのが、なんとなく見えてくる人もいるのではないでしょうか。
ということで、このデータをもとに決定木を作成してみました。その結果が次の図3です。
※ 決定木を作成するツールは多くあります。PythonやJuliaやRといったスクリプト言語ならば簡単にパッケージが見つかります。この記事では、Rのrpartパッケージで決定木を作成し、ggpartyパッケージで図として出力しています。
※ 決定木の生成アルゴリズム(どうやって作成するか)については、いつか上げる続編で紹介予定です。
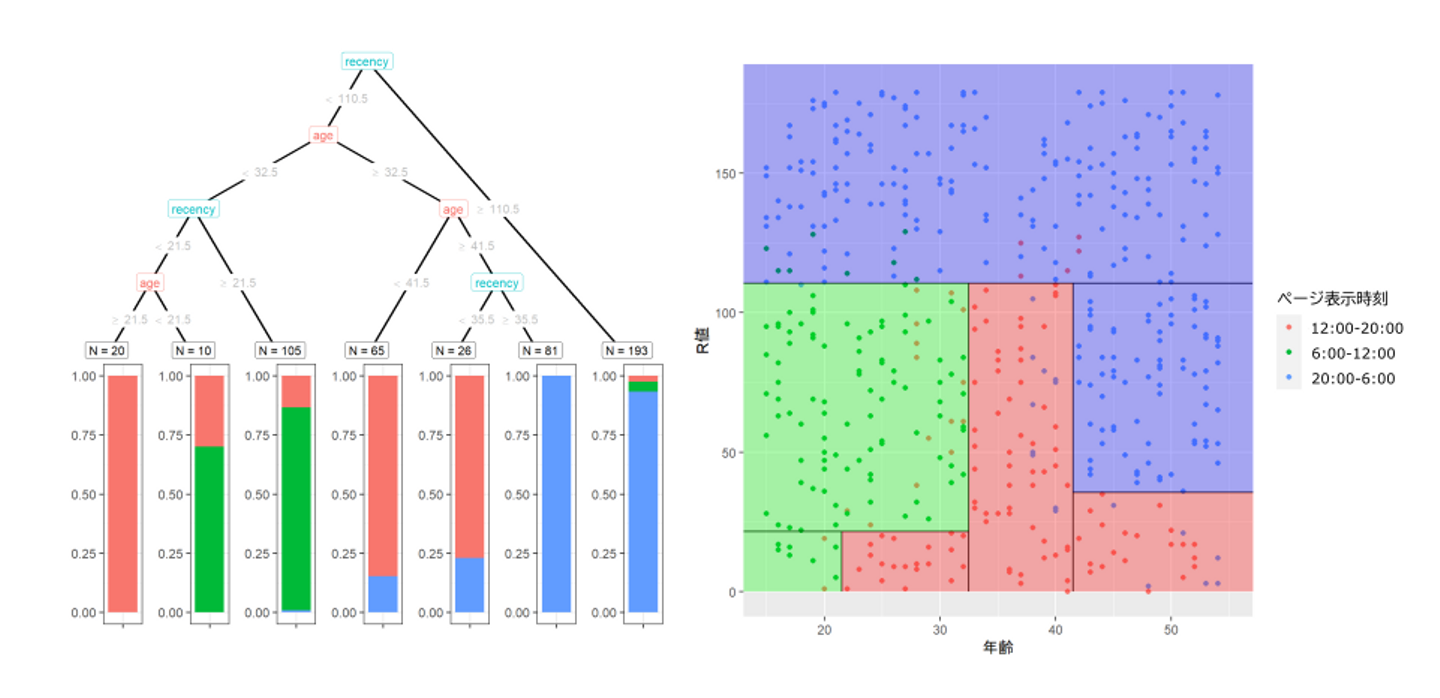
図3: "アレ"の商品ページの表示時刻のデータから、年齢とR値を軸にして決定木を作成。左図が決定木で、右図はその分類を散布図に重ね合わせたもの
図3の左の図が決定木です。
決定木は2択の質問を繰り返すことで分類を行うと書きましたが、例えば、年齢が25歳でR値(前回購入からの日数)が30日であるユーザだと、
というように分類されます。
ちなみに決定木の一番下(”葉”と呼ばれます)にある縦帯グラフですが、これは決定木を作る際に参考にしたデータ(この例では企業がもともと持っていたデータ)全てに対して分類をした場合の内訳です。左から3番目のグループであれば、全体500人のうち105人にここに属し、その内訳として、午前中の緑が8割強を、午後の赤が残りの1割強を占めていることになります。
先の例の通り、決定木にユーザのデータを入力すると、決定木は上から順に2択の質問を繰り返し、最終的にどの分類に入るかを決めてくれるという挙動をします。
図の上下をひっくり返すと、決定”木”という名前の由来もよくわかるのではないでしょうか?(一番上は”根”と呼ばれます)
図3の右は、決定木によってユーザがどう分類されるかを表したものです。
決定木の分類を解釈してみましょう。(何度でも書きますが、これは説明用に作ったデータで、現実にはありえないようなデータにしていますし、この結果から現実に応用できる知見はありません。かつ、もともと違う設定でデータを作っていたので解釈もだいぶ不自然です。)
データがだいぶ不自然で苦しいので変な解釈にはなっていますが、無理やり日常のシーンと紐づけるのであれば、30代前半くらいまでの層は、朝の通学通勤中にページを表示しており、特に直近で買い物したユーザは、午後に気になって閲覧しているのかもしれない。といったことが読み取れそうです。
ということで、
通知を飛ばすと、埋もれずに見てもらえる確率が上がるということになります。
このように、決定木は何かを分類する機械学習モデルでありながら、人の目に解釈しやすいという特徴があります。
※ 今回はラベルは緑赤青の3種類でしたが、だいぶざっくりしていたのでもっと細かく分けた方がいいかもしれません。ただ細かく分けた結果、1つ1つを構成するデータ数が少なくなってしまうと、ロクでもないモデルになってしまうので注意が必要です。
※ 今回は散布図の時点で分類が目に見えるようなデータをでっちあげ、それに決定木をかけてみました。が、実際は、こういった例でわざわざ決定木を持ち出すのはやりすぎです。軸がもっと大量にあって、人が見るには複雑すぎるデータに用いるような場面で、決定木はその価値を発揮します。
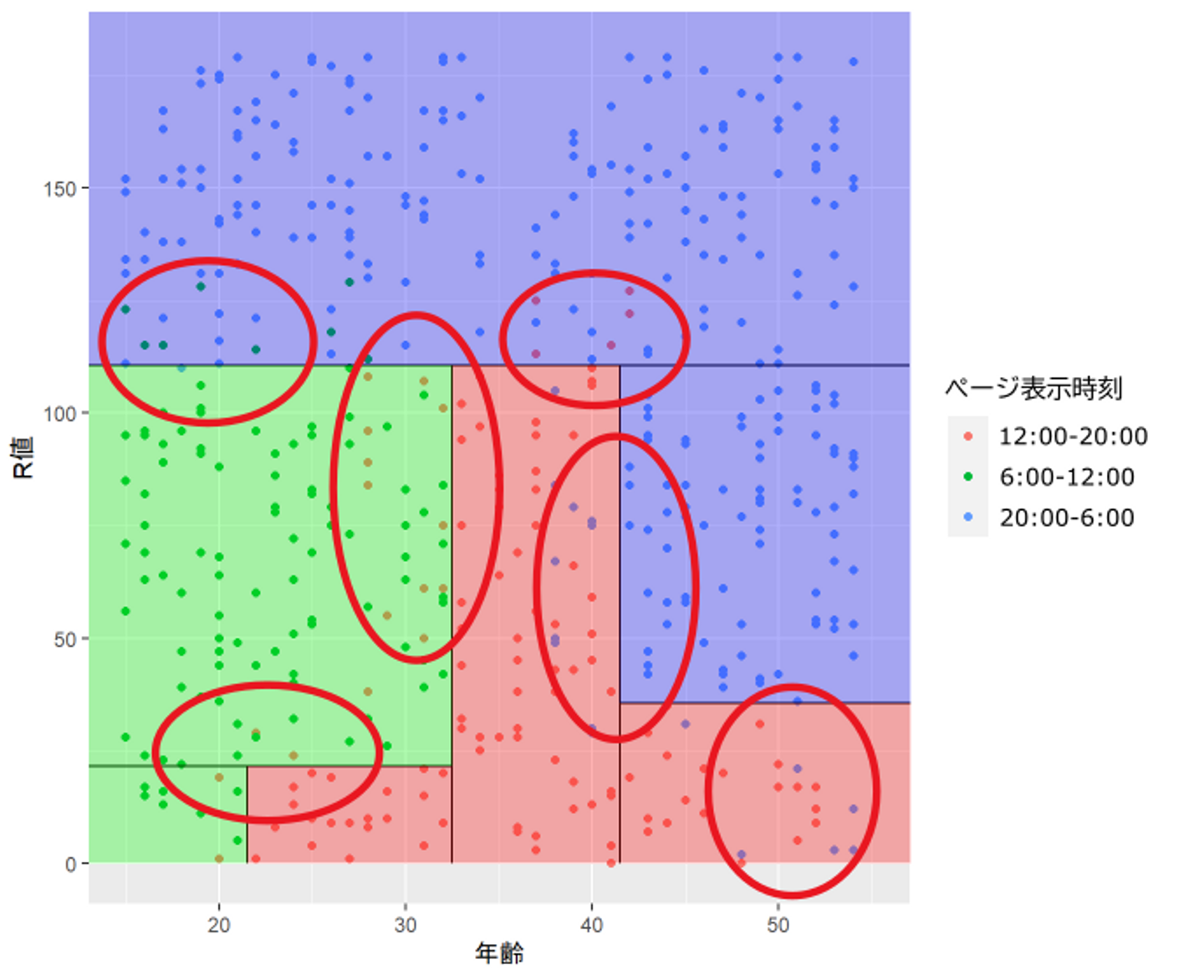
さて、ざっくりと分類できました。が、手元のデータに対して、実際のページ表示時刻と、今作った決定木が分類する予測ページ表示時刻が異なるものが存在します。
図4: 作った決定木を用いて判定すると、手元のデータ(学習データ)の中で矛盾するものが。これらに対しても正しく振り分けようとすると、更に深い分類が必要そう。
今作った決定木は、これらのデータに対しては間違った決定を下してしまうため、その点がよくないように見えます。
さらに深く分類をしていけばきっと解決するはずなので、決定木をより深く作る設定に変えてもう一度作成してみました。その結果が次の図5です。
図5: "アレ"の商品ページの表示時刻のデータから、年齢とR値を軸にしてより深い決定木を作成。図3よりも細かく分類されているのが読み取れる。
更に細かい分類になりましたが、さっきよりも多くのデータに対して正しい決定を下す決定木が作れました。もっと頑張れば全てのデータに対して正しい決定を下すことも夢ではありません。
しかし、図5の右図は分類が細かすぎるような気がします。赤い領域の左上の出っ張りなんかは顕著です。そもそもこの出っ張りに属するユーザはたったの7人しかいませんし、もしかしたらたまたま手元のデータが偏っているだけで、ここに属するユーザで本当に午後にページを表示するのはそんなに多くないのかもしれません。
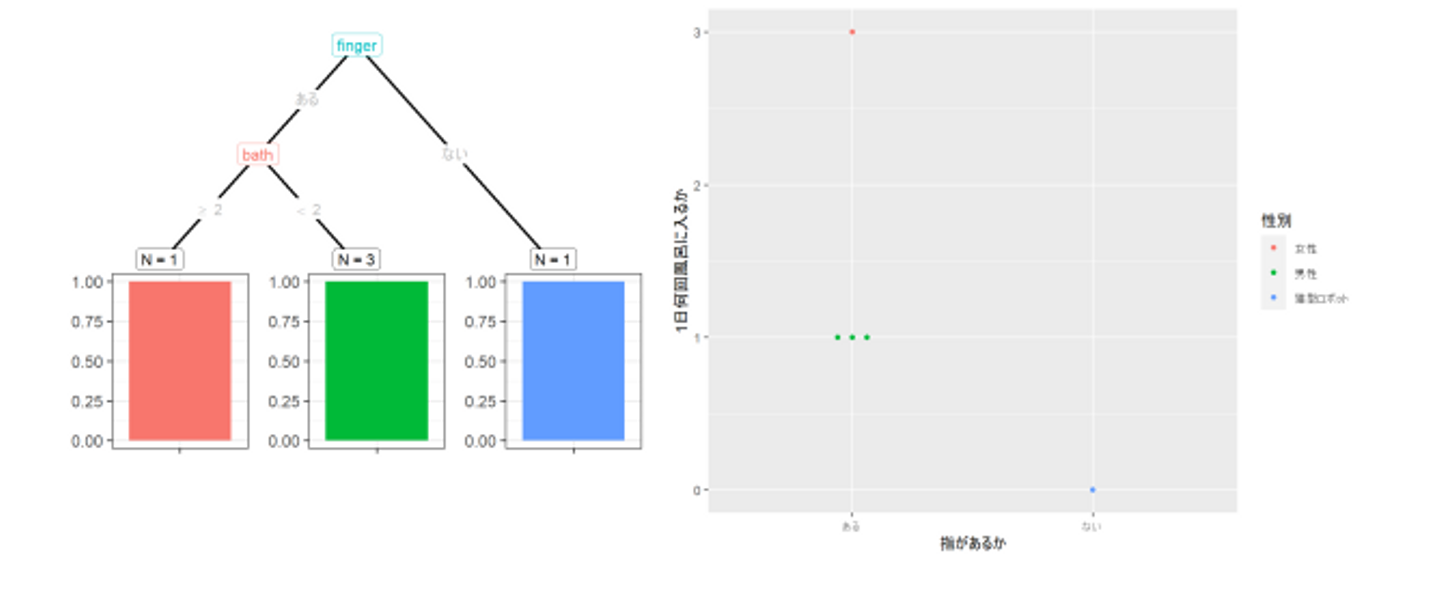
ドラえもんの主要キャラ5人をもとに、キャラクターの性別を予測する決定木を作ってみました。
「指があるか」と「1日に何回風呂に入るか」というのを軸にしてみましたが、5キャラがどう分類されるのかは次の図6で表されます。
図6: ドラえもん, のび太, しずか, ジャイアン, スネ夫を、指の有無と1日辺りの入浴回数を軸にして作成した決定木
ここでは主要5キャラの性別を正しく分類する決定木が作れました。
が、ちょっと尖りすぎているように見えます。この決定木は以下のようにキャラクターの性別を予測してくれます。
これでは他のキャラクターの性別を当てるのにはとても使えそうにありません。
※ ドラえもんの手は「ぺったんハンド」(ぺたりハンドとも?)といい、握らなくてもいろいろなものを持てるようです。しかし過去には、じゃんけんでパーを出したり、指を差したりしている姿が目撃されているとか・・・
ということで、2つの例を紹介し、その中で決定木を3本作りました。
1本目はそれっぽいものが作れましたが、他の2つはなんとなくダメそうでした。
この2つの何がだめなのかということについては、次回の記事で詳しく見ていきます。
最後に、今回の通知を飛ばすべき時刻を予測する決定木の例について、前回ざっくりと紹介した機械学習を用いた予測の流れを当てはめるとどうなるかを見て、第2回の記事を締めたいと思います。
ということで、第2回はここで終わりです。この記事はこんな内容でした。
次回は、今回見た2つのダメ決定木がなぜダメかということを詳しく見ます。それから決定木のいい悪いをどういう考え方で測るのかということを紹介します。
/assets/images/4298867/original/660614d5-392c-46fc-9884-7aab50ba6fcc?1574300883)


/assets/images/4298867/original/660614d5-392c-46fc-9884-7aab50ba6fcc?1574300883)

![]()





/assets/images/7996434/original/660614d5-392c-46fc-9884-7aab50ba6fcc?1635406102)